Diagnosing and Repairing Shape-Prior Shortcuts in Long-Range Single-Shot Fringe Projection Profilometry
Pith reviewed 2026-06-27 04:51 UTC · model grok-4.3
The pith
UNet baselines for long-range single-shot fringe projection profilometry solve the task using object-boundary shape priors rather than fringe-phase decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
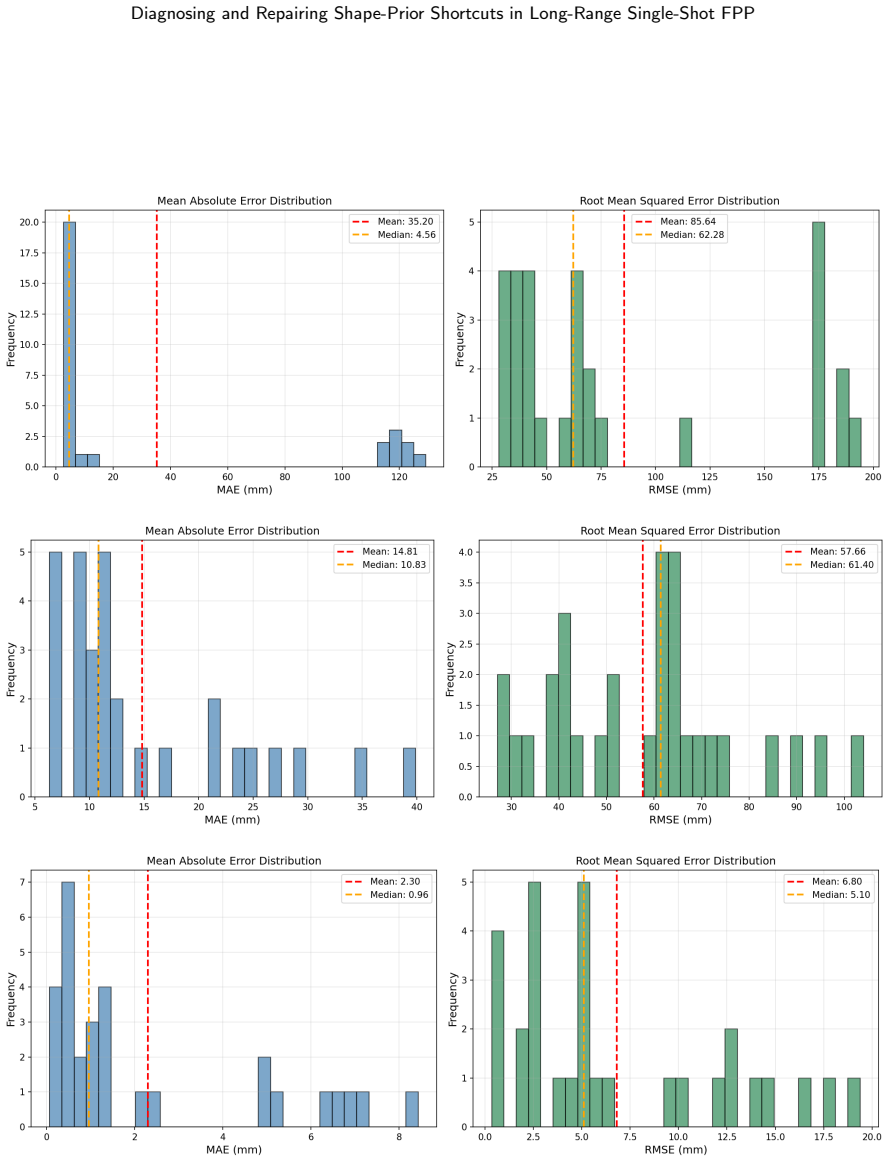
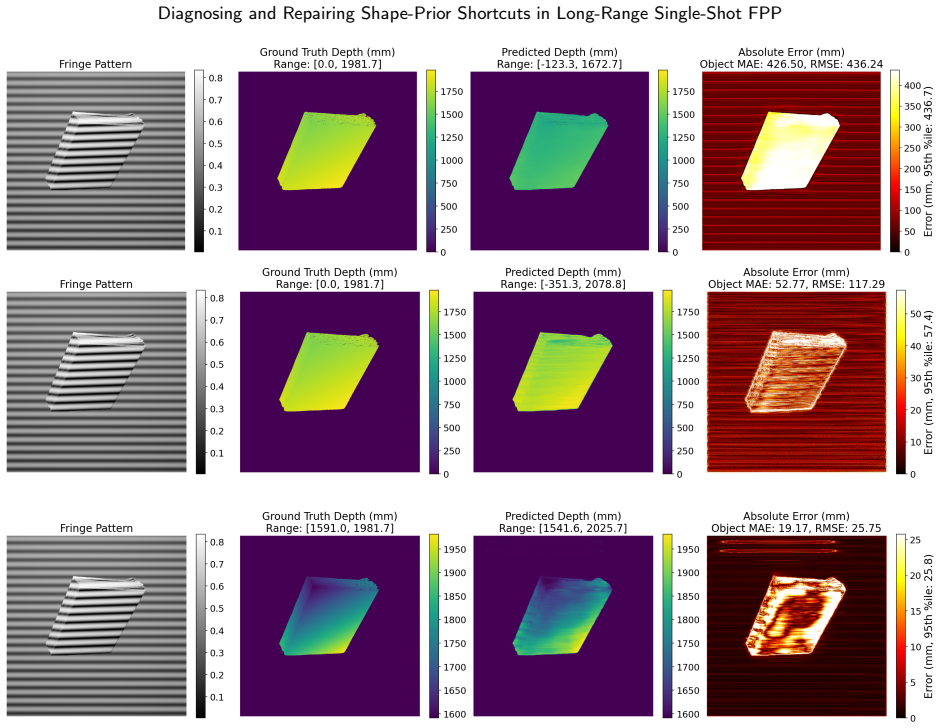
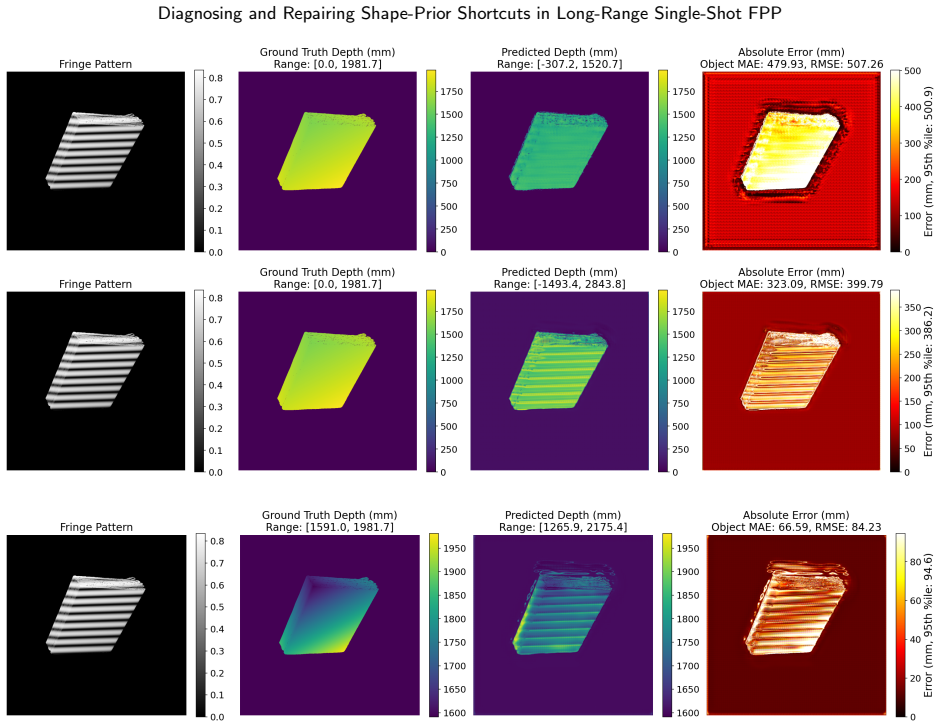
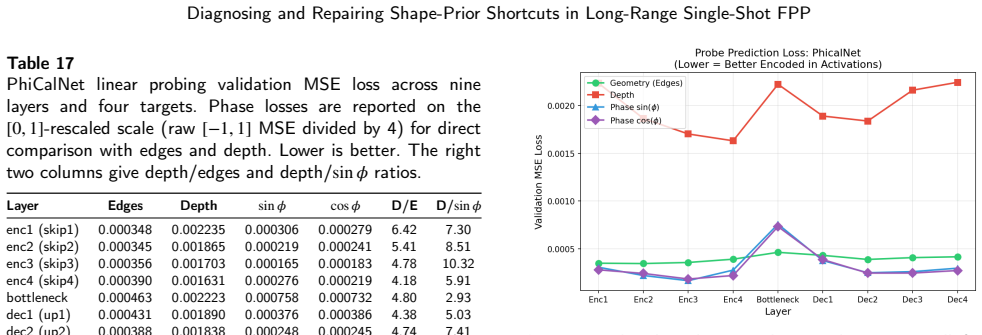
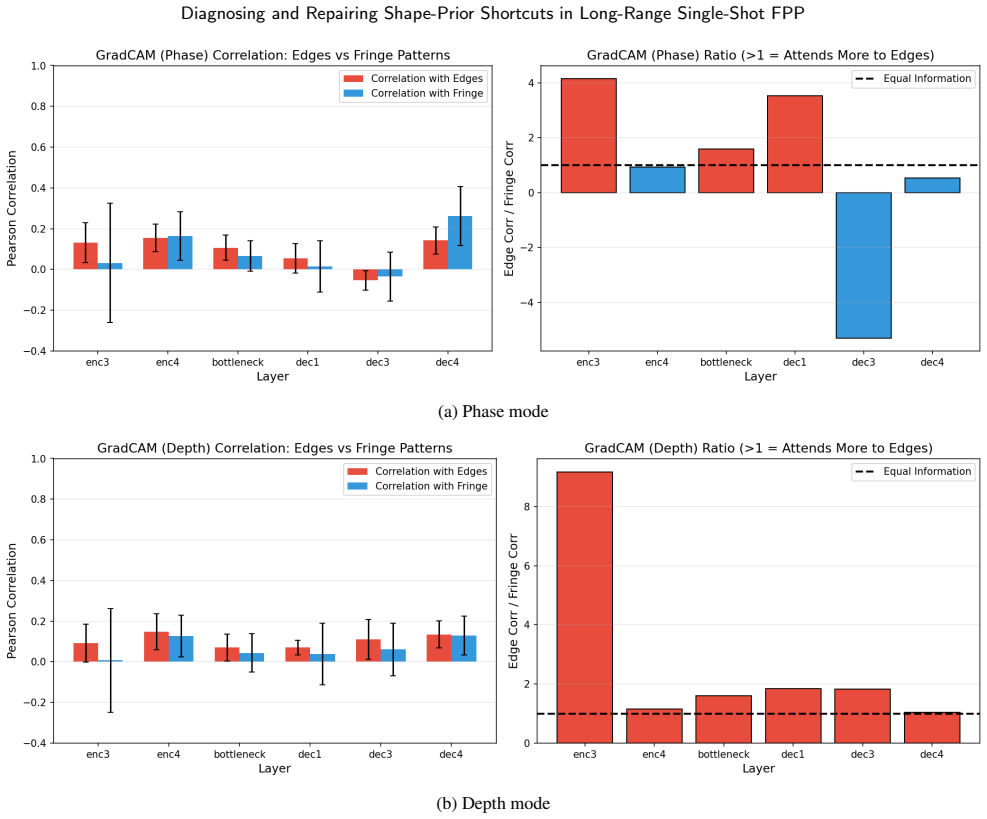
On the 15,600-image benchmark the baseline UNet reaches 14.54 mm object MAE by relying on object-boundary shape priors. PhiCalNet, which outputs wrapped phase rather than depth and applies a fixed differentiable calibration layer mapping phase to depth, reduces object MAE 3.3 times to 4.46 mm. The residual error is carried by the 0.103 percent of pixels at the +/-pi wrap discontinuity. Pixel-wise conformal uncertainty quantification confirms the diagnosis: rejecting the top 5 percent of object pixels by snapshot disagreement cuts PhiCalNet RMSE by 64 percent (20.6 mm to 7.4 mm) versus only 3.5 percent for the baseline.
What carries the argument
PhiCalNet architecture that outputs wrapped phase rather than depth and applies a fixed differentiable calibration layer mapping phase to depth, removing shape-prior solutions from the hypothesis space.
If this is right
- The shape-prior shortcut is the dominant failure mode in baseline models rather than an artifact of the loss function.
