MAPS: Multi-Anchor Projection Similarity for Joint Vision-Language Geo-Localization
Pith reviewed 2026-06-26 10:21 UTC · model grok-4.3
The pith
Joint image-text queries define an anchor plane whose projection length ranks geo-localization targets more discriminatively than pairwise cosine similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
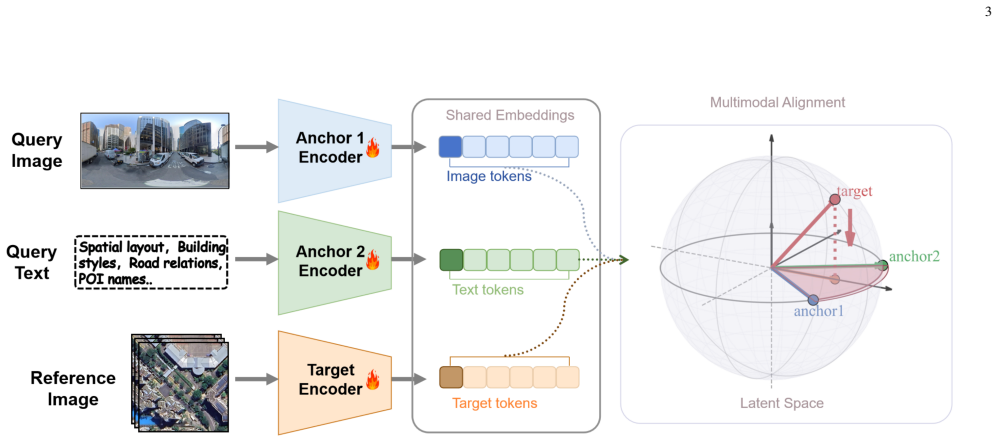
MAPS constructs an anchor plane from visual and textual query features in high-dimensional space and measures similarity by the projection length of the target feature onto this plane. Unlike cosine similarity which evaluates isolated pairwise relations, MAPS captures the geometric consistency between the target feature and the joint query subspace, providing a more discriminative ranking criterion during retrieval. A MAPS-based contrastive loss drives target features toward the corresponding anchor plane, and the resulting framework, metric, and objective together yield state-of-the-art performance in VLGL.
What carries the argument
Multi-Anchor Projection Similarity (MAPS), a metric that builds an anchor plane from query features and scores targets by their projection length onto the plane.
If this is right
- Supplies a more discriminative ranking criterion than pairwise methods for joint vision-language retrieval.
- Requires learned features to align with subspace geometry through the dedicated contrastive loss.
- Produces state-of-the-art retrieval performance on vision-language geo-localization tasks.
- Moves the field from point-to-point alignment toward explicit subspace matching for multimodal queries.
Where Pith is reading between the lines
- The plane-based formulation could be tested on retrieval tasks outside geo-localization where queries combine modalities.
- Performance may degrade when visual and textual cues conflict; experiments with contradictory query pairs would expose this boundary.
- Extending the construction to three or more anchors would allow direct comparison of how additional modalities affect projection-based ranking.
Load-bearing premise
The joint visual-textual query can be usefully represented as a single anchor plane in feature space whose projection length yields a superior similarity measure for geo-localization targets.
What would settle it
A controlled experiment on a standard VLGL benchmark showing that ranking accuracy with MAPS projection length is no higher than, or lower than, cosine similarity on the same features would falsify the central claim.
Figures








read the original abstract
Humans localize places by integrating perceptual cues from vision with semantic reasoning from language, forming a scene understanding that is both intuitive and structured. Although existing geo-localization models have made substantial progress in cross-view and cross-modal settings, they are largely built upon point-to-point alignment, which is insufficient for joint vision-language queries. In such queries, visual and textual cues do not simply act as independent references, but jointly define a semantic subspace for locating the target. In this paper, we formulate vision-language geo-localization (VLGL) with joint image-text queries as a multi-anchor geometric alignment problem and propose a unified framework for this setting. To realize this formulation, we propose Multi-Anchor Projection Similarity (MAPS), a new metric which constructs an anchor plane from visual and textual query features in a high-dimensional space and measures similarity by the projection length of the target feature onto this plane. Unlike cosine similarity which evaluates isolated pairwise relations, MAPS captures the geometric consistency between the target feature and the joint query subspace, providing a more discriminative ranking criterion during retrieval. To make the learned representation consistent with this geometry, we further introduce a MAPS-based contrastive loss that drives target features toward the corresponding anchor plane. The proposed framework, similarity metric, and training objective jointly yield state-of-the-art performance in VLGL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates vision-language geo-localization (VLGL) with joint image-text queries as a multi-anchor geometric alignment problem. It introduces Multi-Anchor Projection Similarity (MAPS), which constructs an anchor plane from the visual and textual query features and scores targets by their projection length onto this plane. A MAPS-based contrastive loss is added to align learned representations with the geometry, and the combination is reported to achieve state-of-the-art retrieval performance.
