Benchmarking AI Agents for Addressing Scientific Challenges Across Scales
Pith reviewed 2026-06-27 09:32 UTC · model grok-4.3
The pith
Current AI agents contribute effectively to structured scientific data analysis but struggle to generate novel insights or handle open-ended research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
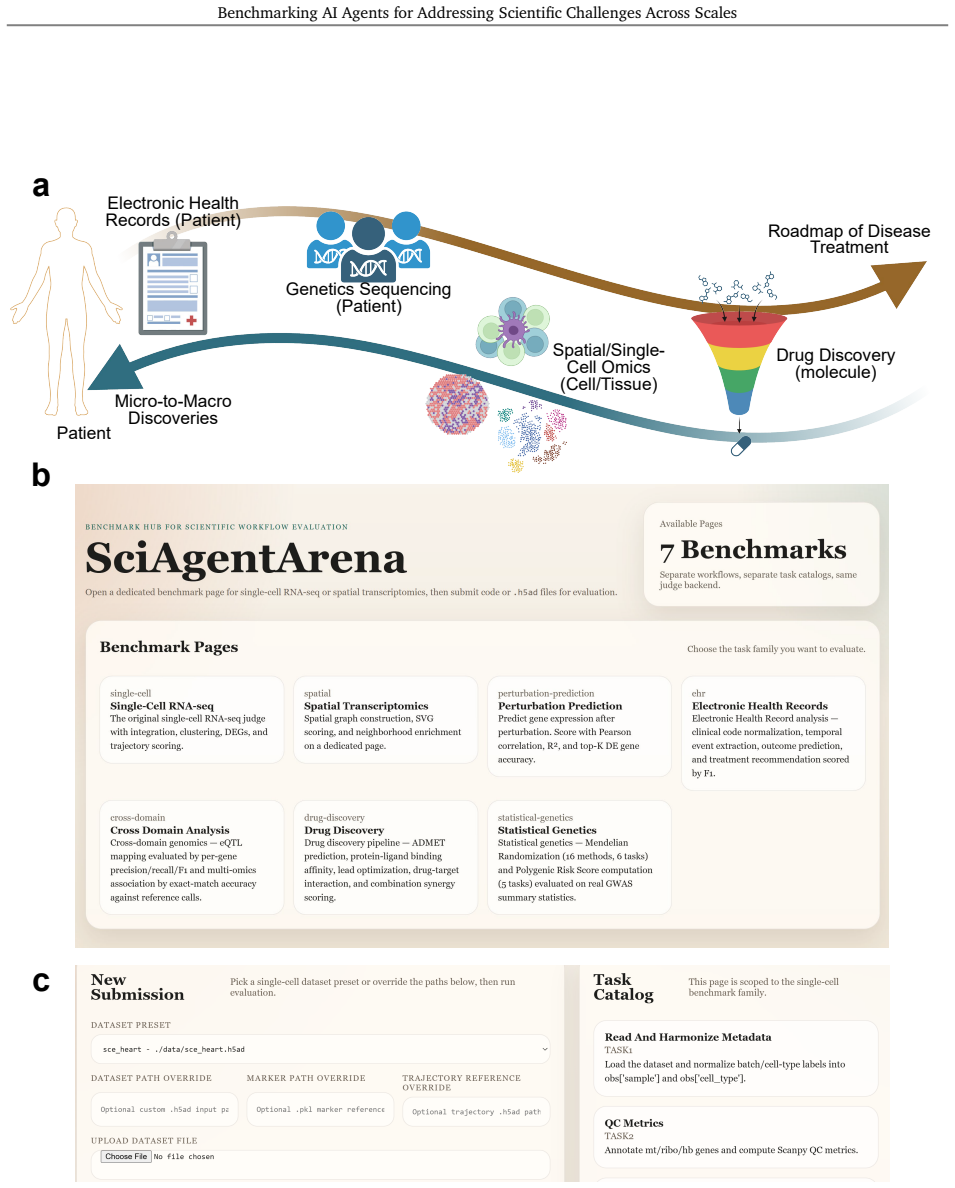
SciAgentArena supplies an interactive, agent-agnostic environment that shows current agents can support well-specified data-analysis workflows when task structure and success metrics are explicit, but performance drops sharply on tasks demanding genuinely novel insights, sustained self-directed exploration, or robust answers to open-ended scientific questions.
What carries the argument
SciAgentArena, a benchmark of approximately 200 tasks equipped with stepwise verification inside an interactive environment that supports diverse agents without favoring any single architecture.
If this is right
- Agents can already be integrated into pipelines that perform well-specified data analysis with explicit criteria.
- Common failure modes across agents have been catalogued, supplying concrete targets for reliability and autonomy improvements.
- The benchmark itself supplies a repeatable method for tracking whether future agents close the gap on novelty and self-directed work.
- Design of new agents can now be guided by the observed contrast between structured and open-ended scientific tasks.
