Efficient implementation of graph autoencoders for model-order reduction of systems with sharp gradients
Pith reviewed 2026-06-26 05:56 UTC · model grok-4.3
The pith
Graph autoencoders enable accurate model-order reduction for systems with sharp gradients where linear methods fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
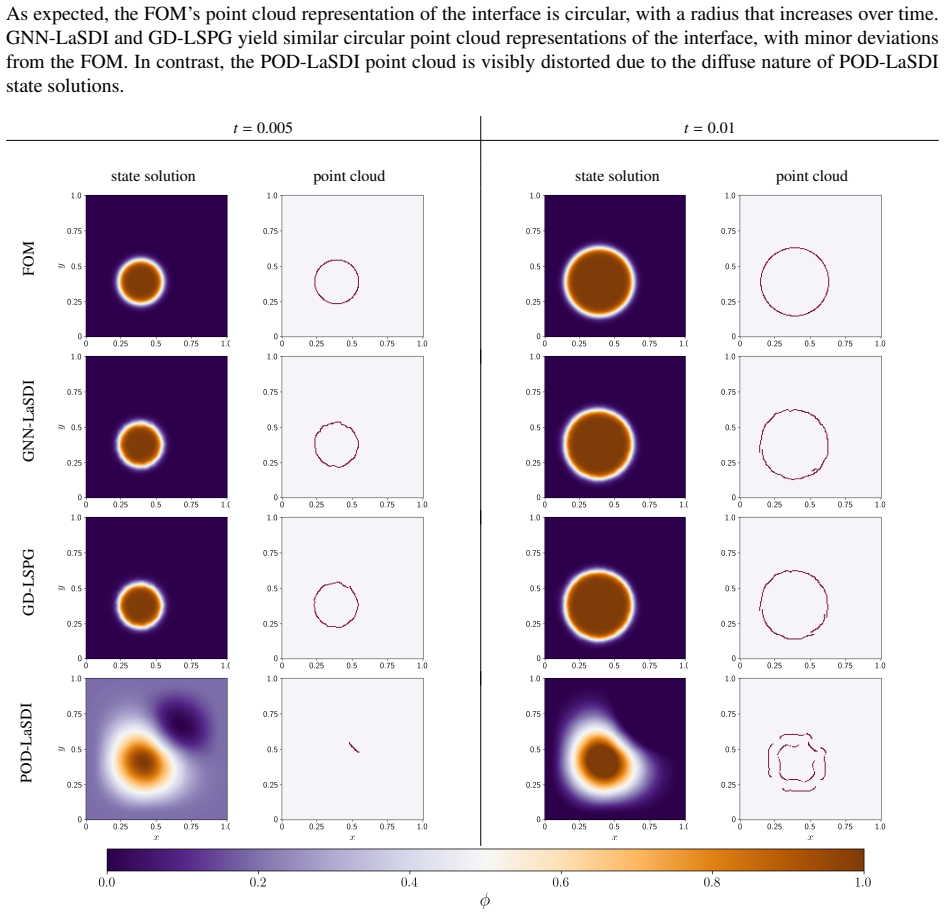
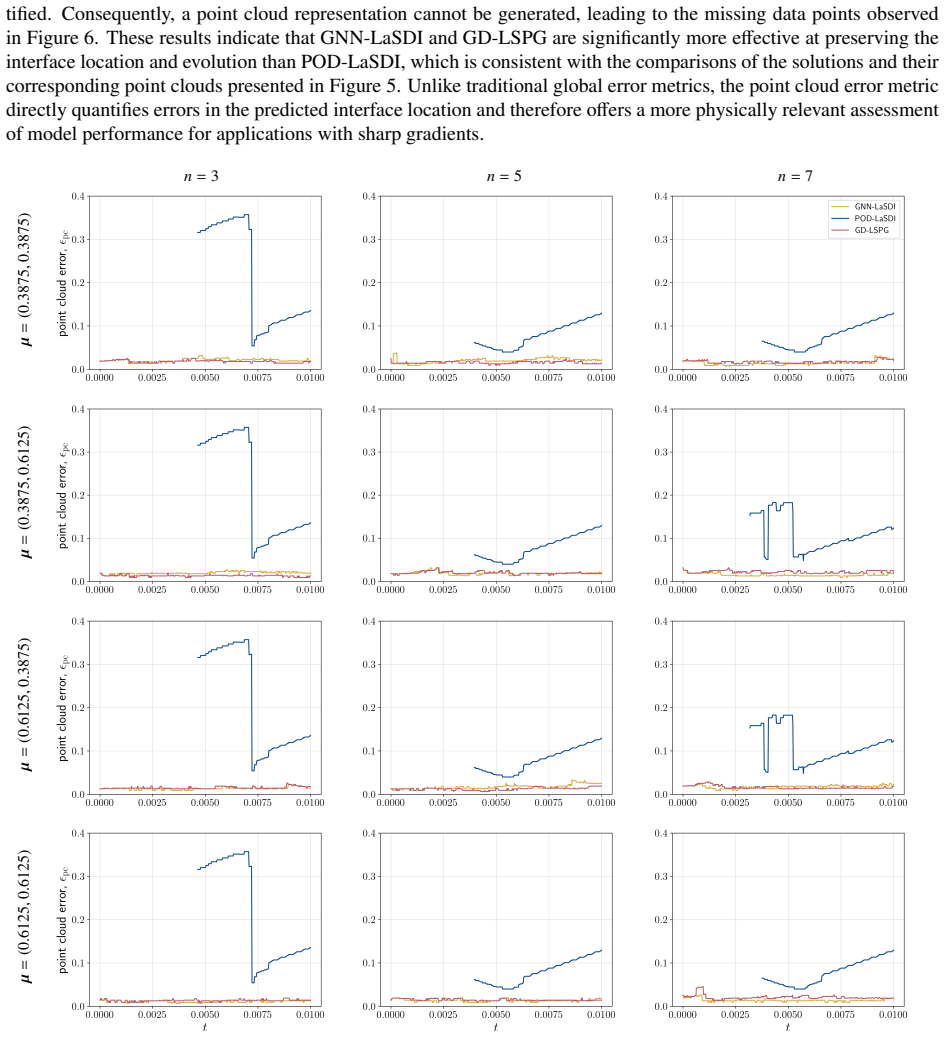
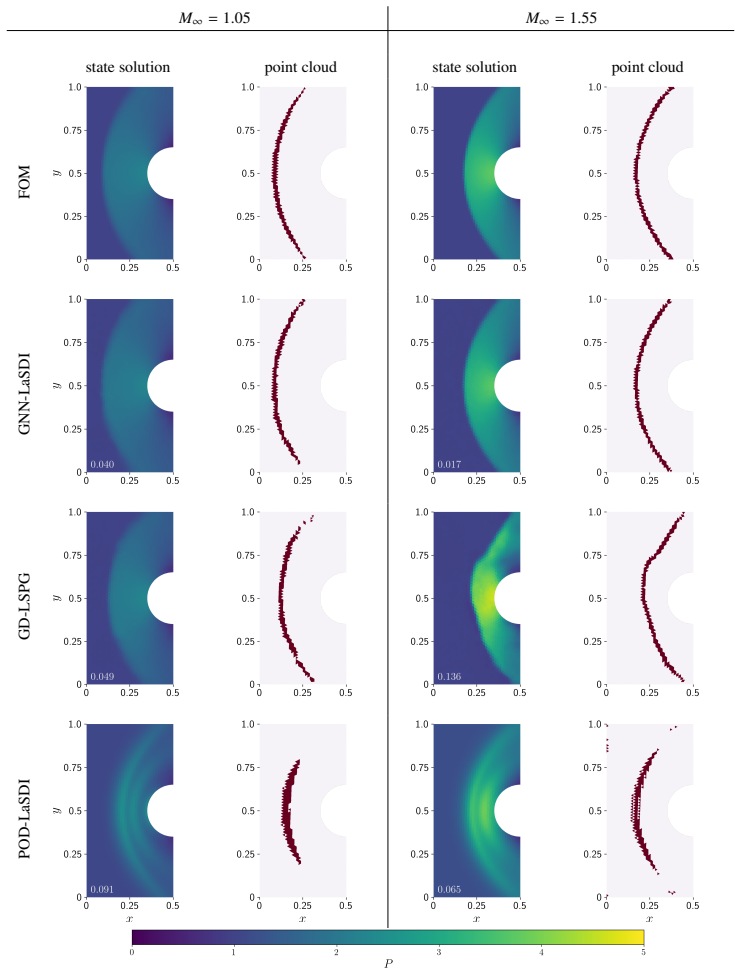
GNN-LaSDI employs graph autoencoders to obtain nonlinear low-dimensional representations of systems with sharp gradients and then applies operator learning to predict the temporal evolution of those representations. For the studied problems this yields significantly greater accuracy than POD-LaSDI at only modestly higher cost, while remaining substantially cheaper than GD-LSPG. The point cloud error metric supplies a more intuitive assessment of accuracy in the vicinity of sharp gradients than standard error measures.
