Audio Editing in the Era of Foundation Models: A Survey
Pith reviewed 2026-06-26 07:08 UTC · model grok-4.3
The pith
Audio editing tasks can be organized into a unified taxonomy supported by foundation models in both training-based and training-free ways.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a comprehensive review of audio editing in the foundation model era can be achieved by first defining a unified taxonomy of editing tasks and then summarizing representative foundation-model approaches from training-based and training-free perspectives, while also addressing resources and open challenges.
What carries the argument
The unified taxonomy of audio editing tasks, which groups methods by how they modify audio using foundation models, along with the split into training-based and training-free paradigms for implementing those edits.
If this is right
- Methods in the field can now be systematically compared using the taxonomy.
- Datasets and evaluation protocols are collected in one place for easier access.
- Identified challenges suggest specific areas for new research efforts.
- Both training and training-free approaches are shown to support different editing needs.
Where Pith is reading between the lines
- Future work might extend the taxonomy to include emerging tasks not yet common.
- Training-free methods could allow faster experimentation without large compute resources.
- The survey's structure might serve as a template for similar reviews in other generative media fields like image or video editing.
Load-bearing premise
The papers and approaches selected for the review represent the field without significant omissions or biases in coverage.
What would settle it
Identification of a widely used audio editing technique based on foundation models that cannot be placed into any category of the proposed taxonomy.
Figures

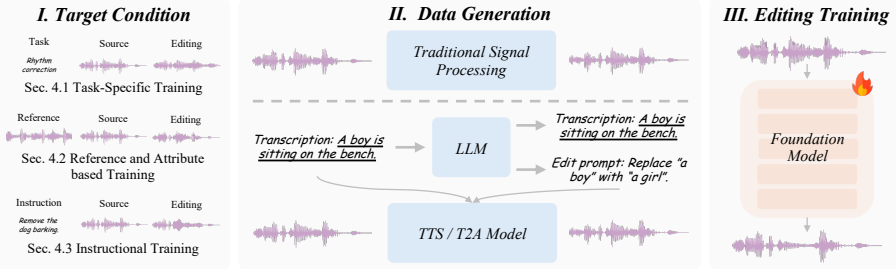
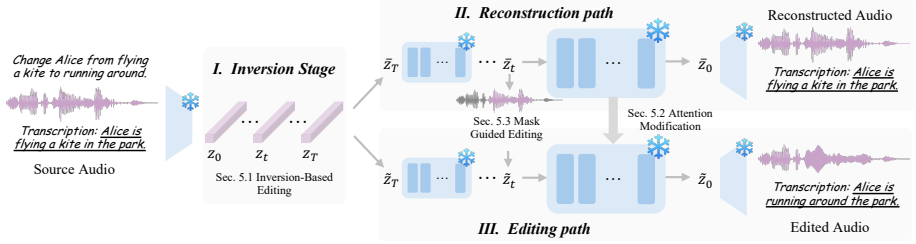
read the original abstract
Audio editing aims to modify a given synthetic or real-world audio signal to satisfy specific user needs. As a promising yet challenging direction in AIGC, it has attracted increasing attention. Recent advances in audio generation have made powerful generative models central to modern audio editing systems. This rapid progress has created a growing need to organize emerging tasks, methods, and resources into a coherent view. In this survey, we provide a comprehensive review of audio editing in the era of foundation models. We first present a unified taxonomy of existing editing tasks and then summarize the major foundation-model paradigms that support modern audio editing, covering representative approaches from both training-based and training-free perspectives. We further discuss related resources, including datasets, evaluation protocols, and data construction tools. Finally, we identify open challenges in this field and outline promising directions for future research. The project page is released at https://github.com/DaViD-Pigeon/AudioEditSurvey.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey on audio editing using foundation models. It claims to deliver a unified taxonomy of audio editing tasks, summarize representative foundation-model approaches from both training-based and training-free perspectives, review associated resources (datasets, evaluation protocols, data construction tools), and outline open challenges and future directions.
Significance. If the taxonomy accurately organizes the cited literature without major omissions and the paradigm summaries are faithful, the work provides a useful organizing framework for a rapidly developing subfield at the intersection of audio signal processing and generative AI. The explicit discussion of resources and challenges adds practical value for researchers entering the area.
minor comments (3)
- [§2] §2 (Taxonomy): The distinction between training-based and training-free paradigms is introduced early but would benefit from an explicit decision tree or decision criteria table showing how a given method is assigned to one category versus the other, to reduce potential reader ambiguity when new papers appear.
- [§4] §4 (Resources): The datasets subsection lists several corpora but does not indicate which editing tasks each corpus primarily supports; adding a task-coverage matrix would strengthen the utility of this section.
- Throughout: A small number of citations appear only in the text and not in the reference list (e.g., the first mention of a diffusion-based editing method in §3.2); ensure all in-text citations are present in the bibliography.
