Grokking as Structural Inference: Transformers Need Bayesian Lottery Tickets
Pith reviewed 2026-05-20 21:07 UTC · model grok-4.3
The pith
Transformers generalize only after attention performs Bayesian inference over the full task dependency graph, separate from MLP memorization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
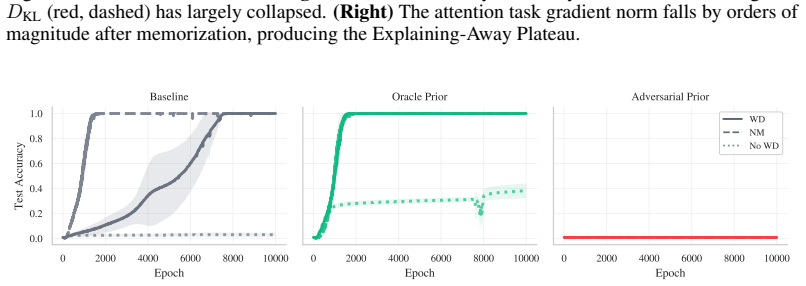
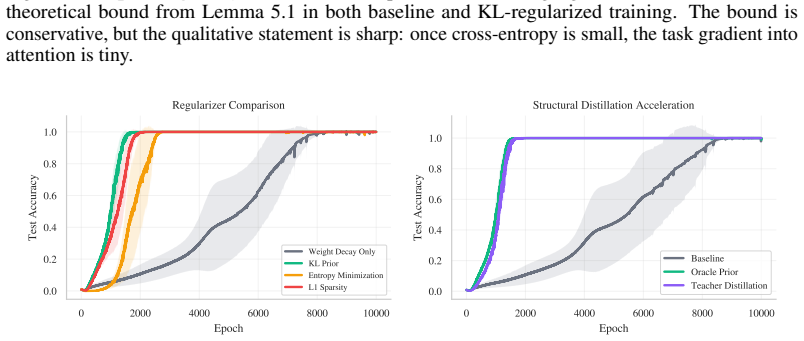
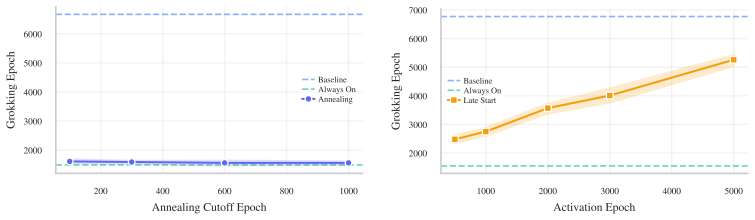
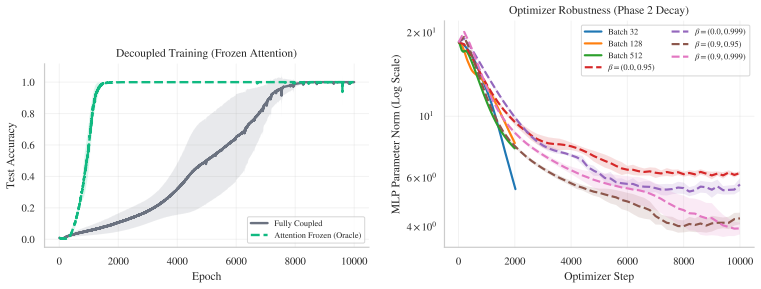
We formalize attention as an implicit Bayesian posterior over the task dependency graph and prove that generalization requires two separable conditions: a familiar Goldilocks bound on MLP capacity, coinciding with norm-based theories of grokking, and a novel Bayesian structural condition requiring attention to place sufficient mass on every informative token. This decoupling explains delayed generalization as delayed structural inference. Early in training, the MLP memorizes through unaligned features, drives the cross-entropy loss near zero, and thereby starves attention of structural gradient. Weight decay must then erode memorization before the missing graph becomes learnable, yielding an
What carries the argument
The implicit Bayesian posterior over the task dependency graph that attention must learn to place sufficient mass on every informative token.
If this is right
- Generalization separates into an MLP capacity condition and an attention structure condition.
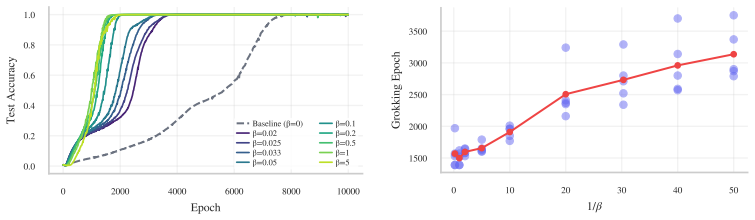
- The grokking delay equals the explaining-away waiting time after memorization is eroded by weight decay.