What carries the argument
Graph autoencoder nonlinear dimensionality reduction combined with operator learning on the latent representation (GNN-LaSDI).
If this is right
- GNN-LaSDI supplies a practical middle ground between the accuracy of geometric deep projection methods and the speed of POD-based latent dynamics identification.
- The point cloud error metric evaluates reduced-order model performance on sharp-gradient locations more informatively than conventional L2-type norms.
- Graph autoencoders succeed at capturing nonlinear features that defeat linear reduction techniques such as POD.
- The overall framework balances predictive accuracy against computational speedup for the class of problems examined.
Where Pith is reading between the lines
- The same graph-autoencoder reduction could be tested on three-dimensional problems or on systems whose sharp features move or interact.
- Replacing the operator learner with a parametric version might allow the reduced model to handle families of problems without retraining.
- The point cloud metric could be generalized to other localized solution features such as contact lines or material interfaces.
Load-bearing premise
The graph autoencoder learns a latent representation that preserves the essential nonlinear structure of sharp gradients well enough for the operator-learning step to produce accurate long-term predictions.
What would settle it
A new test problem containing sharp gradients in which GNN-LaSDI latent dynamics diverge from the full-order solution over time despite low autoencoder reconstruction error on training data.
Figures













read the original abstract
This study investigates the efficient deployment of graph autoencoders, a class of graph neural networks (GNNs), for model-order reduction (MOR) of high-dimensional dynamical systems. The proposed framework leverages graph autoencoders to perform nonlinear dimensionality reduction, enabling low-dimensional representations of systems characterized by sharp gradients for which conventional linear approximations, such as proper orthogonal decomposition (POD), are inadequate. Specifically, this study introduces graph neural network latent space dynamics identification (GNN-LaSDI). GNN-LaSDI employs an operator learning framework to directly approximate the temporal evolution of the graph autoencoder's latent representation. The performance of GNN-LaSDI is assessed against both geometric deep least-squares Petrov-Galerkin (GD-LSPG and POD latent space dynamics identification (POD-LaSDI), which combines POD-based dimensionality reduction with operator learning. In addition to standard error metrics, this work presents a novel point cloud error metric specifically tailored to evaluate the accuracy of the identified locations of sharp gradients within the solution. The effectiveness of the metric and the proposed MOR framework is demonstrated through two numerical experiments featuring sharp gradients. For the studied problems, GNN-LaSDI incurs a substantially lower computational cost than GD-LSPG, though it remains slightly more computationally expensive than POD-LaSDI. However, GNN-LaSDI achieves significantly greater accuracy than POD-LaSDI, thereby providing a balance between predictive accuracy and computational speedup. Additionally, the results indicate that the proposed point cloud error provides a more intuitive and informative measure of reduced-order model accuracy in regions with sharp gradients than conventional error metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GNN-LaSDI, a model-order reduction framework that uses graph autoencoders for nonlinear dimensionality reduction of high-dimensional dynamical systems featuring sharp gradients, followed by an operator-learning step to identify the latent-space dynamics. It compares GNN-LaSDI against POD-LaSDI and GD-LSPG on two numerical test problems, reporting that GNN-LaSDI achieves substantially higher accuracy than POD-LaSDI while incurring only modestly higher online cost than POD-LaSDI and far lower cost than GD-LSPG. A novel point-cloud error metric is introduced to assess the fidelity of predicted sharp-gradient locations.
