AtlasVid: Efficient Ultra-High-Resolution Long Video Generation via Decoupled Global-Local Modeling
Pith reviewed 2026-05-20 18:20 UTC · model grok-4.3
The pith
Decoupled global-local modeling trains video generators at low resolution to produce ultra-high-resolution long videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
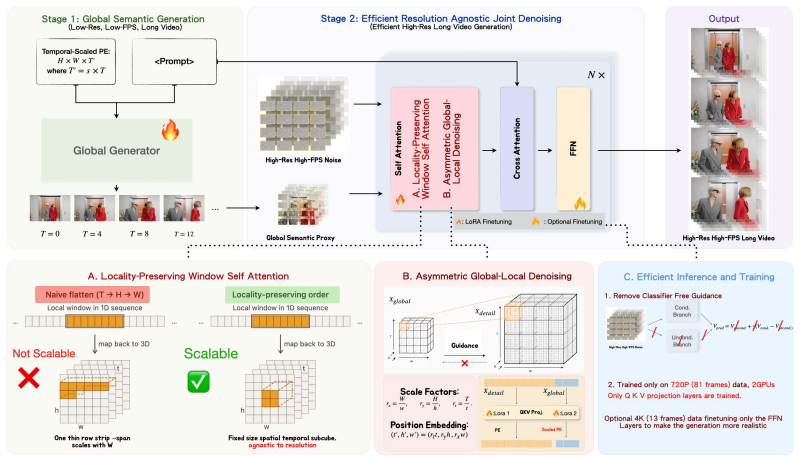
Existing video diffusion models encode strong local priors; the bottleneck is efficient global modeling at scale. AtlasVid therefore decouples the problem: a global branch generates a low-resolution low-FPS semantic proxy via temporally scaled RoPE to extend temporal horizon without raising token count, while a high-resolution branch performs joint denoising under reordered spatiotemporal windows and asymmetric global-local attention that injects aligned guidance while preserving pretrained local ability.
What carries the argument
Temporally scaled RoPE global semantic proxy that guides joint denoising in a high-resolution branch equipped with hierarchical locality-preserving attention.
If this is right
- Training occurs only at 720P yet the model directly synthesizes 4K videos longer than 10 seconds without full retraining.
- Generation runs 60.9 times faster than native high-resolution approaches while using less training compute.
- Quality exceeds that of models trained from scratch at 4K because local priors remain untouched.
- The framework supports resolution-agnostic deployment for arbitrary output sizes after a single low-resolution training run.
Where Pith is reading between the lines
- The same proxy-plus-detail split could be tested on other generative tasks where global structure and local texture must be handled at different scales.
- If the proxy guidance proves robust, the method could lower the barrier to creating custom high-resolution video models without access to large native 4K datasets.
- Extending the temporal scaling factor in RoPE might allow even longer coherent videos without further increases in memory footprint.
Load-bearing premise
The low-resolution low-FPS global proxy supplies enough aligned semantic guidance that joint denoising can keep both long-range temporal coherence and fine spatial details intact.
What would settle it
Generate the same prompt at 4K with the proposed method and with a native 4K baseline; if the decoupled outputs show visibly broken motion continuity or missing fine detail while the native baseline does not, the sufficiency of the low-res proxy is refuted.
