Towards Large Model Feature Coding
Pith reviewed 2026-06-30 17:13 UTC · model grok-4.3
The pith
Large models produce heterogeneous features that existing coding methods cannot efficiently handle.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Existing coding paradigms are profoundly misaligned with the heterogeneous nature of large model features, and LaMoFCBench provides the shared empirical foundation to drive a fundamental departure from those paradigms.
What carries the argument
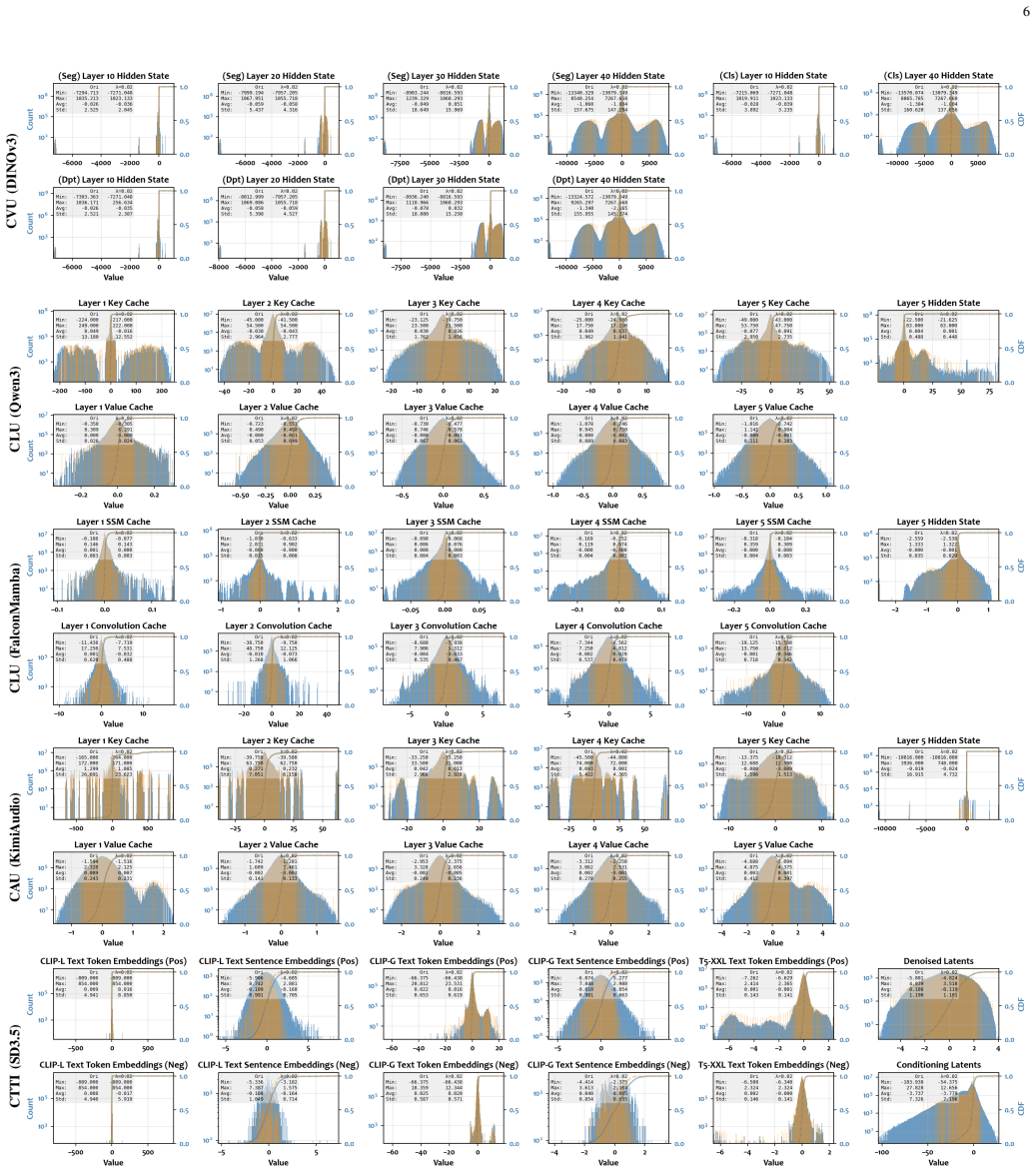
LaMoFCBench, the feature dataset covering 4 categories and 16 scenarios with a unified pipeline for extracting intermediate features at practical split points.
