Towards Efficient Large Language Reasoning Models via Extreme-Ratio Chain-of-Thought Compression
Pith reviewed 2026-05-21 13:38 UTC · model grok-4.3
The pith
Extra-CoT compresses chain-of-thought to extreme ratios while improving accuracy on math tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
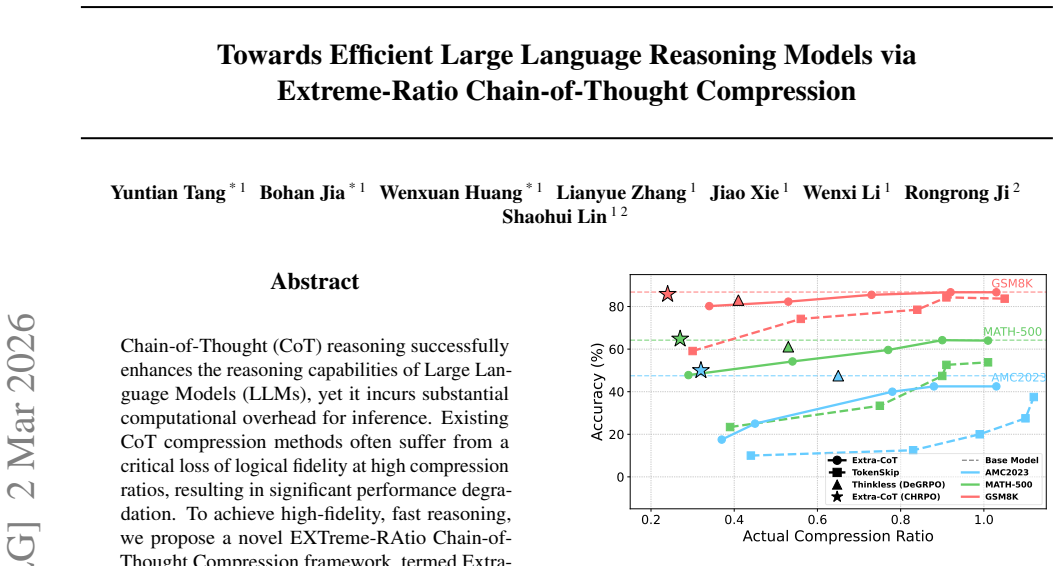
Extra-CoT produces reliable high-fidelity supervision at extreme compression ratios by training a dedicated semantically-preserved compressor on fine-grained mathematical CoT data, followed by mixed-ratio SFT that exposes the model to a spectrum of token budgets and CHRPO that uses constrained hierarchical rewards to incentivize question-solving ability under lower budgets, yielding over 73 percent token reduction and a 0.6 percent accuracy gain on MATH-500 with Qwen3-1.7B while outperforming prior methods on three mathematical reasoning benchmarks.
What carries the argument
Extra-CoT framework, whose core mechanisms are a fine-grained compressor that generates compressed yet semantically faithful CoT pairs and Constrained and Hierarchical Ratio Policy Optimization (CHRPO) that explicitly rewards accurate answers at successively tighter token limits.
If this is right
- Models learn to follow a continuous range of compression budgets after mixed-ratio SFT.
- Hierarchical rewards in the RL stage directly improve solving ability when token counts are forced lower.
- The same pipeline outperforms earlier CoT compression techniques at the highest ratios tested.
- Token budgets can be reduced by more than 70 percent on standard math benchmarks while accuracy holds or rises.
Where Pith is reading between the lines
- If the compressor stays faithful across domains, the same extreme-ratio recipe could shorten reasoning traces in code generation or scientific problem solving.
- Lower average token counts would reduce energy use when many reasoning queries run in parallel on shared hardware.
- One direct test would be to measure whether the accuracy advantage persists when the base model size increases or when the training data includes non-math tasks.
Load-bearing premise
A compressor trained on annotated mathematical reasoning traces can produce compressed chains that remain logically correct at extreme ratios so that later supervised and reinforcement stages can keep or improve final answer accuracy.
What would settle it
Running Extra-CoT on MATH-500 with Qwen3-1.7B and measuring either less than 70 percent token reduction or an accuracy drop instead of the reported 0.6 percent gain would falsify the central performance claim.
Figures






read the original abstract
Chain-of-Thought (CoT) reasoning successfully enhances the reasoning capabilities of Large Language Models (LLMs), yet it incurs substantial computational overhead for inference. Existing CoT compression methods often suffer from a critical loss of logical fidelity at high compression ratios, resulting in significant performance degradation. To achieve high-fidelity, fast reasoning, we propose a novel EXTreme-RAtio Chain-of-Thought Compression framework, termed Extra-CoT, which aggressively reduces the token budget while preserving answer accuracy. To generate reliable, high-fidelity supervision, we first train a dedicated semantically-preserved compressor on mathematical CoT data with fine-grained annotations. An LLM is then fine-tuned on these compressed pairs via a mixed-ratio supervised fine-tuning (SFT), teaching it to follow a spectrum of compression budgets and providing a stable initialization for reinforcement learning (RL). We further propose Constrained and Hierarchical Ratio Policy Optimization (CHRPO) to explicitly incentivize question-solving ability under lower budgets by a hierarchical reward. Experiments on three mathematical reasoning benchmarks show the superiority of Extra-CoT. For example, on MATH-500 using Qwen3-1.7B, Extra-CoT achieves over 73\% token reduction with an accuracy improvement of 0.6\%, significantly outperforming state-of-the-art (SOTA) methods. Our source codes have been released at https://github.com/Mwie1024/Extra-CoT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Extra-CoT, a framework for extreme-ratio Chain-of-Thought compression. It first trains a dedicated compressor on fine-grained mathematical CoT annotations to produce high-fidelity compressed sequences, then performs mixed-ratio supervised fine-tuning on an LLM, and finally applies Constrained and Hierarchical Ratio Policy Optimization (CHRPO) with hierarchical rewards to maintain question-solving accuracy under reduced token budgets. Experiments on three mathematical reasoning benchmarks, including MATH-500 with Qwen3-1.7B, report over 73% token reduction accompanied by a 0.6% accuracy gain while outperforming prior methods; source code is released.
