Probabilistic Contrastive Pretraining for Multi-task ADME Property Prediction
Pith reviewed 2026-06-27 13:33 UTC · model grok-4.3
The pith
A single probabilistic objective unifies graph reconstruction and contrastive tasks to improve multi-task ADME prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that Contrastive KERMT pretraining, which encodes molecular graphs into latent variables, reconstructs SMILES from those codes, augments the contrastive objective with domain-specific chemistry tasks, and formulates reconstruction, contrastive discrimination, and chemistry-specific supervision as unit-weighted log-probability factors inside a single probabilistic latent-variable objective, produces the stated improvements on the three datasets while the contrastive part sharpens chemically meaningful latent neighborhoods.
What carries the argument
The single probabilistic latent-variable objective that treats reconstruction, contrastive discrimination, and chemistry-specific supervision as unit-weighted log-probability factors.
If this is right
- The pretraining produces consistent gains on ADME endpoints across the three evaluated datasets.
- Including ADME-adjacent molecules in the pretraining corpus further improves transfer performance.
- The contrastive component creates chemically meaningful latent neighborhoods.
- The multi-task GNN readout with task-specific heads mitigates negative transfer while modeling nonlinear task relationships.
Where Pith is reading between the lines
- The unified objective could be applied to other multi-task molecular property problems where manual loss balancing is difficult.
- The same probabilistic framing might be tested on non-ADME endpoints to check whether the balancing effect holds more broadly.
- Larger pretraining corpora could be used to test whether the reported gains increase with scale.
Load-bearing premise
That treating reconstruction, contrastive discrimination, and chemistry-specific supervision as unit-weighted log-probability factors inside a single probabilistic latent-variable objective will automatically balance heterogeneous tasks without negative transfer or the need for per-task loss weighting.
What would settle it
An ablation experiment that replaces the unified probabilistic objective with separately tuned loss weights for each pretraining task and measures whether the reported performance gains on Biogen, ExpansionRX, and ChEMBL-MT still appear.
Figures









read the original abstract
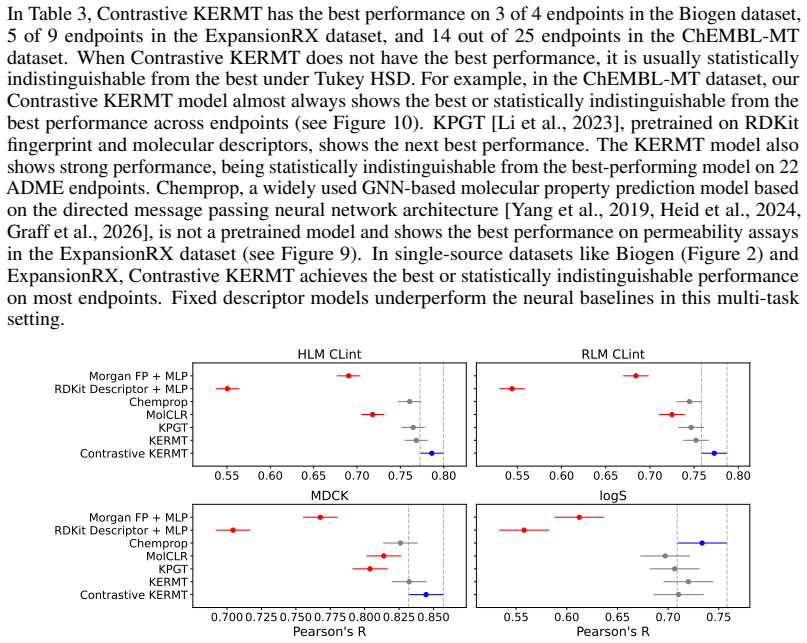
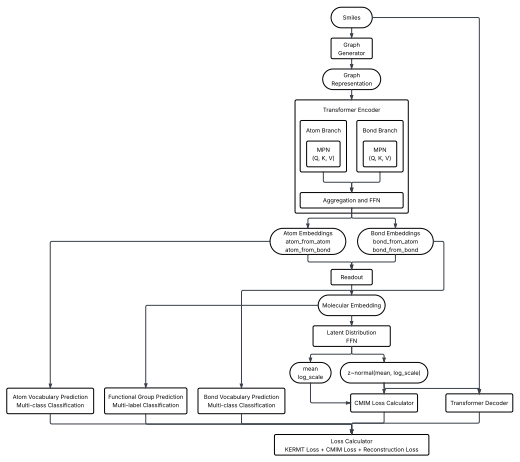
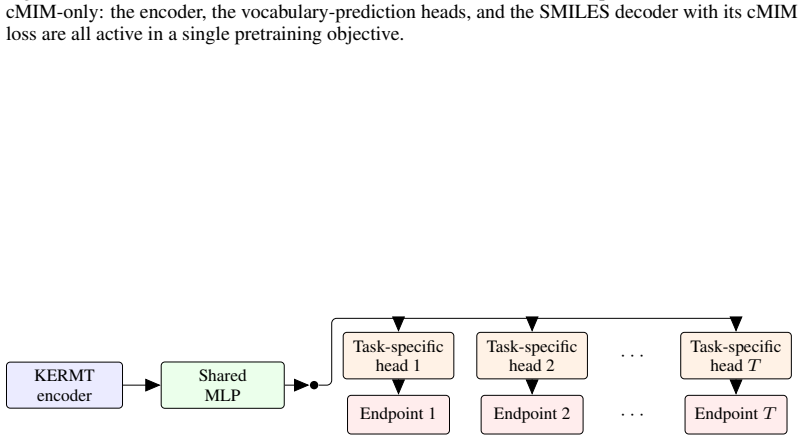
