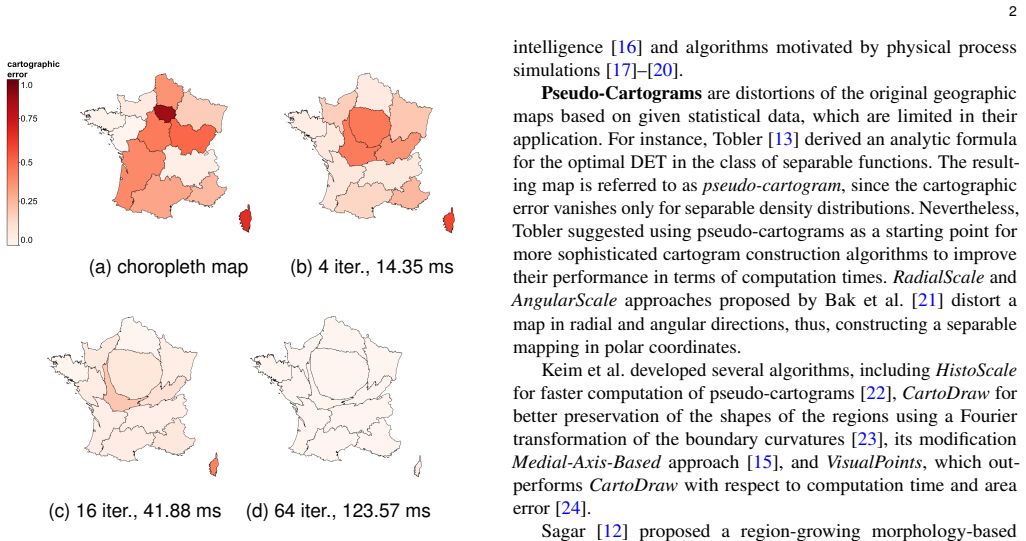
0
Diameter in plane intersection graphs depends on object type and value
Charting the Diameter Computation Landscape on Intersection Graphs in the Plane
Subquadratic for non-degenerate segments and constant-diameter squares; hard to decide diameter 2 for fat triangles.
 full image
full image
abstract click to expand
Computing the diameter of the intersection graphs of objects is a basic problem in computational geometry. Previous works showed that the complexity of computing the diameter mainly depends on the object types: for unit disks and squares in 2D, the problem is solvable in truly subquadratic time, while for other objects, including unit segments and equilateral triangles in 2D or unit balls and axis-parallel unit cubes in 3D, there is no truly subquadratic time algorithm under the Orthogonal Vector (OV) hypothesis. We undertake a comprehensive study of computing the diameter of geometric intersection graphs for various types of objects. We discover many new irregularities, showing that the landscape is extremely nuanced: the source of hardness is a combination of the object type, the true diameter value, and how the objects intersect with each other. Our highlighted results for the 2D case include:
1. The diameter of non-degenerate, axis-aligned line segments can be computed in truly subquadratic time. Previous hardness result for line segments applies only to degenerate instances. On the other hand, for the degenerate case, we show that a truly subquadratic time algorithm exists when the true diameter is constant.
2. An almost-linear-time algorithm for unit-square graphs of constant diameter. Previous algorithms rely on succinct representation assuming bounded VC-dimension; for such a strategy $\Omega(n^{7/4})$ time is an inherent barrier.
3. An $\tilde{O}(n^{4/3})$-time algorithm to decide if the diameter of a unit-disk graph is at most 2. This improves upon the recent algorithm with running time $\tilde{O}(n^{2-1/9})$.
4. Deciding if the diameter of intersection graphs of fat triangles or line segments is at most 2 is truly subquadratic-hard under fine-grained complexity assumptions. Previous lower bounds only hold when deciding if diameter is at most 3.