Learning Dynamic Structural Specialization for Underwater Salient Object Detection
Pith reviewed 2026-05-19 14:20 UTC · model grok-4.3
pith:6TQOLQGU Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{6TQOLQGU}
Prints a linked pith:6TQOLQGU badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Dynamic structural specialization enhances underwater salient object detection by coordinating boundary and region features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that dynamically specializing a shared representation into boundary-sensitive and region-coherent structural features, coordinated by a spatial module according to local context, allows for more accurate localization, coherent regions, and precise boundaries in underwater salient object detection despite image degradations.
What carries the argument
dynamic structural specialization, which decomposes shared features into boundary-sensitive and region-coherent branches regulated by a spatial coordination module
Load-bearing premise
That decomposing the shared base representation into boundary-sensitive and region-coherent branches and regulating them with a spatial coordination module will correct inaccurate localization, fragmented regions, and coarse boundaries caused by underwater degradations.
What would settle it
Observing no improvement in boundary accuracy or region coherence when the spatial coordination or branch decomposition is removed in controlled experiments on degraded underwater images.
Figures








read the original abstract
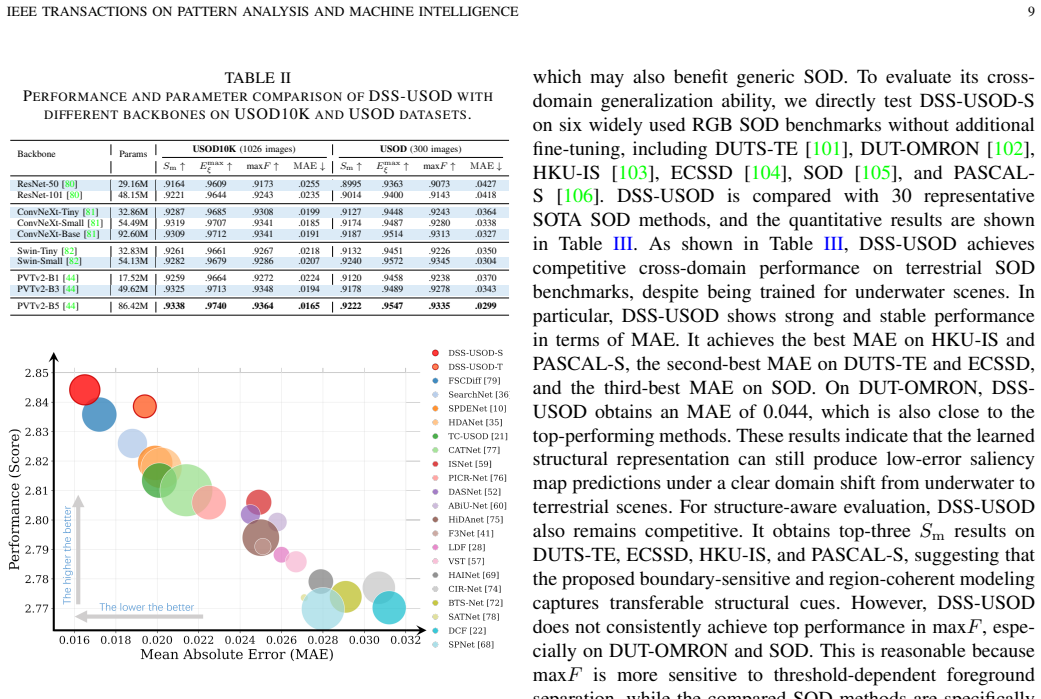
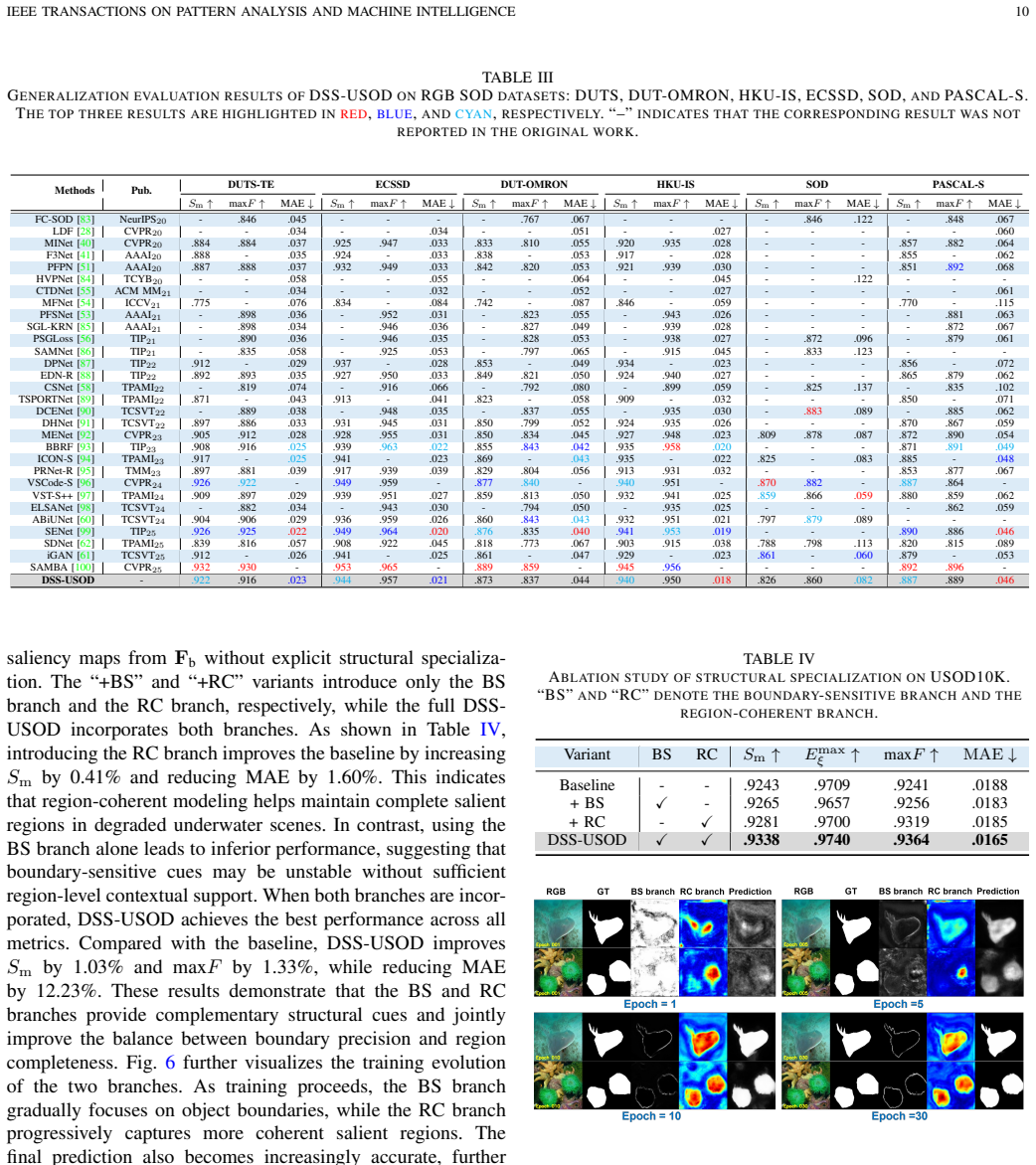
Underwater salient object detection (USOD) has attracted increasing attention for underwater visual scene understanding and vision-guided robotic applications. However, existing USOD methods still struggle with underwater image degradations, which often lead to inaccurate object localization, fragmented salient regions, and coarse boundary prediction. To address these challenges, this paper proposes DSS-USOD, a novel RGB-based USOD method built upon