- Architectural removal of the shortcut outperforms soft physics-informed loss penalties on depth regression.
- Mechanistic interpretability and conformal uncertainty quantification converge on the same failure locus at object boundaries.
- Residual error concentrates at the +/-pi phase wrap discontinuities.
Where Pith is reading between the lines
- If the synthetic benchmark statistics match real hardware, similar shape-prior shortcuts may appear in other single-shot 3D reconstruction tasks that are ill-posed without multi-frame information.
- Explicit handling of wrap discontinuities could further reduce the remaining 4.46 mm error.
- The same fixed-calibration architectural pattern could be applied to other inverse problems where direct regression allows networks to bypass the intended physical decoding step.
Load-bearing premise
The photorealistic synthetic benchmark with 50 objects at 1.5-2.1 m faithfully captures the dominant failure modes and noise statistics of real long-range fringe projection hardware.
What would settle it
Capture real long-range fringe images with the same hardware geometry, run both the baseline UNet and PhiCalNet on them, and check whether the 3.3 times error reduction holds and whether the three diagnostic probes still isolate object-boundary shape priors as the dominant mechanism.
Figures
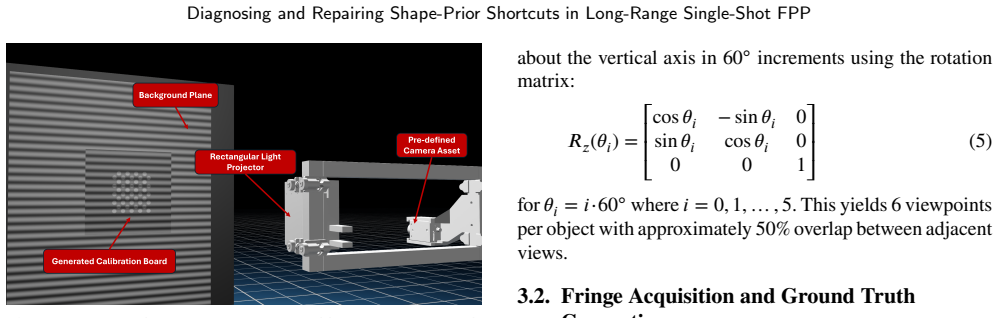


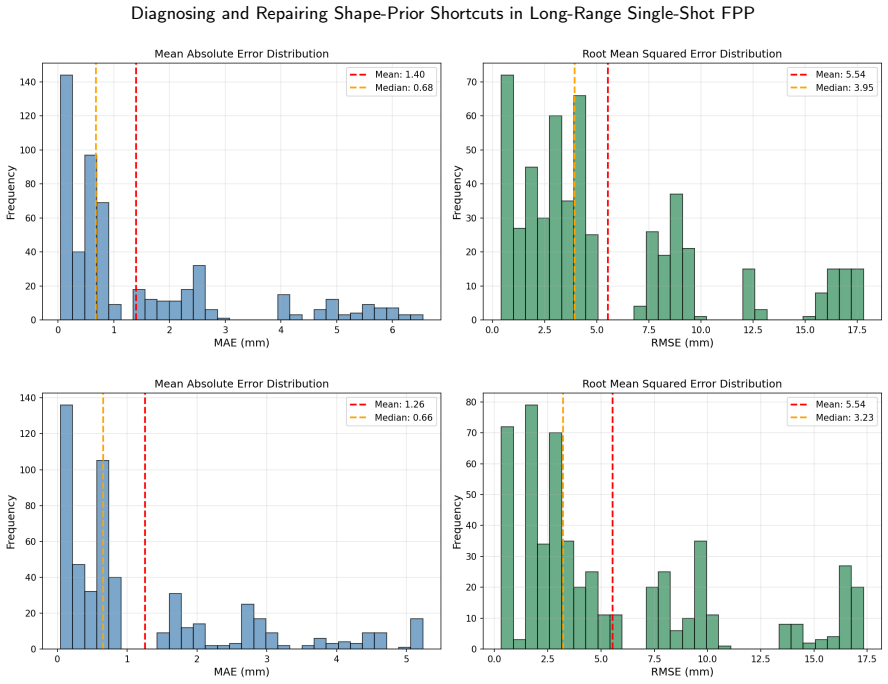

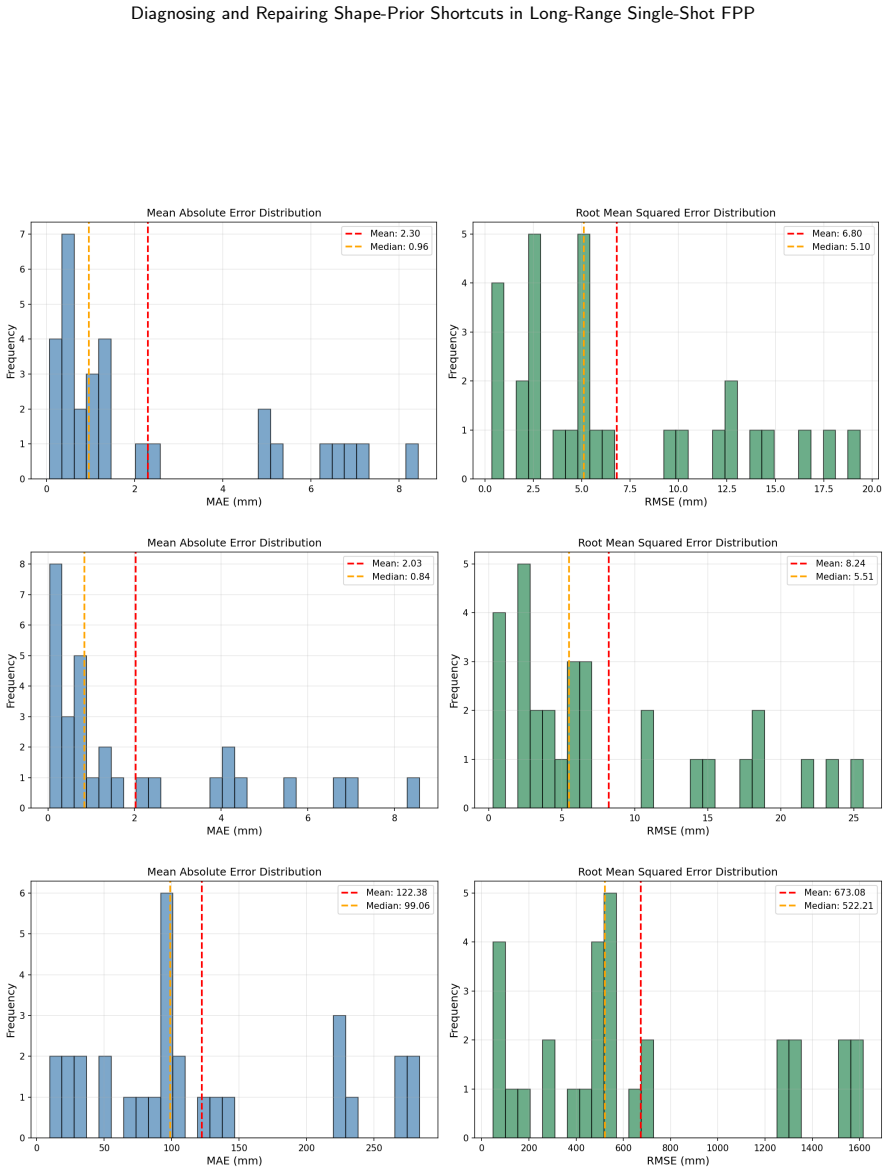









