Dynamic Query Modification for Binary Locality Sensitive Hashing
Pith reviewed 2026-05-25 02:07 UTC · model grok-4.3
The pith
Changing the query point at search time raises the probability that binary LSH collides with its near neighbors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
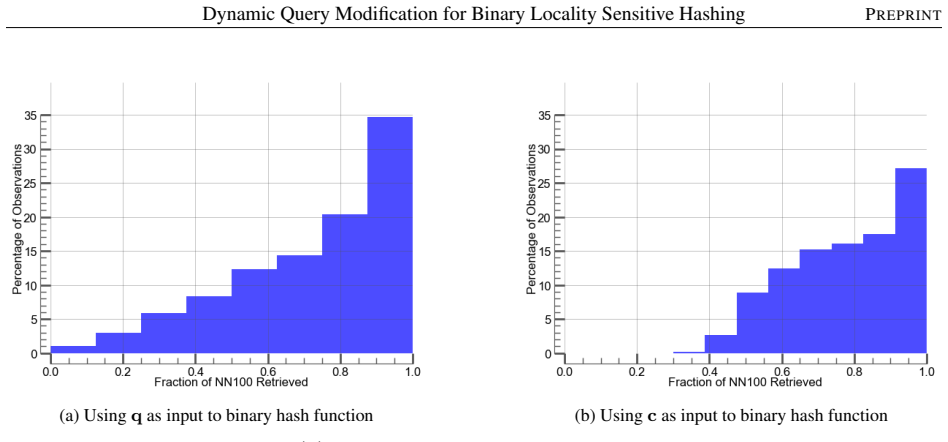
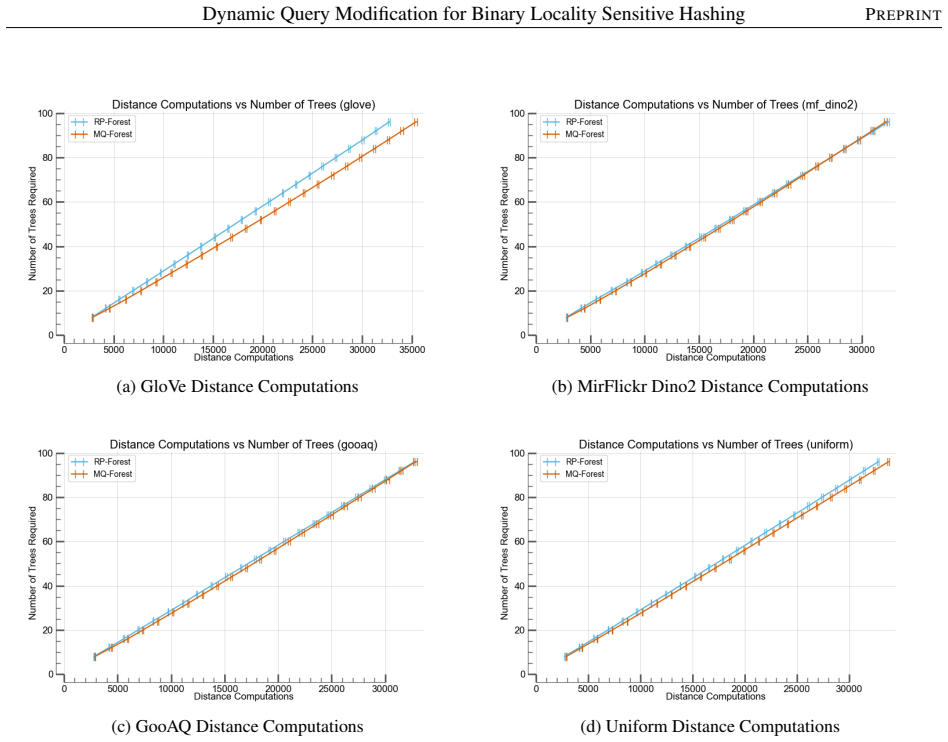
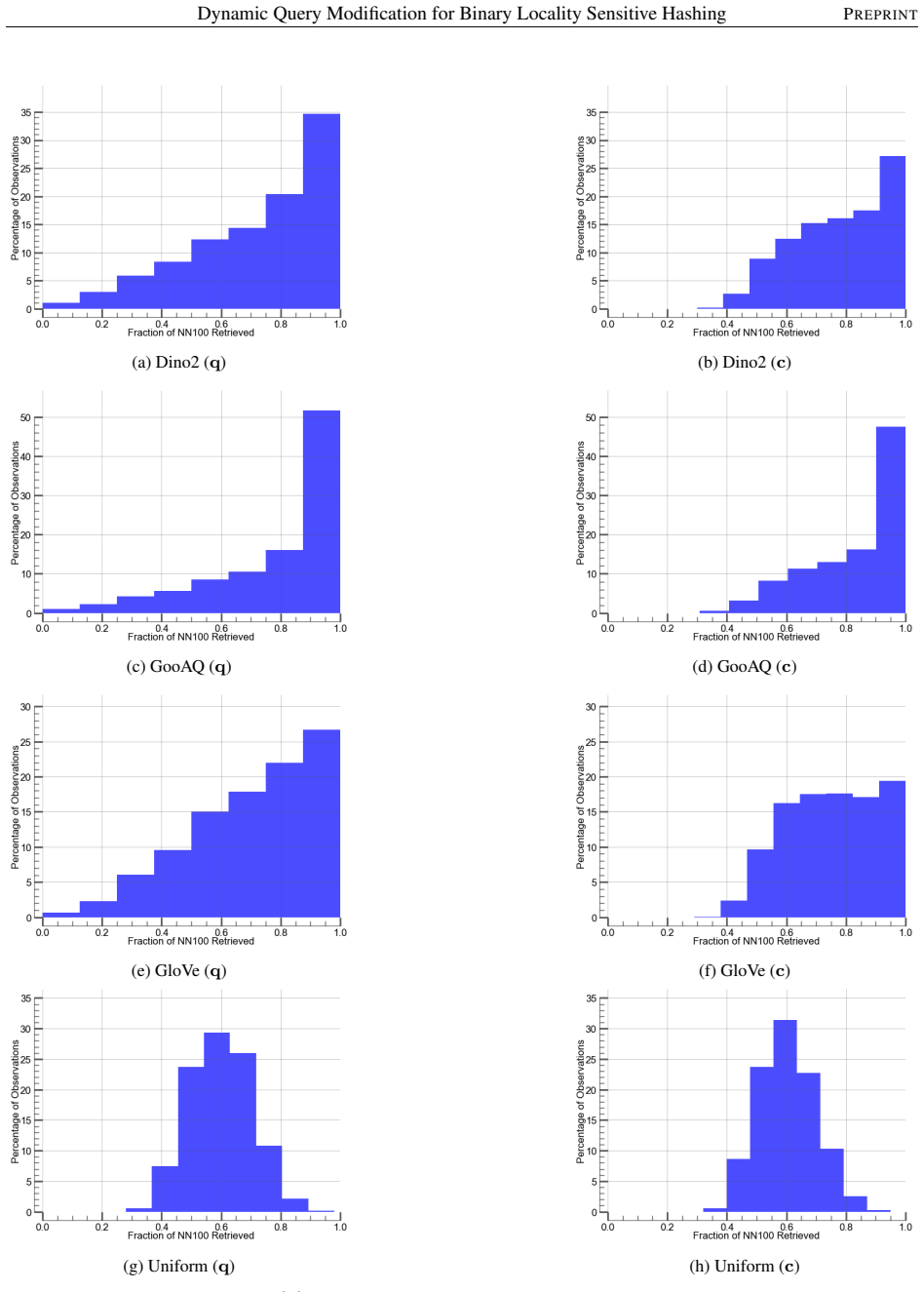
Dynamic query modification changes the query point q to a new value c at query time. The hash output of c collides with near neighbors with greater probability than the output of q, and there is little chance of c failing to collide with any near neighbors, a property not shared by q. The approach is implemented by dynamically estimating c inside MQ-Forest, a modified RP-Forest structure, which reduces build and query times by up to 40 percent on several large high-dimensional benchmark datasets.
What carries the argument
Dynamic query modification, which estimates a new point c from the original query q during the query process to raise collision rates inside binary LSH families.
If this is right
- The hash output of c collides with near neighbors at higher probability than the hash output of q.
- There is little chance that c fails to collide with any near neighbors.
- MQ-Forest reduces both build time and query time by up to 40 percent relative to RP-Forest on large high-dimensional data.
- The same collision improvement holds across multiple binary LSH-based ANN structures.
Where Pith is reading between the lines
- If c estimation stays cheap, the technique could be layered on top of other query-time optimizations in existing ANN indexes.