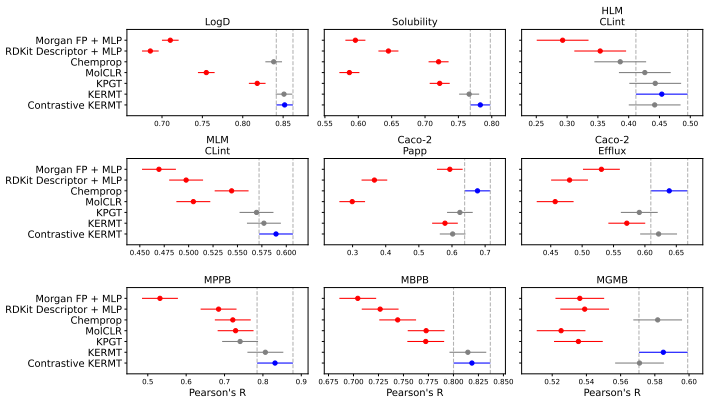
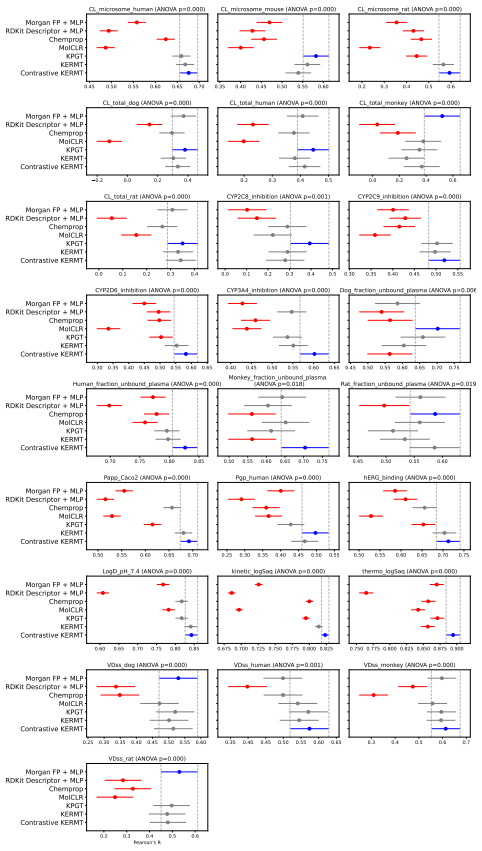
Accurate prediction of absorption, distribution, metabolism, and excretion (ADME) properties is critical to drug discovery, but remains challenging because ADME endpoints are noisy, interdependent, and often data-limited. We propose a molecular graph-transformer pretraining framework that combines chemistry-specific self-supervision with contrastive mutual information machine learning (cMIM). Our method encodes molecular graphs into latent variables, reconstructs SMILES strings from the graph-derived latent codes, and augments the contrastive objective with domain-specific self-supervised chemistry tasks. Rather than treating these tasks as auxiliary regularizers with separately tuned loss weights, we formulate reconstruction, contrastive discrimination, and chemistry-specific supervision as unit-weighted log-probability factors in a single probabilistic latent-variable objective. For fine-tuning, we propose a multi-task GNN readout architecture with task-specific multilayer perceptron heads, preserving shared representation learning while mitigating negative transfer and improving the modeling of heterogeneous, nonlinear task relationships. Across Biogen, ExpansionRX, and ChEMBL-MT, the resulting Contrastive KERMT pretraining improves over the KERMT baseline by 7.6%, 9.9%, and 9.5% respectively (averaged over significantly-improved endpoints). Adding ADME-adjacent molecules to the pretraining corpus further improves transfer, and the contrastive component sharpens chemically meaningful latent neighborhoods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a molecular graph-transformer pretraining framework called Contrastive KERMT that encodes graphs into latent variables, reconstructs SMILES, and augments a contrastive objective with domain-specific chemistry tasks. These are formulated as unit-weighted log-probability factors inside a single probabilistic latent-variable objective rather than as separately weighted auxiliaries. A multi-task GNN readout with task-specific MLP heads is used at fine-tuning time. The method is reported to yield average improvements of 7.6%, 9.9%, and 9.5% over the KERMT baseline on the Biogen, ExpansionRX, and ChEMBL-MT datasets (averaged over significantly improved endpoints), with further gains from adding ADME-adjacent molecules to pretraining.