Significance. If the projection-length metric can be shown to supply an independent ranking signal beyond what the training loss already enforces, the geometric framing could usefully extend point-to-point cross-modal alignment methods. The absence of parameter-free derivations or machine-checked proofs is noted, but the explicit geometric construction is a clear conceptual contribution if empirically isolated.
major comments (2)
- [Abstract, §3] Abstract and §3 (method): the central claim that MAPS supplies a more discriminative ranking criterion because it measures consistency with the joint query subspace is load-bearing, yet no ablation is described that fixes the contrastive loss and replaces the MAPS inference metric with cosine (or averaged-cosine) similarity. Without this isolation the reported gains cannot be attributed to the projection length rather than the training objective.
- [§4] §4 (experiments): the absence of the reverse ablation (standard loss but MAPS metric at test time) leaves open the possibility that any improvement is driven entirely by the MAPS loss; this directly affects the claim that the geometric metric itself is superior.
minor comments (2)
- [Abstract] The abstract would benefit from naming the datasets and the magnitude of the reported gains over the strongest baseline.
- [§3] Notation for the construction of the anchor plane (two query vectors to plane normal and offset) should be made explicit in the first equation block of §3 to avoid ambiguity in the projection-length formula.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for targeted ablations to isolate the contribution of the MAPS metric. We address each major comment below and commit to the indicated revisions.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): the central claim that MAPS supplies a more discriminative ranking criterion because it measures consistency with the joint query subspace is load-bearing, yet no ablation is described that fixes the contrastive loss and replaces the MAPS inference metric with cosine (or averaged-cosine) similarity. Without this isolation the reported gains cannot be attributed to the projection length rather than the training objective.
Authors: We agree that this ablation is necessary to attribute performance gains specifically to the projection-length metric rather than the training objective alone. We will add an experiment that trains with the MAPS contrastive loss but performs inference using cosine similarity (and averaged-cosine) on the same learned representations, reporting the resulting retrieval metrics for direct comparison. revision: yes
-
Referee: [§4] §4 (experiments): the absence of the reverse ablation (standard loss but MAPS metric at test time) leaves open the possibility that any improvement is driven entirely by the MAPS loss; this directly affects the claim that the geometric metric itself is superior.
Authors: We concur that the reverse ablation is required to determine whether the MAPS metric provides benefit independently of the MAPS loss. We will include results for models trained with a standard contrastive loss but evaluated using the MAPS projection similarity at test time, allowing direct assessment of the metric's standalone contribution. revision: yes
Circularity Check
No circularity: MAPS metric and loss are defined independently without reduction to inputs
full rationale
The paper proposes a new similarity metric (anchor plane construction and projection length) and a corresponding contrastive loss without any step that reduces a claimed prediction or result to a fitted parameter or self-citation by construction. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The framework is presented as a self-contained proposal for VLGL, with performance claims following from the new geometry rather than tautological equivalence to prior fits. This aligns with the default expectation for non-circular papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Visual place recognition: A survey,
S. Lowry, N. S ¨underhauf, P. Newman, J. J. Leonard, D. Cox, P. Corke, and M. J. Milford, “Visual place recognition: A survey,”ieee transac- tions on robotics, vol. 32, no. 1, pp. 1–19, 2015. 14
2015
-
[2]
Loc4plan: Locating before planning for outdoor vision and language navigation,
H. Tian, J. Meng, W.-S. Zheng, Y .-M. Li, J. Yan, and Y . Zhang, “Loc4plan: Locating before planning for outdoor vision and language navigation,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 4073–4081