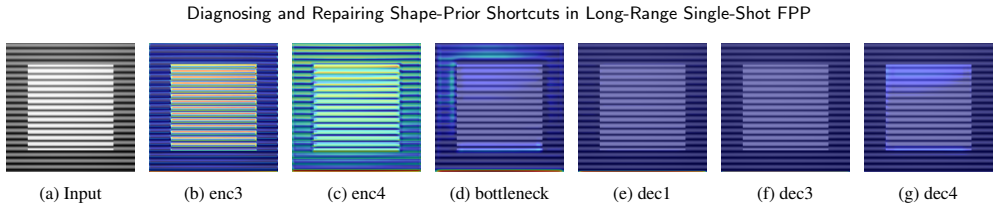


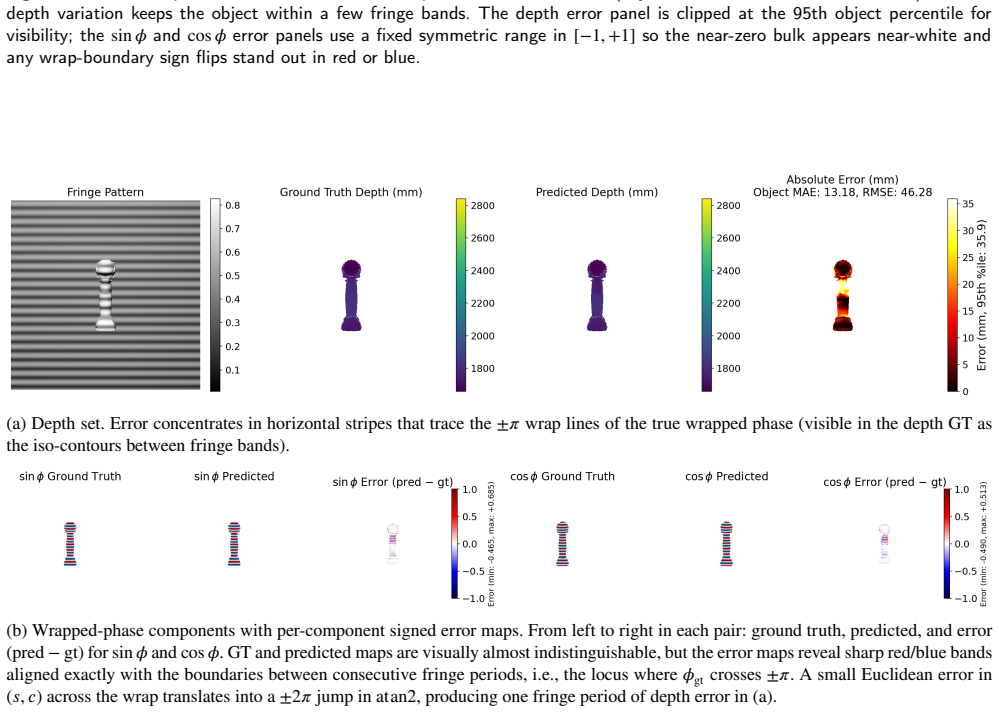



read the original abstract
Learning-based single-shot fringe projection profilometry (FPP) has been studied mostly at close range. The long-range regime (standoff beyond 1 m) remains largely unaddressed: inverse-square intensity falloff lowers fringe signal-to-noise ratio and degrades physical ground truth, the single-shot problem is ill-posed because fringe-order information is absent from one image, and these architectures have not been studied mechanistically. We present a diagnose-repair-verify study using mechanistic interpretability (MI) and conformal uncertainty quantification (UQ) as convergent diagnostics: they agree on one physical failure locus, driving and verifying an architectural repair. On a photorealistic synthetic benchmark (15,600 fringe images, 50 objects at 1.5-2.1 m), a best UNet baseline reaches 14.54 mm object mean absolute error (MAE). Three probes (linear probing, Grad-CAM, flat-plane out-of-distribution test) converge: the baseline solves the task via object-boundary shape priors rather than fringe-phase decoding. We repair this with PhiCalNet, which outputs wrapped phase rather than depth and applies a fixed differentiable calibration layer mapping phase to depth, removing the shape-prior solution from the hypothesis space architecturally rather than by a loss penalty. A physics-informed loss that enforces the same physics as a soft penalty on a depth-regressing network yields no measurable gain, isolating