- Similar point-adjustment ideas might apply to non-binary LSH families once an analogous modification rule is defined.
- Higher collision reliability could allow practitioners to use fewer hash functions or smaller tables while keeping the same recall.
Load-bearing premise
A suitable value for c can be estimated dynamically at query time without adding substantial computational cost or new errors that offset the collision gains.
What would settle it
An experiment that measures collision rates of the estimated c versus the original q and finds no increase in near-neighbor hits or an increase in missed neighbors.
Figures









read the original abstract
Our context of interest is how binary locality sensitive hash (LSH) functions can be used to solve the approximate near neighbour (ANN) problem, which seeks to find the k closest elements of some dataset X to some further point q presented as a query. Binary locality sensitive function families H are sets of functions each which accept a point and return a binary value. A function is locality sensitive if and only if the output of the function is more likely to be equal (a 'hash collision') if two close vectors are used as input than if two far vectors are used. A data structure can be built by generating binary hash codes for each member of X, which are generated by drawing and applying one or more functions from H. When q is presented as a query, the same set of functions is applied to it and those elements of X with equal binary hash codes are retrieved. In this paper we introduce dynamic query modification. This process changes q at query time to form a new value c, which by theoretical and experimental analysis we prove has two significant advantages. Firstly, the hash output of c collides with near neighbours with a greater probability than q. Secondly, we show there is little chance of c failing to collide with any near neighbours; a property which we demonstrate is not true for q. To demonstrate the efficacy of the technique, we define a novel structure MQ-Forest, a modified version of RP-Forest. Both are binary LSH-based ANN mechanisms, but MQ-Forest dynamically estimates a value for c during the query process. We show that MQ-Forest reduces both build and query times by up to 40% when measured over several large, high-dimensional benchmark datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces dynamic query modification for binary locality sensitive hashing (LSH) to solve the approximate nearest neighbor (ANN) problem. It claims that at query time, the query point q is modified to a new value c, which has a higher probability of hash collision with near neighbors and a lower probability of missing all near neighbors. This is implemented in the MQ-Forest structure, a modification of RP-Forest, and the authors report reductions of up to 40% in both build and query times on several large, high-dimensional benchmark datasets.
Significance. If the theoretical analysis and experimental results are substantiated with explicit derivations, this approach could provide a practical enhancement to binary LSH methods for ANN by improving collision properties through query modification without altering the hash family. The claimed advantages would be significant for efficiency in high-dimensional search if the dynamic estimation of c incurs negligible overhead and preserves LSH guarantees.
major comments (2)
- [Abstract] Abstract: The abstract asserts that 'theoretical and experimental analysis we prove' two advantages for c (higher collision probability with near neighbors than q, and little chance of failing to collide with any near neighbors), but provides no equations, derivation steps, or definition of the mapping from q to c. This is load-bearing for the central claim, as the advantages cannot be verified without the explicit probabilistic analysis.
- [MQ-Forest description] MQ-Forest description (as referenced in abstract): No concrete mechanism is specified for dynamically estimating c 'during the query process' (e.g., via additional projections, reuse of existing hashes, or local averaging). This is load-bearing because the skeptic concern is realized here—the estimation overhead and any introduced bias must be shown not to offset the claimed 40% build/query savings or violate the LSH collision probabilities used in the theoretical analysis.
minor comments (1)
- [Abstract] Abstract: The claim of 'up to 40%' reductions references 'several large, high-dimensional benchmark datasets' but gives no dataset names, dimensions, sizes, baselines compared, or error bars/analysis.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments below, indicating the revisions we will make to strengthen the presentation of the theoretical analysis and the MQ-Forest mechanism.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that 'theoretical and experimental analysis we prove' two advantages for c (higher collision probability with near neighbors than q, and little chance of failing to collide with any near neighbors), but provides no equations, derivation steps, or definition of the mapping from q to c. This is load-bearing for the central claim, as the advantages cannot be verified without the explicit probabilistic analysis.