dynamic structural specialization. DSS-USOD extracts a shared base representation from a single underwater image, decomposes it into boundary-sensitive and region-coherent structural features, and dynamically coordinates their contributions according to local structural context. Specifically, the extracted shared base representation is decomposed into a boundary-sensitive branch for modeling fine-grained boundary details and a region-coherent branch for capturing region-level structural consistency. A spatial coordination module is then introduced to adaptively regulate the relative contributions of the two branches according to local structural context. Moreover, cooperative structural supervision is introduced to promote branch specialization and stabilize spatial coordination, enabling DSS-USOD to better balance boundary precision and region coherence under degraded underwater conditions. Extensive experiments show that DSS-USOD achieves superior performance on benchmark datasets. Finally, real-world deployment on an underwater robot validates the practical effectiveness of DSS-USOD for underwater object inspection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DSS-USOD, a novel RGB-based method for underwater salient object detection. It extracts a shared base representation from a single underwater image, decomposes it into a boundary-sensitive branch for modeling fine-grained boundary details and a region-coherent branch for capturing region-level structural consistency, and introduces a spatial coordination module to adaptively regulate the relative contributions of the two branches according to local structural context. Cooperative structural supervision is proposed to promote branch specialization and stabilize coordination. The central claims are that this architecture corrects inaccurate localization, fragmented regions, and coarse boundaries caused by underwater degradations, achieves superior performance on benchmark datasets, and demonstrates practical effectiveness via real-world deployment on an underwater robot.