Significance. If the empirical gains are robust, the work would offer a practical route to multi-task ADME modeling that mitigates negative transfer via a unified probabilistic objective. The explicit credit for treating reconstruction, contrastive discrimination, and chemistry supervision as commensurate log-probability terms without per-task weighting is a methodological contribution worth testing; reproducible code or ablation tables on loss-scale commensurability would strengthen the case.
major comments (3)
- [Abstract, §4] Abstract (final paragraph) and §4 (results): the central claim that unit-weighted log-probability factors automatically balance reconstruction, contrastive, and chemistry-specific terms without negative transfer or per-task weighting is load-bearing for the reported gains, yet no ablation on relative gradient magnitudes, loss-scale histograms, or controlled weighting experiments is referenced to confirm the scales are commensurate.
- [Abstract] Abstract (results paragraph): the percentage improvements (7.6%, 9.9%, 9.5%) are presented as averaged over significantly-improved endpoints, but the text supplies no description of the data-split protocol, number of runs, statistical tests, or error bars, preventing evaluation of whether the gains are statistically distinguishable from the KERMT baseline.
- [Abstract] Abstract (method paragraph): the multi-task GNN readout is introduced only at fine-tuning time and is said to mitigate negative transfer, but the pretraining objective itself is asserted to require no per-task weighting; evidence that the chemistry-specific terms do not overwhelm the contrastive term during pretraining is needed to support the unit-weight claim.
minor comments (2)
- [Methods] Notation for the joint probabilistic objective (latent-variable formulation) should be introduced with an explicit equation early in the methods section to clarify how the three log-probability factors are combined.
- [Figures] Figure captions for latent-space visualizations should state the exact projection method (e.g., t-SNE parameters) and whether the neighborhoods are evaluated quantitatively (e.g., via neighborhood purity metrics).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications on our probabilistic formulation and indicating revisions where additional evidence or details will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract (final paragraph) and §4 (results): the central claim that unit-weighted log-probability factors automatically balance reconstruction, contrastive, and chemistry-specific terms without negative transfer or per-task weighting is load-bearing for the reported gains, yet no ablation on relative gradient magnitudes, loss-scale histograms, or controlled weighting experiments is referenced to confirm the scales are commensurate.