Authors: The referee correctly identifies that the abstract does not contain the explicit equations or derivation steps. While the full manuscript provides the theoretical analysis in dedicated sections, we agree that the abstract should better support the central claim. We will revise the abstract to include a concise definition of the mapping from q to c and the key probabilistic expressions demonstrating the higher collision probability and reduced miss rate. This revision will be made. revision: yes
-
Referee: [MQ-Forest description] MQ-Forest description (as referenced in abstract): No concrete mechanism is specified for dynamically estimating c 'during the query process' (e.g., via additional projections, reuse of existing hashes, or local averaging). This is load-bearing because the skeptic concern is realized here—the estimation overhead and any introduced bias must be shown not to offset the claimed 40% build/query savings or violate the LSH collision probabilities used in the theoretical analysis.
Authors: We agree that the abstract does not specify the concrete mechanism for estimating c. The full paper describes MQ-Forest in detail, including how c is estimated by reusing the existing hash projections from the RP-Forest structure to avoid additional overhead. However, to fully address concerns about overhead, bias, and preservation of LSH guarantees, we will expand the description in the methods section to explicitly detail the estimation process (local averaging of nearby points' hashes or similar), provide bounds on the overhead showing it is negligible relative to the reported savings, and include a proof that the estimation does not violate the collision probabilities. This will be incorporated in the revised manuscript. revision: yes
Circularity Check
No significant circularity; no equations or self-referential reductions present
full rationale
The provided abstract and text introduce dynamic query modification and MQ-Forest with claims of theoretical advantages for collision probabilities, but contain no equations, fitted parameters, derivations, or self-citations. No load-bearing step reduces by construction to its inputs (e.g., no self-definitional c estimation or prediction from fitted values). The estimation procedure for c is mentioned but not formalized, precluding any exhibited circular reduction. This is the normal case of a self-contained descriptive claim without detectable circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Practical and Optimal LSH for Angular Distance
Alexandr Andoni, Piotr Indyk, Thijs Laarhoven, Ilya Razenshteyn, and Ludwig Schmidt. Practical and optimal lsh for angular distance. (arXiv:1509.02897), 2015. arXiv:1509.02897 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[2]
Sums of squares of distances in m-space
Tom M Apostol and Mamikon A Mnatsakanian. Sums of squares of distances in m-space
- [3]
-
[4]
Learning to find good hash functions for embeddings
Ben Claydon, Richard Connor, and Alan Dearle. Learning to find good hash functions for embeddings. In Similarity Search and Applications, page 345–353, Cham, 2026. Springer Nature Switzerland
work page 2026
-
[5]
Demonstrating the efficacy of polyadic queries
Ben Claydon, Richard Connor, Alan Dearle, and Lucia Vadicamo. Demonstrating the efficacy of polyadic queries. InSimilarity Search and Applications, page 49–56, Cham, 2025. Springer Nature Switzerland
work page 2025
-
[6]
Hui Cui, Fengling Li, Lei Zhu, Jingjing Li, and Zheng Zhang. Online query expansion hashing for efficient image retrieval.IEEE Transactions on Circuits and Systems for Video Technology, 34(3):1941–1953, March 2024
work page 1941
-
[7]
Random projection trees and low dimensional manifolds
Sanjoy Dasgupta and Yoav Freund. Random projection trees and low dimensional manifolds. InProceedings of the fortieth annual ACM symposium on Theory of computing, page 537–546, Victoria British Columbia Canada, May 2008. ACM
work page 2008
-
[8]
Dimension importance estimation for dense information retrieval
Guglielmo Faggioli, Nicola Ferro, Raffaele Perego, and Nicola Tonellotto. Dimension importance estimation for dense information retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’24, page 1318–1328, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[9]
Random forest with random projection to impute missing gene expression data
Lovedeep Gondara. Random forest with random projection to impute missing gene expression data. In2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), page 1251–1256, Decem- ber 2015
work page 2015
-
[10]
Distribution of joint gaussian conditional on their sum