Significance. If the central results hold under rigorous verification, the work could meaningfully advance efficient inference for reasoning LLMs by demonstrating that aggressive CoT compression need not degrade (and may even improve) final-answer accuracy. The explicit release of source code and the use of a hierarchical reward structure in CHRPO are constructive elements that support reproducibility and targeted optimization.
major comments (2)
- Abstract: The headline result (73% token reduction +0.6% accuracy on MATH-500) is load-bearing for the central claim yet rests on the unverified assumption that the dedicated compressor preserves full logical structure at extreme ratios. No quantitative fidelity metrics, error analysis, or examples of preserved versus omitted reasoning steps are referenced, leaving open the possibility that downstream SFT and CHRPO merely compensate for introduced inconsistencies rather than benefiting from true high-fidelity compression.
- Method description of CHRPO: The hierarchical reward is defined primarily in terms of final-answer correctness and token budget. This creates a potential mismatch with the compressor-fidelity concern; if subtle logical errors survive compression, the reward signal may not penalize them, undermining the claim that CHRPO explicitly incentivizes reliable reasoning under lower budgets.
minor comments (2)
- Abstract and experimental section: Baseline implementations, data splits, statistical significance tests, and ablation results on compressor quality are not described, which hinders direct comparison and assessment of robustness.
- Notation for mixed compression ratios: The spectrum of budgets used in SFT is referenced but not formalized with an equation or explicit sampling procedure, making the training protocol harder to replicate.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments have helped us identify areas where additional evidence and clarification strengthen the manuscript. We address each major comment below and have revised the paper accordingly.
read point-by-point responses
-
Referee: Abstract: The headline result (73% token reduction +0.6% accuracy on MATH-500) is load-bearing for the central claim yet rests on the unverified assumption that the dedicated compressor preserves full logical structure at extreme ratios. No quantitative fidelity metrics, error analysis, or examples of preserved versus omitted reasoning steps are referenced, leaving open the possibility that downstream SFT and CHRPO merely compensate for introduced inconsistencies rather than benefiting from true high-fidelity compression.
Authors: We agree that explicit evidence of compressor fidelity is essential to support the headline claims. The original manuscript describes training the compressor on fine-grained mathematical CoT annotations to achieve semantic preservation, but we acknowledge that quantitative fidelity metrics, error analysis, and concrete examples were not included in the abstract or sufficiently highlighted in the main text. In the revised version we have added a dedicated subsection (Section 3.2) reporting step-level fidelity metrics (BERTScore and ROUGE on reasoning steps) together with representative examples of preserved versus omitted steps and an accompanying error analysis. These additions demonstrate that the compressor maintains logical structure at extreme ratios and that the observed accuracy gains arise from high-fidelity compression rather than downstream compensation. revision: yes
-
Referee: Method description of CHRPO: The hierarchical reward is defined primarily in terms of final-answer correctness and token budget. This creates a potential mismatch with the compressor-fidelity concern; if subtle logical errors survive compression, the reward signal may not penalize them, undermining the claim that CHRPO explicitly incentivizes reliable reasoning under lower budgets.
Authors: We appreciate the referee’s observation on the reward design. The hierarchical reward indeed centers on final-answer correctness as the primary term and token budget as a secondary constraint. Because the SFT stage is performed on high-fidelity compressed CoTs produced by the dedicated compressor, logical errors are largely eliminated before RL begins; any residual inconsistency that leads to an incorrect answer is directly penalized by the correctness reward. To make this interaction explicit, we have expanded the CHRPO method section with a clearer breakdown of the hierarchical reward components and added a short discussion of how upstream fidelity and the correctness signal together ensure reliable reasoning. We have also included an ablation showing performance degradation when the compressor is replaced by a lower-fidelity baseline, further supporting the design. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims rest on empirical results from training a compressor on annotated CoT data, followed by mixed-ratio SFT and CHRPO-based RL, then measuring accuracy on held-out benchmarks such as MATH-500. These accuracy numbers are obtained after training and are not equivalent to the training inputs by construction. The hierarchical reward in CHRPO is a training objective tied to question-solving but does not reduce the reported benchmark gains to a definitional tautology or fitted input renamed as prediction. No equations, self-citations, or uniqueness theorems are invoked in a load-bearing way that collapses the result to prior author work or ansatz. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- mixed compression ratios
- CHRPO reward coefficients
axioms (1)
- domain assumption A compressor trained on annotated mathematical CoT can generate high-fidelity compressed traces at extreme ratios.
invented entities (1)
-
CHRPO (Constrained and Hierarchical Ratio Policy Optimization)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a novel EXTreme-RAtio Chain-of-Thought Compression framework, termed Extra-CoT, which aggressively reduces the token budget while preserving answer accuracy. ... train a dedicated semantically-preserved compressor on mathematical CoT data with fine-grained annotations.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We further propose Constrained and Hierarchical Ratio Policy Optimization (CHRPO) to explicitly incentivize question-solving ability under lower budgets by a hierarchical reward.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Shorthand for Thought: Compressing LLM Reasoning via Entropy-Guided Supertokens
Entropy-guided supertokens from BPE on reasoning traces compress LLM outputs by 8.1% on average across models and math benchmarks with no accuracy loss while exposing strategy differences between correct and incorrect traces.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.