Significance. If the dynamic structural specialization and spatial coordination reliably improve boundary precision and region coherence under degraded conditions, the work could advance USOD for vision-guided robotic applications by offering a targeted architectural solution to common underwater imaging challenges. The real-world robot deployment provides additional practical value beyond benchmark results.
major comments (2)
- [Method (spatial coordination module description)] The load-bearing assumption is that the spatial coordination module can correctly estimate local structural context (boundary vs. interior) from the same low-contrast, blurred, and color-distorted features that originally cause localization and boundary errors. The manuscript provides no analysis, visualization, or ablation demonstrating that the module avoids misestimation under these conditions; without such evidence the claimed corrective benefit of the branch decomposition and cooperative supervision remains unverified.
- [Abstract and Experiments section] The abstract asserts superior performance on benchmark datasets and practical effectiveness via robot deployment, yet the provided text contains no quantitative metrics, baseline comparisons, ablation results on the branches or coordination module, or error analysis. These details are required to substantiate the central performance claims.
minor comments (2)
- [Abstract] The abstract is clear but would be strengthened by including one or two key quantitative results (e.g., mIoU or F-measure gains) to convey the magnitude of improvement immediately.
- [Notation and figures] Terminology such as 'boundary-sensitive branch' and 'region-coherent branch' should be used consistently in all figures and equations to prevent minor ambiguity.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive feedback and the recommendation for major revision. We have carefully reviewed the comments on the spatial coordination module and the substantiation of performance claims in the abstract and experiments. We address each point below, indicating where revisions will be incorporated to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (spatial coordination module description)] The load-bearing assumption is that the spatial coordination module can correctly estimate local structural context (boundary vs. interior) from the same low-contrast, blurred, and color-distorted features that originally cause localization and boundary errors. The manuscript provides no analysis, visualization, or ablation demonstrating that the module avoids misestimation under these conditions; without such evidence the claimed corrective benefit of the branch decomposition and cooperative supervision remains unverified.
Authors: We agree that direct evidence for the spatial coordination module's robustness to underwater degradations is important for validating the overall approach. The current manuscript includes overall architecture ablations and qualitative results, but lacks targeted visualizations of the estimated local structural context or isolated ablations of the module under low-contrast and blurred conditions. In the revised manuscript, we will add visualizations of the coordination maps on representative degraded images and include a dedicated ablation evaluating the module's impact on boundary and region metrics in challenging subsets of the data. This will help confirm that the module contributes to the claimed corrective benefits without misestimation. revision: yes
-
Referee: [Abstract and Experiments section] The abstract asserts superior performance on benchmark datasets and practical effectiveness via robot deployment, yet the provided text contains no quantitative metrics, baseline comparisons, ablation results on the branches or coordination module, or error analysis. These details are required to substantiate the central performance claims.
Authors: The abstract serves as a high-level summary and conventionally omits specific numerical results. The full manuscript reports quantitative comparisons against state-of-the-art methods on benchmark datasets (Tables 1–2), ablation studies on the boundary-sensitive branch, region-coherent branch, and spatial coordination module (Section 4.3), as well as qualitative error analysis via visual examples (Figures 3–5). The robot deployment results are presented in Section 5. To better align with the referee's request, we will revise the abstract to include brief mentions of key performance gains (e.g., improvements in mIoU and boundary F-measure) and strengthen cross-references to the experimental sections. We will also expand the error analysis subsection if space allows. revision: partial
Circularity Check
No circularity: architectural proposal is self-contained
full rationale
The paper describes DSS-USOD as extracting a shared base representation from an underwater image, decomposing it into boundary-sensitive and region-coherent branches, then using a spatial coordination module and cooperative structural supervision to adaptively balance them. No equations, fitted parameters, or derivations are shown that reduce any claimed prediction or result to quantities defined by the inputs themselves. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on empirical benchmark results and robot deployment rather than tautological reductions, making the derivation chain independent and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Underwater images suffer from degradations that cause inaccurate object localization, fragmented salient regions, and coarse boundary prediction.