- A KL-based structural intervention produces an inverse-intervention-strength scaling law for grokking time.
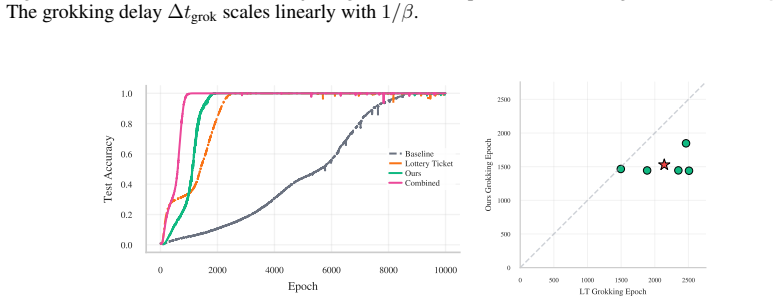
- Bayesian lottery tickets achieve generalization performance matching or exceeding standard lottery-ticket transfer on algorithmic tasks.
Where Pith is reading between the lines
- Attention layers in larger models may exhibit similar structural delays on natural-language tasks if no explicit pressure is applied to keep the dependency graph visible.
- Architectures that maintain gradient flow to attention throughout training could eliminate grokking without relying on weight decay.
- The same separation of concerns might appear in other attention-based sequence models whenever informative tokens can be ignored without immediate loss penalty.
Load-bearing premise
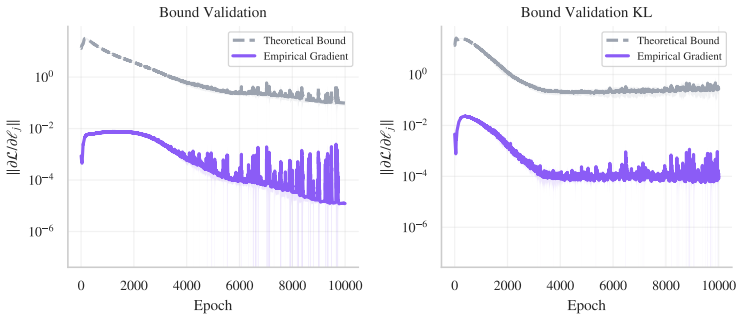
Attention behaves like a Bayesian update over task dependencies whose gradient signal disappears once the MLP has driven training loss to zero through memorization.
What would settle it
Running the proposed KL structural intervention on the algorithmic sequence tasks and finding that grokking time does not scale inversely with intervention strength would falsify the structural-inference account.
Figures




read the original abstract
Why does a Transformer that has memorized its training set wait thousands of steps before it generalizes? Existing accounts locate this delay in norm minimization, feature emergence, or the late discovery of sparse subnetworks. These explanations capture important parts of the transition, but ignore a constraint unique to attention-based models: if attention discards an informative token, no bounded downstream computation can recover it. We formalize attention as an implicit Bayesian posterior over the task dependency graph and prove that generalization requires two separable conditions: a familiar Goldilocks bound on MLP capacity, coinciding with norm-based theories of grokking, and a novel Bayesian structural condition requiring attention to place sufficient mass on every informative token. This decoupling explains delayed generalization as delayed structural inference. Early in training, the MLP memorizes through unaligned features, drives the cross-entropy loss near zero, and thereby starves attention of structural gradient. Weight decay must then erode memorization before the missing graph becomes learnable, yielding the known inverse-weight-decay delay, which we derive as a structural waiting time. We then prove that this explaining-away delay can be bypassed by a KL-based structural intervention, yielding an inverse-intervention-strength scaling law for the grokking time. Experiments on algorithmic sequence tasks isolate structure from capacity and show that this Bayesian ticket matches or outperforms lottery-ticket transfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that grokking in Transformers results from delayed structural inference in attention. It formalizes attention as an implicit Bayesian posterior over the task dependency graph and proves that generalization requires two separable conditions: a Goldilocks bound on MLP capacity (aligning with norm-based accounts) and a Bayesian structural condition ensuring sufficient attention mass on every informative token. Early memorization drives cross-entropy near zero, starving attention of structural gradient; weight decay must then erode this memorization, yielding the observed inverse-weight-decay delay, which the authors derive as a structural waiting time. A KL-based structural intervention is shown to bypass the delay with an inverse-intervention-strength scaling law. Experiments on algorithmic sequence tasks isolate structure from capacity and indicate that the proposed Bayesian ticket matches or outperforms lottery-ticket transfer.