Significance. If the accuracy claims hold under the reported conditions, the work would be significant for MOR applications involving discontinuities or moving fronts, where linear bases such as POD are known to be inadequate. The point-cloud metric provides a domain-appropriate evaluation tool that conventional L2 or relative-error norms do not capture. The framework also demonstrates a practical trade-off between nonlinear reduction quality and computational expense.
major comments (2)
- [§3.2, Eq. (8)] §3.2, Eq. (8): The autoencoder loss is defined solely via reconstruction error plus latent regularization; no auxiliary term enforces that the encoder maps the physical location of a discontinuity or front to a consistent (approximately equivariant) latent coordinate. Consequently, small reconstruction errors can produce inconsistent latent trajectories whose long-time integration by the learned operator may not preserve the reported accuracy advantage.
- [Numerical experiments] Numerical experiments section: The accuracy advantage of GNN-LaSDI over POD-LaSDI is asserted via the point-cloud metric, yet the manuscript provides neither error bars across multiple random seeds nor an explicit statement of the data-exclusion or hyper-parameter selection protocol used to generate the tabulated results. Without these, it is impossible to determine whether the claimed superiority is statistically robust or sensitive to the particular realizations shown.
minor comments (2)
- The definition of the point-cloud error metric should be stated explicitly (including the matching threshold and normalization) rather than referred to only by name.
- Figure captions for the solution snapshots should indicate the time instants shown and whether the plotted fields are full-order or reconstructed latent solutions.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the presentation and statistical rigor of the work.
read point-by-point responses
-
Referee: [§3.2, Eq. (8)] §3.2, Eq. (8): The autoencoder loss is defined solely via reconstruction error plus latent regularization; no auxiliary term enforces that the encoder maps the physical location of a discontinuity or front to a consistent (approximately equivariant) latent coordinate. Consequently, small reconstruction errors can produce inconsistent latent trajectories whose long-time integration by the learned operator may not preserve the reported accuracy advantage.
Authors: We appreciate this observation regarding the loss formulation. The graph autoencoder operates on a mesh that explicitly encodes spatial connectivity, and the training snapshots are generated from physics-consistent evolution of the sharp gradients. Consequently, the encoder learns a latent mapping in which front locations vary smoothly and consistently across the dataset, as required for stable operator learning. While an explicit equivariance penalty is not included, the combination of graph structure and data physics provides the necessary consistency, which is reflected in the reported accuracy gains. In the revision we will add a short paragraph in §3.2 clarifying this implicit mechanism and noting that future extensions could incorporate an auxiliary term if needed for other applications. revision: partial
-
Referee: [Numerical experiments] Numerical experiments section: The accuracy advantage of GNN-LaSDI over POD-LaSDI is asserted via the point-cloud metric, yet the manuscript provides neither error bars across multiple random seeds nor an explicit statement of the data-exclusion or hyper-parameter selection protocol used to generate the tabulated results. Without these, it is impossible to determine whether the claimed superiority is statistically robust or sensitive to the particular realizations shown.