the architecture as the operative factor. PhiCalNet reduces object MAE 3.3x to 4.46 mm; the residual is carried by 0.103% of pixels at the +/-pi wrap discontinuity. Pixel-wise conformal UQ confirms the diagnosis: rejecting the top 5% of object pixels by snapshot disagreement cuts PhiCalNet RMSE by 64% (20.6->7.4 mm) versus 3.5% for the baseline. MI and UQ converge on the same failure locus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in long-range single-shot fringe projection profilometry, standard UNet baselines solve the ill-posed task via object-boundary shape priors rather than fringe-phase decoding. This is diagnosed on a 15,600-image photorealistic synthetic benchmark (50 objects at 1.5-2.1 m) using convergent mechanistic interpretability probes (linear probing, Grad-CAM, flat-plane OOD test) and conformal UQ. The authors introduce PhiCalNet, which regresses wrapped phase and applies a fixed differentiable calibration layer to depth, architecturally excluding the shape-prior solution; a physics-informed loss baseline on depth regression yields no gain. PhiCalNet reduces object MAE from 14.54 mm to 4.46 mm (3.3×), with UQ filtering the top 5% pixels cutting RMSE by 64%.
Significance. If the central diagnosis holds, the work supplies a concrete example of shortcut learning in a physics-constrained vision task and shows that removing a solution from the hypothesis space via architecture can outperform soft loss penalties. Strengths include the internal control (physics-informed loss), agreement between MI and UQ on the failure locus, and the quantitative UQ result. The long-range FPP setting is underexplored; the approach could generalize to other single-shot phase problems where physical consistency must be enforced without fitting parameters.
major comments (2)
- [Benchmark description and § on experiments] Benchmark and experimental sections: All diagnosis, repair, and verification (including the three probes and UQ filtering) are performed exclusively on the photorealistic synthetic renderer with no reported real-camera long-range FPP images or hardware validation. This is load-bearing for the claim that object-boundary shape priors are the operative failure mode, because the probes could respond to renderer-specific cues (perfect edges, idealized inverse-square falloff, absent sensor noise/speckle) rather than physical long-range phenomena.
- [PhiCalNet architecture section] PhiCalNet description and ablation: The fixed differentiable calibration layer is presented as removing the shape-prior solution from the hypothesis space, yet the manuscript does not report whether this layer is derived from the same synthetic renderer parameters or from independent calibration; if the former, the architectural constraint may still embed renderer-specific assumptions.
minor comments (2)
- [Data generation paragraph] The abstract states 15,600 images but the full text should expand the object selection criteria, rendering parameter ranges, and exact noise model to support reproducibility claims.