2024
-
[3]
Visual place recognition: A survey,
S. Lowry, N. S ¨underhauf, P. Newman, J. J. Leonard, D. Cox, P. Corke, and M. J. Milford, “Visual place recognition: A survey,”ieee transac- tions on robotics, vol. 32, no. 1, pp. 1–19, 2015
2015
-
[4]
Netvlad: Cnn architecture for weakly supervised place recognition,
R. Arandjelovic, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “Netvlad: Cnn architecture for weakly supervised place recognition,” inProceed- ings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5297–5307
2016
-
[5]
Classifying building roof damage using high resolution imagery for disaster recovery,
E. Gonsoroski, Y . Ahn, E. W. Harville, N. Countess, M. Y . Lichtveld, K. Pan, L. Beitsch, S. P. Sherchan, and C. K. Uejio, “Classifying building roof damage using high resolution imagery for disaster recovery,” Photogrammetric Engineering & Remote Sensing, vol. 89, no. 7, pp. 437–443, 2023
2023
-
[7]
Visual spatial reasoning,
F. Liu, G. Emerson, and N. Collier, “Visual spatial reasoning,”Trans- actions of the Association for Computational Linguistics, vol. 11, pp. 635–651, 2023
2023
-
[8]
Transgeo: Transformer is all you need for cross-view image geo-localization,
S. Zhu, M. Shah, and C. Chen, “Transgeo: Transformer is all you need for cross-view image geo-localization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1162–1171
2022
-
[9]
Cross-view geo- localization via learning disentangled geometric layout correspondence,
X. Zhang, X. Li, W. Sultani, Y . Zhou, and S. Wshah, “Cross-view geo- localization via learning disentangled geometric layout correspondence,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 3, 2023, pp. 3480–3488
2023
-
[10]
Sample4geo: Hard negative sam- pling for cross-view geo-localisation,
F. Deuser, K. Habel, and N. Oswald, “Sample4geo: Hard negative sam- pling for cross-view geo-localisation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 16 847–16 856
2023
-
[11]
Enhancing cross-view geo-localization with domain alignment and scene consistency,
P. Xia, Y . Wan, Z. Zheng, Y . Zhang, and J. Deng, “Enhancing cross-view geo-localization with domain alignment and scene consistency,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[12]
Camp: A cross-view geo-localization method using contrastive attributes mining and position-aware partitioning,
Q. Wu, Y . Wan, Z. Zheng, Y . Zhang, G. Wang, and Z. Zhao, “Camp: A cross-view geo-localization method using contrastive attributes mining and position-aware partitioning,”IEEE Transactions on Geoscience and Remote Sensing, 2024
2024
-
[13]
Cross-view geo-localization with panoramic street-view and vhr satellite imagery in decentrality settings,
P. Xia, L. Yu, Y . Wan, Q. Wu, P. Chen, L. Zhong, Y . Yao, D. Wei, X. Liu, L. Ruet al., “Cross-view geo-localization with panoramic street-view and vhr satellite imagery in decentrality settings,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 227, pp. 1–11, 2025
2025
-
[14]
Text2pos: Text-to- point-cloud cross-modal localization,
M. Kolmet, Q. Zhou, A. O ˇsep, and L. Leal-Taix ´e, “Text2pos: Text-to- point-cloud cross-modal localization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 6687– 6696
2022
-
[15]
Towards natural language-guided drones: Geotext-1652 benchmark with spatial relation matching,
M. Chu, Z. Zheng, W. Ji, T. Wang, and T.-S. Chua, “Towards natural language-guided drones: Geotext-1652 benchmark with spatial relation matching,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 213–231
2024
-
[16]
Y . Hu, J. Chen, C. Xu, Y . Kou, S. Zhou, S. Yan, P. Shi, Q. Hu, and J. Li, “Global cross-modal geo-localization: A million-scale dataset and a physical consistency learning framework,” 2026. [Online]. Available: https://arxiv.org/abs/2603.08491
Pith/arXiv arXiv 2026
-
[17]
Where am i? cross-view geo-localization with natural language descriptions,
J. Ye, H. Lin, L. Ou, D. Chen, Z. Wang, Q. Zhu, C. He, and W. Li, “Where am i? cross-view geo-localization with natural language descriptions,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 5890–5900
2025
-
[18]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inInternational conference on machine learning. PmLR, 2020, pp. 1597–1607
2020
-
[19]
Momentum contrast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9729–9738
2020
-
[20]
Representation learning with contrastive predictive coding,
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[21]
Cvm-net: Cross-view matching network for image-based ground-to-aerial geo-localization,