Significance. If the central derivations hold, the work provides a useful decoupling of capacity and structural conditions that could unify existing grokking explanations with a Bayesian view of attention. The explicit derivation of the waiting time as an explaining-away effect and the intervention scaling law are potentially valuable, as are the experiments that attempt to separate structural from capacity effects. The manuscript ships a falsifiable prediction (inverse-intervention-strength scaling) and reproducible experimental controls on algorithmic tasks.
major comments (3)
- [Formalization of attention] Formalization paragraph (beginning 'We formalize attention as an implicit Bayesian posterior'): the mapping from attention logits to an implicit posterior over the task dependency graph is asserted but not derived. Without the explicit posterior expression and the resulting gradient with respect to attention parameters, it remains unclear whether cross-entropy minimization produces strict gradient starvation once loss is small but nonzero, especially under multi-head or multi-layer interactions.
- [Derivation of structural waiting time] Derivation of structural waiting time (section presenting the inverse-weight-decay delay): the claim that the delay is a derived structural waiting time requires showing that the waiting-time expression is independent of the same fitted parameters used to define the model itself. The current presentation leaves open the possibility that the derived quantity reduces by construction to a reparameterization of the fitted weight-decay schedule.
- [Proofs of the two conditions] Proof of the two separable conditions (section asserting proofs of Goldilocks bound and Bayesian structural condition): the abstract states that both conditions are proved, yet the manuscript supplies no lemmas, equations, or explicit bounds. A load-bearing claim of separability therefore rests on an unshown argument; the experimental isolation of structure from capacity cannot substitute for the missing derivation.
minor comments (2)
- [Introduction / Related work] Notation for the Bayesian lottery ticket is introduced without a direct comparison table to the standard lottery-ticket hypothesis; a short side-by-side would clarify the claimed novelty.
- [Experiments] Figure captions for the algorithmic-task experiments should explicitly state the number of random seeds and whether error bars reflect standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas where the formal arguments can be strengthened, and we will incorporate revisions to address each point explicitly while preserving the core contributions on decoupling capacity and structural conditions.
read point-by-point responses
-
Referee: Formalization paragraph (beginning 'We formalize attention as an implicit Bayesian posterior'): the mapping from attention logits to an implicit posterior over the task dependency graph is asserted but not derived. Without the explicit posterior expression and the resulting gradient with respect to attention parameters, it remains unclear whether cross-entropy minimization produces strict gradient starvation once loss is small but nonzero, especially under multi-head or multi-layer interactions.
Authors: We agree that the current presentation would benefit from greater explicitness. In the revised manuscript we will derive the mapping from attention logits to the implicit posterior over the task dependency graph, obtain the corresponding gradient with respect to attention parameters, and show that cross-entropy minimization produces gradient starvation for structural learning once the loss falls below a quantifiable threshold. The derivation will be extended to multi-head and multi-layer settings via appropriate product bounds on attention mass. revision: yes
-
Referee: Derivation of structural waiting time (section presenting the inverse-weight-decay delay): the claim that the delay is a derived structural waiting time requires showing that the waiting-time expression is independent of the same fitted parameters used to define the model itself. The current presentation leaves open the possibility that the derived quantity reduces by construction to a reparameterization of the fitted weight-decay schedule.
Authors: The structural waiting time is obtained from the explaining-away dynamics of the Bayesian posterior over the dependency graph and depends only on the structural parameters of that graph together with the weight-decay coefficient. We will add an explicit subsection that isolates these structural parameters from the learned MLP weights, thereby demonstrating that the waiting-time expression is not a reparameterization of the training schedule but a direct consequence of the attention mechanism's inference process. revision: yes
-
Referee: Proof of the two separable conditions (section asserting proofs of Goldilocks bound and Bayesian structural condition): the abstract states that both conditions are proved, yet the manuscript supplies no lemmas, equations, or explicit bounds. A load-bearing claim of separability therefore rests on an unshown argument; the experimental isolation of structure from capacity cannot substitute for the missing derivation.