Figures









read the original abstract
Recent diffusion-based video generators have achieved remarkable visual fidelity and prompt controllability, yet scaling them to ultra-high-resolution (UHR) long videos remains prohibitively expensive. The difficulty is especially pronounced for long single-shot generation where a continuous scene must preserve global temporal coherence, and fine-grained spatial details without relying on clip transitions or autoregressive shot stitching. In this work, we revisit this challenge from the perspective of decoupled modeling. We argue that existing video diffusion models already encode strong local visual priors, while the main bottleneck lies in efficiently extending global spatiotemporal modeling as resolution and duration increase. Based on this insight, we propose AtlaVid, a decoupled global-local framework for efficient UHR long video generation. AtlaVid first generates a low-resolution and low-FPS global semantic proxy via temporally scaled RoPE, thereby extending the temporal horizon without increasing the training token count. Guided by this proxy, a high-resolution detail branch performs joint denoising with hierarchical locality-preserving attention. Reordered spatiotemporal windows preserve geometric locality and asymmetric global-local attention injects aligned semantic guidance and preserves the model's pretrained ability. This design enables resolution-agnostic training: the model is trained only at 720P with lightweight LoRA adaptation, yet generalizes directly to 4K and beyond for longer (>10s) video synthesis. Experiments show that AtlaVid substantially improves the efficiency of ultra-high-resolution long video generation, achieving high-quality UHR long video generation with 60.9x speed up and significantly less training cost and even better performance than native 4K video generators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AtlasVid, a decoupled global-local framework for efficient ultra-high-resolution long video generation. It generates a low-resolution low-FPS global semantic proxy using temporally scaled RoPE to extend the temporal horizon without increasing token count, then performs joint denoising in a high-resolution detail branch guided by hierarchical locality-preserving attention and asymmetric global-local attention. The design claims to enable resolution-agnostic training at 720P with lightweight LoRA adaptation that generalizes directly to 4K and beyond for videos longer than 10s, achieving a 60.9x speedup and better performance than native 4K generators while preserving global temporal coherence and fine spatial details.
Significance. If the empirical claims hold, the work would be significant for video diffusion models by demonstrating a practical path to scale beyond current resolution and duration limits without full high-resolution retraining. The emphasis on reusing pretrained local priors and decoupling global semantics via a proxy could reduce compute barriers in the field, provided the guidance mechanism proves robust.
major comments (3)
- [Abstract] Abstract: the central generalization claim (resolution-agnostic training at 720P generalizing to 4K with 60.9x speedup) rests on unshown experiments; no quantitative metrics, baselines, error bars, or ablation details are supplied to support the speedup or coherence preservation over >10s sequences.
- [Method] Method description: the temporally scaled RoPE proxy operates at reduced FPS while the detail branch performs joint denoising at native 4K; no equations or analysis demonstrate that upsampled guidance from the low-FPS proxy maintains frame-to-frame temporal coherence without drift or hallucination in long continuous shots.
- [Experiments] Experiments section: the claim that reordered spatiotemporal windows and hierarchical attention preserve both global coherence and fine details without high-resolution training data requires explicit ablations on proxy FPS/resolution and quantitative comparisons against native 4K baselines to be load-bearing for the resolution-agnostic assertion.
minor comments (2)
- [Method] Clarify notation for 'temporally scaled RoPE' versus standard RoPE in the method section to avoid ambiguity in how temporal scaling is implemented.
- [Discussion] Add a short discussion of potential failure modes when the low-FPS proxy provides insufficient granularity for very long shots.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below. We agree that additional clarity, quantitative details, and analysis will strengthen the manuscript and have revised accordingly where the comments identify gaps in presentation or supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central generalization claim (resolution-agnostic training at 720P generalizing to 4K with 60.9x speedup) rests on unshown experiments; no quantitative metrics, baselines, error bars, or ablation details are supplied to support the speedup or coherence preservation over >10s sequences.
Authors: We acknowledge that the abstract, being a concise summary, does not contain the full experimental details. The quantitative metrics supporting the 60.9x speedup (measured as the ratio of wall-clock inference time on identical hardware for equivalent-length 4K outputs), coherence metrics over sequences longer than 10s, baseline comparisons, and error bars from repeated runs are reported in Section 4 (Experiments) and the associated tables/figures. To address the concern directly, we will revise the abstract to include a brief parenthetical reference to these results and the specific sections where they appear, ensuring the central claims are transparently linked to the supporting evidence without exceeding abstract length constraints. revision: partial
-
Referee: [Method] Method description: the temporally scaled RoPE proxy operates at reduced FPS while the detail branch performs joint denoising at native 4K; no equations or analysis demonstrate that upsampled guidance from the low-FPS proxy maintains frame-to-frame temporal coherence without drift or hallucination in long continuous shots.