Simulated Author's Rebuttal
We thank the referee for their review and positive assessment of our survey. The recommendation for minor revision is noted. No specific major comments were provided in the report, so we have no individual points to address. We will prepare a revised manuscript incorporating any minor editorial improvements as needed.
Circularity Check
No significant circularity; survey of external literature
full rationale
The paper is a literature survey whose central claim is a unified taxonomy and summary of paradigms drawn from reviewed external works. No equations, fitted parameters, derivations, or self-referential steps exist that could reduce to the paper's own inputs. Self-citations, if present, are not load-bearing for any technical result since the work contains no technical derivations. The completeness assumption is inherent to surveys and does not create circularity in the argument structure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Paul Boersma and David Weenink
Beyond voice identity conversion: manipulat- ing voice attributes by adversarial learning of struc- tured disentangled representations.arXiv preprint arXiv:2107.12346. Paul Boersma and David Weenink. 2021. Praat: Doing phonetics by computer (6.1. 16)[computer software]. Dmitry Bogdanov, Minz Won, Philip Tovstogan, Alas- tair Porter, and Xavier Serra. 2019...
arXiv 2021
-
[2]
A comparative analysis of automatic speech recognition errors in small group classroom discourse. InProceedings of the 31st ACM conference on user modeling, adaptation and personalization, pages 250– 262. Edresson Casanova, Julian Weber, Christopher D Shulby, Arnaldo Candido Junior, Eren Gölge, and Moacir A Ponti. 2022. Yourtts: Towards zero-shot multi-sp...
arXiv 2022
-
[3]
Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261. Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. 2023. Simple and controllable music gen- eration.Advances in neural information pro...
Pith/arXiv arXiv 2023
-
[4]
InForty-first interna- tional conference on machine learning
Scaling rectified flow transformers for high- resolution image synthesis. InForty-first interna- tional conference on machine learning. Zach Evans, CJ Carr, Josiah Taylor, Scott H Hawley, and Jordi Pons. 2024. Fast timing-conditioned latent audio diffusion. InForty-first International Confer- ence on Machine Learning. Eduardo Fonseca, Xavier Favory, Jordi...
2024
-
[5]
Metricgan+: An improved version of met- ricgan for speech enhancement.arXiv preprint arXiv:2104.03538. Youquan Fu, Ruiyang Si, Hongfa Wang, Dongzhan Zhou, Jiacheng Sun, Ping Luo, Di Hu, Hongyuan Zhang, and Xuelong Li. 2025. Object-avedit: An object-level audio-visual editing model.arXiv preprint arXiv:2510.00050. Liting Gao, Yi Yuan, Yaru Chen, Yuelan Che...
arXiv 2025
-
[6]
Rfm-editing: Rectified flow matching for text- guided audio editing. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 15467–15471. IEEE. Zhifu Gao, Zerui Li, Jiaming Wang, Haoneng Luo, Xian Shi, Mengzhe Chen, Yabin Li, Lingyun Zuo, Zhihao Du, Zhangyu Xiao, et al. 2023. Funasr: A funda- mental end-...
arXiv 2026
-
[7]
V oicenong: Robust high-quality speech editing model without hallucinations. InProc. Interspeech 2025, pages 3469–3473. Yannick Jadoul, Bill Thompson, and Bart De Boer. 2018. Introducing parselmouth: A python interface to praat. Journal of Phonetics, 71:1–15. Shengpeng Ji, Yifu Chen, Minghui Fang, Jialong Zuo, Jingyu Lu, Hanting Wang, Ziyue Jiang, Long Zh...
arXiv 2025
-
[8]
Keon Lee, Kyumin Park, and Daeyoung Kim
Dgmo: Training-free audio source separation through diffusion-guided mask optimization.arXiv preprint arXiv:2506.02858. Keon Lee, Kyumin Park, and Daeyoung Kim. 2023. Dailytalk: Spoken dialogue dataset for conversational text-to-speech. InICASSP 2023-2023 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE....
arXiv 2023
-
[9]
Styletts: A style-based generative model for natural and diverse text-to-speech synthesis.IEEE Journal of Selected Topics in Signal Processing, 19(1):283–296. Jinhua Liang, Yuanzhe Chen, Yi Yuan, Dongya Jia, Xiaobin Zhuang, Zhuo Chen, Yuping Wang, and Yux- uan Wang. 2025. Audiomorphix: Training-free audio editing with diffusion probabilistic models.arXiv ...
arXiv 2025
-
[10]
Chen-Chou Lo, Szu-Wei Fu, Wen-Chin Huang, Xin Wang, Junichi Yamagishi, Yu Tsao, and Hsin-Min Wang
Stylestream: Real-time zero-shot voice style conversion.arXiv preprint arXiv:2602.20113. Chen-Chou Lo, Szu-Wei Fu, Wen-Chin Huang, Xin Wang, Junichi Yamagishi, Yu Tsao, and Hsin-Min Wang. 2019. Mosnet: Deep learning based objec- tive assessment for voice conversion.arXiv preprint arXiv:1904.08352. Sihan Lv, Yechen Jin, Zhen Li, Jintao Chen, Jinshan Zhang,...