If this is right
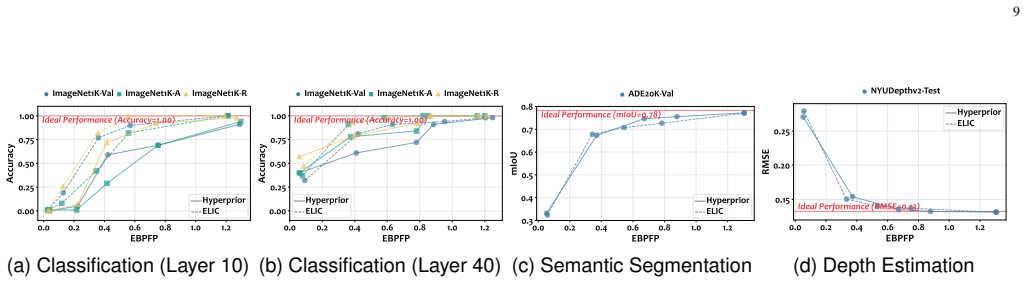
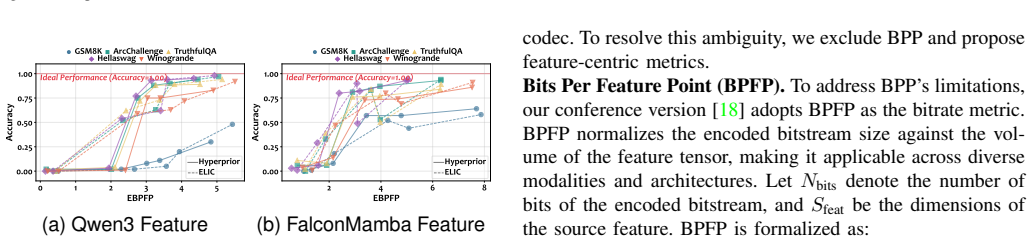
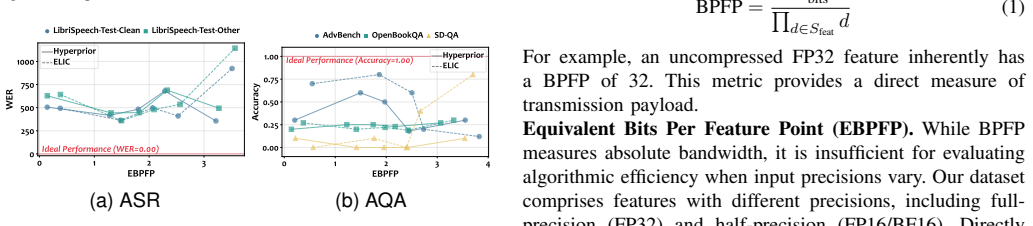
- Mainstream universal feature codecs show significant misalignment with large model feature distributions.
- Future coding methods should target the specific variations in multi-level, multi-modal, and autoregressive features.
- The benchmark enables fair comparisons across different codecs and split-computing settings.
- Practical deployments will benefit from codecs designed around the identified compression tolerances.
Where Pith is reading between the lines
- The benchmark could be expanded to include more recent model architectures to confirm the generality of the misalignment.
- Researchers might develop hybrid codecs that adapt to the different feature types within a single model.
- Integration with privacy-preserving techniques in split computing could be explored using the same evaluation setup.
Load-bearing premise
The 4 categories, 16 scenarios, and chosen split points capture enough of the statistical diversity and compression tolerances found in real large-model deployments.
What would settle it
An experiment showing that standard codecs achieve competitive compression rates and quality on a wide range of large model intermediate features not included in LaMoFCBench.