S. Hu, M. Feng, R. M. Nguyen, and G. H. Lee, “Cvm-net: Cross-view matching network for image-based ground-to-aerial geo-localization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7258–7267
2018
-
[22]
Valor: Vision-audio-language omni-perception pretraining model and dataset,
J. Liu, S. Chen, X. He, L. Guo, X. Zhu, W. Wang, and J. Tang, “Valor: Vision-audio-language omni-perception pretraining model and dataset,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 47, no. 2, pp. 708–724, 2024
2024
-
[23]
Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset,
S. Chen, H. Li, Q. Wang, Z. Zhao, M. Sun, X. Zhu, and J. Liu, “Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset,”Advances in Neural Information Processing Systems, vol. 36, pp. 72 842–72 866, 2023
2023
-
[24]
Gramian multimodal representation learning and alignment,
G. Cicchetti, E. Grassucci, L. Sigillo, and D. Comminiello, “Gramian multimodal representation learning and alignment,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 42 128– 42 149
2025
-
[25]
Principled multimodal representation learning,
X. Liu, X. Xia, S.-K. Ng, and T.-S. Chua, “Principled multimodal representation learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[26]
Wide-area image geolo- calization with aerial reference imagery,
S. Workman, R. Souvenir, and N. Jacobs, “Wide-area image geolo- calization with aerial reference imagery,” inProceedings of the IEEE International Conference on Computer Vision, 2015, pp. 3961–3969
2015
-
[27]
Lending orientation to neural networks for cross- view geo-localization,
L. Liu and H. Li, “Lending orientation to neural networks for cross- view geo-localization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5624–5633
2019
-
[28]
Vigor: Cross-view image geo-localization beyond one-to-one retrieval,
S. Zhu, T. Yang, and C. Chen, “Vigor: Cross-view image geo-localization beyond one-to-one retrieval,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2021, pp. 3640–3649
2021
-
[29]
Cv-cities: Advancing cross- view geo-localization in global cities,
G. Huang, Y . Zhou, L. Zhao, and W. Gan, “Cv-cities: Advancing cross- view geo-localization in global cities,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024
2024
-
[30]
Cross- view image geo-localization with panorama-bev co-retrieval network,
J. Ye, Z. Lv, W. Li, J. Yu, H. Yang, H. Zhong, and C. He, “Cross- view image geo-localization with panorama-bev co-retrieval network,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 74– 90
2024
-
[31]
Z. Song, J. Zhang, D. Wang, Z. Zhou, W. Liu, H. Guo, E. Wang, and B. Du, “Geobridge: A semantic-anchored multi-view foundation model bridging images and text for geo-localization,”arXiv preprint arXiv:2512.02697, 2025
Pith/arXiv arXiv 2025
-
[32]
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. Van Den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3674–3683
2018
-
[33]
Touchdown: Natural language navigation and spatial reasoning in visual street environments,
H. Chen, A. Suhr, D. Misra, N. Snavely, and Y . Artzi, “Touchdown: Natural language navigation and spatial reasoning in visual street environments,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 538–12 547
2019
-
[34]
Multimodal machine learning: A survey and taxonomy,
T. Baltru ˇsaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,”IEEE transactions on pattern anal- ysis and machine intelligence, vol. 41, no. 2, pp. 423–443, 2018
2018
-
[35]
Devise: A deep visual-semantic embedding model,
A. Frome, G. S. Corrado, J. Shlens, S. Bengio, J. Dean, M. Ranzato, and T. Mikolov, “Devise: A deep visual-semantic embedding model,” Advances in neural information processing systems, vol. 26, 2013
2013
-
[36]
Scaling up visual and vision-language representation learning with noisy text supervision,
C. Jia, Y . Yang, Y . Xia, Y .-T. Chen, Z. Parekh, H. Pham, Q. Le, Y .-H. Sung, Z. Li, and T. Duerig, “Scaling up visual and vision-language representation learning with noisy text supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 4904–4916
2021
-
[37]
Retrieve-then- compare mitigates visual hallucination in multi-modal large language models,
D. Yang, B. Cao, S. Qu, F. Lu, S. Gu, and G. Chen, “Retrieve-then- compare mitigates visual hallucination in multi-modal large language models,”Intelligence & Robotics, vol. 5, no. 2, pp. 248–275, 2025
2025
-
[38]
Infrared and visible image fusion based on multi-level detail enhancement and generative adversarial network,
