Off-Policy Evaluation for Missingness-Aware Policies in MDPs with Rewards Missing Not at Random
Pith reviewed 2026-06-26 15:36 UTC · model grok-4.3
The pith
Future states as shadow variables identify the full-data conditional mean reward under reward-dependent missingness in offline RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By formalizing a reward-dependent propensity model and using future states as shadow variables, the full-data conditional mean reward is identified. A bridge function then recovers this quantity without explicitly modeling the MNAR mechanism and is estimated by a min-max procedure that avoids double sampling. These identification results support an Fitted-Q-Evaluation-style estimator that propagates the recovered rewards while permitting target policies to depend on past missingness indicators, with consistency and finite-sample error bounds established for the resulting OPE estimator.
What carries the argument
Bridge function that recovers the conditional mean reward from observed data using future states as shadow variables, estimated by min-max optimization.
If this is right
- The OPE estimator is consistent for the value of any target policy whose decisions may depend on past missingness indicators.
- Finite-sample error bounds are available for the value estimates produced by the propagated recovered rewards.
- The method produces lower error than standard OPE approaches that ignore MNAR on both simulated trajectories and the MIMIC-III Sepsis cohort.
- No explicit parametric model of the MNAR mechanism is required once the bridge function is estimated.
Where Pith is reading between the lines
- Datasets that record future states even when rewards are absent become especially valuable for policy evaluation under this identification strategy.
- The same shadow-variable logic could be tested on other sequential missing-data problems where a later observed variable is independent of the target quantity given the observed history.
- If the min-max procedure can be replaced by a direct regression under additional assumptions, computational cost for large batches would decrease.
Load-bearing premise
Future states must satisfy the conditional independence and completeness conditions that allow them to identify the reward-dependent missingness mechanism.
What would settle it
In a controlled simulation where the true conditional mean reward is known and MNAR is active, the bridge-function estimator would fail to recover the correct value if the completeness condition between future states and the missingness indicator is violated.
Figures

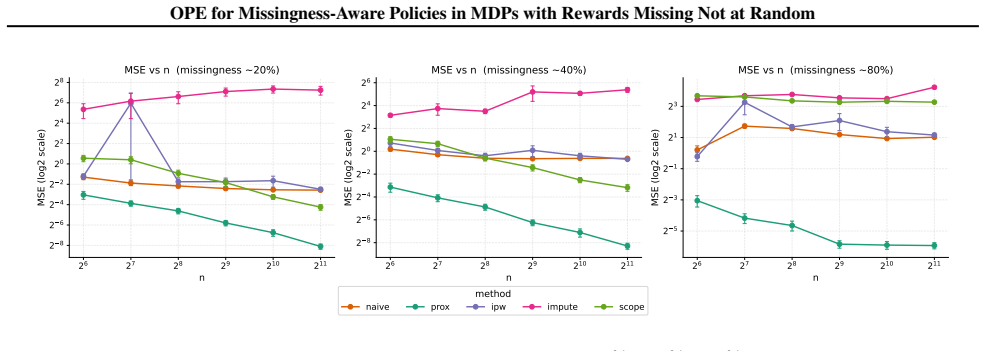
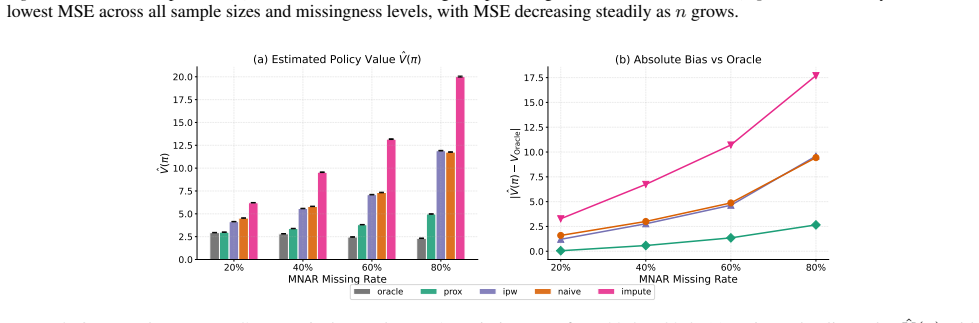



read the original abstract
In offline Reinforcement Learning, immediate rewards in logged batch data are often unobserved due to sparse or irregular record-keeping, or censored beyond certain reward values. This issue arises in practical settings, including health care and marketing. We investigate off-policy evaluation (OPE) in finite-horizon Markov decision processes when rewards are missing not at random (MNAR), which breaks ignorability and induces selection bias even after conditioning on states and actions. To address this, we formalize a reward-dependent propensity model and use future states as shadow variables to identify the full-data conditional mean reward. We further introduce a bridge function that recovers the conditional mean reward without explicitly modeling the MNAR mechanism, and estimate it via a min-max procedure to avoid double sampling. Building upon these identification results, we propose an Fitted-Q-Evaluation-style estimator that propagates the recovered rewards while allowing target policies to depend on past missingness indicators. Finally, we establish consistency and finite-sample error bounds for our OPE estimator, and show through experiments the strong performance of our method compared to existing methods on simulated and MIMIC-III Sepsis data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses off-policy evaluation (OPE) in finite-horizon MDPs when rewards are