Figures

read the original abstract
Large models have delivered remarkable performance across a wide range of perception and generation tasks, yet practical deployment is increasingly constrained by computational and memory budgets, as well as privacy requirements. Split execution alleviates these constraints by partitioning computation across devices, but it inevitably introduces intensive transmission and storage of intermediate features. Unlike conventional feature coding for CNNs that typically targets homogeneous spatial activation maps, modern large models generate heterogeneous features with varying statistical distributions and compression tolerances, e.g., multi-level/multi-modal representations and autoregressive context caches. These characteristics necessitate treating large model feature coding (LaMoFC) as a fundamental system component and call for a systematic evaluation framework. In this paper, we present a comprehensive benchmark and evaluation framework for LaMoFC. We first build the feature dataset LaMoFCBench, covering diverse task requirements across 4 categories and 16 scenarios while integrating widelyadopted architectures and various split-computing settings. We then specify representative split points according to practical application scenarios to extract intermediate features, establishing a unified pipeline for fair and reproducible comparisons. Finally, we benchmark mainstream universal feature codecs, exposing the profound misalignment between existing coding paradigms and the heterogeneous nature of large model features. These findings reveal that LaMoFC demands a fundamental departure from existing paradigms, and LaMoFCBench provides the shared empirical foundation to drive this transition. The data and code will be available at https://github.com/lartpang/LaMoFCBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LaMoFCBench, a benchmark and evaluation framework for large model feature coding (LaMoFC) in split-computing deployments. It constructs a feature dataset spanning 4 categories and 16 scenarios drawn from widely adopted architectures, specifies representative split points, and benchmarks mainstream universal codecs to demonstrate profound misalignment between existing coding paradigms and the heterogeneous statistical properties of large-model features (multi-level, multi-modal, and autoregressive caches), arguing that LaMoFC requires a fundamental departure from prior approaches. Data and code are to be released publicly.
Significance. If the benchmark's coverage proves representative and the misalignment findings hold under quantitative evaluation, the work would supply a shared empirical testbed that could accelerate development of feature codecs tailored to large-model split inference, addressing real deployment constraints in computation, memory, and privacy. The planned public release of data and code strengthens its potential utility as a community resource.
major comments (1)
- [Abstract / dataset construction] Abstract and dataset-construction description: the central claim that existing codecs are 'profoundly misaligned' with large-model features in general rests on the assertion that the chosen 4 categories and 16 scenarios (plus selected architectures and split points) adequately capture the relevant statistical diversity and compression tolerances. No explicit justification, ablation, or sensitivity analysis is supplied showing that these choices exhaust key axes such as multi-level vs. autoregressive caches, vision vs. language vs. multimodal, or short vs. long context; without such evidence the observed misalignment could be an artifact of the sampled subset rather than a general property.
minor comments (1)
- [Abstract] Abstract contains the typo 'widelyadopted' (should be 'widely adopted').
Simulated Author's Rebuttal
We thank the referee for the constructive comment on dataset construction. We address the concern regarding justification of coverage below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / dataset construction] Abstract and dataset-construction description: the central claim that existing codecs are 'profoundly misaligned' with large-model features in general rests on the assertion that the chosen 4 categories and 16 scenarios (plus selected architectures and split points) adequately capture the relevant statistical diversity and compression tolerances. No explicit justification, ablation, or sensitivity analysis is supplied showing that these choices exhaust key axes such as multi-level vs. autoregressive caches, vision vs. language vs. multimodal, or short vs. long context; without such evidence the observed misalignment could be an artifact of the sampled subset rather than a general property.