Authors: The unit-weighted formulation is motivated by expressing all terms (reconstruction, contrastive discrimination, and chemistry-specific supervision) as log-probability factors in a single latent-variable model, which places them on commensurate scales by construction without manual weighting. We acknowledge that explicit empirical checks on gradient magnitudes would provide stronger support. In the revised version we will add an analysis of per-term gradient norms and loss-component histograms during pretraining to verify balance. revision: yes
-
Referee: [Abstract] Abstract (results paragraph): the percentage improvements (7.6%, 9.9%, 9.5%) are presented as averaged over significantly-improved endpoints, but the text supplies no description of the data-split protocol, number of runs, statistical tests, or error bars, preventing evaluation of whether the gains are statistically distinguishable from the KERMT baseline.
Authors: Section 4 of the manuscript details the evaluation protocol, including scaffold-based splits, five independent runs per endpoint, paired t-tests for significance, and reporting of standard errors. The abstract summarizes the headline numbers for brevity. We will expand the abstract with a concise statement on the evaluation protocol and statistical testing to make the gains more readily interpretable. revision: partial
-
Referee: [Abstract] Abstract (method paragraph): the multi-task GNN readout is introduced only at fine-tuning time and is said to mitigate negative transfer, but the pretraining objective itself is asserted to require no per-task weighting; evidence that the chemistry-specific terms do not overwhelm the contrastive term during pretraining is needed to support the unit-weight claim.
Authors: Because the pretraining objective is a single joint probabilistic model, all terms are log-probabilities and therefore commensurate without per-task weights; the multi-task GNN readout with task-specific heads is applied only at fine-tuning to accommodate heterogeneous ADME endpoints. To directly address the concern we will include training curves showing the evolution of each loss component, confirming that the contrastive term remains active throughout pretraining. revision: yes
Circularity Check
No circularity: empirical gains from modeling choice, not algebraic reduction
full rationale
The paper presents the unit-weighted log-probability formulation of reconstruction, contrastive, and chemistry tasks as an explicit modeling decision rather than a derived result. Reported improvements (7.6%, 9.9%, 9.5%) are framed as experimental outcomes on Biogen, ExpansionRX, and ChEMBL-MT after pretraining and fine-tuning, with no equations shown that reduce a claimed prediction to a fitted input by construction. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work appear in the abstract or described architecture. The multi-task readout is introduced at fine-tuning time as an empirical mitigation strategy. The derivation chain is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1910.04153 , year=
High Mutual Information in Representation Learning with Symmetric Variational Inference , author=. arXiv preprint arXiv:1910.04153 , year=
-
[2]
arXiv preprint arXiv:2003.02645 , year=
Sentencemim: A latent variable language model , author=. arXiv preprint arXiv:2003.02645 , year=
-
[3]
arXiv preprint arXiv:2509.21511 , year=
Contrastive Mutual Information Learning: Toward Robust Representations without Positive-Pair Augmentations , author=. arXiv preprint arXiv:2509.21511 , year=
-
[4]
Advances in neural information processing systems , volume=
Self-supervised graph transformer on large-scale molecular data , author=. Advances in neural information processing systems , volume=
-
[5]
arXiv preprint arXiv:2208.09016 , year=
Improving small molecule generation using mutual information machine , author=. arXiv preprint arXiv:2208.09016 , year=
-
[6]
Journal of Chemical Information and Modeling , volume=
Prospective validation of machine learning algorithms for absorption, distribution, metabolism, and excretion prediction: An industrial perspective , author=. Journal of Chemical Information and Modeling , volume=. 2023 , publisher=
2023
-
[7]
2026 , howpublished=
2026
-
[8]
Nucleic acids research , volume=
ChEMBL: towards direct deposition of bioassay data , author=. Nucleic acids research , volume=. 2019 , publisher=
2019
-
[9]
arXiv preprint arXiv:2510.12719 , year=
Multitask finetuning and acceleration of chemical pretrained models for small molecule drug property prediction , author=. arXiv preprint arXiv:2510.12719 , year=
-
[10]
Nature Communications , publisher =
Li, Han and Zhang, Ruotian and Min, Yaosen and Ma, Dacheng and Zhao, Dan and Zeng, Jianyang , doi =. Nature Communications , publisher =
-
[11]
and Chung, Yunsie and Li, Shih-Cheng and Graff, David E
Heid, Esther and Greenman, Kevin P. and Chung, Yunsie and Li, Shih-Cheng and Graff, David E. and Vermeire, Florence H. and Wu, Haoyang and Green, William H. and McGill, Charles J. , doi =. Journal of Chemical Information and Modeling , month =
-
[12]
and Morgan, Nathan K
Graff, David E. and Morgan, Nathan K. and Burns, Jackson W. and Doner, Anna C. and Li, Brian and Li, Shih-Cheng and Manu, Joel and Menon, Angiras and Pang, Hao-Wei and Wu, Haoyang and Zalte, Akshat Shirish and Zheng, Jonathan W. and Coley, Connor W. and Green, William H. and Greenman, Kevin P. , title =. Journal of Chemical Information and Modeling , volu...