invented entities (3)
-
boundary-sensitive branch
no independent evidence
-
region-coherent branch
no independent evidence
-
spatial coordination module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DSS-USOD extracts a shared base representation from a single underwater image, decomposes it into boundary-sensitive and region-coherent structural features, and dynamically coordinates their contributions according to local structural context.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A spatial coordination module is then introduced to adaptively regulate the relative contributions of the two branches according to local structural context.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Perceptual inference, learning, and attention in a multi- sensory world,
U. Noppeney, “Perceptual inference, learning, and attention in a multi- sensory world,”Annual Review of Neuroscience, vol. 44, pp. 449–473, 2021
work page 2021
-
[2]
A model of saliency-based visual attention for rapid scene analysis,
L. Itti, C. Koch, and E. Niebur, “A model of saliency-based visual attention for rapid scene analysis,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 20, no. 11, pp. 1254–1259, 1998
work page 1998
-
[3]
Global contrast based salient region detection,
M.-M. Cheng, N. J. Mitra, X. Huang, P. H. Torr, and S.-M. Hu, “Global contrast based salient region detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, no. 3, pp. 569–582, 2014
work page 2014
-
[4]
S. Khan, I. Ullah, F. Ali, M. Shafiq, Y . Y . Ghadi, and T. Kim, “Deep learning-based marine big data fusion for ocean environment monitoring: Towards shape optimization and salient objects detection,” Frontiers in Marine Science, vol. 9, p. 1094915, 2023
work page 2023
-
[5]
Saliency ranking for benthic survey using underwater images,
M. Johnson-Roberson, O. Pizarro, and S. Williams, “Saliency ranking for benthic survey using underwater images,” in2010 11th Interna- tional Conference on Control Automation Robotics & Vision. IEEE, 2010, pp. 459–466
work page 2010
-
[6]
L. Hong, X. Wang, D.-S. Zhang, M. Zhao, and H. Xu, “Vision- based underwater inspection with portable autonomous underwater vehicle: Development, control, and evaluation,”IEEE Transactions on Intelligent Vehicles, vol. 9, no. 1, pp. 2197–2209, 2024
work page 2024
-
[7]
L. Hong, X. Wang, and D. Zhang, “Robust hybrid visual servoing for hovering control of autonomous underwater vehicles in unstructured environments,”Ocean Engineering, vol. 339, p. 122103, 2025
work page 2025
-
[8]
Sea-thru: A method for removing water from underwater images,
D. Akkaynak and T. Treibitz, “Sea-thru: A method for removing water from underwater images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 1682–1691
work page 2019
-
[9]
Wsuie: Weakly supervised underwater image enhancement for improved visual per- ception,
L. Hong, X. Wang, Z. Xiao, G. Zhang, and J. Liu, “Wsuie: Weakly supervised underwater image enhancement for improved visual per- ception,”IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 8237–8244, 2021
work page 2021
-
[10]
Underwater salient object detection via dual-stage self-paced learning and depth emphasis,
J. Jin, Q. Jiang, Q. Wu, B. Xu, and R. Cong, “Underwater salient object detection via dual-stage self-paced learning and depth emphasis,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[11]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
work page 1998
-
[12]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[13]
Salient object detection: A benchmark,
A. Borji, M.-M. Cheng, H. Jiang, and J. Li, “Salient object detection: A benchmark,”IEEE Transactions on Image Processing, vol. 24, no. 12, pp. 5706–5722, 2015
work page 2015
-
[14]
Rgb-d salient object detection: A survey,
T. Zhou, D.-P. Fan, M.-M. Cheng, J. Shen, and L. Shao, “Rgb-d salient object detection: A survey,”Computational Visual Media, pp. 1–33, 2021
work page 2021
-
[15]
Effiseanet: Pio- neering lightweight network for underwater salient object detection,
Q. Wu, Z. Fu, H. Lin, C. Ma, X. Tu, and X. Ding, “Effiseanet: Pio- neering lightweight network for underwater salient object detection,” inProceedings of the Asian Conference on Computer Vision, 2024, pp. 1486–1501
work page 2024
-
[16]
A fusion underwater salient object detection based on multi-scale saliency and spatial optimization,
W. Huang, X. Zhuet al., “A fusion underwater salient object detection based on multi-scale saliency and spatial optimization,”Journal of Marine Science and Engineering, vol. 11, no. 9, p. 1757, 2023
work page 2023
-
[17]