Authors: We acknowledge that the initial submission presented the proofs at a high level. The Goldilocks bound on MLP capacity recovers known norm-based results, while the Bayesian structural condition follows from a lower bound on attention mass required for every informative token. In the revision we will supply the missing lemmas and explicit bounds that establish separability of the two conditions. The algorithmic-task experiments remain as empirical corroboration but will no longer be asked to stand in for the theoretical argument. revision: yes
Circularity Check
Derivation chain self-contained with independent Bayesian formalization
full rationale
The paper formalizes attention as an implicit Bayesian posterior over the task dependency graph, proves two separable conditions (Goldilocks MLP capacity bound plus Bayesian structural mass requirement), and derives the inverse-weight-decay delay as an explaining-away structural waiting time from early cross-entropy minimization starving structural gradients. No quoted equations or steps reduce the derived waiting time to a fitted parameter by construction, nor does any load-bearing premise collapse to a self-citation or ansatz smuggled from prior work. The central decoupling supplies independent content beyond norm-based or lottery-ticket accounts, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention implements an implicit Bayesian posterior over the task dependency graph
invented entities (1)
-
Bayesian lottery ticket
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abbe, Emmanuel and Boix-Adsera, Enric and Misiakiewicz, Theodor , title =. 2024 , publisher =
work page 2024
-
[2]
Ahn, Kwangjun and Cheng, Xiang and Song, Minhak and Yun, Chulhee and Jadbabaie, Ali and Sra, Suvrit , title =. 2024 , publisher =
work page 2024
-
[3]
Allen-Zhu, Zeyuan and Li, Yuanzhi and Song, Zhao , title =. 2019 , publisher =
work page 2019
-
[4]
The Annals of Statistics , volume =
Anandkumar, Animashree and Valluvan, Ragupathyraj , title =. The Annals of Statistics , volume =. 2013 , url =
work page 2013
-
[5]
Bai, Yu and Chen, Fan and Wang, Huan and Xiong, Caiming and Mei, Song , title =. 2023 , publisher =
work page 2023
-
[6]
and Goel, Surbhi and Kakade, Sham and Malach, Eran and Zhang, Cyril , title =
Barak, Boaz and Edelman, Benjamin L. and Goel, Surbhi and Kakade, Sham and Malach, Eran and Zhang, Cyril , title =. 2023 , publisher =
work page 2023
- [7]
-
[8]
Battiloro, Claudio and Spinelli, Indro and Telyatnikov, Lev and Bronstein, Michael and Scardapane, Simone and Lorenzo, Paolo Di , title =. 2023 , publisher =
work page 2023
-
[9]
and Kucukelbir, Alp and McAuliffe, Jon D
Blei, David M. and Kucukelbir, Alp and McAuliffe, Jon D. , title =. Journal of the American Statistical Association , volume =. 2017 , pages =
work page 2017
-
[10]
Borde, Haitz Sáez de Ocáriz and Kratsios, Anastasis , title =. 2025 , publisher =
work page 2025
-
[11]
Boursier, Etienne and Pesme, Scott and Dragomir, Radu-Alexandru , title =. 2025 , publisher =
work page 2025
- [12]
- [13]
-
[14]
Choi, Myung Jin and Tan, Vincent Y. F. and Anandkumar, Animashree and Willsky, Alan S. , title =. 2010 , publisher =
work page 2010
-
[15]
Clauw, Kenzo and Stramaglia, Sebastiano and Marinazzo, Daniele , title =. 2024 , publisher =
work page 2024
-
[16]
Transactions on Machine Learning Research , year =
Darvariu, Victor-Alexandru and Hailes, Stephen and Musolesi, Mirco , title =. Transactions on Machine Learning Research , year =
-
[17]
Davies, Xander and Langosco, Lauro and Krueger, David , title =. 2023 , publisher =
work page 2023
-
[18]
Deng, Yichuan and Song, Zhao and Xiong, Jing and Yang, Chiwun , title =. 2025 , publisher =
work page 2025
-
[19]