Authors: We agree that the manuscript would benefit from an explicit justification of the selected categories and scenarios to support the generality claim. The 4 categories were designed to cover the main axes of feature heterogeneity (vision-only multi-level activations, language autoregressive caches, multimodal combinations, and varying context lengths), with the 16 scenarios drawn from representative architectures and split points in current literature. However, no dedicated ablation or sensitivity analysis is currently included. In the revised version we will add a subsection under dataset construction that maps each category and scenario to the relevant statistical axes, cites their prevalence in deployed large models, and reports a sensitivity study (e.g., results when subsets of scenarios are held out) to demonstrate that the observed misalignment persists across different samplings. revision: yes
Circularity Check
No circularity: empirical benchmark without derivation or self-referential claims
full rationale
The paper constructs LaMoFCBench across 4 categories and 16 scenarios, extracts features at chosen split points, and benchmarks existing codecs to observe misalignment. No equations, fitted parameters, or mathematical derivations appear in the provided text. The central claim rests on empirical results from the new dataset rather than reducing to self-citation chains, ansatzes, or definitional loops. Selection of architectures and scenarios is a benchmark design choice, not a circular reduction of the conclusion to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 4 categories and 16 scenarios plus chosen split points adequately represent practical large-model split-computing use cases
Reference graph
Works this paper leans on
-
[1]
Challenges and applications of large language models,
J. Kaddour, J. Harris, M. Mozes, H. Bradley, R. Raileanu, and R. McHardy, “Challenges and applications of large language models,” CoRR, vol. abs/2307.10169, 2023. 1
-
[2]
Split learning for health: Distributed deep learning without sharing raw patient data
P. Vepakomma, O. Gupta, T. Swedish, and R. Raskar, “Split learning for health: Distributed deep learning without sharing raw patient data,” CoRR, vol. abs/1812.00564, 2018. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Split computing and early exiting for deep learning applications: Survey and research challenges,
Y . Matsubara, M. Levorato, and F. Restuccia, “Split computing and early exiting for deep learning applications: Survey and research challenges,” ACM Computing Surveys, vol. 55, no. 5, pp. 90:1–90:30, 2023. 1, 3 15
2023
-
[4]
Fedbert: When federated learning meets pre-training,
Y . Tian, Y . Wan, L. Lyu, D. Yao, H. Jin, and L. Sun, “Fedbert: When federated learning meets pre-training,”ACM Transactions on Intelligent Systems and Technology, vol. 13, no. 4, pp. 66:1–66:26, 2022. 1
2022
-
[5]
Openfedllm: Training large language models on decentralized private data via federated learning,
R. Ye, W. Wang, J. Chai, D. Li, Z. Li, Y . Xu, Y . Du, Y . Wang, and S. Chen, “Openfedllm: Training large language models on decentralized private data via federated learning,” inACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 6137–6147. 1, 3
2024
-
[6]
Safely learning with private data: A federated learning framework for large language model,
J. Zheng, H. Zhang, L. Wang, W. Qiu, H. Zheng, and Z. M. Zheng, “Safely learning with private data: A federated learning framework for large language model,” inConference on Empirical Methods in Natural Language Processing, 2024, pp. 5293–5306. 1, 3
2024
-
[7]
Gshard: Scaling giant models with conditional computation and automatic sharding,
D. Lepikhin, H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen, “Gshard: Scaling giant models with conditional computation and automatic sharding,” inInternational Conference on Learning Representations, 2021. 1
2021
-
[8]
LLM-based edge intelligence: A comprehensive survey on architectures, applications, security and trustworthiness,
O. Friha, M. Amine Ferrag, B. Kantarci, B. Cakmak, A. Ozgun, and N. Ghoualmi-Zine, “LLM-based edge intelligence: A comprehensive survey on architectures, applications, security and trustworthiness,”IEEE Open Journal of the Communications Society, vol. 5, pp. 5799–5856,
-
[9]
When feder- ated learning meets privacy-preserving computation,
J. Chen, H. Yan, Z. Liu, M. Zhang, H. Xiong, and S. Yu, “When feder- ated learning meets privacy-preserving computation,”ACM Computing Surveys, vol. 56, no. 12, pp. 1–36, 2024. 1, 3
2024
-
[10]
Toward intelligent sensing: Intermediate deep feature compression,
Z. Chen, K. Fan, S. Wang, L. Duan, W. Lin, and A. C. Kot, “Toward intelligent sensing: Intermediate deep feature compression,”IEEE Trans- actions on Image Processing, vol. 29, pp. 2230–2243, 2020. 1
2020
-
[11]
IMOFC: identity- level metric optimized feature compression for identification tasks,
C. Gao, Y . Jiang, S. Wu, Y . Ma, L. Li, and D. Liu, “IMOFC: identity- level metric optimized feature compression for identification tasks,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 2, pp. 1855–1869, 2025. 1
2025
-
[12]
Dmofc: Discrimination metric-optimized feature compression,