Q. Wu, J. Xie, Z. Fu, X. Tu, Y . Huang, and X. Ding, “Ce 3usod: Channel-enhanced, efficient, and effective network for underwater salient object detection,”IEEE Journal of Oceanic Engineering, vol. 50, no. 2, pp. 941–954, 2025
work page 2025
-
[18]
G. Yuan, J. Song, and J. Li, “If-usod: Multimodal information fusion interactive feature enhancement architecture for underwater salient object detection,”Information Fusion, vol. 117, p. 102806, 2025
work page 2025
-
[19]
Detecting underwater salient objects via self-supervised depth priors and task-driven optimization,
Y . Liu, X. Zhang, K. Zhang, B. Ma, S. Yang, R. Yang, and P. Tan, “Detecting underwater salient objects via self-supervised depth priors and task-driven optimization,”Expert Systems with Applications, p. 130873, 2025
work page 2025
-
[20]
Udepth: Fast monocular depth estima- tion for visually-guided underwater robots,
B. Yu, J. Wu, and M. J. Islam, “Udepth: Fast monocular depth estima- tion for visually-guided underwater robots,” in2023 IEEE International Conference on Robotics and Automation. IEEE, 2023, pp. 3116–3123
work page 2023
-
[21]
Usod10k: A new benchmark dataset for underwater salient object detection,
L. Hong, X. Wang, G. Zhang, and M. Zhao, “Usod10k: A new benchmark dataset for underwater salient object detection,”IEEE Transactions on Image Processing, vol. 34, pp. 1602–1615, 2025
work page 2025
-
[22]
Calibrated rgb-d salient object detection,
W. Ji, J. Li, S. Yu, M. Zhang, Y . Piao, S. Yao, Q. Bi, K. Ma, Y . Zheng, H. Lu, and L. Cheng, “Calibrated rgb-d salient object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, June 2021, pp. 9471–9481
work page 2021
-
[23]
Accurate rgb-d salient object detection via collaborative learning,
W. Ji, J. Li, M. Zhang, Y . Piao, and H. Lu, “Accurate rgb-d salient object detection via collaborative learning,” inProceedings of the European Conference on Computer Vision, 2020, pp. 52–69
work page 2020
-
[24]
Basnet: Boundary-aware salient object detection,
X. Qin, Z. Zhang, C. Huang, C. Gao, M. Dehghan, and M. Jagersand, “Basnet: Boundary-aware salient object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2019, pp. 7479–7489
work page 2019
-
[25]
Edge-guided non-local fully convolutional network for salient object detection,
Z. Tu, Y . Ma, C. Li, J. Tang, and B. Luo, “Edge-guided non-local fully convolutional network for salient object detection,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 2, pp. 582– 593, 2020
work page 2020
-
[26]
Egnet: Edge guidance network for salient object detection,
J. Zhao, J.-J. Liu, D.-P. Fan, Y . Cao, J. Yang, and M.-M. Cheng, “Egnet: Edge guidance network for salient object detection,” in2019 IEEE/CVF International Conference on Computer Vision, 2019, pp. 8778–8787
work page 2019
-
[27]
Selectivity or invari- ance: Boundary-aware salient object detection,
J. Su, J. Li, Y . Zhang, C. Xia, and Y . Tian, “Selectivity or invari- ance: Boundary-aware salient object detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 3799–3808
work page 2019
-
[28]
Label de- coupling framework for salient object detection,
J. Wei, S. Wang, Z. Wu, C. Su, Q. Huang, and Q. Tian, “Label de- coupling framework for salient object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13 025–13 034. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 14
work page 2020
-
[29]
Csunet: Contour-sensitive underwater salient object detection,
Y . Wei, Y . Wang, S. Yan, T. Wang, Z. Wang, W. Sun, Y . Zhao, and X. Xue, “Csunet: Contour-sensitive underwater salient object detection,” inProceedings of the 6th ACM Multimedia Asia, 2024, pp. 78:1–78:7
work page 2024
-
[30]
Edge distraction-aware salient object detection,
S. Ren, W. Liu, J. Jiao, G. Han, and S. He, “Edge distraction-aware salient object detection,”IEEE MultiMedia, vol. 30, no. 3, pp. 63–73, 2023
work page 2023
-
[31]
Filling-in the forms: Surface and boundary interactions in visual cortex,
S. Grossberg, “Filling-in the forms: Surface and boundary interactions in visual cortex,” inFilling-in: From Perceptual Completion to Skill Learning, L. Pessoa and P. D. Weerd, Eds. New York: Oxford University Press, 2003, pp. 13–37
work page 2003
-
[32]
Mechanisms of visual attention in the human cortex,
S. Kastner and L. G. Ungerleider, “Mechanisms of visual attention in the human cortex,”Annual Review of Neuroscience, vol. 23, pp. 315– 341, 2000
work page 2000
-
[33]
Under- water salient object detection by combining 2d and 3d visual features,
Z. Chen, H. Gao, Z. Zhang, H. Zhou, X. Wang, and Y . Tian, “Under- water salient object detection by combining 2d and 3d visual features,” Neurocomputing, vol. 391, pp. 249–259, 2020