Where Pith is reading between the lines
- The multi-domain construction of the benchmark makes it possible to test whether failure patterns are consistent across fields or remain domain-specific.
- Hybrid agent designs that combine structured analysis modules with separate hypothesis-generation modules could be evaluated directly against the same task set.
- Extending the benchmark with longer-horizon tasks that span weeks of simulated work would expose whether current limits on self-direction persist at realistic research timescales.
Load-bearing premise
The roughly 200 tasks chosen for SciAgentArena adequately represent the full range of complexity, heterogeneity, and extended reasoning found in actual scientific research.
What would settle it
An agent that produces and verifies a genuinely novel scientific result on a set of tasks constructed independently of the original 200 would contradict the reported limits on novelty and open-ended reasoning.
Figures





read the original abstract
AI agents are increasingly being developed to accelerate scientific discovery, yet their practical capabilities in real research settings remain poorly understood. Existing benchmarks for AI agents rarely capture the complexity, heterogeneity, and extended reasoning required by scientific work, whereas benchmarks for scientific tasks often reduce research to static, direct problems and provide limited support for interactive evaluation. Here, we introduce SciAgentArena, a systematic benchmark for evaluating AI agents in real-world scientific research scenarios drawn from emerging needs across multiple domains. SciAgentArena comprises approximately 200 tasks with stepwise verification and an interactive, agent-agnostic environment for assessing diverse AI agents. Using this benchmark, we find that current agents can contribute effectively to well-specified data-analysis workflows, particularly when the task structure and evaluation criteria are clear. However, their performance remains uneven across scientific contexts: agents struggle to generate genuinely novel insights, sustain self-directed exploration, and formulate robust solutions for open-ended research questions. We further characterize common failure modes across agents and identify opportunities for improving their reliability, autonomy, and scientific reasoning. Together, SciAgentArena provides a practical framework for measuring progress in AI agents for science and for guiding the design of future agents capable of addressing complex scientific challenges. Full codes, tasks, and datasets can be accessed via this link: https://sciagentarena.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SciAgentArena, a benchmark with approximately 200 tasks drawn from multiple scientific domains, featuring stepwise verification and an interactive agent-agnostic environment. It evaluates current AI agents and claims they perform effectively on well-specified data-analysis workflows with clear structure and criteria, but exhibit uneven results overall, struggling to generate novel insights, sustain self-directed exploration, or solve open-ended research questions. The work also identifies common failure modes and opportunities for improving agent reliability and scientific reasoning.
Significance. If the benchmark tasks are shown to be faithful proxies for real scientific complexity and extended reasoning, SciAgentArena would offer a practical, reproducible framework for tracking progress in AI for science and guiding agent design. The provision of full codes, tasks, and datasets is a strength that supports reproducibility.
major comments (2)
- [abstract and task construction section] Task construction and validation (abstract and §3): The central claim that performance gaps reflect agent limitations rather than benchmark artifacts rests on the ~200 tasks capturing 'complexity, heterogeneity, and extended reasoning.' No concrete criteria for domain sampling, expert validation of realism, or quantitative checks confirming sustained multi-step reasoning chains (vs. static problems) are supplied, undermining the diagnostic value of the reported uneven performance.
- [results and evaluation sections] Results and evaluation protocols (§4 and §5): The abstract states high-level findings on agent performance without reporting specific metrics, statistical tests, agent architectures/details, or evaluation protocols. This prevents assessment of whether the data-analysis success vs. open-ended failure distinction is robust or sensitive to task selection.
minor comments (1)
- [abstract] The link to codes/tasks/datasets is provided but the manuscript should include a brief summary table of task categories, domains, and verification steps for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify how to strengthen the presentation of SciAgentArena. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [abstract and task construction section] Task construction and validation (abstract and §3): The central claim that performance gaps reflect agent limitations rather than benchmark artifacts rests on the ~200 tasks capturing 'complexity, heterogeneity, and extended reasoning.' No concrete criteria for domain sampling, expert validation of realism, or quantitative checks confirming sustained multi-step reasoning chains (vs. static problems) are supplied, undermining the diagnostic value of the reported uneven performance.
Authors: We agree that Section 3 would benefit from greater explicitness. In the revision we will add: (i) the precise sampling criteria used to select the ~200 tasks across domains (prioritizing tasks drawn from recent open research questions and expert-identified gaps), (ii) the protocol for expert validation of task realism (including the number of domain scientists consulted and the rubric applied), and (iii) quantitative descriptors of reasoning depth (average verification steps per task, distribution of task lengths, and results from pilot studies confirming that tasks require sustained multi-step interaction rather than single-shot answers). These additions will directly support the claim that observed performance differences arise from agent capabilities. revision: yes
-
Referee: [results and evaluation sections] Results and evaluation protocols (§4 and §5): The abstract states high-level findings on agent performance without reporting specific metrics, statistical tests, agent architectures/details, or evaluation protocols. This prevents assessment of whether the data-analysis success vs. open-ended failure distinction is robust or sensitive to task selection.
