Boundary-targeted Membership Inference Attacks on Safety Classifiers
Pith reviewed 2026-05-25 05:41 UTC · model grok-4.3
The pith
Safety classifiers leak training data when attacked on low-confidence boundary examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
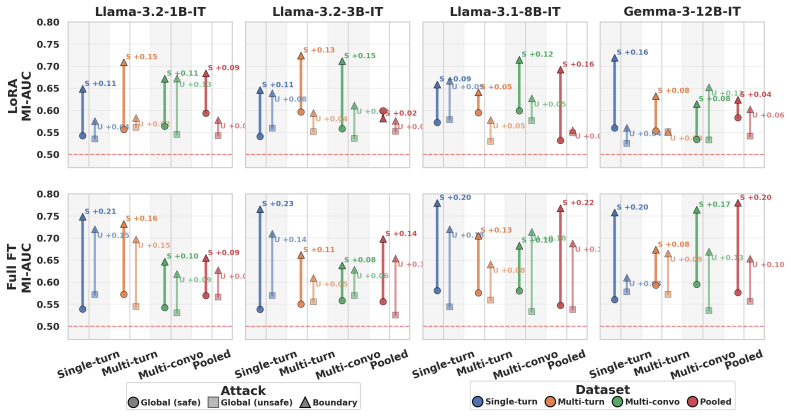
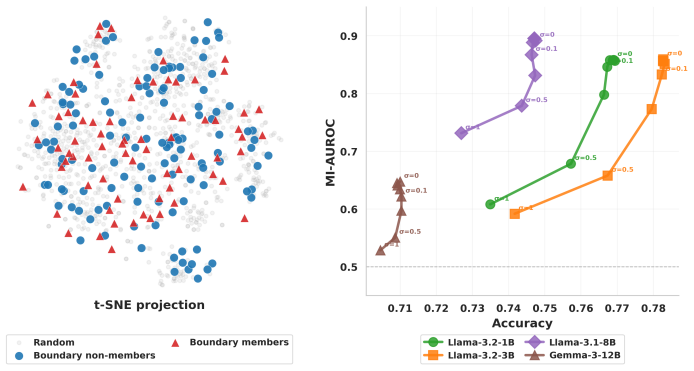
The paper claims that a boundary-targeted selection strategy, which prioritizes low-confidence examples, amplifies the membership signal enough to let an adversary recover 19 percent of the conversations a safety classifier flagged as indicating user distress, at a 5 percent false-positive rate. This holds for a fine-tuned classifier that detects users who may require emotional support, and the improvement is 3.5 times over state-of-the-art membership inference methods alone. The authors further characterize these boundary examples and report that content-based filtering fails to protect them while existing noise strategies reduce their susceptibility.
What carries the argument
boundary-targeted selection strategy that identifies low-confidence examples to amplify membership signals
If this is right
- Content-based filtering leaves boundary examples exposed to membership inference.
- Noise addition strategies reduce the leakage from low-confidence examples.
- The attack succeeds because of localized memorization failures on ambiguous training cases.
- The 19 percent recovery rate at 5 percent false-positive rate applies specifically to emotional-support safety classifiers.
Where Pith is reading between the lines
- Similar low-confidence targeting may expose training data in other moderation or safety models beyond emotional support detection.
- Auditing or removing ambiguous examples from training sets could shrink the attack surface.
- Uncertainty estimates themselves may become a new privacy signal if released or observable by adversaries.
Load-bearing premise
Low-confidence examples mark places where the model relies on memorization instead of generalization.
What would settle it
An experiment in which attacks on high-confidence examples recover as many or more training samples as the low-confidence boundary attack would falsify the central claim.