Authors: We agree that reporting variability across seeds and documenting the experimental protocol would improve confidence in the results. In the revised manuscript we will (i) repeat all experiments with five independent random seeds, (ii) report means and standard deviations of the point-cloud metric, and (iii) add a dedicated subsection describing the train/validation/test split, hyper-parameter search procedure (grid search with cross-validation), and any data-exclusion rules applied. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines GNN-LaSDI as the combination of a graph autoencoder (with reconstruction + latent regularization loss) followed by operator learning on the latent coordinates, then validates performance via direct numerical comparison to POD-LaSDI and GD-LSPG on two test problems using both standard and point-cloud error metrics. No equation or step reduces a reported prediction or accuracy claim to a fitted parameter by construction, nor does any central premise rest on a self-citation chain that would make the result tautological. The framework is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sirovich, Turbulence and the dynamics of coherent structures part I: coherent structures, Quarterly of Applied Mathematics 45 (3) (1987) 561–571
L. Sirovich, Turbulence and the dynamics of coherent structures part I: coherent structures, Quarterly of Applied Mathematics 45 (3) (1987) 561–571
1987
-
[2]
T. Lieu, C. Farhat, M. Lesoinne, Reduced-order fluid/structure modeling of a complete aircraft configuration, Computer Methods in Applied Mechanics and Engineering 195 (41) (2006) 5730–5742
2006
-
[3]
C. R. Wentland, K. Duraisamy, C. Huang, Scalable projection-based reduced-order models for large multiscale fluid systems, AIAA Journal 61 (10) (2023) 4499–4523
2023
-
[4]
S. A. McQuarrie, C. Huang, K. E. Willcox, Data-driven reduced-order models via regularised operator inference for a single-injector combustion process, Journal of the Royal Society of New Zealand 51 (2) (2021) 194–211
2021
-
[5]
Welper, Interpolation of functions with parameter dependent jumps by transformed snapshots, SIAM Journal on Scientific Computing 39 (4) (2017) A1225–A1250
G. Welper, Interpolation of functions with parameter dependent jumps by transformed snapshots, SIAM Journal on Scientific Computing 39 (4) (2017) A1225–A1250
2017
-
[6]
Peherstorfer, Model reduction for transport-dominated problems via online adaptive bases and adaptive sam- pling, SIAM Journal on Scientific Computing 42 (5) (2020) A2803–A2836
B. Peherstorfer, Model reduction for transport-dominated problems via online adaptive bases and adaptive sam- pling, SIAM Journal on Scientific Computing 42 (5) (2020) A2803–A2836
2020
-
[7]
Peherstorfer, Breaking the Kolmogorov barrier with nonlinear model reduction, Notices of the American Mathematical Society 69 (5) (2022) 725–733
B. Peherstorfer, Breaking the Kolmogorov barrier with nonlinear model reduction, Notices of the American Mathematical Society 69 (5) (2022) 725–733
2022
-
[8]
Barnett, C
J. Barnett, C. Farhat, Quadratic approximation manifold for mitigating the Kolmogorov barrier in nonlinear projection-based model order reduction, Journal of Computational Physics (2022) 111348
2022
-
[9]
Geelen, S
R. Geelen, S. Wright, K. Willcox, Operator inference for non-intrusive model reduction with quadratic mani- folds, Computer Methods in Applied Mechanics and Engineering 403 (2023) 115717
2023
-
[10]
Barnett, C
J. Barnett, C. Farhat, Y . Maday, Neural-network-augmented projection-based model order reduction for mitigat- ing the Kolmogorov barrier to reducibility, Journal of Computational Physics 492 (2023) 112420
2023
-
[11]
Ares de Parga, R
S. Ares de Parga, R. Tezaur, C. G. Hernández, C. Farhat, Nonlinear projection-based model order reduction with machine learning regression for closure error modeling in the latent space, Computer Methods in Applied Mechanics and Engineering 448 (2026) 118443. 24
2026
-
[12]
J. Guo, D. Xiao, Nonlinear model reduction by probabilistic manifold decomposition, SIAM Journal on Scien- tific Computing 48 (1) (2026) A209–A235