2026
-
[13]
, title =
Kelley, Brian P. , title =. 2018 , howpublished =
2018
-
[14]
Journal of Chemical Information and Modeling , volume =
Yang, Kevin and Swanson, Kyle and Jin, Wengong and Coley, Connor and Eiden, Philipp and Gao, Hua and Guzman-Perez, Angel and Hopper, Timothy and Kelley, Brian and Mathea, Miriam and Palmer, Andrew and Settels, Volker and Jaakkola, Tommi and Jensen, Klavs and Barzilay, Regina , title =. Journal of Chemical Information and Modeling , volume =. 2019 , doi =
2019
-
[15]
Journal of Chemical Information and Modeling , volume =
Rogers, David and Hahn, Mathew , title =. Journal of Chemical Information and Modeling , volume =. 2010 , doi =
2010
-
[16]
, title =
Sterling, Teague and Irwin, John J. , title =. Journal of Chemical Information and Modeling , volume =. 2015 , doi =
2015
-
[17]
Journal of Chemical Information and Computer Sciences , volume =
Weininger, David , title =. Journal of Chemical Information and Computer Sciences , volume =. 1988 , doi =
1988
-
[18]
Bajusz, D. Why Is. Journal of Cheminformatics , volume =. 2015 , doi =
2015
-
[19]
Proceedings of the International Conference on Artificial Neural Networks (ICANN 2001) , pages =
Venna, Jarkko and Kaski, Samuel , title =. Proceedings of the International Conference on Artificial Neural Networks (ICANN 2001) , pages =. 2001 , publisher =
2001
-
[20]
and Murcko, Mark A
Bemis, Guy W. and Murcko, Mark A. , title =. Journal of Medicinal Chemistry , volume =. 1996 , doi =
1996
-
[21]
Journal of Chemical Information and Computer Sciences , volume =
Butina, Darko , title =. Journal of Chemical Information and Computer Sciences , volume =. 1999 , doi =
1999
-
[22]
and Kaiser, Lukasz and Polosukhin, Illia , title =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , title =. Advances in Neural Information Processing Systems , volume =
-
[23]
Neurocomputing , volume =
Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Wen, Bo and Liu, Yunfeng , title =. Neurocomputing , volume =. 2024 , doi =
2024
-
[24]
and Wognum, Cas and Rodríguez-P
Ash, Jeremy R. and Wognum, Cas and Rodríguez-P. Practically Significant Method Comparison Protocols for Machine Learning in Small Molecule Drug Discovery , journal =. 2025 , doi =
2025
-
[25]
and Humbeck, Lina and Skalic, Miha , title =
Walter, Moritz and Borghardt, Jens M. and Humbeck, Lina and Skalic, Miha , title =. Molecular Informatics , volume =. doi:https://doi.org/10.1002/minf.202400079 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/minf.202400079 , abstract =
-
[26]
, title =
Chen, Jacky and Chung, Yunsie and Tynan, Jonathan and Cheng, Chen and Yang, Song and Cheng, Alan C. , title =. Journal of Chemical Information and Modeling , volume =. 2025 , doi =
2025
-
[27]
Molecules , VOLUME =
Montanari, Floriane and Kuhnke, Lara and Ter Laak, Antonius and Clevert, Djork-Arné , TITLE =. Molecules , VOLUME =. 2020 , NUMBER =
2020
-
[28]
, title =
Sheridan, Robert P. , title =. Journal of Chemical Information and Modeling , volume =. 2013 , doi =
2013
-
[29]
and Riley, Patrick F
Gilmer, Justin and Schoenholz, Samuel S. and Riley, Patrick F. and Vinyals, Oriol and Dahl, George E. , title =. Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =. 2017 , publisher =
2017
-
[30]
Journal of Medicinal Chemistry , volume =
Xiong, Zhaoping and Wang, Dingyan and Liu, Xiaohong and Zhong, Feisheng and Wan, Xiaozhe and Li, Xutong and Li, Zhaojun and Luo, Xiaomin and Chen, Kaixian and Jiang, Hualiang and Zheng, Mingyue , title =. Journal of Medicinal Chemistry , volume =. 2020 , doi =