Figures


read the original abstract
Safety classifiers are essential safeguards within generative AI systems, filtering harmful content or identifying at-risk users when interacting with large language models. Despite their necessity, these models are trained on sensitive datasets including discussions of self-harm and mental health, raising important, yet poorly understood, privacy concerns. Membership inference attacks (MIAs) allow adversaries to infer membership of examples used to train models. In this work, we hypothesize that identifying the examples on which the classifier is least confident are informative for an adversary to infer membership. This reflects a localized failure of generalization, where the model relies on memorization to resolve ambiguity in the training set. To investigate this, we introduce a new boundary-targeted selection strategy that identifies low confidence examples that amplify the signal of an examples membership within a training set. Our experimental results show that an adversary can recover 19% of the conversations a safety classifier flagged as indicating user distress, at a 5% false-positive rate, on a classifier fine-tuned for detecting a user who may require emotional support. This is $3.5$ times more than attacking using state-of-the-art MIA methods alone. Finally, we characterize the boundary laying examples and show that content-based filtering is ineffective for protection, and existing noise strategies can effectively mitigate susceptibility of these examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a boundary-targeted membership inference attack on safety classifiers for detecting user distress or need for emotional support. It hypothesizes that low-confidence predictions reflect localized memorization failures that can be exploited by selecting boundary examples. The central empirical claim is that this strategy recovers 19% of flagged conversations at a 5% false-positive rate on a fine-tuned classifier, achieving a 3.5× improvement over state-of-the-art MIA methods alone. The work also characterizes boundary examples and evaluates mitigation via content filtering (ineffective) and noise addition (effective).
Significance. If the reported lift holds after proper controls, the result would indicate that standard MIAs underestimate privacy leakage in safety classifiers trained on subjective, sensitive mental-health data, particularly near decision boundaries. This could motivate targeted regularization or auditing for such models. The paper does not ship machine-checked proofs or parameter-free derivations.
major comments (2)
- [Abstract] Abstract: The 19% recovery at 5% FPR and 3.5× lift are stated without any description of the experimental setup, dataset splits, baseline MIA implementations, or how the low-confidence subset was constructed, making it impossible to verify whether the performance supports the memorization hypothesis or reduces to a task-specific heuristic.
- [Abstract] Abstract and § (method description): The central hypothesis—that low-confidence examples indicate localized memorization failures rather than intrinsic label ambiguity or class overlap in distress detection—is not isolated by any control experiment comparing member enrichment in low- vs. high-confidence subsets while holding task properties fixed; without this, the 3.5× gain cannot be attributed to amplified membership signal.
minor comments (1)
- [Abstract] The abstract uses 'conversations a safety classifier flagged' without clarifying whether this refers to the training set or a held-out set, which affects interpretation of the recovery rate.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need to better isolate the memorization hypothesis. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 19% recovery at 5% FPR and 3.5× lift are stated without any description of the experimental setup, dataset splits, baseline MIA implementations, or how the low-confidence subset was constructed, making it impossible to verify whether the performance supports the memorization hypothesis or reduces to a task-specific heuristic.
Authors: We agree the abstract is too high-level for a result of this nature. In the revision we will expand it to briefly state the dataset (distress-flagged conversations), the fine-tuning setup, how the low-confidence boundary subset is selected (bottom 10% confidence on the training distribution), the exact baseline MIA implementations (LiRA and LOSS), and the 5% FPR operating point. Full experimental details remain in Sections 3–4. revision: yes
-
Referee: [Abstract] Abstract and § (method description): The central hypothesis—that low-confidence examples indicate localized memorization failures rather than intrinsic label ambiguity or class overlap in distress detection—is not isolated by any control experiment comparing member enrichment in low- vs. high-confidence subsets while holding task properties fixed; without this, the 3.5× gain cannot be attributed to amplified membership signal.
Authors: The existing experiments already compare the boundary-targeted attack against standard MIAs on the identical classifier and data distribution, isolating the contribution of the low-confidence selection. Nevertheless, we acknowledge that an explicit low- vs. high-confidence member-enrichment control (holding label distribution and task fixed) would further strengthen the claim. We will add this control experiment in the revision, reporting membership inference AUC on both subsets. revision: yes
Circularity Check
No circularity: empirical attack success is measured, not derived by construction
full rationale
The paper presents a hypothesis about low-confidence examples and reports an empirical attack result (19% recovery at 5% FPR, 3.5× over SOTA MIA baselines) obtained by running the proposed boundary-targeted selection on a fine-tuned safety classifier. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The performance number is a direct experimental measurement on held-out data rather than a quantity that reduces to the hypothesis or to any input by definition. The interpretive claim that low confidence signals memorization is an assumption, not a load-bearing derivation step.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brendan, Mironov Ilya, Talwar Kunal, Zhang Li
Abadi Martin, Chu Andy, Goodfellow Ian, McMahan H. Brendan, Mironov Ilya, Talwar Kunal, Zhang Li. Deep Learning with Differential Privacy // Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. Vienna Austria: ACM, X
work page 2016
-
[2]
Carlini Nicholas, Chien Steve, Nasr Milad, Song Shuang, Terzis Andreas, Tramer Florian
308–318. Carlini Nicholas, Chien Steve, Nasr Milad, Song Shuang, Terzis Andreas, Tramer Florian. Member- ship inference attacks from first principles // 2022 IEEE symposium on security and privacy (SP). 2022a. 1897–1914. Carlini Nicholas, Ippolito Daphne, Jagielski Matthew, Lee Katherine, Tramer Florian, Zhang Chiyuan. Quantifying memorization across neur...