Authors: Sections 4 and 5 already contain the requested details (per-task success rates, statistical comparisons, agent configurations, and the stepwise verification protocol). To make the abstract self-contained and allow immediate assessment of robustness, we will revise it to include a small number of key quantitative results (e.g., aggregate success rates on structured data-analysis tasks versus open-ended tasks) while retaining the high-level narrative. We view this as a modest but effective clarification. revision: yes
Circularity Check
Empirical benchmark paper with no derivations or self-referential steps
full rationale
This paper introduces an empirical benchmark (SciAgentArena) consisting of ~200 tasks for evaluating AI agents on scientific workflows. The abstract and described content contain no equations, fitted parameters, predictions derived from inputs, or derivation chains. Claims about agent performance rest on task construction and reported runs rather than any self-definitional or self-citation load-bearing logic. The assumption that tasks capture real scientific complexity is a design choice open to external validation, not a reduction by construction. No circular steps exist.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Closed-loop Auto Research for Molecular Property Prediction: Discovering and Certifying Generalizable Improvements
Closed-loop LM-agent auto research finds some transferable gains on molecular property prediction benchmarks via external data but shows non-transfer for model and feature edits selected on validation.
Reference graph
Works this paper leans on
-
[1]
A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2):1–124, 2023
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2):1–124, 2023
Pith/arXiv arXiv 2023
-
[2]
MouradGridach,JayNanavati,KhaldounZineElAbidine,LenonMendes,andChristinaMack. Agenticaiforscientificdiscovery: Asurveyofprogress,challenges,andfuturedirections.arXiv preprint arXiv:2503.08979, 2025
arXiv 2025
-
[3]
Litllms, llms for literature re- view: Are we there yet?arXiv preprint arXiv:2412.15249, 2024
Shubham Agarwal*, Gaurav Sahu*, Abhay Puri*, Issam H Laradji, Krishnamurthy DJ Dvi- jotham, Jason Stanley, Laurent Charlin, and Christopher Pal. Litllms, llms for literature re- view: Are we there yet?arXiv preprint arXiv:2412.15249, 2024. 38 Benchmarking AI Agents for Addressing Scientific Challenges Across Scales
arXiv 2024
-
[4]
Biomni: A general-purpose biomedical ai agent
KexinHuang, SerenaZhang, HanchenWang, YuanhaoQu, YingzhouLu, YusufRoohani, Ryan Li, Lin Qiu, Gavin Li, Junze Zhang, et al. Biomni: A general-purpose biomedical ai agent. biorxiv, 2025
2025
-
[5]
Yuanqi Du, Botao Yu, Tianyu Liu, Tony Shen, Junwu Chen, Jan G Rittig, Kunyang Sun, Yikun Zhang, Zhangde Song, Bo Zhou, et al. Accelerating scientific discovery with autonomous goal-evolving agents.arXiv preprint arXiv:2512.21782, 2025
arXiv 2025
-
[6]
Deep research: A survey of autonomous research agents.arXiv preprint arXiv:2508.12752, 2025
Wenlin Zhang, Xiaopeng Li, Yingyi Zhang, Pengyue Jia, Yichao Wang, Huifeng Guo, Yong Liu, and Xiangyu Zhao. Deep research: A survey of autonomous research agents.arXiv preprint arXiv:2508.12752, 2025
arXiv 2025
-
[7]
Deep research, 2026
OpenAI. Deep research, 2026
2026
-
[8]
Towards an ai co-scientist.arXiv preprint arXiv:2502.18864, 2025
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Ar- tiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, et al. Towards an ai co-scientist.arXiv preprint arXiv:2502.18864, 2025
Pith/arXiv arXiv 2025
-
[9]
Towards end-to-end automation of ai research.Nature, 651(8107):914– 919, 2026
Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Yamada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. Towards end-to-end automation of ai research.Nature, 651(8107):914– 919, 2026
2026
-
[10]
Yilun Zhao, Kaiyan Zhang, Tiansheng Hu, Sihong Wu, Ronan Le Bras, Taira Anderson, Jonathan Bragg, Joseph Chee Chang, Jesse Dodge, Matt Latzke, et al. Sciarena: An open evaluation platform for foundation models in scientific literature tasks.arXiv preprint arXiv:2507.01001, 2025
arXiv 2025
-
[11]
Evaluatinglargelanguagemodelsinscientificdiscovery