2026
-
[13]
K. Lee, K. T. Carlberg, Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders, Journal of Computational Physics 404 (2020) 108973
2020
-
[14]
K. Lee, K. T. Carlberg, Deep conservation: A latent-dynamics model for exact satisfaction of physical conser- vation laws, in: Proceedings of the AAAI Conference on Artificial Intelligence, V ol. 35, 2021, pp. 277–285
2021
-
[15]
Magargal, P
L. Magargal, P. Khodabakhshi, S. Rodriguez, J. Jaworski, J. Michopoulos, Projection-based model-order reduc- tion via graph autoencoders suited for unstructured meshes, Data-Centric Engineering 6 (2025) e52
2025
-
[16]
Wiewel, M
S. Wiewel, M. Becher, N. Thuerey, Latent space physics: Towards learning the temporal evolution of fluid flow, Computer Graphics Forum 38 (2) (2019) 71–82
2019
-
[17]
Fresca, L
S. Fresca, L. Dede, A. Manzoni, A comprehensive deep learning-based approach to reduced order modeling of nonlinear time-dependent parametrized PDEs, Journal of Scientific Computing 87 (2) (2021) 1–36
2021
-
[18]
R. Fu, D. Xiao, I. Navon, F. Fang, L. Yang, C. Wang, S. Cheng, A non-linear non-intrusive reduced order model of fluid flow by auto-encoder and self-attention deep learning methods, International Journal for Numerical Methods in Engineering 124 (13) (2023) 3087–3111
2023
-
[19]
R. Fu, D. Xiao, A. Buchan, X. Lin, Y . Feng, G. Dong, A parametric non-linear non-intrusive reduce-order model using deep transfer learning, Computer Methods in Applied Mechanics and Engineering 438 (2025) 117807
2025
-
[20]
Bui-Thanh, K
T. Bui-Thanh, K. Willcox, O. Ghattas, Model reduction for large-scale systems with high-dimensional paramet- ric input space, SIAM Journal on Scientific Computing 30 (6) (2008) 3270–3288
2008
-
[21]
Carlberg, C
K. Carlberg, C. Bou-Mosleh, C. Farhat, Efficient non-linear model reduction via a least-squares Petrov–Galerkin projection and compressive tensor approximations, International Journal for Numerical Methods in Engineering 86 (2) (2011) 155–181
2011
-
[22]
Carlberg, M
K. Carlberg, M. Barone, H. Antil, Galerkin v. least-squares Petrov-Galerkin projection in nonlinear model re- duction, Journal of Computational Physics 330 (2017) 693–734
2017
-
[23]
L. K. Magargal, P. Khodabakhshi, S. N. Rodriguez, Hyper-reduction-free reduced-order newton solvers for projection-based model-order reduction of nonlinear dynamical systems, Engineering with Computers 42 (2026) 133
2026
-
[24]
E. J. Parish, C. R. Wentland, K. Duraisamy, The adjoint Petrov–Galerkin method for non-linear model reduction, Computer Methods in Applied Mechanics and Engineering 365 (2020) 112991
2020
-
[25]
Antoulas, Approximation of large-scale dynamical systems, Society for Industrial and Applied Mathematics, Philadelphia, PA, 2009
A. Antoulas, Approximation of large-scale dynamical systems, Society for Industrial and Applied Mathematics, Philadelphia, PA, 2009
2009
-
[26]
Barrault, Y
M. Barrault, Y . Maday, N. C. Nguyen, A. T. Patera, An ‘empirical interpolation’ method: application to efficient reduced-basis discretization of partial differential equations, Comptes Rendus Mathematique 339 (9) (2004) 667–672
2004
-
[27]
Chaturantabut, D
S. Chaturantabut, D. C. Sorensen, Nonlinear model reduction via discrete empirical interpolation, SIAM Journal on Scientific Computing 32 (5) (2010) 2737–2764
2010
-
[28]
Drmac, S
Z. Drmac, S. Gugercin, A new selection operator for the discrete empirical interpolation method—improved a priori error bound and extensions, SIAM Journal on Scientific Computing 38 (2) (2016) A631–A648
2016
-
[29]
Carlberg, C
K. Carlberg, C. Farhat, J. Cortial, D. Amsallem, The GNAT method for nonlinear model reduction: effective implementation and application to computational fluid dynamics and turbulent flows, Journal of Computational Physics 242 (2013) 623–647. 25
2013
-
[30]
Farhat, T
C. Farhat, T. Chapman, P. Avery, Structure-preserving, stability, and accuracy properties of the energy- conserving sampling and weighting method for the hyper reduction of nonlinear finite element dynamic models, International Journal for Numerical Methods in Engineering 102 (5) (2015) 1077–1110