work page 2022
-
[3]
Chang Hongyan, Shahin Shamsabadi Ali, Katevas Kleomenis, Haddadi Hamed, Shokri Reza
2633–2650. Chang Hongyan, Shahin Shamsabadi Ali, Katevas Kleomenis, Haddadi Hamed, Shokri Reza. Context- Aware Membership Inference Attacks against Pre-trained Large Language Models // Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Suzhou, China: Association for Computational Linguistics, XI
work page 2025
-
[4]
Chaudhari Harsh, Abascal John, Oprea Alina, Jagielski Matthew, Tramer Florian, Ullman Jonathan
55005–55029. Chaudhari Harsh, Abascal John, Oprea Alina, Jagielski Matthew, Tramer Florian, Ullman Jonathan. SNAP: Efficient extraction of private properties with poisoning // 2023 IEEE Symposium on Security and Privacy (SP)
work page 2023
-
[5]
Cheng Myra, Lee Cinoo, Khadpe Pranav, Yu Sunny, Han Dyllan, Jurafsky Dan
22854–22874. Cheng Myra, Lee Cinoo, Khadpe Pranav, Yu Sunny, Han Dyllan, Jurafsky Dan. Sycophantic AI decreases prosocial intentions and promotes dependence // arXiv preprint arXiv:2510.01395
-
[6]
(Proceedings of Machine Learning Research)
1964–1974. (Proceedings of Machine Learning Research). 11 Cohan Arman, Desmet Bart, Yates Andrew, Soldaini Luca, MacAvaney Sean, Goharian Nazli. SMHD: a large-scale resource for exploring online language usage for multiple mental health conditions // Proceedings of the 27th international conference on computational linguistics
work page 1964
-
[7]
Cunningham Hoagy, Wei Jerry, Wang Zihan, Persic Andrew, Peng Alwin, Abderrachid Jordan, Agarwal Raj, Chen Bobby, Cohen Austin, Dau Andy, others. Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks // arXiv preprint arXiv:2601.04603
-
[8]
143–158. Farinhas António, Guerreiro Nuno M, Pombal José, Martins Pedro Henrique, Melton Laura, Conway Alex, Dochat Cara, D’Eon Maya, Rei Ricardo. MindGuard: Guardrail Classifiers for Multi-Turn Mental Health Support // arXiv preprint arXiv:2602.00950
-
[9]
Fleisig Eve, Abebe Rediet, Klein Dan
954–959. Fleisig Eve, Abebe Rediet, Klein Dan. When the majority is wrong: Modeling annotator disagreement for subjective tasks // Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
work page 2023
-
[10]
arXiv:2409.17190 [cs]. Hakim Joe B., Painter Jeffery L., Ramcharran Darmendra, Kara Vijay, Powell Greg, Sobczak Paulina, Sato Chiho, Bate Andrew, Beam Andrew. The Need for Guardrails with Large Language Models in Medical Safety-Critical Settings: An Artificial Intelligence Application in the Pharmacovigilance Ecosystem. IX
-
[11]
arXiv:2407.18322 [cs]. Hallinan Skyler, Jung Jaehun, Sclar Melanie, Lu Ximing, Ravichander Abhilasha, Ramnath Sahana, Choi Yejin, Karimireddy Sai Praneeth, Mireshghallah Niloofar, Ren Xiang. The surprising effec- tiveness of membership inference with simple n-gram coverage // arXiv preprint arXiv:2508.09603
-