Maxim (https://math.stackexchange.com/users/491644/maxim). Distribution of joint gaussian conditional on their sum. Mathematics Stack Exchange. URL:https://math.stackexchange.com/q/2943590 (version: 2018-10- 05)
-
[11]
Qiang Huang, Jianlin Feng, Yikai Zhang, Qiong Fang, and Wilfred Ng. Query-aware locality-sensitive hashing for approximate nearest neighbor search.Proceedings of the VLDB Endowment, 9(1):1–12, 2015
work page 2015
-
[12]
Mark J. Huiskes and Michael S. Lew. The mir flickr retrieval evaluation. InProceedings of the 1st ACM International Conference on Multimedia Information Retrieval, MIR ’08, page 39–43, New York, NY , USA,
-
[13]
Association for Computing Machinery
-
[14]
Approximate nearest neighbors: towards removing the curse of dimensionality
Piotr Indyk and Rajeev Motwani. Approximate nearest neighbors: towards removing the curse of dimensionality. InProceedings of the thirtieth annual ACM symposium on Theory of computing - STOC ’98, page 604–613. ACM Press, 1998
work page 1998
-
[15]
Gooaq: Open question answering with diverse answer types.arXiv preprint, 2021
Daniel Khashabi, Amos Ng, Tushar Khot, Ashish Sabharwal, Hannaneh Hajishirzi, and Chris Callison-Burch. Gooaq: Open question answering with diverse answer types.arXiv preprint, 2021
work page 2021
-
[16]
Yin-Hsi Kuo, Kuan-Ting Chen, Chien-Hsing Chiang, and Winston H. Hsu. Query expansion for hash-based image object retrieval. InProceedings of the 17th ACM international conference on Multimedia, page 65–74, Beijing China, October 2009. ACM
work page 2009
-
[17]
Query expansion using word embeddings
Saar Kuzi, Anna Shtok, and Oren Kurland. Query expansion using word embeddings. InProceedings of the 25th ACM International on Conference on Information and Knowledge Management, CIKM ’16, page 1929–1932, New York, NY , USA, 2016. Association for Computing Machinery
work page 1929
-
[18]
Fast and accurate head pose estimation via random pro- jection forests
Donghoon Lee, Ming-Hsuan Yang, and Songhwai Oh. Fast and accurate head pose estimation via random pro- jection forests. In2015 IEEE International Conference on Computer Vision (ICCV), page 1958–1966, Santiago, Chile, December 2015. IEEE
work page 1958
-
[19]
Donghoon Lee, Ming-Hsuan Yang, and Songhwai Oh. Head and body orientation estimation using convolutional random projection forests.IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(1):107–120, January 2019
work page 2019
-
[20]
Maximum likelihood estimation of intrinsic dimension
Elizaveta Levina and Peter J Bickel. Maximum likelihood estimation of intrinsic dimension
-
[21]
Multi-probe lsh: Efficient indexing for high-dimensional similarity search
Qin Lv, William Josephson, Zhe Wang, Moses Charikar, and Kai Li. Multi-probe lsh: Efficient indexing for high-dimensional similarity search. 16 Dynamic Query Modification for Binary Locality Sensitive HashingPREPRINT
-
[22]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. (arXiv:1301.3781), 2013. arXiv:1301.3781 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[23]
Muirhead.Aspects of Multivariate Statistical Theory
Robb J. Muirhead.Aspects of Multivariate Statistical Theory. Wiley-Interscience, 2005
work page 2005
-
[24]
Mervin E. Muller. A note on a method for generating points uniformly on n-dimensional spheres.Communica- tions of the ACM, 2(4):19–20, April 1959
work page 1959
-
[25]
Di- nov2: Learning robust visual features without supervision, 2023
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, and et al. Di- nov2: Learning robust visual features without supervision, 2023
work page 2023
-
[26]
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. Glove: Global vectors for word representation. InEmpirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, 2014
work page 2014
-
[27]
Joseph John Rocchio Jr. Relevance feedback in information retrieval.The SMART retrieval system: experiments in automatic document processing, 1971
work page 1971
-
[28]
Sparse random projection isolation forest for outlier detection
Xu Tan, Jiawei Yang, and Susanto Rahardja. Sparse random projection isolation forest for outlier detection. Pattern Recognition Letters, 163:65–73, November 2022
work page 2022
-
[29]
Comparative analysis of relevance feed- back techniques for image retrieval
Lucia Vadicamo, Francesca Scotti, Alan Dearle, and Richard Connor. Comparative analysis of relevance feed- back techniques for image retrieval. In Ichiro Ide, Ioannis Kompatsiaris, Changsheng Xu, Keiji Yanai, Wei-Ta Chu, Naoko Nitta, Michael Riegler, and Toshihiko Yamasaki, editors,MultiMedia Modeling, page 206–219, Singapore, 2025. Springer Nature
work page 2025
-
[30]