Zhangde Song, Jieyu Lu, Yuanqi Du, Botao Yu, Thomas M Pruyn, Yue Huang, Kehan Guo, XiuzheLuo,YuanhaoQu,YiQu,etal. Evaluatinglargelanguagemodelsinscientificdiscovery. arXiv preprint arXiv:2512.15567, 2025
Pith/arXiv arXiv 2025
-
[12]
Yujiong Shen, Yajie Yang, Zhiheng Xi, Binze Hu, Huayu Sha, Jiazheng Zhang, Qiyuan Peng, Junlin Shang, Jixuan Huang, Yutao Fan, et al. Sciagentgym: Benchmarking multi-step scien- tific tool-use in llm agents.arXiv preprint arXiv:2602.12984, 2026
Pith/arXiv arXiv 2026
-
[13]
Scienceagentbench: Toward rigorous assessment of lan- guage agents for data-driven scientific discovery
Ziru Chen, Shijie Chen, Yuting Ning, Qianheng Zhang, Boshi Wang, Botao Yu, Yifei Li, Zeyi Liao, Chen Wei, Zitong Lu, et al. Scienceagentbench: Toward rigorous assessment of lan- guage agents for data-driven scientific discovery. InThe Thirteenth International Conference on Learning Representations
-
[14]
Maojun Sun, Yifei Xie, Yue Wu, Ruijian Han, Binyan Jiang, Defeng Sun, Yancheng Yuan, and Jian Huang. Dsaeval: Evaluating data science agents on a wide range of real-world data science problems.arXiv preprint arXiv:2601.13591, 2026
Pith/arXiv arXiv 2026
-
[15]
Towards artificial intelligence research assistant for expert- involved learning.arXiv e-prints, pages arXiv–2505, 2025
Tianyu Liu, Simeng Han, Xiao Luo, Hanchen Wang, Pan Lu, Biqing Zhu, Yuge Wang, Keyi Li, Jiapeng Chen, Rihao Qu, et al. Towards artificial intelligence research assistant for expert- involved learning.arXiv e-prints, pages arXiv–2505, 2025
2025
-
[16]
Deepak Nathani, Lovish Madaan, Nicholas Roberts, Nikolay Bashlykov, Ajay Menon, Vincent Moens, Amar Budhiraja, Despoina Magka, Vladislav Vorotilov, Gaurav Chaurasia, et al. Ml- gym: A new framework and benchmark for advancing ai research agents.arXiv preprint arXiv:2502.14499, 2025. 39 Benchmarking AI Agents for Addressing Scientific Challenges Across Scales
arXiv 2025
-
[17]
Jonathan Bragg, Mike D’Arcy, Nishant Balepur, Dan Bareket, Bhavana Dalvi, Sergey Feldman, Dany Haddad, Jena D Hwang, Peter Jansen, Varsha Kishore, et al. Astabench: Rigorous benchmarking of ai agents with a scientific research suite.arXiv preprint arXiv:2510.21652, 2025
Pith/arXiv arXiv 2025
-
[18]
Math- arena: Evaluating llms on uncontaminated math competitions.Proceedings of the Neural In- formation Processing Systems Track on Datasets and Benchmark, 2025
Mislav Balunović, Jasper Dekoninck, Ivo Petrov, Nikola Jovanović, and Martin Vechev. Math- arena: Evaluating llms on uncontaminated math competitions.Proceedings of the Neural In- formation Processing Systems Track on Datasets and Benchmark, 2025
2025
-
[19]
Folio: Natural language reasoning with first-order logic
SimengHan,HaileySchoelkopf,YilunZhao,ZhentingQi,MartinRiddell,WenfeiZhou,James Coady, David Peng, Yujie Qiao, Luke Benson, et al. Folio: Natural language reasoning with first-order logic. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 22017–22031, 2024
2024
-
[20]
Scicode: Aresearchcodingbenchmarkcurated by scientists.Advances in Neural Information Processing Systems, 37:30624–30650, 2024
Minyang Tian, Luyu Gao, Shizhuo D Zhang, Xinan Chen, Cunwei Fan, Xuefei Guo, Roland Haas,PanJi,KittithatKrongchon,YaoLi,etal. Scicode: Aresearchcodingbenchmarkcurated by scientists.Advances in Neural Information Processing Systems, 37:30624–30650, 2024
2024
-
[21]
Swe-bench: Can language models resolve real-world github issues? In12th International Conference on Learning Representations, ICLR 2024, 2024
CarlosEJimenez,JohnYang,AlexanderWettig,ShunyuYao,KexinPei,OfirPress,andKarthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? In12th International Conference on Learning Representations, ICLR 2024, 2024
2024
-
[22]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst conference on language modeling, 2024
2024
-
[23]
Sci- enceqa: A novel resource for question answering on scholarly articles.International Journal on Digital Libraries, 23(3):289–301, 2022
Tanik Saikh, Tirthankar Ghosal, Amish Mittal, Asif Ekbal, and Pushpak Bhattacharyya. Sci- enceqa: A novel resource for question answering on scholarly articles.International Journal on Digital Libraries, 23(3):289–301, 2022