missing not at random (MNAR). It formalizes a reward-dependent propensity model, uses future states as shadow variables to identify the full-data conditional mean reward under conditional independence and completeness conditions, introduces a bridge function recovered via a min-max procedure (avoiding explicit MNAR modeling or double sampling), proposes an FQE-style estimator that propagates recovered rewards while allowing target policies to depend on past missingness indicators, establishes consistency and finite-sample error bounds, and reports strong empirical performance versus baselines on simulated data and MIMIC-III Sepsis.
Significance. If the identification assumptions hold and the bounds are rigorous, the work offers a practically relevant advance for OPE under MNAR rewards in domains such as healthcare, by recovering rewards via shadow variables and bridge functions without requiring double sampling. The finite-sample bounds and missingness-aware policy handling constitute concrete strengths.
major comments (2)
- [Identification result / abstract] The identification result (abstract and §3) rests on the conditional independence R ⊥ S' | (S, A, Y) and the completeness condition on P(S' | S, A, Y) for future states S' to serve as valid shadow variables; these are stated as required but the manuscript supplies no diagnostic, sensitivity analysis, or empirical verification that they hold in the MDP setting. Violation would bias the recovered conditional mean rewards and propagate directly into the FQE-style estimator.
- [Theoretical results] The abstract and theoretical sections claim consistency and finite-sample error bounds for the OPE estimator, yet the manuscript provides no derivation details, proof sketches, or data-exclusion rules supporting these claims, rendering it impossible to assess whether the math establishes the stated rates.
minor comments (2)
- [§2] Notation for the missingness indicator and its dependence on past history could be made more explicit in the problem setup to aid readability.
- [Estimation procedure] The min-max optimization for the bridge function is described at a high level; a brief algorithmic pseudocode or implementation note would clarify how double sampling is avoided in practice.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our paper addressing off-policy evaluation for missingness-aware policies in MDPs with rewards missing not at random. We respond to each major comment below.
read point-by-point responses
-
Referee: [Identification result / abstract] The identification result (abstract and §3) rests on the conditional independence R ⊥ S' | (S, A, Y) and the completeness condition on P(S' | S, A, Y) for future states S' to serve as valid shadow variables; these are stated as required but the manuscript supplies no diagnostic, sensitivity analysis, or empirical verification that they hold in the MDP setting. Violation would bias the recovered conditional mean rewards and propagate directly into the FQE-style estimator.
Authors: The conditional independence follows directly from the Markov property of the finite-horizon MDP, under which the next state S' is independent of the current reward R given (S, A). The completeness condition is the standard technical requirement from the shadow-variable identification literature that ensures the bridge function is well-defined. We agree that the manuscript would benefit from explicit discussion of these points. In revision we will add a dedicated subsection on practical verification strategies (e.g., testable implications under the MDP structure) together with a sensitivity analysis that perturbs the conditional independence assumption and reports the resulting OPE bias on both simulated and MIMIC-III data. revision: yes
-
Referee: [Theoretical results] The abstract and theoretical sections claim consistency and finite-sample error bounds for the OPE estimator, yet the manuscript provides no derivation details, proof sketches, or data-exclusion rules supporting these claims, rendering it impossible to assess whether the math establishes the stated rates.