C. Gao, Y . Jiang, L. Li, D. Liu, and F. Wu, “Dmofc: Discrimination metric-optimized feature compression,” inPicture Coding Symposium, Jun. 2024, pp. 1–5. 1
2024
-
[13]
Towards analysis-friendly face representation with scalable feature and texture compression,
S. Wang, S. Wang, W. Yang, X. Zhang, S. Wang, S. Ma, and W. Gao, “Towards analysis-friendly face representation with scalable feature and texture compression,”IEEE Transactions on Multimedia, vol. 24, pp. 3169–3181, 2022. 1
2022
-
[14]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations, 2021. 1, 3
2021
-
[15]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inInternational Conference on Neural Information Processing Systems, 2017, pp. 5998–
2017
-
[16]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”CoRR, vol. abs/2312.00752, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inInternational Conference on Neural Information Processing Systems,
-
[18]
Feature coding in the era of large models: Dataset, test conditions, and benchmark,
C. Gao, Y . Ma, Q. Chen, Y . Xu, D. Liu, and W. Lin, “Feature coding in the era of large models: Dataset, test conditions, and benchmark,” inIEEE International Conference on Computer Vision, Oct. 2025, pp. 1068–1077. 1, 2, 4, 5, 7, 9, 10
2025
-
[19]
DT-UFC: universal large model feature coding via peaky-to-balanced distribution transformation,
C. Gao, Z. Liu, L. Li, D. Liu, X. Sun, and W. Lin, “DT-UFC: universal large model feature coding via peaky-to-balanced distribution transformation,” inACM International Conference on Multimedia, 2025, pp. 5198–5207. 2, 9, 10, 12, 13
2025
-
[20]
Variational image compression with a scale hyperprior,
J. Ball ´e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” inInternational Conference on Learning Representations, 2018. 2, 10
2018
-
[21]
Efficient feature compression for the object tracking task,
R. Henzel, K. M. Misra, and T. Ji, “Efficient feature compression for the object tracking task,” inIEEE International Conference on Image Processing, 2022, pp. 3505–3509. 2, 10
2022
-
[22]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. E. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. J ´egou, P. Labatut, and P. Bojanowski, “Dinov3,”CoRR, vol. abs/2508.10104,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inIEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248–255. 3, 5
2009
-
[24]
Natural adversarial examples,
D. Hendrycks, K. Zhao, S. Basart, J. Steinhardt, and D. Song, “Natural adversarial examples,” inIEEE Conference on Computer Vision and Pattern Recognition, Jun. 2021, pp. 15 257–15 266. 3, 5
2021
-
[25]
The many faces of robustness: A critical analysis of out- of-distribution generalization,
D. Hendrycks, S. Basart, N. Mu, S. Kadavath, F. Wang, E. Dorundo, R. Desai, T. Zhu, S. Parajuli, M. Guo, D. Song, J. Steinhardt, and J. Gilmer, “The many faces of robustness: A critical analysis of out- of-distribution generalization,” inIEEE International Conference on Computer Vision, 2021, pp. 8320–8329. 3, 5
2021
-
[26]
Masked-attention mask transformer for universal image segmentation,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmentation,” inIEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 1280–1289. 3, 4
2022
-
[27]
Scene parsing through ADE20K dataset,
B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba, “Scene parsing through ADE20K dataset,” inIEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 5122–5130. 3, 5
2017
-
[28]
Vision transformers for dense prediction,
R. Ranftl, A. Bochkovskiy, and V . Koltun, “Vision transformers for dense prediction,” inIEEE International Conference on Computer Vision, 2021, pp. 12 159–12 168. 3, 4
2021
-
[29]
Indoor segmentation and support inference from RGBD images,
N. Silberman, D. Hoiem, P. Kohli, and R. Fergus, “Indoor segmentation and support inference from RGBD images,” inEuropean Conference on Computer Vision, vol. 7576, 2012, pp. 746–760. 3, 5
2012
-
[30]
Q. Team, “Qwen3 technical report,”CoRR, vol. abs/2505.09388, 2025. 3, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Falcon mamba: The first competitive attention-free 7b language model,
J. Zuo, M. Velikanov, D. E. Rhaiem, I. Chahed, Y . Belkada, G. Kunsch, and H. Hacid, “Falcon mamba: The first competitive attention-free 7b language model,”CoRR, vol. abs/2410.05355, 2024. 3, 4, 5
-
[32]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schul- man, “Training verifiers to solve math word problems,”CoRR, vol. abs/2110.14168, 2021. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have solved question answering? try arc, the AI2 reasoning challenge,”CoRR, vol. abs/1803.05457, 2018. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
Truthfulqa: Measuring how models mimic human falsehoods,
S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how models mimic human falsehoods,” inAnnual Meeting of the Association for Computational Linguistics, 2022, pp. 3214–3252. 3, 5
2022
-
[35]
Hellaswag: Can a machine really finish your sentence?