work page 2020
-
[34]
Salient object detection in the deep learning era: An in-depth survey,
W. Wang, Q. Lai, H. Fu, J. Shen, H. Ling, and R. Yang, “Salient object detection in the deep learning era: An in-depth survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 6, pp. 3239–3259, 2021
work page 2021
-
[35]
Y . Liu, X. Zhang, J. Zhu, B. Ma, Y . Duan, and P. Tan, “Hdanet: Enhancing underwater salient object detection with physics-inspired multimodal joint learning,”IEEE Transactions on Geoscience and Remote Sensing, 2025
work page 2025
-
[36]
W. Zhou, B. Tang, R. Cong, and Q. Jiang, “Turbidity–similarity decoupling: Feature-consistent mutual learning for underwater salient object detection,”IEEE Transactions on Image Processing, pp. 1–1, 2026
work page 2026
-
[37]
Blurriness-guided underwater salient object detection and data augmentation,
Y .-T. Peng, Y .-C. Lin, W.-Y . Peng, and C.-Y . Liu, “Blurriness-guided underwater salient object detection and data augmentation,”IEEE Journal of Oceanic Engineering, vol. 49, no. 3, pp. 1089–1103, 2024
work page 2024
-
[38]
Heterogeneous experts and hierarchical perception for underwater salient object detection,
M. Zha, G. Wang, Y . Pei, T. Li, X. Tang, C. Li, Y . Yang, and H. T. Shen, “Heterogeneous experts and hierarchical perception for underwater salient object detection,”IEEE Transactions on Image Processing, 2025
work page 2025
-
[39]
A simple pooling-based design for real-time salient object detection,
J.-J. Liu, Q. Hou, M.-M. Cheng, J. Feng, and J. Jiang, “A simple pooling-based design for real-time salient object detection,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 3917–3926
work page 2019
-
[40]
Multi-scale interactive network for salient object detection,
Y . Pang, X. Zhao, L. Zhang, and H. Lu, “Multi-scale interactive network for salient object detection,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9410–9419
work page 2020
-
[41]
F 3net: fusion, feedback and focus for salient object detection,
J. Wei, S. Wang, and Q. Huang, “F 3net: fusion, feedback and focus for salient object detection,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 12 321–12 328
work page 2020
-
[42]
Stacked cross refinement network for edge-aware salient object detection,
Z. Wu, L. Su, and Q. Huang, “Stacked cross refinement network for edge-aware salient object detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 7264–7273
work page 2019
-
[43]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, pp. 8026–8037, 2019
work page 2019
-
[44]
Pvt v2: Improved baselines with pyramid vision transformer,
W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pvt v2: Improved baselines with pyramid vision transformer,”Computational visual media, vol. 8, no. 3, pp. 415–424, 2022
work page 2022
-
[45]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[46]
Svam: Saliency-guided visual at- tention modeling by autonomous underwater robots,
M. J. Islam, R. Wang, and J. Sattar, “Svam: Saliency-guided visual at- tention modeling by autonomous underwater robots,” in18th Robotics: Science and Systems, RSS 2022. MIT Press Journals, 2022
work page 2022
-
[47]
Structure- measure: A new way to evaluate foreground maps,
D.-P. Fan, M.-M. Cheng, Y . Liu, T. Li, and A. Borji, “Structure- measure: A new way to evaluate foreground maps,” in2017 IEEE International Conference on Computer Vision, 2017, pp. 4558–4567
work page 2017
-
[48]
Enhanced-alignment measure for binary foreground map evaluation,
D.-P. Fan, C. Gong, Y . Cao, B. Ren, M.-M. Cheng, and A. Borji, “Enhanced-alignment measure for binary foreground map evaluation,” inProceedings of the 27th International Joint Conference on Artificial Intelligence, 2018, pp. 698–704
work page 2018
-
[49]
Frequency-tuned salient region detection,
R. Achanta, S. Hemami, F. Estrada, and S. Susstrunk, “Frequency-tuned salient region detection,” in2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 1597–1604
work page 2009
-
[50]
Saliency filters: Contrast based filtering for salient region detection,
F. Perazzi, P. Kr ¨ahenb¨uhl, Y . Pritch, and A. Hornung, “Saliency filters: Contrast based filtering for salient region detection,” in2012 IEEE Conference on Computer Vision and Pattern Recognition, 2012, pp. 733–740
work page 2012
-
[51]
Progressive feature polishing network for salient object detection,
B. Wang, Q. Chen, M. Zhou, Z. Zhang, and K. Gai, “Progressive feature polishing network for salient object detection,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 7, pp. 12 128–12 135, 2020
work page 2020
-
[52]
Is depth really necessary for salient object detection?