- [Methods] Notation for wrapped phase output and the calibration mapping could be formalized with an equation to clarify that no learned parameters remain in the phase-to-depth step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of the work. We address each major comment below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: [Benchmark description and § on experiments] Benchmark and experimental sections: All diagnosis, repair, and verification (including the three probes and UQ filtering) are performed exclusively on the photorealistic synthetic renderer with no reported real-camera long-range FPP images or hardware validation. This is load-bearing for the claim that object-boundary shape priors are the operative failure mode, because the probes could respond to renderer-specific cues (perfect edges, idealized inverse-square falloff, absent sensor noise/speckle) rather than physical long-range phenomena.
Authors: We agree this is a substantive limitation. The synthetic renderer was constructed to model the dominant physical effects of the long-range regime (inverse-square falloff, reduced SNR, single-shot ambiguity), and the three MI probes plus conformal UQ converge on the same failure mode. Nevertheless, renderer-specific artifacts cannot be fully ruled out without real hardware data. We will add an explicit limitations subsection discussing the domain gap and the need for future physical validation; no real-camera images are available in the current study. revision: partial
-
Referee: [PhiCalNet architecture section] PhiCalNet description and ablation: The fixed differentiable calibration layer is presented as removing the shape-prior solution from the hypothesis space, yet the manuscript does not report whether this layer is derived from the same synthetic renderer parameters or from independent calibration; if the former, the architectural constraint may still embed renderer-specific assumptions.
Authors: The calibration layer implements the standard phase-to-depth mapping using the known camera/projector intrinsics and baseline geometry employed by the renderer; these parameters are obtained from the same geometric calibration procedure that would be performed on physical hardware and are independent of object shape or texture. We will revise the architecture section to state this explicitly and to note that the layer contains no learned parameters or object-specific information. revision: yes
- No real-camera long-range FPP images or hardware validation are available in the current study.
Circularity Check
No circularity: derivation relies on empirical diagnostics and architectural constraint, not self-referential reduction
full rationale
The paper's core argument—that the UNet baseline exploits object-boundary shape priors (diagnosed via linear probing, Grad-CAM, and flat-plane OOD tests) and that PhiCalNet removes this via an architectural change to wrapped-phase output plus fixed calibration layer—is supported by an internal control (physics-informed loss yields no gain) and conformal UQ verification on the same benchmark. No equations, fitted parameters, or self-citations are shown to reduce the 3.3× MAE improvement to a tautology or prior result by construction. The derivation chain is self-contained against the reported synthetic benchmark and interpretability probes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2016 , publisher=
High-Speed 3D Imaging with Digital Fringe Projection Techniques , author=. 2016 , publisher=
2016
-
[2]
Advances in optics and photonics , volume=
Structured-light 3D surface imaging: a tutorial , author=. Advances in optics and photonics , volume=. 2011 , publisher=
2011
-
[3]
Wiley Encyclopedia of Electrical and Electronics Engineering , pages=
Structured Light Techniques and Applications , author=. Wiley Encyclopedia of Electrical and Electronics Engineering , pages=. 2016 , publisher=
2016
-
[4]
Optics and lasers in engineering , volume=
Recent progresses on real-time 3D shape measurement using digital fringe projection techniques , author=. Optics and lasers in engineering , volume=. 2010 , publisher=
2010
-
[5]
Scientific reports , volume=
Temporal phase unwrapping using deep learning , author=. Scientific reports , volume=. 2019 , publisher=
2019
-
[6]
Optics express , volume=
Deep neural networks for single shot structured light profilometry , author=. Optics express , volume=. 2019 , publisher=
2019
-
[7]
Light: Science & Applications , volume=
Deep learning in optical metrology: a review , author=. Light: Science & Applications , volume=. 2022 , publisher=
2022
-
[8]
Advanced Photonics Nexus , number=
Kaiqiang Wang and Qian Kemao and Jianglei Di and Jianlin Zhao , title=. Advanced Photonics Nexus , number=. 2022 , doi=
2022
-
[9]
2019 , author=
Fringe pattern denoising based on deep learning , journal=. 2019 , author=
2019
-
[10]
Optical Engineering , volume=
Hformer: Hybrid convolutional neural network transformer network for fringe order prediction in phase unwrapping of fringe projection , author=. Optical Engineering , volume=. 2022 , publisher=
2022
-
[11]
Optics Express , volume=
Single-shot fringe projection profilometry based on deep learning and computer graphics , author=. Optics Express , volume=. 2021 , publisher=
2021
-
[12]
Sensors , volume=
Single-shot 3D shape reconstruction using structured light and deep convolutional neural networks , author=. Sensors , volume=. 2020 , publisher=
2020
-
[13]
Optics Express , volume=
Deep-learning-enabled single-shot fringe projection profilometry based on inner shifting-phase encoding , author=. Optics Express , volume=. 2025 , publisher=
2025
-
[14]
Measurement , volume=