R. Zellers, A. Holtzman, Y . Bisk, A. Farhadi, and Y . Choi, “Hellaswag: Can a machine really finish your sentence?” inAnnual Meeting of the Association for Computational Linguistics, 2019, pp. 4791–4800. 3, 5
2019
-
[36]
Winogrande: an adversarial winograd schema challenge at scale,
K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y . Choi, “Winogrande: an adversarial winograd schema challenge at scale,”Communications of the ACM, vol. 64, no. 9, pp. 99–106, Aug. 2021. 3, 5
2021
-
[37]
KimiTeam, D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tang, Z. Wang, C. Wei, Y . Xin, X. Xu, J. Yu, Y . Zhang, X. Zhou, Y . Charles, J. Chen, Y . Chen, Y . Du, W. He, Z. Hu, G. Lai, Q. Li, Y . Liu, W. Sun, J. Wang, Y . Wang, Y . Wu, Y . Wu, D. Yang, H. Yang, Y . Yang, Z. Yang, A. Yin, R. Yuan, Y . Zhang, and Z. Zhou, “...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Librispeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” inInternational Conference on Acoustics, Speech and Signal Processing, 2015, pp. 5206–5210. 3, 5
2015
-
[39]
V oicebench: Benchmarking llm-based voice assistants,
Y . Chen, X. Yue, C. Zhang, X. Gao, R. T. Tan, and H. Li, “V oicebench: Benchmarking llm-based voice assistants,”Transactions of the Associa- tion for Computational Linguistics, vol. 14, pp. 378–398, Apr. 2026. 3, 6
2026
-
[40]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, and R. Rombach, “Scaling rectified flow transformers for high-resolution image synthesis,” inInternational Conference on Machine Learning,
-
[41]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inIEEE International Conference on Computer Vision, Oct. 2023, pp. 3813–3824. 3, 4, 5
2023
-
[42]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean Conference on Computer Vision, 2014, pp. 740–
2014
-
[43]
Microsoft COCO Captions: Data Collection and Evaluation Server
X. Chen, H. Fang, T. Lin, R. Vedantam, S. Gupta, P. Doll ´ar, and C. L. Zitnick, “Microsoft COCO captions: Data collection and evaluation server,”CoRR, vol. abs/1504.00325, 2015. 3
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[44]
Video coding for machines: Compact visual representation compression for intelligent collaborative analytics,
W. Yang, H. Huang, Y . Hu, L.-Y . Duan, and J. Liu, “Video coding for machines: Compact visual representation compression for intelligent collaborative analytics,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 7, pp. 5174–5191, Jul. 2024. 3
2024
-
[45]
Video coding for machines: A paradigm of collaborative compression and intelligent 16 analytics,
L. Duan, J. Liu, W. Yang, T. Huang, and W. Gao, “Video coding for machines: A paradigm of collaborative compression and intelligent 16 analytics,”IEEE Transactions on Image Processing, vol. 29, pp. 8680– 8695, 2020. 3
2020
-
[46]
Non-semantics suppressed mask learning for unsupervised video semantic compression,
Y . Tian, G. Lu, G. Zhai, and Z. Gao, “Non-semantics suppressed mask learning for unsupervised video semantic compression,” inIEEE International Conference on Computer Vision, 2023, pp. 13 564–13 576. 3
2023
-
[47]
All-in-one image coding for joint human-machine vision with multi-path aggregation,
X. Zhang, P. Guo, M. Lu, and Z. Ma, “All-in-one image coding for joint human-machine vision with multi-path aggregation,” inInternational Conference on Neural Information Processing Systems, vol. 37, 2024, pp. 71 465–71 503. 3
2024
-
[48]
Towards task-generic image compression: A study of semantics-oriented metrics,
C. Gao, D. Liu, L. Li, and F. Wu, “Towards task-generic image compression: A study of semantics-oriented metrics,”IEEE Transactions on Multimedia, vol. 25, pp. 721–735, 2023. 3
2023
-
[49]
Preprocessing enhanced image compression for machine vision,
G. Lu, X. Ge, T. Zhong, Q. Hu, and J. Geng, “Preprocessing enhanced image compression for machine vision,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 12, pp. 13 556–13 568, Dec. 2024. 3
2024
-
[50]
SMC++: masked learning of unsupervised video semantic compression,
Y . Tian, X. Ling, C. Geng, Q. Hu, G. Lu, and G. Zhai, “SMC++: masked learning of unsupervised video semantic compression,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 2, pp. 1992–2011, Feb. 2026. 3
1992
-
[51]