2022
-
[24]
Bioml-bench: Evaluation of ai agents for end-to-end biomedical ml.bioRxiv, pages 2025–09, 2025
HenryEMiller,MatthewGreenig,BenjaminTenmann,andBoWang. Bioml-bench: Evaluation of ai agents for end-to-end biomedical ml.bioRxiv, pages 2025–09, 2025
2025
-
[25]
Ludovico Mitchener, Jon M Laurent, Alex Andonian, Benjamin Tenmann, Siddharth Narayanan, Geemi P Wellawatte, Andrew White, Lorenzo Sani, and Samuel G Rodriques. Bixbench: a comprehensive benchmark for llm-based agents in computational biology.arXiv preprint arXiv:2503.00096, 2025
arXiv 2025
-
[26]
Erpai Luo, Jinmeng Jia, Yifan Xiong, Xiangyu Li, Xiaobo Guo, Baoqi Yu, Lei Wei, and Xuegong Zhang. Benchmarking ai scientists in omics data-driven biological research.arXiv preprint arXiv:2505.08341, 2025
arXiv 2025
-
[27]
Agentic systems are adept at solving well-scoped, verifiable problems in computational biol- ogy.bioRxiv, pages 2026–04, 2026
SuragNair,LauraGunsalus,BrianOrcutt-Jahns,JordanRossen,AvantikaLal,CarloDeDonno, Muhammed Hasan Celik, Kipper Fletez-Brant, Xiaoman Xie, Hector Corrada Bravo, et al. Agentic systems are adept at solving well-scoped, verifiable problems in computational biol- ogy.bioRxiv, pages 2026–04, 2026
2026
-
[28]
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
Pith/arXiv arXiv 2026
-
[29]
Gpt-5.2 system card.https://openai.com/index/ gpt-5-system-card-update-gpt-5-2/, 2025
OpenAI. Gpt-5.2 system card.https://openai.com/index/ gpt-5-system-card-update-gpt-5-2/, 2025. Accessed: 2026-04-18. 40 Benchmarking AI Agents for Addressing Scientific Challenges Across Scales
2025
-
[30]
Single cell analysis: the new frontier in ‘omics’.Trends in biotechnology, 28(6):281–290, 2010
Daojing Wang and Steven Bodovitz. Single cell analysis: the new frontier in ‘omics’.Trends in biotechnology, 28(6):281–290, 2010
2010
-
[31]
The dawn of spatial omics.Science, 381(6657):eabq4964, 2023
Dario Bressan, Giorgia Battistoni, and Gregory J Hannon. The dawn of spatial omics.Science, 381(6657):eabq4964, 2023
2023
-
[32]
The role of ai in drug discovery: challenges, opportunities, and strategies.Pharmaceuticals, 16(6):891, 2023
Alexandre Blanco-Gonzalez, Alfonso Cabezon, Alejandro Seco-Gonzalez, Daniel Conde- Torres, Paula Antelo-Riveiro, Angel Pineiro, and Rebeca Garcia-Fandino. The role of ai in drug discovery: challenges, opportunities, and strategies.Pharmaceuticals, 16(6):891, 2023
2023
-
[33]
From real-world electronic health record data to real- world results using artificial intelligence.Annals of the Rheumatic Diseases, 82(3):306–311, 2023
Rachel Knevel and Katherine P Liao. From real-world electronic health record data to real- world results using artificial intelligence.Annals of the Rheumatic Diseases, 82(3):306–311, 2023
2023
-
[34]
Engineeringaico-scientistsforstatisticalgeneticsapplications.NatureGenetics, pages 1–4, 2026
BingxinZhao. Engineeringaico-scientistsforstatisticalgeneticsapplications.NatureGenetics, pages 1–4, 2026
2026
-
[35]
Gemini 3 pro.https://storage.googleapis.com/deepmind-media/ Model-Cards/Gemini-3-Pro-Model-Card.pdf, 2025
Google. Gemini 3 pro.https://storage.googleapis.com/deepmind-media/ Model-Cards/Gemini-3-Pro-Model-Card.pdf, 2025. Accessed: 2026-04-18
2025
-
[36]
Claude sonnet 4.6.https://docs.anthropic.com/, 2025
Anthropic. Claude sonnet 4.6.https://docs.anthropic.com/, 2025. Accessed: 2026- 04-18
2025
-
[37]
Democratizing ai scientists using tooluniverse.arXiv preprint arXiv:2509.23426, 2025
Shanghua Gao, Richard Zhu, Pengwei Sui, Zhenglun Kong, Sufian Aldogom, Yepeng Huang, Ayush Noori, Reza Shamji, Krishna Parvataneni, Theodoros Tsiligkaridis, et al. Democratizing ai scientists using tooluniverse.arXiv preprint arXiv:2509.23426, 2025
arXiv 2025
-
[38]
ChatGPT Codex.https://chatgpt.com/codex/, 2026
OpenAI. ChatGPT Codex.https://chatgpt.com/codex/, 2026. Accessed: 2026-04-23
2026
-
[39]
Claude Code Overview.https://code.claude.com/docs/en/overview,
Anthropic. Claude Code Overview.https://code.claude.com/docs/en/overview,
-
[40]
Accessed: 2026-04-23
2026
-
[41]
Cellforge: agentic design of virtual cell models
Xiangru Tang, Zhuoyun Yu, Jiapeng Chen, Yan Cui, Daniel Shao, Weixu Wang, Fang Wu, Yuchen Zhuang, Wenqi Shi, Zhi Huang, et al. Cellforge: agentic design of virtual cell models. arXiv preprint arXiv:2508.02276, 2025