End-to-end single-shot composite color FPP network for multiple separated objects reconstruction , author=. Measurement , volume=. 2025 , publisher=
2025
-
[15]
2021 , publisher=
Synthetic data for deep learning , author=. 2021 , publisher=
2021
-
[16]
Trends in cognitive sciences , volume=
Next-generation deep learning based on simulators and synthetic data , author=. Trends in cognitive sciences , volume=. 2022 , publisher=
2022
-
[17]
Zheng and S
Y. Zheng and S. Wang and Q. Li and B. Li , title=. Optics Express , volume=. 2020 , publisher=
2020
-
[18]
Optical Review , volume=
Fringe projection profilometry system verification for 3D shape measurement using virtual space of game engine , author=. Optical Review , volume=. 2021 , publisher=
2021
-
[19]
IEEE Access , volume=
Measurement Simulation System of Fringe Projection Profilometry Based on Ray Tracing , author=. IEEE Access , volume=. 2023 , publisher=
2023
-
[20]
Optical Review , pages=
Deep-learning-assisted single-shot 3D shape and color measurement using color fringe projection profilometry , author=. Optical Review , pages=. 2025 , publisher=
2025
-
[21]
VIRTUS-FPP: Virtual Sensor Modeling for Fringe Projection Profilometry in NVIDIA Isaac Sim , year=
Haroon, Adam and Lakshman, Anush and Balasubramaniam, Badrinath and Li, Beiwen , journal=. VIRTUS-FPP: Virtual Sensor Modeling for Fringe Projection Profilometry in NVIDIA Isaac Sim , year=
-
[22]
High-resolution real-time 360
Qian, Jiaming and Feng, Shijie and Xu, Mingzhu and Tao, Tianyang and Shang, Yuhao and Chen, Qian and Zuo, Chao , journal=. High-resolution real-time 360. 2021 , publisher=
2021
-
[23]
Optical Metrology and Inspection for Industrial Applications IV , volume=
Three-dimensional surface inspection for semiconductor components with fringe projection profilometry , author=. Optical Metrology and Inspection for Industrial Applications IV , volume=. 2016 , organization=
2016
-
[24]
Precision Engineering , volume=
Machine learning enhanced high dynamic range fringe projection profilometry for in-situ layer-wise surface topography measurement during LPBF additive manufacturing , author=. Precision Engineering , volume=. 2023 , publisher=
2023
-
[25]
Measurement , volume=
A systematic study and framework of fringe projection profilometry with improved measurement performance for in-situ LPBF process monitoring , author=. Measurement , volume=. 2022 , publisher=
2022
-
[26]
Dimensional Optical Metrology and Inspection for Practical Applications XIII , volume=
Autonomous robotic 3D scanning for smart factory planning , author=. Dimensional Optical Metrology and Inspection for Practical Applications XIII , volume=. 2024 , organization=
2024
-
[27]
Robotics and Computer-Integrated Manufacturing , volume=
Robotic measurement system based on cooperative optical profiler integrating fringe projection with photometric stereo for highly reflective workpiece , author=. Robotics and Computer-Integrated Manufacturing , volume=. 2024 , publisher=
2024
-
[28]
What Is Isaac Sim? , year=
-
[29]
ACM transactions on graphics (TOG) , volume=
Optix: a general purpose ray tracing engine , author=. ACM transactions on graphics (TOG) , volume=. 2010 , publisher=
2010
-
[30]
2025 , howpublished=
Universal Scene Description (. 2025 , howpublished=
2025
-
[31]
2025 , howpublished=
2025
-
[32]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Close the Sim2real Gap via Physically-based Structured Light Synthetic Data Simulation , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[33]
2015 , publisher=
Ronneberger, Olaf and Fischer, Philipp and Brox, Thomas , booktitle=. 2015 , publisher=
2015
-
[34]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Image-to-Image Translation with Conditional Adversarial Networks , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[35]
High-Resolution Image Synthesis and Semantic Manipulation with Conditional
Wang, Ting-Chun and Liu, Ming-Yu and Zhu, Jun-Yan and Tao, Andrew and Kautz, Jan and Catanzaro, Bryan , booktitle=. High-Resolution Image Synthesis and Semantic Manipulation with Conditional
-
[36]
Frontiers of Architectural Research , year=
A dual-aspect evaluation framework for architectural-like plan generation via pix2pix series algorithms , author=. Frontiers of Architectural Research , year=
-
[37]
International Manufacturing Science and Engineering Conference , volume=
Single Shot 3D Shape Measurement of Non-Volatile Data Storage Devices , author=. International Manufacturing Science and Engineering Conference , volume=. 2023 , organization=
2023
-
[38]
2009 , organization=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li , booktitle=. 2009 , organization=
2009
-
[39]
Microsoft
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll. Microsoft. Computer Vision--ECCV 2014: 13th European Conference , pages=. 2014 , organization=
2014
-
[40]
The International Journal of Robotics Research , volume=
Yale-CMU-Berkeley dataset for robotic manipulation research , author=. The International Journal of Robotics Research , volume=. 2017 , publisher=
2017
-
[41]
2025 , howpublished =
2025
-
[42]
2003 , publisher=
Multiple view geometry in computer vision , author=. 2003 , publisher=
2003
-
[43]
Optics and Lasers in Engineering , volume=
Status, challenges, and future perspectives of fringe projection profilometry , author=. Optics and Lasers in Engineering , volume=. 2020 , publisher=
2020
-
[44]
Pattern recognition , volume=
Pattern codification strategies in structured light systems , author=. Pattern recognition , volume=. 2004 , publisher=
2004
-
[45]
Applied optics , volume=
Three-dimensional vision based on a combination of Gray-code and phase-shift light projection: analysis and compensation of the systematic errors , author=. Applied optics , volume=. 1999 , publisher=