2015
-
[31]
P. J. Schmid, Dynamic mode decomposition of numerical and experimental data, Journal of Fluid Mechanics 656 (2010) 5–28
2010
-
[32]
Peherstorfer, K
B. Peherstorfer, K. Willcox, Data-driven operator inference for nonintrusive projection-based model reduction, Computer Methods in Applied Mechanics and Engineering 306 (2016) 196–215
2016
-
[33]
S. A. McQuarrie, P. Khodabakhshi, K. E. Willcox, Nonintrusive reduced-order models for parametric partial differential equations via data-driven operator inference, SIAM Journal on Scientific Computing 45 (4) (2023) A1917–A1946
2023
-
[34]
C. Gu, Qlmor: A projection-based nonlinear model order reduction approach using quadratic-linear represen- tation of nonlinear systems, IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 30 (9) (2011) 1307–1320
2011
-
[35]
Kramer, K
B. Kramer, K. E. Willcox, Nonlinear model order reduction via lifting transformations and proper orthogonal decomposition, AIAA journal 57 (6) (2019) 2297–2307
2019
-
[36]
E. Qian, B. Kramer, B. Peherstorfer, K. Willcox, Lift & Learn: physics-informed machine learning for large- scale nonlinear dynamical systems, Physica D: Nonlinear Phenomena 406 (2020) 132401
2020
-
[37]
Swischuk, B
R. Swischuk, B. Kramer, C. Huang, K. Willcox, Learning physics-based reduced-order models for a single- injector combustion process, AIAA Journal 58 (6) (2020) 2658–2672
2020
-
[38]
Khodabakhshi, K
P. Khodabakhshi, K. E. Willcox, Non-intrusive data-driven model reduction for differential–algebraic equations derived from lifting transformations, Computer Methods in Applied Mechanics and Engineering 389 (2022) 114296
2022
-
[39]
W. D. Fries, X. He, Y . Choi, Lasdi: Parametric latent space dynamics identification, Computer Methods in Applied Mechanics and Engineering 399 (2022) 115436
2022
-
[40]
X. He, Y . Choi, W. D. Fries, J. L. Belof, J.-S. Chen, gLaSDI: Parametric physics-informed greedy latent space dynamics identification, Journal of Computational Physics 489 (2023) 112267
2023
-
[41]
Qian, I.-G
E. Qian, I.-G. Farcas, K. Willcox, Reduced operator inference for nonlinear partial differential equations, SIAM Journal on Scientific Computing 44 (4) (2022) A1934–A1959
2022
-
[42]
Karypis, V
G. Karypis, V . Kumar, Multilevel k-way partitioning scheme for irregular graphs, Journal of Parallel and Dis- tributed Computing (1998)
1998
-
[43]
Barwey, V
S. Barwey, V . Shankar, V . Viswanathan, R. Maulik, Multiscale graph neural network autoencoders for inter- pretable scientific machine learning, Journal of Computational Physics 495 (2023) 112537
2023
-
[44]
T. Tran, L. Magargal, P. Khodabakhshi, Scalable node clustering for graph autoencoders used in model-order reduction, in: AIAA SCITECH 2026 Forum, 2026
2026
-
[45]
Magargal, S
L. Magargal, S. Moreno-Rivera, P. Khodabakhshi, Topology-inspired clustering hierarchy for graph autoen- coders via spectral graph theory, in: AIAA SCITECH 2026 Forum, 2026
2026
-
[46]
Hamilton, Z
W. Hamilton, Z. Ying, J. Leskovec, Inductive representation learning on large graphs, Advances in Neural Infor- mation Processing Systems 30 (2017)
2017
-
[47]
Y . Kim, Y . Choi, D. Widemann, T. Zohdi, A fast and accurate physics-informed neural network reduced order model with shallow masked autoencoder, Journal of Computational Physics 451 (2022) 110841. 26
2022
-
[48]
S. L. Brunton, J. L. Proctor, J. N. Kutz, Discovering governing equations from data by sparse identification of nonlinear dynamical systems, Proceedings of the national academy of sciences 113 (15) (2016) 3932–3937
2016
-
[49]
M. R. Chmiel, J. Barnett, C. Farhat, Unified LSPG model reduction framework and assessment for hypersonic computational fluid dynamics, AIAA Journal 63 (1) (2025) 72–90
2025
-
[50]
Geelen, K
R. Geelen, K. Willcox, Localized non-intrusive reduced-order modelling in the operator inference framework, Philosophical Transactions of the Royal Society A 380 (2229) (2022) 20210206
2022
-
[51]
Cucchiara, A