arXiv 2025
-
[42]
Stella: Towards a biomedical world model with self-evolving multimodal agents.bioRxiv, pages 2025–07, 2025
Ruofan Jin, Mingyang Xu, Fei Meng, Guancheng Wan, Qingran Cai, Yize Jiang, Jin Han, Yuanyuan Chen, Wanqing Lu, Mengyang Wang, et al. Stella: Towards a biomedical world model with self-evolving multimodal agents.bioRxiv, pages 2025–07, 2025
2025
-
[43]
An aiagentforfullyautomatedmulti-omic analyses.Advanced Science, 11(44):2407094, 2024
Juexiao Zhou, Bin Zhang, Guowei Li, Xiuying Chen, Haoyang Li, Xiaopeng Xu, Siyuan Chen, WenjiaHe, ChenchengXu, LiweiLiu, and XinGao. An aiagentforfullyautomatedmulti-omic analyses.Advanced Science, 11(44):2407094, 2024
2024
-
[44]
Txagent: An ai agent for therapeutic reason- ing across a universe of tools, 2025
Shanghua Gao, Richard Zhu, Zhenglun Kong, Ayush Noori, Xiaorui Su, Curtis Ginder, Theodoros Tsiligkaridis, and Marinka Zitnik. Txagent: An ai agent for therapeutic reason- ing across a universe of tools, 2025
2025
-
[45]
Medea: An omics ai agent for therapeutic discovery.bioRxiv, pages 2026–01, 2026
Pengwei Sui, Michelle M Li, Shanghua Gao, Wanxiang Shen, Valentina Giunchiglia, Andrew Shen, Yepeng Huang, Zhenglun Kong, and Marinka Zitnik. Medea: An omics ai agent for therapeutic discovery.bioRxiv, pages 2026–01, 2026
2026
-
[46]
McNaughton, Gautham Ramalaxmi, Agustin Kruel, Carter R
Andrew D. McNaughton, Gautham Ramalaxmi, Agustin Kruel, Carter R. Knutson, Rohith A. Varikoti, and Neeraj Kumar. Cactus: Chemistry agent connecting tool-usage to science. 2024. 41 Benchmarking AI Agents for Addressing Scientific Challenges Across Scales
2024
-
[47]
Baker, Ziru Chen, Garrett Herb, Boyu Gou, Daniel Adu-Ampratwum, Xia Ning, and Huan Sun
Botao Yu, Frazier N. Baker, Ziru Chen, Garrett Herb, Boyu Gou, Daniel Adu-Ampratwum, Xia Ning, and Huan Sun. Tooling or not tooling? the impact of tools on language agents for chemistry problem solving. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational Linguistics: NAACL 2025, pages 7635–7655, Albuquerque, N...
2025
-
[48]
Dru- gagent: Automating ai-aided drug discovery programming through llm multi-agent collabo- ration, 2025
Sizhe Liu, Yizhou Lu, Siyu Chen, Xiyang Hu, Jieyu Zhao, Yingzhou Lu, and Yue Zhao. Dru- gagent: Automating ai-aided drug discovery programming through llm multi-agent collabo- ration, 2025
2025
-
[49]
LIDDIA:Language-basedintelligent drug discovery agent
RezaAverly, FrazierN.Baker, IanAWatson, andXiaNing. LIDDIA:Language-basedintelligent drug discovery agent. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12004–12028, Suzhou, China, November 2025. Association for Comput...
2025
-
[50]
An auditable agent platform for automated molec- ular optimisation, 2025
Atabey Ünlü, Phil Rohr, and Ahmet Celebi. An auditable agent platform for automated molec- ular optimisation, 2025
2025
-
[51]
Mragent: an llm-based automated agent for causal knowledge discovery in disease via mendelian randomization.Briefings in Bioinformat- ics, 26(2):bbaf140, 03 2025
Wei Xu, Gang Luo, Weiyu Meng, Xiaobing Zhai, Keli Zheng, Ji Wu, Yanrong Li, Abao Xing, Junrong Li, Zhifan Li, Ke Zheng, and Kefeng Li. Mragent: an llm-based automated agent for causal knowledge discovery in disease via mendelian randomization.Briefings in Bioinformat- ics, 26(2):bbaf140, 03 2025
2025
-
[52]
RDKit: Open-source cheminformatics
-
[53]
Kexin Huang, Tianfan Fu, Wenhao Gao, Yue Zhao, Yusuf Roohani, Jure Leskovec, Con- nor W Coley, Cao Xiao, Jimeng Sun, and Marinka Zitnik. Therapeutics data commons: Machine learning datasets and tasks for drug discovery and development.arXiv preprint arXiv:2102.09548, 2021
arXiv 2021
-
[54]
Patrícia Bento, Jon Chambers, Marleen De Veij, Eloy Félix, María Paula Magariños, Juan F
David Mendez, Anna Gaulton, A. Patrícia Bento, Jon Chambers, Marleen De Veij, Eloy Félix, María Paula Magariños, Juan F. Mosquera, Prudence Mutowo, Michal Nowotka, María Gordillo-Marañón, FionaHunter, LauraJunco, GraceMugumbate, MilagrosRodriguez-Lopez, Francis Atkinson, Nicolas Bosc, Chris J. Radoux, Aldo Segura-Cabrera, Anne Hersey, and An- drew R. Leac...