[12]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Inan Hakan, Upasani Kartikeya, Chi Jianfeng, Rungta Rashi, Iyer Krithika, Mao Yuning, Tontchev Michael, Hu Qing, Fuller Brian, Testuggine Davide, others. Llama guard: Llm-based input-output safeguard for human-ai conversations // arXiv preprint arXiv:2312.06674
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Kramár János, Engels Joshua, Wang Zheng, Chughtai Bilal, Shah Rohin, Nanda Neel, Conmy Arthur
10697–10707. Kramár János, Engels Joshua, Wang Zheng, Chughtai Bilal, Shah Rohin, Nanda Neel, Conmy Arthur. Building Production-Ready Probes For Gemini // arXiv preprint arXiv:2601.11516
-
[14]
Leonardelli Elisa, Menini Stefano, Aprosio Alessio Palmero, Guerini Marco, Tonelli Sara
83–94. Leonardelli Elisa, Menini Stefano, Aprosio Alessio Palmero, Guerini Marco, Tonelli Sara. Agreeing to disagree: Annotating offensive language datasets with annotators’ disagreement // Proceedings of the 2021 conference on empirical methods in natural language processing
work page 2021
-
[15]
Lermen Simon, Paleka Daniel, Swanson Joshua, Aerni Michael, Carlini Nicholas, Tramèr Florian
10528–10539. Lermen Simon, Paleka Daniel, Swanson Joshua, Aerni Michael, Carlini Nicholas, Tramèr Florian. Large-scale online deanonymization with LLMs // arXiv preprint arXiv:2602.16800
-
[16]
Li Tianshi. Agentic LLMs as Powerful Deanonymizers: Re-identification of Participants in the Anthropic Interviewer Dataset // arXiv preprint arXiv:2601.05918
-
[17]
Lukas Nils, Salem Ahmed, Sim Robert, Tople Shruti, Wutschitz Lukas, Zanella-Béguelin Santiago
1–24. Lukas Nils, Salem Ahmed, Sim Robert, Tople Shruti, Wutschitz Lukas, Zanella-Béguelin Santiago. Analyzing Leakage of Personally Identifiable Information in Language Models // 2023 IEEE Symposium on Security and Privacy (SP). San Francisco, CA, USA: IEEE, V
work page 2023
-
[18]
Lv Lijia, Zhao Yuanshu, Wang Guan, Tang Xuehai, Jie Wen, Han Jizhong, Hu Songlin
346–363. Lv Lijia, Zhao Yuanshu, Wang Guan, Tang Xuehai, Jie Wen, Han Jizhong, Hu Songlin. Gamma-Guard: Lightweight Residual Adapters for Robust Guardrails in Large Language Models // Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
work page 2025
-
[19]
Mireshghallah Fatemehsadat, Goyal Kartik, Uniyal Archit, Berg-Kirkpatrick Taylor, Shokri Reza
61065–61105. Mireshghallah Fatemehsadat, Goyal Kartik, Uniyal Archit, Berg-Kirkpatrick Taylor, Shokri Reza. Quantifying Privacy Risks of Masked Language Models Using Membership Inference Attacks // Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, XII
work page 2022
-
[20]
Naseem Usman, Shiwakoti Shuvam, Shah Siddhant Bikram, Thapa Surendrabikram, Zhang Qi. GameTox: A Comprehensive Dataset and Analysis for Enhanced Toxicity Detection in Online Gaming Communities // Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume ...