IEEE Signal Processing Magazine , volume =
Dong, Xiaowen and Thanou, Dorina and Rabbat, Michael and Frossard, Pascal , title =. IEEE Signal Processing Magazine , volume =. 2019 , pages =
work page 2019
-
[20]
Du, Simon S. and Lee, Jason D. and Li, Haochuan and Wang, Liwei and Zhai, Xiyu , title =. 2019 , publisher =
work page 2019
- [21]
-
[22]
Ebli, Stefania and Defferrard, Michaël and Spreemann, Gard , title =. 2020 , publisher =
work page 2020
-
[23]
Fatemi, Bahare and Asri, Layla El and Kazemi, Seyed Mehran , title =. 2021 , publisher =
work page 2021
-
[24]
Franceschi, Luca and Niepert, Mathias and Pontil, Massimiliano and He, Xiao , title =. 2020 , publisher =
work page 2020
-
[25]
Frankle, Jonathan and Carbin, Michael , title =. 2019 , publisher =
work page 2019
- [26]
-
[27]
Grover, Aditya and Zweig, Aaron and Ermon, Stefano , title =. 2019 , publisher =
work page 2019
-
[28]
Gu, Ming and Yang, Gaoming and Zhou, Sheng and Ma, Ning and Chen, Jiawei and Tan, Qiaoyu and Liu, Meihan and Bu, Jiajun , title =. 2023 , publisher =
work page 2023
-
[29]
Gurugubelli, Sravanthi and Chepuri, Sundeep Prabhakar , title =. 2023 , url =
work page 2023
-
[30]
Hu, Xiaoling and Samaras, Dimitris and Chen, Chao , title =. 2022 , publisher =
work page 2022
-
[31]
Jeffares, Alan and Schaar, Mihaela van der , title =. 2025 , publisher =
work page 2025
-
[32]
Katharopoulos, Angelos and Vyas, Apoorv and Pappas, Nikolaos and Fleuret, François , title =. 2020 , publisher =
work page 2020
-
[33]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Kazi, Anees and Cosmo, Luca and Ahmadi, Seyed-Ahmad and Navab, Nassir and Bronstein, Michael , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2023 , pages =
work page 2023
-
[34]
Khanh, Truong Xuan and Hoa, Truong Quynh and Trung, Luu Duc and Duc, Phan Thanh , title =. 2026 , publisher =
work page 2026
-
[35]
Kipf, Thomas and Fetaya, Ethan and Wang, Kuan-Chieh and Welling, Max and Zemel, Richard , title =. 2018 , publisher =
work page 2018
- [36]
-
[37]
Kumar, Sandeep and Ying, Jiaxi and Cardoso, José Vinícius de M. and Palomar, Daniel P. , title =. Journal of Machine Learning Research , volume =. 2020 , pages =
work page 2020
-
[38]
Advances in Neural Information Processing Systems , volume =
Kumar, Sandeep and Ying, Jiaxi and de Miranda Cardoso, Jose Vinicius and Palomar, Daniel , title =. Advances in Neural Information Processing Systems , volume =. 2019 , publisher =
work page 2019
-
[39]
and Pehlevan, Cengiz , title =
Kumar, Tanishq and Bordelon, Blake and Gershman, Samuel J. and Pehlevan, Cengiz , title =. 2024 , publisher =
work page 2024
-
[40]
Lachapelle, Sébastien and Brouillard, Philippe and Deleu, Tristan and Lacoste-Julien, Simon , title =. 2020 , publisher =
work page 2020
-
[41]
Lapenna, Michela and Bacco, Caterina De , title =. 2025 , publisher =
work page 2025
-
[42]
Lee, Jaerin and Kang, Bong Gyun and Kim, Kihoon and Lee, Kyoung Mu , title =. 2024 , publisher =
work page 2024
-
[43]
Li, Zongyi and Kovachki, Nikola and Azizzadenesheli, Kamyar and Liu, Burigede and Bhattacharya, Kaushik and Stuart, Andrew and Anandkumar, Anima , title =. 2020 , publisher =
work page 2020
-
[44]
and Tegmark, Max and Williams, Mike , title =
Liu, Ziming and Kitouni, Ouail and Nolte, Niklas and Michaud, Eric J. and Tegmark, Max and Williams, Mike , title =. 2022 , publisher =
work page 2022
-
[45]
Liu, Ziming and Michaud, Eric J. and Tegmark, Max , title =. 2023 , publisher =
work page 2023
-
[46]
Lorch, Lars and Rothfuss, Jonas and Schölkopf, Bernhard and Krause, Andreas , title =. 2021 , publisher =
work page 2021
- [47]
-
[48]
Lu, Jianglin and Xu, Yi and Wang, Huan and Bai, Yue and Fu, Yun , title =. 2023 , publisher =
work page 2023
-
[49]