S. Cucchiara, A. Iollo, T. Taddei, H. Telib, Model order reduction by convex displacement interpolation, Journal of Computational Physics 514 (2024) 113230
2024
-
[52]
Canny, A computational approach to edge detection, Pattern Analysis and Machine Intelligence, IEEE Trans- actions on PAMI-8 (1986) 679 – 698
J. Canny, A computational approach to edge detection, Pattern Analysis and Machine Intelligence, IEEE Trans- actions on PAMI-8 (1986) 679 – 698
1986
-
[53]
Ducros, V
F. Ducros, V . Ferrand, F. Nicoud, C. Weber, D. Darracq, C. Gacherieu, T. Poinsot, Large-eddy simulation of the shock/turbulence interaction, Journal of Computational Physics 152 (2) (1999) 517–549
1999
-
[54]
R. T. Rockafellar, R. J. Wets, Variational analysis, Springer
-
[55]
A. A. Taha, A. Hanbury, An efficient algorithm for calculating the exact Hausdorffdistance, IEEE Transactions on Pattern Analysis and Machine Intelligence 37 (11) (2015) 2153–2163
2015
-
[56]
Kobayashi, Modeling and numerical simulations of dendritic crystal growth, Physica D: Nonlinear Phenom- ena 63 (3) (1993) 410–423
R. Kobayashi, Modeling and numerical simulations of dendritic crystal growth, Physica D: Nonlinear Phenom- ena 63 (3) (1993) 410–423
1993
-
[57]
Nishikawa, K
H. Nishikawa, K. Kitamura, Very simple, carbuncle-free, boundary-layer-resolving, rotated-hybrid Riemann solvers, Journal of Computational Physics 227 (4) (2008) 2560–2581
2008
-
[58]
Modesti, S
D. Modesti, S. Pirozzoli, A low-dissipative solver for turbulent compressible flows on unstructured meshes, with OpenFOAM implementation, Computers & Fluids 152 (2017) 14–23
2017
-
[59]
Tibshirani, Regression shrinkage and selection via the lasso, Journal of the Royal Statistical Society Series B: Statistical Methodology 58 (1) (1996) 267–288
R. Tibshirani, Regression shrinkage and selection via the lasso, Journal of the Royal Statistical Society Series B: Statistical Methodology 58 (1) (1996) 267–288
1996
-
[60]
Maulik, B
R. Maulik, B. Lusch, P. Balaprakash, Reduced-order modeling of advection-dominated systems with recurrent neural networks and convolutional autoencoders, Physics of Fluids 33 (3) (2021) 037106
2021
-
[61]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al., Pytorch: an imperative style, high-performance deep learning library, Advances in Neural Information Processing Systems 32 (2019)
2019
-
[62]
M. Fey, J. E. Lenssen, Fast graph representation learning with PyTorch Geometric, arXiv preprint arXiv:1903.02428 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[63]
Glorot, Y
X. Glorot, Y . Bengio, Understanding the difficulty of training deep feedforward neural networks, in: Proceed- ings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, 2010, pp. 249–256
2010
-
[64]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[65]
Clevert, T
D.-A. Clevert, T. Unterthiner, S. Hochreiter, Fast and accurate deep network learning by exponential linear units (ELUs), in: International Conference on Learning Representations (ICLR), 2016
2016
-
[66]
C. R. Harris, K. J. Millman, S. J. van der Walt, R. Gommers, P. Virtanen, D. Cournapeau, E. Wieser, J. Taylor, S. Berg, N. J. Smith, R. Kern, M. Picus, S. Hoyer, M. H. van Kerkwijk, M. Brett, A. Haldane, J. F. del Río, M. Wiebe, P. Peterson, P. Gérard-Marchant, K. Sheppard, T. Reddy, W. Weckesser, H. Abbasi, C. Gohlke, T. E. Oliphant, Array programming wi...
2020
-
[67]
Virtanen, R
P. Virtanen, R. Gommers, T. E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright, S. J. van der Walt, M. Brett, J. Wilson, K. J. Millman, N. Mayorov, A. R. J. Nelson, E. Jones, R. Kern, E. Larson, C. J. Carey,˙I. Polat, Y . Feng, E. W. Moore, J. VanderPlas, D. Laxalde, J. Perktold, R. Cimrman, I. Henriksen,...
2020
-
[68]
# of MP operations
S. K. Lam, A. Pitrou, S. Seibert, Numba: A LLVM-based Python JIT compiler, in: Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, 2015, pp. 1–6. Appendix A. Fundamentals of Geometric deep least-squares Petrov-Galerkin The deep LSPG framework [13] employed a nonlinear manifold LSPG projection using a CNN-based autoen- coder. Whi...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.