1999
-
[46]
Optics and lasers in engineering , volume=
Calibration of fringe projection profilometry: A comparative review , author=. Optics and lasers in engineering , volume=. 2021 , publisher=
2021
-
[47]
Materials , volume=
Zapico, Pablo and Meana, Victor and Cuesta, Eduardo and Mateos, Sabino , title=. Materials , volume=. 2023 , doi=
2023
-
[48]
Micromachines , volume=
Ou, Jia and Xu, Tingfa and Gan, Xiaochuan and He, Xuejun and Li, Yan and Qu, Jiansu and Zhang, Wei and Cai, Cunliang , title=. Micromachines , volume=. 2022 , doi=
2022
-
[49]
Optical Metrology and Inspection for Industrial Applications III , volume=
Experimental study for the influence of surface characteristics on the fringe patterns , author=. Optical Metrology and Inspection for Industrial Applications III , volume=. 2014 , organization=
2014
-
[50]
2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=
Domain randomization for transferring deep neural networks from simulation to the real world , author=. 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=. 2017 , organization=
2017
-
[51]
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Transunet: Transformers make strong encoders for medical image segmentation , author=. arXiv preprint arXiv:2102.04306 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Distill , volume=
Zoom In: An Introduction to Circuits , author=. Distill , volume=. 2020 , doi=
2020
-
[53]
Understanding intermediate layers using linear classifier probes
Understanding intermediate layers using linear classifier probes , author=. arXiv preprint arXiv:1610.01644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
and Cogswell, Michael and Das, Abhishek and Vedantam, Ramakrishna and Parikh, Devi and Batra, Dhruv , booktitle=
Selvaraju, Ramprasaath R. and Cogswell, Michael and Das, Abhishek and Vedantam, Ramakrishna and Parikh, Devi and Batra, Dhruv , booktitle=. Grad-
-
[55]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[56]
Journal of Computational physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational physics , volume=. 2019 , publisher=
2019
-
[57]
Nature Reviews Physics , volume=
Physics-informed machine learning , author=. Nature Reviews Physics , volume=. 2021 , publisher=
2021
-
[58]
Advances in neural information processing systems , volume=
Characterizing possible failure modes in physics-informed neural networks , author=. Advances in neural information processing systems , volume=
-
[59]
Computer Methods in Applied Mechanics and Engineering , volume=
Respecting causality for training physics-informed neural networks , author=. Computer Methods in Applied Mechanics and Engineering , volume=. 2024 , publisher=
2024
-
[60]
Radio science , volume=
Satellite radar interferometry: Two-dimensional phase unwrapping , author=. Radio science , volume=. 1988 , publisher=
1988
-
[61]
Optics and lasers in engineering , volume=
Temporal phase unwrapping algorithms for fringe projection profilometry: A comparative review , author=. Optics and lasers in engineering , volume=. 2016 , publisher=
2016
-
[62]
Foundations and Trends in Machine Learning , volume=
Conformal Prediction: A Gentle Introduction , author=. Foundations and Trends in Machine Learning , volume=. 2023 , doi=
2023
-
[63]
and Weinberger, Kilian Q
Huang, Gao and Li, Yixuan and Pleiss, Geoff and Liu, Zhuang and Hopcroft, John E. and Weinberger, Kilian Q. , booktitle=. Snapshot Ensembles: Train 1, Get
-
[64]
arXiv preprint arXiv:2601.02572 , year=
Heteroscedastic Snapshot-Ensemble Uncertainty Quantification for Single-Shot Fringe Projection Profilometry , author=. arXiv preprint arXiv:2601.02572 , year=
-
[65]
What Uncertainties Do We Need in
Kendall, Alex and Gal, Yarin , booktitle=. What Uncertainties Do We Need in
-
[66]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[67]
2005 , publisher=
Algorithmic Learning in a Random World , author=. 2005 , publisher=
2005
-
[68]
Information Fusion , volume=
A Review of Uncertainty Quantification in Deep Learning: Techniques, Applications and Challenges , author=. Information Fusion , volume=. 2021 , publisher=
2021
-
[69]
Advanced photonics , volume=
Fringe pattern analysis using deep learning , author=. Advanced photonics , volume=. 2019 , publisher=
2019
-
[70]
Applied optics , volume=
Real-time 3D shape measurement using 3LCD projection and deep machine learning , author=. Applied optics , volume=. 2019 , publisher=
2019
-
[71]
Journal of Imaging , volume=
Deep learning for single-shot structured light profilometry: A comprehensive dataset and performance analysis , author=. Journal of Imaging , volume=. 2024 , publisher=
2024
-
[72]
Light: Science & Applications , volume=
Modeling the measurement precision of fringe projection profilometry , author=. Light: Science & Applications , volume=. 2023 , publisher=
2023
-
[73]
International Journal of Medical Informatics , volume=
Explainability and uncertainty: Two sides of the same coin for enhancing the interpretability of deep learning models in healthcare , author=. International Journal of Medical Informatics , volume=. 2025 , publisher=
2025
-
[74]
Sciurus: Shared circuits for interpretable uncertainty representations in language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[75]
and Adam Haroon and Beiwen Li , title =
Anush Lakshman S. and Adam Haroon and Beiwen Li , title =. Photonic Instrumentation Engineering XIII , editor =. 2026 , doi =
2026
-
[76]
Journal of biomedical optics , volume=
Deep-learning-based endoscopic single-shot fringe projection profilometry , author=. Journal of biomedical optics , volume=. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.