Authors: The complete proofs of consistency and the finite-sample bounds, including all derivation steps and the precise data-exclusion rules used to control the remainder terms, appear in the supplementary appendix. To improve readability we will insert concise proof sketches (one paragraph each for the identification step, the bridge-function estimation error, and the propagated FQE error) into the main theoretical section and will restate the data-exclusion rules explicitly in the statement of the finite-sample theorem. revision: yes
Circularity Check
No significant circularity; identification rests on external assumptions
full rationale
The paper's core identification result for the full-data conditional mean reward relies on posited conditional independence R ⊥ S' | (S,A,Y) and completeness conditions for future states as shadow variables; these are external modeling assumptions, not quantities defined in terms of the estimator or recovered via self-referential fitting. The bridge function and min-max procedure are constructed to invert the MNAR mechanism under those assumptions, and the subsequent FQE-style OPE estimator propagates the identified rewards without reducing the target to a parameter fitted from the same data by construction. No load-bearing self-citations or ansatzes imported from prior author work appear in the derivation chain. The results remain self-contained against the stated assumptions and standard OPE techniques.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward-dependent propensity parameters
axioms (2)
- domain assumption Future states act as valid shadow variables that identify the MNAR mechanism
- domain assumption A bridge function exists that recovers the conditional mean reward
invented entities (1)
-
bridge function
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Biometrika , volume=
On varieties of doubly robust estimators under missingness not at random with a shadow variable , author=. Biometrika , volume=. 2016 , publisher=
2016
-
[2]
Statistica Sinica , volume=
Identification and inference with nonignorable missing covariate data , author=. Statistica Sinica , volume=
-
[3]
Advances in Neural Information Processing Systems , volume=
Off-policy evaluation for episodic partially observable markov decision processes under non-parametric models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[5]
Proceedings of the twelfth international conference on machine learning , pages=
Residual algorithms: Reinforcement learning with function approximation , author=. Proceedings of the twelfth international conference on machine learning , pages=
-
[6]
Advances in Neural Information Processing Systems , volume=
Minimax estimation of conditional moment models , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
2019 , publisher=
High-dimensional statistics: A non-asymptotic viewpoint , author=. 2019 , publisher=
2019
-
[8]
1989 , publisher=
Linear integral equations , author=. 1989 , publisher=
1989
-
[9]
Advances in neural information processing systems , volume=
Kernel choice and classifiability for RKHS embeddings of probability distributions , author=. Advances in neural information processing systems , volume=
-
[10]
The Annals of Statistics , volume=
Orthogonal statistical learning , author=. The Annals of Statistics , volume=. 2023 , publisher=
2023
-
[11]
Local rademacher complexities , author=
-
[12]
Proceedings of the Twentieth International Conference on International Conference on Machine Learning , pages=
Error bounds for approximate policy iteration , author=. Proceedings of the Twentieth International Conference on International Conference on Machine Learning , pages=
-
[13]
SIAM journal on control and optimization , volume=
Performance bounds in l\_p-norm for approximate value iteration , author=. SIAM journal on control and optimization , volume=. 2007 , publisher=
2007
-
[14]
International conference on machine learning , pages=
Information-theoretic considerations in batch reinforcement learning , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[15]
International Conference on Machine Learning , pages=
Risk bounds and rademacher complexity in batch reinforcement learning , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[16]
Journal of Complexity , volume=
Tensor power sequences and the approximation of tensor product operators , author=. Journal of Complexity , volume=. 2018 , publisher=
2018
-
[17]
arXiv preprint arXiv:2305.17083 , year=
A policy gradient method for confounded pomdps , author=. arXiv preprint arXiv:2305.17083 , year=
-
[18]
Journal of the American Statistical Association , number=
Reinforcement Learning with Continuous Actions Under Unmeasured Confounding , author=. Journal of the American Statistical Association , number=. 2025 , publisher=
2025
-
[19]
Journal of the American Statistical Association , volume=
Semiparametric proximal causal inference , author=. Journal of the American Statistical Association , volume=. 2024 , publisher=
2024
-
[20]
Journal of Machine Learning Research , volume=
Sobolev norm learning rates for regularized least-squares algorithms , author=. Journal of Machine Learning Research , volume=
-
[21]
Econometric Theory , volume=