2020
-
[31]
Nature Communications , year =
Multi-channel learning for integrating structural hierarchies into context-dependent molecular representation , author =. Nature Communications , year =. doi:10.1038/s41467-024-55082-4 , url =
-
[32]
Multi-task Neural Networks for QSAR Predictions
Multi-task Neural Networks for QSAR Predictions , author =. arXiv preprint arXiv:1406.1231 , year =. doi:10.48550/arXiv.1406.1231 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1406.1231
-
[33]
2023 , howpublished =
Walters, Patrick , title =. 2023 , howpublished =
2023
-
[34]
and Ash, J
Wognum, C. and Ash, J. R. and Aldeghi, M. and Rodríguez-Pérez, R. and Fang, C. and Cheng, A. C. and Price, D. J. and Clevert, D.-A. and Engkvist, O. and Walters, W. P. , title =. Nature Machine Intelligence , year =
-
[35]
Balani, Suresh K. and Miwa, Gerald T. and Gan, Liang-Shang and Wu, Jing-Tao and Lee, Frank W. , Keywords =. Strategy of Utilizing In Vitro and In Vivo ADME Tools for Lead Optimization and Drug Candidate Selection , Journal =. 2005 , ISSN =. doi:10.2174/156802605774297038 , URL =
-
[36]
Expert Opinion on Drug Metabolism & Toxicology , volume =
Mario Pellegatti , title =. Expert Opinion on Drug Metabolism & Toxicology , volume =. 2012 , publisher =. doi:10.1517/17425255.2012.652084 , note =
-
[37]
and Arimoto, Rieko and Desino, Kelly E
Lombardo, Franco and Desai, Prashant V. and Arimoto, Rieko and Desino, Kelly E. and Fischer, Holger and Keefer, Christopher E. and Petersson, Carl and Winiwarter, Susanne and Broccatelli, Fabio , title =. Journal of Medicinal Chemistry , volume =. 2017 , doi =
2017
-
[38]
Prediction of Small-Molecule Developability Using Large-Scale In Silico ADMET Models , journal =
Beckers, Maximilian and Sturm, No. Prediction of Small-Molecule Developability Using Large-Scale In Silico ADMET Models , journal =. 2023 , doi =
2023
-
[39]
Future Medicinal Chemistry , volume =
Elena L Cáceres and Matthew Tudor and Alan C Cheng , title =. Future Medicinal Chemistry , volume =. 2020 , publisher =. doi:10.4155/fmc-2020-0259 , note =
-
[40]
Wang, Yuyang and Wang, Jianren and Cao, Zhonglin and Barati Farimani, Amir , date =. Molecular contrastive learning of representations via graph neural networks , url =. Nature Machine Intelligence , number =. 2022 , bdsk-url-1 =. doi:10.1038/s42256-022-00447-x , id =
-
[41]
Semi-Supervised Classification with Graph Convolutional Networks
Semi-supervised classification with graph convolutional networks , author=. arXiv preprint arXiv:1609.02907 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
arXiv preprint arXiv:2212.02229 , year=
Gps++: An optimised hybrid mpnn/transformer for molecular property prediction , author=. arXiv preprint arXiv:2212.02229 , year=
-
[43]
Advances in Neural Information Processing Systems , volume=
On the scalability of gnns for molecular graphs , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Chemical Science , volume=
MoleculeNet: a benchmark for molecular machine learning , author=. Chemical Science , volume=. 2018 , doi=
2018
-
[45]
, journal=
Honda, Shion and Shi, Shoi and Ueda, Hiroki R. , journal=. 2019 , url=
2019
-
[46]
2020 , url=
Chithrananda, Seyone and Grand, Gabriel and Ramsundar, Bharath , journal=. 2020 , url=
2020
-
[47]
Nature Machine Intelligence , volume=