Jinxi Xu and W. Bruce Croft. Improving the effectiveness of information retrieval with local context analysis. ACM Trans. Inf. Syst., 18(1):79–112, January 2000
work page 2000
-
[31]
K-nearest neighbor search by random projection forests
Donghui Yan, Yingjie Wang, Jin Wang, Honggang Wang, and Zhenpeng Li. K-nearest neighbor search by random projection forests. In2018 IEEE International Conference on Big Data (Big Data), page 4775–4781, December 2018. arXiv:1812.11689 [cs, stat]
-
[32]
Bailing Zhang. Phenotype recognition for rnai screening by random projection forest.AIP Conference Proceed- ings, 1371(1):55–64, 2011
work page 2011
-
[33]
Xiang Sean Zhou and Thomas S. Huang. Relevance feedback in image retrieval: A comprehensive review. Multimedia Systems, 8(6):536–544, April 2003. 17 Dynamic Query Modification for Binary Locality Sensitive HashingPREPRINT A Description of Datasets We use four high-dimensional vector datasets of different modalities for experimentation:
work page 2003
-
[34]
MirFlickr is a collection of 1 million images submitted by Flickr users [12]. We encode each of these images with the DinoV2S embedder [24], which outputs 384-dimensional embeddings of each image in Euclidean space. The dissimilarity metric for this space is either Euclidean or Cosine distance. Downloadable from https://zenodo.org/records/15373201
-
[35]
These embeddings were gener- ated by analysing word co-occurrences from Twitter posts
Twitter GloVe is a set of approximately 1.1 million word embeddings [25]. These embeddings were gener- ated by analysing word co-occurrences from Twitter posts. The dissimilarity metric for this space is either Euclidean or Cosine distance. Downloadable fromhttps://nlp.stanford.edu/projects/glove/
-
[36]
GOOAQ is a set of 3 million questions submitted to the Google search engine and their answers [14]. They were embedded using a sentence BERT model to produce 384 dimensional feature vectors.Downloadable at https://huggingface.co/datasets/sentence-transformers/gooaq
-
[37]
Generated using the method described by Muller [23]
A uniform spherical dataset of 1 million points in 200 dimensions. Generated using the method described by Muller [23]. B Statistical Model of Hyperplane Hash Function We derive a statistical model which describes the probability that a pointuand a each member of some set of points knn(q)will hash collide under the familyH rp. This class of hash function ...
-
[38]
For a given query, generate1000random hyperplanes such thatu·w<0.005(approximating planes where b= 0). Note that the choice ofb= 0is arbitrary as the value ofbdoes not influence the covariance as per Equation 11, but must be fixed such that the mean value is stable
-
[39]
For each planew, we compute the valuesAw, or the height of each near neighbour abovew. We store these results inD, a1000×100matrix representing the heights of the100nearest neighbours to the query over all 1000hyperplanes
-
[40]
This measures the degree of correlation betweenx i ·wandx j ·wover a large sample of planes
Finally, we measure the covariance between the columns of the matrixD. This measures the degree of correlation betweenx i ·wandx j ·wover a large sample of planes. Recall that these covariances are bounded between±1. Figure 8 shows the distribution of all such covariances aggregated over all200. For all datasets, settingu=⟨c⟩reduces the average covariance...
-
[41]
Sample a subset of 250,000 points from Twitter GloVe as a dataset
-
[42]
Sample a disjoint set of 5000 points to serve as queries
-
[43]
(b) Letknn(µ)be theknearest neighbour set ofµ
For each queryµin the set: (a) Create a shifted datasetXcentred onµby subtractingµfrom all members of the dataset. (b) Letknn(µ)be theknearest neighbour set ofµ. LetYbe the set ofkpoints inXsampled uniformly from the 300 near neighbours ofµ. From these sets, we derivecand⟨ˆ c⟩by computing the centroids of the setsknn(µ)andYrespectively. As the dataset is ...
-
[44]
To demonstrate this fact empirically, we formulate the following experiment; we use the same set of 5000 queries and the same 250,000 points drawn previously:
-
[45]
For each query, we measure the valuer 1 andr 2 by measuring the largest distance fromµin bothknn(µ) andYrespectively
-
[46]
If our assumption is correct, then this distribution will be identical to that of ⟨ˆ c⟩ −µ
We record the vector r2 r1 (c−µ). If our assumption is correct, then this distribution will be identical to that of ⟨ˆ c⟩ −µ. Again, we only consider co-ordinate 0 of each vector as their own distributions. To measure the difference in these distributions, we use a Kolgromov-Smirnov (KS) test, which measures the likeli- hood that co-ordinate0of the distri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.