Authors: We agree that the current method description would benefit from explicit equations and analysis on temporal coherence. In the revised manuscript we will add a new subsection (or expanded paragraph) in Section 3 that includes: (1) the mathematical formulation of temporally scaled RoPE and the upsampling operator from the low-FPS proxy to the high-resolution branch; (2) a short derivation showing how the asymmetric global-local attention and locality-preserving mechanism align semantic guidance across frames; and (3) an empirical coherence analysis (e.g., frame-to-frame optical flow consistency and drift metrics) on long continuous shots. These additions will directly demonstrate the absence of drift or hallucination under the proposed guidance. revision: yes
-
Referee: [Experiments] Experiments section: the claim that reordered spatiotemporal windows and hierarchical attention preserve both global coherence and fine details without high-resolution training data requires explicit ablations on proxy FPS/resolution and quantitative comparisons against native 4K baselines to be load-bearing for the resolution-agnostic assertion.
Authors: We appreciate this observation. While the current experiments section contains comparisons to native 4K generators and some attention-related ablations, we concur that more targeted ablations on proxy FPS and resolution are needed to make the resolution-agnostic claim fully load-bearing. In the revision we will add a dedicated ablation study (new table or figure) that systematically varies proxy FPS (e.g., 1, 2, 4 fps) and resolution, reporting quantitative metrics including FVD, temporal coherence scores, and direct side-by-side comparisons against native 4K training baselines. This will provide the explicit evidence requested. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core derivation introduces independent architectural elements including temporally scaled RoPE for low-resolution low-FPS global proxy generation and hierarchical locality-preserving attention with reordered spatiotemporal windows for the high-resolution detail branch. These choices are presented as design decisions that enable resolution-agnostic training at 720P with LoRA adaptation and direct generalization to 4K, without any equations or steps that reduce the claimed speedup, coherence preservation, or performance metrics back to fitted parameters or quantities extracted from the target high-resolution outputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a load-bearing way that collapses the argument to prior author work or tautological renaming; the decoupling insight and proxy-guidance mechanism stand as self-contained modeling assumptions whose validity is left to empirical validation rather than definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing video diffusion models already encode strong local visual priors
- domain assumption Temporally scaled RoPE extends temporal horizon without increasing token count
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.lean (and Cost/FunctionalEquation.lean)reality_from_one_distinction; washburn_uniqueness_aczel; alexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
low-resolution and low-FPS global semantic proxy via temporally scaled RoPE... reordered spatiotemporal windows... asymmetric global-local attention
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Vladimir Arkhipkin, Vladimir Korviakov, Nikolai Gerasimenko, Denis Parkhomenko, Viacheslav Vasilev, Alexey Letunovskiy, Nikolai Vaulin, Maria Kovaleva, Ivan Kirillov, Lev Novitskiy, et al. Kandinsky 5.0: A family of foundation models for image and video generation.arXiv preprint arXiv:2511.14993,
-
[2]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025a. Junsong Chen, Yuyang Zhao, Jincheng Yu, Ruihang Chu, Junyu Chen, Shuai Yang, Xianbang Wang, Yicheng Pan, Daquan Zhou, Huan Ling, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https://deepmind. google/technologies/veo/. Zhentao Fan, Zongzuo Wang, and Weiwei Zhang. Taocache: Structure-maintained video generation acceleration.arXiv preprint arXiv:2508.08978,
-
[5]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Venhancer: Generative space-time enhancement for video generation
Jingwen He, Tianfan Xue, Dongyang Liu, Xinqi Lin, Peng Gao, Dahua Lin, Yu Qiao, Wanli Ouyang, and Ziwei Liu. Venhancer: Generative space-time enhancement for video generation.arXiv preprint arXiv:2407.07667,
-
[8]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
In-context lora for diffusion transformers.arXiv preprint arXiv:2410.23775, 2024a
Lianghua Huang, Wei Wang, Zhi-Fan Wu, Yupeng Shi, Huanzhang Dou, Chen Liang, Yutong Feng, Yu Liu, and Jingren Zhou. In-context lora for diffusion transformers.arXiv preprint arXiv:2410.23775, 2024a. Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint...