On rate optimality for ill-posed inverse problems in econometrics , author=. Econometric Theory , volume=. 2011 , publisher=
2011
-
[22]
Econometrica , volume=
Estimation of nonparametric conditional moment models with possibly nonsmooth generalized residuals , author=. Econometrica , volume=. 2012 , publisher=
2012
-
[23]
Advances in neural information processing systems , volume=
Future-dependent value-based off-policy evaluation in pomdps , author=. Advances in neural information processing systems , volume=
-
[24]
Advances in neural information processing systems , volume=
Predictive representations of state , author=. Advances in neural information processing systems , volume=
-
[25]
Proceedings of the 20th International Conference on Machine Learning (ICML-03) , pages=
Learning predictive state representations , author=. Proceedings of the 20th International Conference on Machine Learning (ICML-03) , pages=
-
[26]
International Conference on Machine Learning , pages=
An instrumental variable approach to confounded off-policy evaluation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[27]
2015 , publisher=
Identification and doubly robust estimation of data missing not at random with an ancillary variable , author=. 2015 , publisher=
2015
-
[28]
arXiv preprint arXiv:2406.10438 , year=
A fine-grained analysis of fitted Q-evaluation: beyond parametric models , author=. arXiv preprint arXiv:2406.10438 , year=
-
[29]
Offline Reinforcement Learning Workshop at Neural Information Processing Systems (NeurIPS) , pages=
Shaping control variates for off-policy evaluation , author=. Offline Reinforcement Learning Workshop at Neural Information Processing Systems (NeurIPS) , pages=
-
[30]
Scientific data , volume=
MIMIC-III, a freely accessible critical care database , author=. Scientific data , volume=. 2016 , publisher=
2016
-
[31]
arXiv preprint arXiv:1711.09602 , year=
Deep reinforcement learning for sepsis treatment , author=. arXiv preprint arXiv:1711.09602 , year=
-
[32]
International Conference on Machine Learning , pages=
Multiply robust off-policy evaluation and learning under truncation by death , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[33]
arXiv preprint arXiv:2510.07501 , year=
Evaluating and Learning Optimal Dynamic Treatment Regimes under Truncation by Death , author=. arXiv preprint arXiv:2510.07501 , year=
-
[34]
arXiv preprint arXiv:2507.06961 , year=
Off-Policy Evaluation Under Nonignorable Missing Data , author=. arXiv preprint arXiv:2507.06961 , year=
-
[35]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[37]
arXiv preprint arXiv:2303.08774 , year=
GPT-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[38]
2019 , publisher=
Dynamic Treatment Regimes: Statistical Methods for Precision Medicine , author=. 2019 , publisher=
2019
-
[39]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
Optimal dynamic treatment regimes , author=. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=. 2003 , publisher=
2003
-
[40]
Proceedings of AAMAS , year=
Offline policy evaluation across representations with applications to educational games , author=. Proceedings of AAMAS , year=
-
[41]
arXiv preprint arXiv:2005.01643 , year=
Offline reinforcement learning: Tutorial, review, and perspectives on open problems , author=. arXiv preprint arXiv:2005.01643 , year=
Pith/arXiv arXiv 2005
-
[42]
arXiv preprint arXiv:2212.06355 , year=
A Review of Off-Policy Evaluation in Reinforcement Learning , author=. arXiv preprint arXiv:2212.06355 , year=
-
[43]
arXiv preprint arXiv:1911.06854 , year=
Empirical study of off-policy policy evaluation for reinforcement learning , author=. arXiv preprint arXiv:1911.06854 , year=
arXiv 1911
-
[44]
John Wiley & Sons , edition=
Statistical Analysis with Missing Data , author=. John Wiley & Sons , edition=
-
[45]
Advances in Neural Information Processing Systems , volume=
Confounding-robust policy evaluation in infinite-horizon reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
Artificial Intelligence , volume=
Planning and acting in partially observable stochastic domains , author=. Artificial Intelligence , volume=. 1998 , publisher=
1998
-
[47]
Advances in Neural Information Processing Systems , pages=
Reinforcement learning algorithm for partially observable Markov decision problems , author=. Advances in Neural Information Processing Systems , pages=
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Off-Policy Evaluation in Partially Observable Environments , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[49]
International Conference on Artificial Intelligence and Statistics , pages=
Off-policy evaluation in infinite-horizon reinforcement learning with latent confounders , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
2021
-
[50]
International Conference on Machine Learning , pages=
A minimax learning approach to off-policy evaluation in confounded partially observable markov decision processes , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[51]
International Conference on Machine Learning , pages=
Policy invariance under reward transformations: Theory and application to reward shaping , author=. International Conference on Machine Learning , pages=
-
[52]
Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems , pages=
Dynamic potential-based reward shaping , author=. Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems , pages=
-
[53]
arXiv preprint arXiv:1502.03248 , year=
Off-policy reward shaping with ensembles , author=. arXiv preprint arXiv:1502.03248 , year=
-
[54]
Conference on Learning Theory , pages=
Offline reinforcement learning with realizability and single-policy concentrability , author=. Conference on Learning Theory , pages=. 2022 , organization=
2022
-
[55]
Advances in Neural Information Processing Systems , volume=
Bridging offline reinforcement learning and imitation learning: A tale of pessimism , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
Advances in Neural Information Processing Systems , volume=
Bellman-consistent pessimism for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
International Conference on Machine Learning , pages=
Pessimistic Q-learning for offline reinforcement learning: Towards optimal sample complexity , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[58]
International Conference on Machine Learning , pages=
Batch policy learning under constraints , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[59]
Advances in Neural Information Processing Systems , volume=
Breaking the curse of horizon: Infinite-horizon off-policy estimation , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
International Conference on Machine Learning , pages=
Double reinforcement learning for efficient off-policy evaluation in Markov decision processes , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[61]
Biometrika , volume=
Identifying causal effects with proxy variables of an unmeasured confounder , author=. Biometrika , volume=. 2018 , publisher=
2018
-
[62]
arXiv preprint arXiv:2009.10982 , year=
An introduction to proximal causal learning , author=. arXiv preprint arXiv:2009.10982 , year=
arXiv 2009
-
[63]
arXiv preprint arXiv:2110.15332 , year=
Proximal reinforcement learning: Efficient off-policy evaluation in partially observed markov decision processes , author=. arXiv preprint arXiv:2110.15332 , year=
-
[64]
Journal of the American Statistical Association , volume=
Graphical models for processing missing data , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
2021
-
[65]
Statistica Sinica , volume=
Semiparametric estimation with data missing not at random using an instrumental variable , author=. Statistica Sinica , volume=. 2018 , publisher=
2018
-
[66]
Biometrika , volume=
Semiparametric inverse propensity weighting for nonignorable missing data , author=. Biometrika , volume=. 2016 , publisher=
2016
-
[67]
International Conference on Machine Learning , pages =
Minimax-Optimal Off-Policy Evaluation with Linear Function Approximation , author =. International Conference on Machine Learning , pages =. 2020 , organization =
2020
-
[68]
International Conference on Machine Learning , pages=
Off-policy fitted q-evaluation with differentiable function approximators: Z-estimation and inference theory , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[69]
International Conference on Artificial Intelligence and Statistics , pages =
Asymptotically Efficient Off-Policy Evaluation for Tabular Reinforcement Learning , author =. International Conference on Artificial Intelligence and Statistics , pages =. 2020 , volume =
2020
-
[70]
The annals of statistics , pages =
Optimal global rates of convergence for nonparametric regression , author =. The annals of statistics , pages =. 1982 , publisher =
1982
-
[71]
Proceedings of the 12th ACM conference on recommender systems , pages=
Unbiased offline recommender evaluation for missing-not-at-random implicit feedback , author=. Proceedings of the 12th ACM conference on recommender systems , pages=
-
[72]
2022 , publisher=
Applied missing data analysis , author=. 2022 , publisher=
2022
-
[73]
Advances in Neural Information Processing Systems , volume=
On the curses of future and history in future-dependent value functions for off-policy evaluation , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
arXiv preprint arXiv:2503.01134 , year=
Statistical tractability of off-policy evaluation of history-dependent policies in pomdps , author=. arXiv preprint arXiv:2503.01134 , year=
-
[75]
Reinforcement Learning Conference , year=
Concept-Based Off-Policy Evaluation , author=. Reinforcement Learning Conference , year=
-
[76]
Advances in Neural Information Processing Systems , volume=
Breaking the Order Barrier: Off-Policy Evaluation for Confounded POMDPs , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
arXiv preprint arXiv:1612.00429 , year=
Generalizing skills with semi-supervised reinforcement learning , author=. arXiv preprint arXiv:1612.00429 , year=
-
[78]
International Conference on Machine Learning , pages=
Mahalo: Unifying offline reinforcement learning and imitation learning from observations , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[79]
International conference on machine learning , pages=
Semi-supervised offline reinforcement learning with action-free trajectories , author=. International conference on machine learning , pages=. 2023 , organization=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.