work page 2025
-
[21]
Perez Ethan, Huang Saffron, Song Francis, Cai Trevor, Ring Roman, Aslanides John, Glaese Amelia, McAleese Nat, Irving Geoffrey. Red teaming language models with language models // Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing
work page 2022
-
[22]
Reimers Nils, Gurevych Iryna. Sentence-bert: Sentence embeddings using siamese bert-networks // Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP)
work page 2019
-
[23]
Rossi Lorenzo, Aerni Michael, Zhang Jie, Tramèr Florian
3982–3992. Rossi Lorenzo, Aerni Michael, Zhang Jie, Tramèr Florian. Membership Inference Attacks on Sequence Models // 2025 IEEE Security and Privacy Workshops (SPW)
work page 2025
-
[24]
98–110. Sharma Mrinank, Tong Meg, Mu Jesse, Wei Jerry, Kruthoff Jorrit, Goodfriend Scott, Ong Euan, Peng Alwin, Agarwal Raj, Anil Cem, others. Constitutional classifiers: Defending against universal jailbreaks across thousands of hours of red teaming // arXiv preprint arXiv:2501.18837
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Shejwalkar Virat, Inan Huseyin A., Houmansadr Amir, Sim Robert. Membership Inference Attacks Against NLP Classification Models // NeurIPS 2021 Workshop Privacy in Machine Learning
work page 2021
-
[26]
Shokri Reza, Stronati Marco, Song Congzheng, Shmatikov Vitaly. Membership Inference Attacks Against Machine Learning Models // 2017 IEEE Symposium on Security and Privacy (SP). San Jose, CA, USA: IEEE, V
work page 2017
-
[27]
Steenstra Ian, Pedrelli Paola, Shi Weiyan, Marsella Stacy, Bickmore Timothy W. Assessing Risks of Large Language Models in Mental Health Support: A Framework for Automated Clinical AI Red Teaming // arXiv preprint arXiv:2602.19948
-
[28]
Team Gemma, Kamath Aishwarya, Ferret Johan, Pathak Shreya, Vieillard Nino, Merhej Ramona, Perrin Sarah, Matejovicova Tatiana, Ramé Alexandre, Others. Gemma 3 Technical Report. 2025a. Team Olmo, Ettinger A, Bertsch A, Kuehl B, Graham D, Heineman D, Groeneveld D, Brahman F , Timbers F , Ivison H, others. Olmo 3 // arXiv preprint arXiv:2512.13961. 2025b. 23–...
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Wang Zezhong, Yang Fangkai, Wang Lu, Zhao Pu, Wang Hongru, Chen Liang, Lin Qingwei, Wong Kam-Fai
240–254. Wang Zezhong, Yang Fangkai, Wang Lu, Zhao Pu, Wang Hongru, Chen Liang, Lin Qingwei, Wong Kam-Fai. Self-guard: Empower the llm to safeguard itself // Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers)
work page 2024
-
[30]
Xie Roy, Wang Junlin, Huang Ruomin, Zhang Minxing, Ge Rong, Pei Jian, Gong Neil Zhenqiang, Dhingra Bhuwan. ReCaLL: Membership Inference via Relative Conditional Log-Likelihoods // Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Miami, Florida, USA: Association for Computational Linguistics, XI
work page 2024
-
[31]
Yeom Samuel, Giacomelli Irene, Fredrikson Matt, Jha Somesh
8671–8689. Yeom Samuel, Giacomelli Irene, Fredrikson Matt, Jha Somesh. Privacy risk in machine learning: An- alyzing the connection to overfitting // 2018 IEEE 31st computer security foundations symposium (CSF)
work page 2018
-
[32]
40306–40320. Zeng Wenjun, Kurniawan Dana, Mullins Ryan, Liu Yuchi, Saha Tamoghna, Ike-Njoku Dirichi, Gu Jindong, Song Yiwen, Xu Cai, Zhou Jingjing, others. Shieldgemma 2: Robust and tractable image content moderation // arXiv preprint arXiv:2504.01081
-
[33]
ShieldGemma: Generative AI Content Moderation Based on Gemma
Zeng Wenjun, Liu Yuchi, Mullins Ryan, Peran Ludovic, Fernandez Joe, Harkous Hamza, Narasimhan Karthik, Proud Drew, Kumar Piyush, Radharapu Bhaktipriya, others. Shieldgemma: Generative ai content moderation based on gemma // arXiv preprint arXiv:2407.21772
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Zhang Ziqi, Shahin Shamsabadi Ali, Lu Hanxiao, Cai Yifeng, Haddadi Hamed. Membership and Memorization in LLM Knowledge Distillation // Proceedings of the 2025 Conference on Empir- ical Methods in Natural Language Processing. Suzhou, China: Association for Computational Linguistics, XI
work page 2025
-
[35]
20074–20084. 15 Zhao Haiquan, Yuan Chenhan, Huang Fei, Hu Xiaomeng, Zhang Yichang, Yang An, Yu Bowen, Liu Dayiheng, Zhou Jingren, Lin Junyang, others. Qwen3guard technical report // arXiv preprint arXiv:2510.14276
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Hyperparameter Value Sequence length Single-turn (BeaverTails) 1024 Multi-turn (XGuard) 8192 Multi-session (Emotional Support) 16394 Pooled 16394 Table 5: Sequenc lengths for classifier fine-tuning. K Compute All experiments were conducted on a single compute node equipped with 4× NVIDIA H100 NVL GPUs (94 GB VRAM each), an AMD EPYC 9454 48-Core CPU, and 7...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.