J. Zhao, Y . Zhao, J. Li, and X. Chen, “Is depth really necessary for salient object detection?” inProceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 1745–1754
work page 2020
-
[53]
Pyramidal feature shrinking for salient object detection,
M. Ma, C. Xia, and J. Li, “Pyramidal feature shrinking for salient object detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 3, 2021, pp. 2311–2318
work page 2021
-
[54]
Mfnet: Multi-filter directive network for weakly supervised salient object detection,
Y . Piao, J. Wang, M. Zhang, and H. Lu, “Mfnet: Multi-filter directive network for weakly supervised salient object detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 4136–4145
work page 2021
-
[55]
Complementary trilateral decoder for fast and accurate salient object detection,
Z. Zhao, C. Xia, C. Xie, and J. Li, “Complementary trilateral decoder for fast and accurate salient object detection,” inProceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 4967– 4975
work page 2021
-
[56]
Progressive self- guided loss for salient object detection,
S. Yang, W. Lin, G. Lin, Q. Jiang, and Z. Liu, “Progressive self- guided loss for salient object detection,”IEEE Transactions on Image Processing, vol. 30, pp. 8426–8438, 2021
work page 2021
-
[57]
Visual saliency trans- former,
N. Liu, N. Zhang, K. Wan, L. Shao, and J. Han, “Visual saliency trans- former,” inProceedings of the IEEE/CVF International Conference on Computer Vision, October 2021, pp. 4722–4732
work page 2021
-
[58]
A highly efficient model to study the semantics of salient object detec- tion,
M.-M. Cheng, S.-H. Gao, A. Borji, Y .-Q. Tan, Z. Lin, and M. Wang, “A highly efficient model to study the semantics of salient object detec- tion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
work page 2022
-
[59]
Separate first, then segment: An integrity segmentation network for salient object detection,
G. Zhu, J. Li, and Y . Guo, “Separate first, then segment: An integrity segmentation network for salient object detection,”Pattern Recognition, vol. 150, p. 110328, 2024
work page 2024
-
[60]
Boosting salient object detection with transformer-based asymmetric bilateral u-net,
Y . Qiu, Y . Liu, L. Zhang, H. Lu, and J. Xu, “Boosting salient object detection with transformer-based asymmetric bilateral u-net,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 4, 2024
work page 2024
-
[61]
Genera- tive transformer for accurate and reliable salient object detection,
Y . Mao, J. Zhang, Z. Wan, X. Tian, A. Li, Y . Lv, and Y . Dai, “Genera- tive transformer for accurate and reliable salient object detection,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 2, pp. 1041–1054, 2025
work page 2025
-
[62]
Rapid salient object detection with difference con- volutional neural networks,
Z. Su, L. Liu, M. M ¨uller, J. Zhang, D. Wofk, M.-M. Cheng, and M. Pietik ¨ainen, “Rapid salient object detection with difference con- volutional neural networks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[63]
Jl-dcf: Joint learning and densely-cooperative fusion framework for rgb-d salient object detection,
K. Fu, D.-P. Fan, G.-P. Ji, and Q. Zhao, “Jl-dcf: Joint learning and densely-cooperative fusion framework for rgb-d salient object detection,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2020, pp. 3052–3062
work page 2020
-
[64]
Uc-net: Uncertainty inspired rgb-d saliency detection via conditional variational autoencoders,
J. Zhang, D.-P. Fan, Y . Dai, S. Anwar, F. Sadat Saleh, T. Zhang, and N. Barnes, “Uc-net: Uncertainty inspired rgb-d saliency detection via conditional variational autoencoders,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2020
work page 2020
-
[65]
Learning selective mutual attention and contrast for rgb-d saliency detection,
N. Liu, N. Zhang, L. Shao, and J. Han, “Learning selective mutual attention and contrast for rgb-d saliency detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 9026–9042, 2021
work page 2021
-
[66]
Bbs-net: Rgb-d salient object detection with a bifurcated backbone strategy network,
D.-P. Fan, Y . Zhai, A. Borji, J. Yang, and L. Shao, “Bbs-net: Rgb-d salient object detection with a bifurcated backbone strategy network,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 275–292