Perceptual image compression with conditional diffusion transformers,
R. Mao, X. Feng, C. Gao, L. Li, D. Liu, and X. Sun, “Perceptual image compression with conditional diffusion transformers,” inIEEE Inter- national Conference on Visual Communications and Image Processing, 2024, pp. 1–5. 3
2024
-
[52]
Vnvc: A versatile neural video coding framework for efficient human-machine vision,
X. Sheng, L. Li, D. Liu, and H. Li, “Vnvc: A versatile neural video coding framework for efficient human-machine vision,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, vol. 46, no. 7, pp. 4579–4596, 2024. 3
2024
-
[53]
Object segmentation- assisted inter prediction for versatile video coding,
Z. Li, Z. Yuan, L. Li, D. Liu, X. Tang, and F. Wu, “Object segmentation- assisted inter prediction for versatile video coding,”IEEE Transactions on Broadcasting, 2024. 3
2024
-
[54]
USTC-TD: A test dataset and benchmark for image and video coding in 2020s,
Z. Li, J. Liao, C. Tang, H. Zhang, Y . Li, Y . Bian, X. Sheng, X. Feng, Y . Li, C. Gao, L. Li, D. Liu, and F. Wu, “USTC-TD: A test dataset and benchmark for image and video coding in 2020s,”IEEE Transactions on Multimedia, vol. 28, pp. 269–284, 2026. 3
2026
-
[55]
Attention- based variable-size feature compression module for edge inference,
S. Li, C. Ma, Y . Zhang, L. Li, C. Wang, X. Cui, and J. Liu, “Attention- based variable-size feature compression module for edge inference,”The Journal of Supercomputing, 2023. 3, 4
2023
-
[56]
Deep feature compression using spatio-temporal arrangement toward collaborative intelligent world,
S. Suzuki, S. Takeda, M. Takagi, R. Tanida, H. Kimata, and H. Shouno, “Deep feature compression using spatio-temporal arrangement toward collaborative intelligent world,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 6, pp. 3934–3946, 2022. 3, 4
2022
-
[57]
End-to-end learnable multi-scale feature compression for VCM,
Y . Kim, H. Jeong, J. Yu, Y . Kim, J. Lee, S. Y . Jeong, and H. Y . Kim, “End-to-end learnable multi-scale feature compression for VCM,”IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1,
-
[58]
Learnt mutual feature compression for machine vision,
T. Liu, M. Xu, S. Li, C. Chen, L. Yang, and Z. Lv, “Learnt mutual feature compression for machine vision,” inInternational Conference on Acoustics, Speech and Signal Processing, 2023, pp. 1–5. 3, 4
2023
-
[59]
High efficient 3D convolution feature compression,
Y . Cai, P. Xing, and X. Gao, “High efficient 3D convolution feature compression,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 4, pp. 3732–3744, May 2025. 3, 4
2025
-
[60]
Feature compression with 3d sparse convolution,
Y . Ma, C. Gao, Q. Chen, L. Li, D. Liu, and X. Sun, “Feature compression with 3d sparse convolution,” inIEEE International Conference on Visual Communications and Image Processing, 2024, pp. 1–5. 3, 4
2024
-
[61]
Rethinking the joint optimization in video coding for machines: A case study,
C. Gao, Z. Li, L. Li, D. Liu, and F. Wu, “Rethinking the joint optimization in video coding for machines: A case study,” inData Compression Conference, Mar. 2024, pp. 556–556. 3, 4
2024
-
[62]
Emerging standards for machine-to-machine video coding,
M. E. H. Eimon, V . Adzic, H. Kalva, and B. Furht, “Emerging standards for machine-to-machine video coding,” inProceedings of the Mile-High Video Conference, 2026, pp. 128–134. 3, 4
2026
-
[63]
Efficient feature compression for machines with global statistics preservation,
M. E. Hossain Eimon, H. Choi, F. Racap ´e, M. Ulhaq, V . Adzic, H. Kalva, and B. Furht, “Efficient feature compression for machines with global statistics preservation,” inIEEE International Symposium on Circuits and Systems, May 2025, pp. 1–5. 3, 4
2025
-
[64]
Multiscale feature importance-based bit allocation for end-to-end feature coding for ma- chines,
J. Liu, Y . Zhang, Z. Guo, X. Huang, and G. Jiang, “Multiscale feature importance-based bit allocation for end-to-end feature coding for ma- chines,”ACM Transactions on Multimedia Computing, Communications, and Applications, vol. 21, no. 9, pp. 263:1–263:19, 2025. 3, 4
2025
-
[65]
New vvc profiles targeting feature coding for machines,
M. E. H. Eimon, A. Perera, J. Merlos, V . Adzic, and H. Kalva, “New vvc profiles targeting feature coding for machines,” inIEEE International Conference on Image Processing Workshops, Sep. 2025, pp. 685–690. 3, 4