Large-scale chemical language representations capture molecular structure and properties , author=. Nature Machine Intelligence , volume=. 2022 , doi=
2022
-
[48]
2023 , url=
Zhou, Gengmo and Gao, Zhifeng and Ding, Qiankun and Zheng, Hang and Xu, Hongteng and Wei, Zhewei and Zhang, Linfeng and Ke, Guolin , booktitle=. 2023 , url=
2023
-
[49]
Nature Communications , volume=
A self-conformation-aware pre-training framework for molecular property prediction with substructure interpretability , author=. Nature Communications , volume=. 2025 , doi=
2025
-
[50]
2020 , url=
Sun, Fan-Yun and Hoffmann, Jordan and Verma, Vikas and Tang, Jian , booktitle=. 2020 , url=
2020
-
[51]
Advances in Neural Information Processing Systems , volume=
Graph Contrastive Learning with Augmentations , author=. Advances in Neural Information Processing Systems , volume=. 2020 , url=
2020
-
[52]
Proceedings of the 37th International Conference on Machine Learning , series=
Which Tasks Should Be Learned Together in Multi-task Learning? , author=. Proceedings of the 37th International Conference on Machine Learning , series=. 2020 , url=
2020
-
[53]
and Svetnik, Vladimir , title =
Xu, Yuting and Ma, Junshui and Liaw, Andy and Sheridan, Robert P. and Svetnik, Vladimir , title =. Journal of Chemical Information and Modeling , volume =. 2017 , doi =
2017
-
[54]
arXiv preprint arXiv:2009.09796 , year=
Multi-task learning with deep neural networks: A survey , author=. arXiv preprint arXiv:2009.09796 , year=
-
[55]
Multi-task learning for natural language processing in the 2020s: Where are we going? , journal =
Joseph Worsham and Jugal Kalita , keywords =. Multi-task learning for natural language processing in the 2020s: Where are we going? , journal =. 2020 , issn =. doi:https://doi.org/10.1016/j.patrec.2020.05.031 , url =
-
[56]
A Survey on Multi-Task Learning , year=
Zhang, Yu and Yang, Qiang , journal=. A Survey on Multi-Task Learning , year=
-
[57]
An Overview of Multi-Task Learning in Deep Neural Networks
An overview of multi-task learning in deep neural networks , author=. arXiv preprint arXiv:1706.05098 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Machine learning , volume=
Multitask learning , author=. Machine learning , volume=. 1997 , publisher=
1997
-
[59]
doi:10.5281/zenodo.18098214 , url =
Greg Landrum and others , title =. doi:10.5281/zenodo.18098214 , url =
-
[60]
, title =
Adrian, Matthew and Chung, Yunsie and Cheng, Alan C. , title =. Journal of Chemical Information and Modeling , volume =. 2024 , doi =
2024
-
[61]
2022 , howpublished =
Wang, Yuyang , title =. 2022 , howpublished =
2022
-
[62]
2023 , howpublished =
Li, Han , title =. 2023 , howpublished =
2023
-
[63]
9th Python in Science Conference , year=
statsmodels: Econometric and statistical modeling with python , author=. 9th Python in Science Conference , year=
-
[64]
Nature chemical biology , volume=
Artificial intelligence foundation for therapeutic science , author=. Nature chemical biology , volume=. 2022 , publisher=
2022
-
[65]
and Chan, Yvonne H
Rich, Alexander S. and Chan, Yvonne H. and Birnbaum, Benjamin and Haider, Kamran and Haimson, Joshua and Hale, Michael and Han, Yongxin and Hickman, William and Hoeflich, Klaus P. and Ortwine, Daniel and. Machine Learning ADME Models in Practice: Four Guidelines from a Successful Lead Optimization Case Study , journal =. 2024 , doi =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.