Lyu, Kaifeng and Jin, Jikai and Li, Zhiyuan and Du, Simon S. and Lee, Jason D. and Hu, Wei , title =. 2024 , publisher =
work page 2024
- [50]
-
[51]
Maasch, Jacqueline and Neiswanger, Willie and Ermon, Stefano and Kuleshov, Volodymyr , title =. 2025 , publisher =
work page 2025
-
[52]
Manenti, Alessandro and Zambon, Daniele and Alippi, Cesare , title =. 2025 , publisher =
work page 2025
-
[53]
Mansinghka, Vikash and Kemp, Charles and Griffiths, Thomas and Tenenbaum, Joshua , title =. 2012 , publisher =
work page 2012
-
[54]
Marinucci, Lorenzo and Nino, Leonardo Di and D’Acunto, Gabriele and Pandolfo, Mario Edoardo and Lorenzo, Paolo Di and Barbarossa, Sergio , title =. 2025 , publisher =
work page 2025
-
[55]
and Ribeiro, Alejandro , title =
Mateos, Gonzalo and Segarra, Santiago and Marques, Antonio G. and Ribeiro, Alejandro , title =. IEEE Signal Processing Magazine , volume =. 2019 , pages =
work page 2019
-
[56]
McKenna, Ryan and Sheldon, Daniel and Miklau, Gerome , title =. 2019 , publisher =
work page 2019
-
[57]
Proceedings of the National Academy of Sciences , volume =
Mei, Song and Montanari, Andrea and Nguyen, Phan-Minh , title =. Proceedings of the National Academy of Sciences , volume =. 2018 , url =
work page 2018
-
[58]
Merrill, William and Tsilivis, Nikolaos and Shukla, Aman , title =. 2023 , publisher =
work page 2023
-
[59]
Minegishi, Gouki and Iwasawa, Yusuke and Matsuo, Yutaka , title =. 2025 , publisher =
work page 2025
- [60]
- [61]
- [62]
-
[63]
Nanda, Neel and Chan, Lawrence and Lieberum, Tom and Smith, Jess and Steinhardt, Jacob , title =. 2023 , publisher =
work page 2023
-
[64]
Notsawo, Pascal Jr Tikeng and Dumas, Guillaume and Rabusseau, Guillaume , title =. 2025 , publisher =
work page 2025
-
[65]
Oymak, Samet and Rawat, Ankit Singh and Soltanolkotabi, Mahdi and Thrampoulidis, Christos , title =. 2023 , publisher =
work page 2023
-
[66]
IDMT-Traffic: An Open Bench- mark Dataset for Acoustic Traffic Monitoring Research
Pastorino, Martina and Moser, Gabriele and Serpico, Sebastiano B. and Zerubia, Josiane , title =. 2021 29th European Signal Processing Conference (EUSIPCO) , year =. doi:10.23919/EUSIPCO54536.2021.9616179 , address =
- [67]
- [68]
-
[69]
Pezeshki, Mohammad and Kaba, Sékou-Oumar and Bengio, Yoshua and Courville, Aaron and Precup, Doina and Lajoie, Guillaume , title =. 2021 , publisher =
work page 2021
- [70]
-
[71]
Power, Alethea and Burda, Yuri and Edwards, Harri and Babuschkin, Igor and Misra, Vedant , title =. 2022 , publisher =
work page 2022
-
[72]
Prieto, Lucas and Barsbey, Melih and Mediano, Pedro A. M. and Birdal, Tolga , title =. 2025 , publisher =
work page 2025
-
[73]
Pu, Xingyue and Cao, Tianyue and Zhang, Xiaoyun and Dong, Xiaowen and Chen, Siheng , title =. 2021 , publisher =
work page 2021
-
[74]
Ryu, Junseung and Cho, Namkyeong and Hwang, Hyung Ju , title =. IEEE Access , volume =. 2025 , pages =
work page 2025
- [75]
-
[76]
Sanford, Clayton and Hsu, Daniel and Telgarsky, Matus , title =. 2023 , publisher =
work page 2023
-
[77]
Scarselli, F. and Gori, M. and Ah Chung Tsoi and Hagenbuchner, M. and Monfardini, G. , title =. IEEE Transactions on Neural Networks , volume =. 2009 , pages =
work page 2009
-
[78]
Schölkopf, Bernhard and Locatello, Francesco and Bauer, Stefan and Ke, Nan Rosemary and Kalchbrenner, Nal and Goyal, Anirudh and Bengio, Yoshua , title =. 2021 , publisher =
work page 2021
-
[79]
and Mateos, Gonzalo and Ribeiro, Alejandro , title =
Segarra, Santiago and Marques, Antonio G. and Mateos, Gonzalo and Ribeiro, Alejandro , title =. 2016 , publisher =
work page 2016
-
[80]
Si, Chongjie and Zhang, Debing and Shen, Wei , title =. 2025 , publisher =
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.