work page 2020
-
[67]
A single stream network for robust and real-time rgb-d salient object detection,
X. Zhao, L. Zhang, Y . Pang, H. Lu, and L. Zhang, “A single stream network for robust and real-time rgb-d salient object detection,” in European Conference on Computer Vision. Springer, 2020, pp. 646– 662
work page 2020
-
[68]
Specificity- preserving rgb-d saliency detection,
T. Zhou, H. Fu, G. Chen, Y . Zhou, D.-P. Fan, and L. Shao, “Specificity- preserving rgb-d saliency detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 4681–4691
work page 2021
-
[69]
Hierarchical alternate interaction network for rgb-d salient object detection,
G. Li, Z. Liu, M. Chen, Z. Bai, W. Lin, and H. Ling, “Hierarchical alternate interaction network for rgb-d salient object detection,”IEEE Transactions on Image Processing, vol. 30, pp. 3528–3542, 2021
work page 2021
-
[70]
Tritransnet: Rgb-d salient object detection with a triplet transformer embedding network,
Z. Liu, Y . Wang, Z. Tu, Y . Xiao, and B. Tang, “Tritransnet: Rgb-d salient object detection with a triplet transformer embedding network,” Proceedings of the 29th ACM International Conference on Multimedia, 2021
work page 2021
-
[71]
Rethinking rgb-d salient object detection: Models, data sets, and large-scale bench- marks,
D.-P. Fan, Z. Lin, Z. Zhang, M. Zhu, and M.-M. Cheng, “Rethinking rgb-d salient object detection: Models, data sets, and large-scale bench- marks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 5, pp. 2075–2089, 2020. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 15
work page 2075
-
[72]
Bts-net: Bi-directional transfer-and-selection network for rgb-d salient object detection,
W. Zhang, Y . Jiang, K. Fu, and Q. Zhao, “Bts-net: Bi-directional transfer-and-selection network for rgb-d salient object detection,” in 2021 IEEE International Conference on Multimedia and Expo. IEEE, 2021, pp. 1–6
work page 2021
-
[73]
Cross-modality discrepant interaction network for RGB-D salient object detection,
C. Zhang, R. Cong, Q. Lin, L. Ma, L. Feng, Y . Zhao, and S. Kwong, “Cross-modality discrepant interaction network for RGB-D salient object detection,” inProceedings of the 29th ACM International Conference on Multimedia. ACM, 2021
work page 2021
-
[74]
Cir-net: Cross-modality interaction and refinement for rgb-d salient object detection,
R. Cong, Q. Lin, C. Zhang, C. Li, X. Cao, Q. Huang, and Y . Zhao, “Cir-net: Cross-modality interaction and refinement for rgb-d salient object detection,”IEEE Transactions on Image Processing, vol. 31, 2022
work page 2022
-
[75]
Hi- danet: Rgb-d salient object detection via hierarchical depth awareness,
Z. Wu, G. Allibert, F. Meriaudeau, C. Ma, and C. Demonceaux, “Hi- danet: Rgb-d salient object detection via hierarchical depth awareness,” IEEE Transactions on Image Processing, vol. 32, 2023
work page 2023
-
[76]
Point-aware interaction and cnn-induced refinement net- work for rgb-d salient object detection,
R. Cong, H. Liu, C. Zhang, W. Zhang, F. Zheng, R. Song, and S. Kwong, “Point-aware interaction and cnn-induced refinement net- work for rgb-d salient object detection,” inProceedings of the 31st ACM International Conference on Multimedia, 2023
work page 2023
-
[77]
Catnet: A cascaded and aggregated transformer network for rgb-d salient object detection,
F. Sun, P. Ren, B. Yin, F. Wang, and H. Li, “Catnet: A cascaded and aggregated transformer network for rgb-d salient object detection,” IEEE Transactions on Multimedia, vol. 26, 2024
work page 2024
-
[78]
Lightweight rgb-d salient object detection from a speed-accuracy tradeoff perspective,
S. Duan, X. Yang, N. Wang, and X. Gao, “Lightweight rgb-d salient object detection from a speed-accuracy tradeoff perspective,”IEEE Transactions on Image Processing, vol. 34, pp. 2529–2543, 2025
work page 2025
-
[79]
H. Li, G. Lin, Z. Li, S. Kwong, and R. Cong, “Fscdiff: Frequency- spatial entangled conditional diffusion model for underwater salient object detection,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 8379–8388
work page 2025
-
[80]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.