X. Tian, X. Xianyu, Z. Li, T. Xu, and Y . Jia, “Infrared and visible image fusion based on multi-level detail enhancement and generative adversarial network,”Intelligence & Robotics, vol. 4, no. 4, pp. 524– 543, 2024
2024
-
[39]
Eva-02: A visual representation for neon genesis,
Y . Fang, Q. Sun, X. Wang, T. Huang, X. Wang, and Y . Cao, “Eva-02: A visual representation for neon genesis,”Image and Vision Computing, vol. 149, p. 105171, 2024
2024
-
[40]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[41]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inInternational conference on machine learning. PMLR, 2022, pp. 12 888–12 900
2022
-
[42]
Remoteclip: A vision language foundation model for remote sensing,
F. Liu, D. Chen, Z. Guan, X. Zhou, J. Zhu, Q. Ye, L. Fu, and J. Zhou, “Remoteclip: A vision language foundation model for remote sensing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1– 16, 2024. 15
2024
-
[43]
Long-clip: Unlocking the long-text capability of clip,
B. Zhang, P. Zhang, X. Dong, Y . Zang, and J. Wang, “Long-clip: Unlocking the long-text capability of clip,” inEuropean conference on computer vision. Springer, 2024, pp. 310–325
2024
-
[44]
Text-based aerial-ground person retrieval,
X. Zhou, Y . Wu, J. Ma, W. Wang, M. Cao, and M. Ye, “Text-based aerial-ground person retrieval,”arXiv e-prints, pp. arXiv–2511, 2025
2025
-
[45]
Vse++: Improv- ing visual-semantic embeddings with hard negatives,
F. Faghri, D. J. Fleet, J. R. Kiros, and S. Fidler, “Vse++: Improv- ing visual-semantic embeddings with hard negatives,”arXiv preprint arXiv:1707.05612, 2017
Pith/arXiv arXiv 2017
-
[46]
Stacked cross attention for image-text matching,
K.-H. Lee, X. Chen, G. Hua, H. Hu, and X. He, “Stacked cross attention for image-text matching,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 201–216
2018
-
[47]
Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,
J. Lu, D. Batra, D. Parikh, and S. Lee, “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[48]
Visualbert: A simple and performant baseline for vision and language,
L. H. Li, M. Yatskar, D. Yin, C.-J. Hsieh, and K.-W. Chang, “Visualbert: A simple and performant baseline for vision and language,”arXiv preprint arXiv:1908.03557, 2019
Pith/arXiv arXiv 1908
-
[49]
Uniter: Universal image-text representation learning,
Y .-C. Chen, L. Li, L. Yu, A. El Kholy, F. Ahmed, Z. Gan, Y . Cheng, and J. Liu, “Uniter: Universal image-text representation learning,” in European conference on computer vision. Springer, 2020, pp. 104– 120
2020
-
[50]
Align before fuse: Vision and language representation learning with momentum distillation,
J. Li, R. Selvaraju, A. Gotmare, S. Joty, C. Xiong, and S. C. H. Hoi, “Align before fuse: Vision and language representation learning with momentum distillation,”Advances in neural information processing systems, vol. 34, pp. 9694–9705, 2021
2021
-
[51]
Clap learning audio concepts from natural language supervision,
B. Elizalde, S. Deshmukh, M. Al Ismail, and H. Wang, “Clap learning audio concepts from natural language supervision,” inICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[52]
Videoclip: Contrastive pre- training for zero-shot video-text understanding,
H. Xu, G. Ghosh, P.-Y . Huang, D. Okhonko, A. Aghajanyan, F. Metze, L. Zettlemoyer, and C. Feichtenhofer, “Videoclip: Contrastive pre- training for zero-shot video-text understanding,” inProceedings of the 2021 conference on empirical methods in natural language processing, 2021, pp. 6787–6800
2021
-
[53]
Pointclip: Point cloud understanding by clip,
R. Zhang, Z. Guo, W. Zhang, K. Li, X. Miao, B. Cui, Y . Qiao, P. Gao, and H. Li, “Pointclip: Point cloud understanding by clip,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8552–8562
2022
-
[54]
Imagebind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “Imagebind: One embedding space to bind them all,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 15 180–15 190
2023
-
[55]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[56]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
Pith/arXiv arXiv 2014
-
[57]
Benchmarking neural network ro- bustness to common corruptions and perturbations,
D. Hendrycks and T. Dietterich, “Benchmarking neural network ro- bustness to common corruptions and perturbations,”arXiv preprint arXiv:1903.12261, 2019
Pith/arXiv arXiv 1903
-
[58]
Visualizing data using t-sne
L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.”Journal of machine learning research, vol. 9, no. 11, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.