2019
-
[55]
Gilson, Tiqing Liu, Michael Baitaluk, George Nicola, Linda Hwang, and Jenny Chong
Michael K. Gilson, Tiqing Liu, Michael Baitaluk, George Nicola, Linda Hwang, and Jenny Chong. BindingDB in 2015: A public database for medicinal chemistry, computational chem- istryandsystemspharmacology.NucleicAcidsResearch,44(D1):D1045–D1053,January2016
2015
-
[56]
Baell and Georgina A
Jonathan B. Baell and Georgina A. Holloway. New Substructure Filters for Removal of Pan Assay Interference Compounds (PAINS) from Screening Libraries and for Their Exclusion in Bioassays.Journal of Medicinal Chemistry, 53(7):2719–2740, April 2010
2010
-
[57]
Guacamol: bench- marking models for de novo molecular design.Journal of chemical information and modeling, 59(3):1096–1108, 2019
Nathan Brown, Marco Fiscato, Marwin HS Segler, and Alain C Vaucher. Guacamol: bench- marking models for de novo molecular design.Journal of chemical information and modeling, 59(3):1096–1108, 2019
2019
-
[58]
Clustering with the average silhouette width.Computa- tional Statistics & Data Analysis, 158:107190, 2021
Fatima Batool and Christian Hennig. Clustering with the average silhouette width.Computa- tional Statistics & Data Analysis, 158:107190, 2021. 42 Benchmarking AI Agents for Addressing Scientific Challenges Across Scales
2021
-
[59]
Fast, sensitive and accu- rate integration of single-cell data with harmony.Nature methods, 16(12):1289–1296, 2019
Ilya Korsunsky, Nghia Millard, Jean Fan, Kamil Slowikowski, Fan Zhang, Kevin Wei, Yuriy Baglaenko, Michael Brenner, Po-ru Loh, and Soumya Raychaudhuri. Fast, sensitive and accu- rate integration of single-cell data with harmony.Nature methods, 16(12):1289–1296, 2019
2019
-
[60]
Deep genera- tive modeling for single-cell transcriptomics.Nature methods, 15(12):1053–1058, 2018
Romain Lopez, Jeffrey Regier, Michael B Cole, Michael I Jordan, and Nir Yosef. Deep genera- tive modeling for single-cell transcriptomics.Nature methods, 15(12):1053–1058, 2018
2018
-
[61]
Moderated estimation of fold change and dispersion for rna-seq data with deseq2.Genome biology, 15(12):550, 2014
Michael I Love, Wolfgang Huber, and Simon Anders. Moderated estimation of fold change and dispersion for rna-seq data with deseq2.Genome biology, 15(12):550, 2014
2014
-
[62]
Modelingandpredicting single-cell multi-gene perturbation responses with sclambda.bioRxiv, 2024
GefeiWang, TianyuLiu, JiaZhao, YoushuCheng, andHongyuZhao. Modelingandpredicting single-cell multi-gene perturbation responses with sclambda.bioRxiv, 2024
2024
-
[63]
Ibarra, Olle Holmberg, Isaac Virshup, Mohammad Lotfollahi, Sabrina Richter, and Fabian J
Giovanni Palla, Hannah Spitzer, Michal Klein, David Fischer, Anna Christina Schaar, Louis Benedikt Kuemmerle, Sergei Rybakov, Ignacio L. Ibarra, Olle Holmberg, Isaac Virshup, Mohammad Lotfollahi, Sabrina Richter, and Fabian J. Theis. Squidpy: a scalable framework for spatial omics analysis.Nature Methods, 19(2):171–178, 2 2022
2022
-
[64]
Jensen, Lars J
Peter B. Jensen, Lars J. Jensen, and Søren Brunak. Mining electronic health records: towards better research applications and clinical care.Nature Reviews Genetics, 13(6):395–405, 2012
2012
-
[65]
George Hripcsak and David J. Albers. Next-generation phenotyping of electronic health records.Journal of the American Medical Informatics Association, 20(1):117–121, 2013
2013
-
[66]
Jason Walonoski, Mike Kramer, Justin Nichols, Anthony Quina, Christian Moesel, Derek Hall, Chris Duffett, Kristi Dube, Tony Gallagher, and Sean McLachlan. Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic elec- tronic health care record.Journal of the American Medical Informatics Association, 25(3):23...