arXiv 2019
-
[11]
arXiv preprint arXiv:2310.12858
Audio editing with non-rigid text prompts. arXiv preprint arXiv:2310.12858. William Peebles and Saining Xie. 2023. Scalable diffu- sion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205. Puyuan Peng, Po-Yao Huang, Shang-Wen Li, Abdelrah- man Mohamed, and David Harwath. 2024. V oice- craft:...
arXiv 2023
-
[12]
Alessandro Ragano, Jan Skoglund, and Andrew Hines
The musdb18 corpus for music separation. Alessandro Ragano, Jan Skoglund, and Andrew Hines
-
[13]
InICASSP 2024-2024 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 1011–1015
Nomad: Unsupervised learning of per- ceptual embeddings for speech enhancement and non-matching reference audio quality assessment. InICASSP 2024-2024 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 1011–1015. IEEE. ITUT Rec. 2006. P. 800.1, mean opinion score (mos) ter- minology.International Telecommunication U...
2024
-
[14]
Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. InICASSP 2021-2021 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 6493–6497. IEEE. Antony W Rix, John G Beerends, Michael P Hollier, and Andries P Hekstra. 2001. Perceptual evaluation of speech quality (pesq)-a new ...
Pith/arXiv arXiv 2021
-
[15]
Jaesung Tae, Hyeongju Kim, and Taesu Kim
IEEE. Jaesung Tae, Hyeongju Kim, and Taesu Kim. 2021. Editts: Score-based editing for controllable text-to- speech.arXiv preprint arXiv:2110.02584. Daxin Tan, Liqun Deng, Yu Ting Yeung, Xin Jiang, Xiao Chen, and Tan Lee. 2021. Editspeech: A text based speech editing system using partial inference and bidirectional fusion. In2021 IEEE Automatic Speech Reco...
arXiv 2021
-
[16]
IEEE/ACM transactions on audio, speech, and lan- guage processing, 28:1778–1787
Complex spectral mapping for single-and multi-channel speech enhancement and robust asr. IEEE/ACM transactions on audio, speech, and lan- guage processing, 28:1778–1787. Haojie Wei, Xueke Cao, Tangpeng Dan, and Yueguo Chen. 2023. Rmvpe: A robust model for vocal pitch estimation in polyphonic music.arXiv preprint arXiv:2306.15412. 16 Gordon Wichern, Joe An...
arXiv 2023
-
[17]
Shih-Lun Wu, Chris Donahue, Shinji Watanabe, and Nicholas J Bryan
Analysis of forced aligner performance on l2 english speech.Speech Communication, 158:103042. Shih-Lun Wu, Chris Donahue, Shinji Watanabe, and Nicholas J Bryan. 2024. Music controlnet: Mul- tiple time-varying controls for music generation. IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, 32:2692–2703. Tianxin Xie, Yan Rong, Pengfei Zhang...
Pith/arXiv arXiv 2024
-
[18]
remove the background crowd noise from the speech
Editsinger: Zero-shot text-based singing voice editing system with diverse prosody modeling. In IJCAI, pages 4503–4509. Yixiao Zhang, Yukara Ikemiya, Woosung Choi, Naoki Murata, Marco A Martínez-Ramírez, Liwei Lin, Gus Xia, Wei-Hsiang Liao, Yuki Mitsufuji, and Simon Dixon. 2024a. Instruct-musicgen: Unlocking text-to- music editing for music language model...
arXiv 2023
-
[19]
When the editable unit is defined by speaker activity rather than text, pyannote (Bredin,
generates word-level timestamps for long- form speech. When the editable unit is defined by speaker activity rather than text, pyannote (Bredin,
-
[20]
For general au- dio, sound event detection models (Kong et al., 2020; Li et al., 2023) produce event-level activity boundaries
and V AD tools (Karan et al., 2024) can provide speaker-active segments. For general au- dio, sound event detection models (Kong et al., 2020; Li et al., 2023) produce event-level activity boundaries. In music editing, temporal localization often relies on pitch or note-level cues: Parsel- mouth (Jadoul et al., 2018), RMVPE (Wei et al., 2023), and CREPE (...
2024
-
[21]
How- ever, their effectiveness depends heavily on stable text-acoustic alignment and high-quality tokeniza- tion
and SpeechX (Wang et al., 2024b). How- ever, their effectiveness depends heavily on stable text-acoustic alignment and high-quality tokeniza- tion. When applied to music or general audio, weak semantic boundaries, dense source mixtures, and long-term structural constraints may lead to token- level errors, context drift, and fidelity degradation. Diffusion...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.