-
[10]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Skyreels-v3 technique report.arXiv preprint arXiv:2601.17323,
Debang Li, Zhengcong Fei, Tuanhui Li, Yikun Dou, Zheng Chen, Jiangping Yang, Mingyuan Fan, Jingtao Xu, Jiahua Wang, Baoxuan Gu, et al. Skyreels-v3 technique report.arXiv preprint arXiv:2601.17323,
-
[12]
Open-Sora Plan: Open-Source Large Video Generation Model
Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Liuhan Chen, et al. Open-sora plan: Open-source large video generation model. arXiv preprint arXiv:2412.00131,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Timestep embedding tells: It’s time to cache for video diffusion model, 2024
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. arXiv preprint arXiv:2411.19108,
-
[14]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model
Guoqing Ma, Haoyang Huang, Kun Yan, Liangyu Chen, Nan Duan, Shengming Yin, Changyi Wan, Ranchen Ming, Xiaoniu Song, Xing Chen, et al. Step-video-t2v technical report: The practice, challenges, and future of video foundation model.arXiv preprint arXiv:2502.10248, 2025a. Zehong Ma, Longhui Wei, Feng Wang, Shiliang Zhang, and Qi Tian. Magcache: Fast video ge...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Haonan Qiu, Ning Yu, Ziqi Huang, Paul Debevec, and Ziwei Liu. Cinescale: Free lunch in high- resolution cinematic visual generation.arXiv preprint arXiv:2508.15774,
-
[17]
HunyuanVideo 1.5 Technical Report
URL https: //arxiv.org/abs/2511.18870. Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean conference on computer vision, pages 402–419. Springer,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Yunfeng Wu, Jiayi Song, Zhenxiong Tan, Zihao He, and Songhua Liu. Freeswim: Revisiting sliding- window attention mechanisms for training-free ultra-high-resolution video generation.arXiv preprint arXiv:2511.14712,
-
[21]
Zhucun Xue, Jiangning Zhang, Teng Hu, Haoyang He, Yinan Chen, Yuxuan Cai, Yabiao Wang, Chengjie Wang, Yong Liu, Xiangtai Li, et al. Ultravideo: High-quality uhd video dataset with comprehensive captions.arXiv preprint arXiv:2506.13691,
-
[22]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024a. Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli ...
-
[23]
Chen Zhao, Jiawei Chen, Hongyu Li, Zhuoliang Kang, Shilin Lu, Xiaoming Wei, Kai Zhang, Jian Yang, and Ying Tai. Luve: Latent-cascaded ultra-high-resolution video generation with dual frequency experts.arXiv preprint arXiv:2602.11564,
-
[24]
Videogen-of-thought: Step-by-step generating multi-shot video with minimal manual intervention, 2025
Mingzhe Zheng, Yongqi Xu, Haojian Huang, Xuran Ma, Yexin Liu, Wenjie Shu, Yatian Pang, Feilong Tang, Qifeng Chen, Harry Yang, et al. Videogen-of-thought: A collaborative framework for multi-shot video generation.arXiv preprint arXiv:2412.02259, 3(6),
-
[25]
Junhao Zhuang, Shi Guo, Xin Cai, Xiaohui Li, Yihao Liu, Chun Yuan, and Tianfan Xue. Flashvsr: To- wards real-time diffusion-based streaming video super-resolution.arXiv preprint arXiv:2510.12747,
-
[26]
for 15K iterations. Mixed-precision (bf16) is used throughout, and we adopt a flow-matching objective consistent with the Wan2.1 base model. Stage 1 (semantic generator).We finetune the base model with temporal-scale RoPE ( rt=4) on 720P×81 -frame clips sub-sampled at 4 fps, so that an 81-frame proxy spans an effective horizon of ∼20seconds at16fps target...
work page 2025
-
[27]
End-to-end runtime includes text encoding, both denoising stages, and 3D-V AE decoding. C Detailed Metric Definitions This section formalises the metrics referenced in Table 2 and the ablation tables of the main paper. For all metrics, v∈R T×H×W×3 denotes a video. Higher-is-better metrics are marked ↑ and lower-is-better↓. C.1 High-Definition Metrics The ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.