2018
-
[68]
Polygenic prediction via bayesian regression and continuous shrinkage priors.Nature communications, 10(1):1776, 2019
Tian Ge, Chia-Yen Chen, Yang Ni, Yen-Chen Anne Feng, and Jordan W Smoller. Polygenic prediction via bayesian regression and continuous shrinkage priors.Nature communications, 10(1):1776, 2019
2019
-
[69]
Martin, Shengying Qin, Hail- iang Huang, and Tian Ge
Yunfeng Ruan, Yen-Feng Lin, Yen-Chen Anne Feng, Chia-Yen Chen, Max Lam, Zhenglin Guo, Stanley Global Asia Initiatives, Lin He, Akira Sawa, Alicia R. Martin, Shengying Qin, Hail- iang Huang, and Tian Ge. Improving polygenic prediction in ancestrally diverse populations. Nature Genetics, 54(5):573–580, May 2022
2022
-
[70]
The gtex consortium atlas of genetic regulatory effects across human tissues.Science, 369(6509):1318–1330, 2020
GTEx Consortium. The gtex consortium atlas of genetic regulatory effects across human tissues.Science, 369(6509):1318–1330, 2020
2020
-
[71]
On the art of compilingandusing’drug-like’chemicalfragmentspaces.ChemMedChem, 3(10):1503–1507, October 2008
Jörg Degen, Christof Wegscheid-Gerlach, Andrea Zaliani, and Matthias Rarey. On the art of compilingandusing’drug-like’chemicalfragmentspaces.ChemMedChem, 3(10):1503–1507, October 2008
2008
-
[72]
conda: Asystem-level,binarypackageandenvironmentmanagerrunning on all major operating systems and platforms
condacontributors. conda: Asystem-level,binarypackageandenvironmentmanagerrunning on all major operating systems and platforms
-
[73]
QuantStack and Mamba Contributors. mamba. 43 Benchmarking AI Agents for Addressing Scientific Challenges Across Scales
-
[74]
Shoemaker, Paul A
Sunghwan Kim, Jie Chen, Tiejun Cheng, Asta Gindulyte, Jia He, Siqian He, Qingliang Li, Benjamin A. Shoemaker, Paul A. Thiessen, Bo Yu, Leonid Zaslavsky, Jian Zhang, and Evan E. Bolton. PubChem in 2021: new data content and improved web interfaces.Nucleic Acids Research, 49(D1):D1388–D1395, January 2021
2021
-
[75]
ChEBI in 2016: Improved services and an expanding collection of metabolites.Nucleic Acids Research, 44(D1):D1214–1219, January 2016
Janna Hastings, Gareth Owen, Adriano Dekker, Marcus Ennis, Namrata Kale, Venkatesh Muthukrishnan, Steve Turner, Neil Swainston, Pedro Mendes, and Christoph Steinbeck. ChEBI in 2016: Improved services and an expanding collection of metabolites.Nucleic Acids Research, 44(D1):D1214–1219, January 2016
2016
-
[76]
Irwin and Brian K
John J. Irwin and Brian K. Shoichet. ZINC - A Free Database of Commercially Available Com- pounds for Virtual Screening.Journal of Chemical Information and Modeling, 45(1):177–182, January 2005
2005
-
[77]
A clinical road map for single-cell omics.Cell, 188(14):3633–3647, 2025
Michael A Skinnider, Gregoire Courtine, Jocelyne Bloch, and Jordan W Squair. A clinical road map for single-cell omics.Cell, 188(14):3633–3647, 2025
2025
-
[78]
Single- cell rna sequencing technologies and applications: a brief overview.Clinical and translational medicine, 12(3):e694, 2022
Dragomirka Jovic, Xue Liang, Hua Zeng, Lin Lin, Fengping Xu, and Yonglun Luo. Single- cell rna sequencing technologies and applications: a brief overview.Clinical and translational medicine, 12(3):e694, 2022
2022
-
[79]
Scanpy: large-scale single-cell gene expression data analysis.Genome biology, 19(1):15, 2018
F Alexander Wolf, Philipp Angerer, and Fabian J Theis. Scanpy: large-scale single-cell gene expression data analysis.Genome biology, 19(1):15, 2018
2018
-
[80]
Benchmarking atlas-level data integration in single-cell genomics.Nature methods, 19(1):41–50, 2022
Malte D Luecken, Maren Büttner, Kridsadakorn Chaichoompu, Anna Danese, Marta Inter- landi, Michaela F Müller, Daniel C Strobl, Luke Zappia, Martin Dugas, Maria Colomé-Tatché, et al. Benchmarking atlas-level data integration in single-cell genomics.Nature methods, 19(1):41–50, 2022
2022
-
[81]
Scikit- learn: Machine learning in python.the Journal of machine Learning research, 12:2825–2830, 2011
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit- learn: Machine learning in python.the Journal of machine Learning research, 12:2825–2830, 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.