2025
-
[66]
Enabling next-generation consumer experience with feature coding for machines,
M. E. Hossain Eimon, J. Merlos, A. Perera, H. Kalva, V . Adzic, and B. Furht, “Enabling next-generation consumer experience with feature coding for machines,” inIEEE International Conference on Consumer Electronics, Jan. 2025, pp. 1–4. 3, 4
2025
-
[67]
Feature coding for scalable machine vision,
M. E. H. Eimon, J. Merlos, A. Perera, H. Kalva, V . Adzic, and B. Furht, “Feature coding for scalable machine vision,”IEEE Consumer Electronics Magazine, pp. 1–12, 2025. 3, 4
2025
-
[68]
Stereo image coding for machines with joint visual feature compression,
D. Jin, J. Lei, B. Peng, Z. Pan, N. Ling, and Q. Huang, “Stereo image coding for machines with joint visual feature compression,”CoRR, vol. abs/2502.14190, 2025. 3, 4
-
[69]
Deep Learning Scaling is Predictable, Empirically
J. Hestness, S. Narang, N. Ardalani, G. F. Diamos, H. Jun, H. Kianinejad, M. M. A. Patwary, Y . Yang, and Y . Zhou, “Deep learning scaling is predictable, empirically,”CoRR, vol. abs/1712.00409, 2017. 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[70]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”CoRR, vol. abs/2001.08361, 2020. 3
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[71]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L. Sifre, “Training compute-optimal large language models,”CoRR, vol. abs/2203.15556, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[72]
Privacy and robustness in federated learning: Attacks and defenses,
L. Lyu, H. Yu, X. Ma, C. Chen, L. Sun, J. Zhao, Q. Yang, and P. S. Yu, “Privacy and robustness in federated learning: Attacks and defenses,” IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 7, pp. 8726–8746, 2024. 3
2024
-
[73]
On protecting the data privacy of large language models (llms): A survey,
B. Yan, K. Li, M. Xu, Y . Dong, Y . Zhang, Z. Ren, and X. Cheng, “On protecting the data privacy of large language models (llms): A survey,” inInternational Conference on Meta Computing, Jun. 2024, pp. 1–12. 3
2024
-
[74]
A survey on model compression for large language models,
X. Zhu, J. Li, Y . Liu, C. Ma, and W. Wang, “A survey on model compression for large language models,”Transactions of the Association for Computational Linguistics, vol. 12, pp. 1556–1577, 2024. 3
2024
-
[75]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: accu- rate post-training quantization for generative pre-trained transformers,” CoRR, vol. abs/2210.17323, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[76]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
J. Lin, J. Tang, H. Tang, S. Yang, X. Dang, and S. Han, “AWQ: activation-aware weight quantization for LLM compression and accel- eration,”CoRR, vol. abs/2306.00978, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[77]
H2O: heavy- hitter oracle for efficient generative inference of large language models,
Z. Zhang, Y . Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y . Tian, C. R ´e, C. W. Barrett, Z. Wang, and B. Chen, “H2O: heavy- hitter oracle for efficient generative inference of large language models,” inInternational Conference on Neural Information Processing Systems,
-
[78]
Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time,
Z. Liu, A. Desai, F. Liao, W. Wang, V . Xie, Z. Xu, A. Kyrillidis, and A. Shrivastava, “Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time,” inInternational Conference on Neural Information Processing Systems, 2023. 4
2023
-
[79]
Kvquant: Towards 10 million context length LLM inference with KV cache quantization,
C. Hooper, S. Kim, H. Mohammadzadeh, M. W. Mahoney, Y . S. Shao, K. Keutzer, and A. Gholami, “Kvquant: Towards 10 million context length LLM inference with KV cache quantization,” inInternational Conference on Neural Information Processing Systems, 2024. 4
2024
-
[80]
Latent-space scalability for multi-task col- laborative intelligence,
H. Choi and I. V . Baji ´c, “Latent-space scalability for multi-task col- laborative intelligence,” inIEEE International Conference on Image Processing, 2021, pp. 3562–3566. 4
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.