Divide and Conquer: Reliable Multi-View Evidential Learning for Deepfake Detection
Pith reviewed 2026-06-28 14:58 UTC · model grok-4.3
The pith
Geometric projection decomposes representations into semantic and artifact views, which evidential learning then reconciles to yield better generalization and calibrated uncertainty in deepfake detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
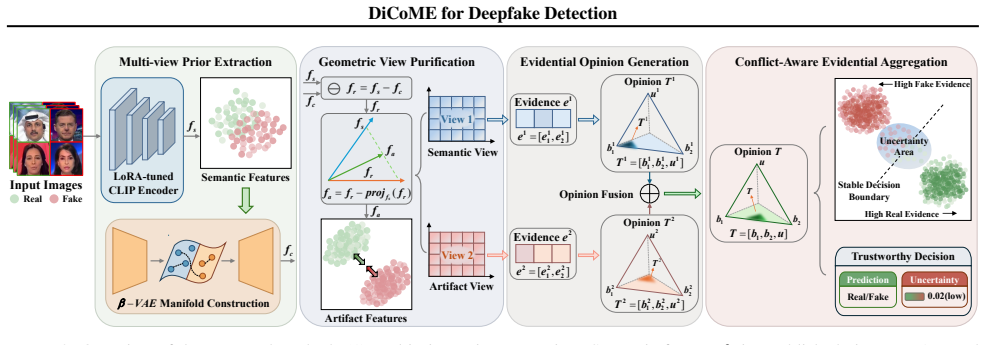
By employing Geometric View Purification in the Divide phase to suppress semantic interference within artifact-sensitive representations and form decorrelated semantic and artifact views, then using Uncertainty-Aware Evidential Learning in the Conquer phase to synthesize these views by modeling their epistemic conflict, the DiCoME framework achieves consistent outperformance in generalization performance on multiple benchmarks while providing calibrated uncertainty estimates for trustworthy deepfake detection.
What carries the argument
The Divide-and-Conquer Multi-View Evidential Learning (DiCoME) mechanism, specifically the geometric projection that decomposes the entangled representation space and the evidential learning that handles epistemic conflict between views.
If this is right
- Existing single-view methods are outperformed in generalization on deepfake benchmarks.
- Predictions come with calibrated uncertainty rather than overconfidence.
- Semantic and artifact cues are treated as complementary rather than entangled.
- The framework avoids rigid deterministic decisions by accounting for view conflicts.
Where Pith is reading between the lines
- Similar view separation techniques might help in other detection tasks where high-level semantics mask low-level anomalies.
- Uncertainty outputs could enable active learning by prioritizing uncertain samples for labeling.
- The approach suggests that explicit conflict modeling between feature types is key to robustness against generative model evolution.
Load-bearing premise
The geometric projection step suppresses semantic interference inside artifact-sensitive representations without discarding information needed for detection.
What would settle it
A new deepfake benchmark where the method shows no improvement in generalization accuracy or where its uncertainty estimates fail to correlate with actual error rates compared to baselines.
Figures




read the original abstract
With the evolution of generative models, deepfakes have achieved near-perfect semantic realism, leaving forensic traces only in subtle structural anomalies. However, existing single-view paradigms often fail to generalize, as dominant semantic features overwhelm subtle artifact cues within entangled representations. This imbalance leads to overconfident yet brittle predictions -- a phenomenon we term the Semantic Masking Effect. To address this challenge, we propose a reliable framework called Divide-and-Conquer Multi-View Evidential Learning (DiCoME) for Deepfake Detection. In the "Divide" phase, we employ Geometric View Purification to decompose the entangled representation space through principled geometric projection. This process suppresses semantic interference within artifact-sensitive representations, forming the foundation for decorrelated yet complementary semantic and artifact views. In the "Conquer" phase, we leverage Uncertainty-Aware Evidential Learning to synthesize these distinct views. By explicitly modeling the "epistemic conflict" between semantic and artifact cues, this mechanism provides calibrated uncertainty estimates instead of forcing rigid deterministic decisions. Extensive experiments across multiple benchmarks demonstrate that our method consistently outperforms existing approaches in generalization performance, while providing reliable uncertainty estimation for trustworthy deepfake detection. Code is available at https://github.com/kxl0825/DiCoME.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DiCoME, a Divide-and-Conquer Multi-View Evidential Learning framework for deepfake detection. It identifies the Semantic Masking Effect in single-view methods and addresses it via a Divide phase using Geometric View Purification (geometric projection to create decorrelated semantic and artifact views) and a Conquer phase using Uncertainty-Aware Evidential Learning to model epistemic conflict between views, yielding calibrated uncertainty. The abstract claims consistent outperformance in generalization across multiple benchmarks plus reliable uncertainty estimates, with code released.
Significance. If the geometric projection and evidential synthesis deliver the claimed decorrelation and calibration without discarding detection-critical information, the work could strengthen trustworthy deepfake detection by mitigating overconfidence and improving cross-domain generalization, both of which are practically important.
Simulated Author's Rebuttal
We thank the referee for reviewing our manuscript and for the summary provided. The recommendation is listed as 'uncertain,' but the report contains no specific major comments to address point by point. We remain available to supply additional experiments, clarifications, or revisions should the referee identify particular concerns.
Circularity Check
No significant circularity detected
full rationale
The abstract and provided text contain no equations, no explicit derivation chain, and no self-citations that reduce any claimed prediction or result to a fitted input or prior ansatz by construction. The method description (Geometric View Purification and Uncertainty-Aware Evidential Learning) is presented at a high level without mathematical reductions that could be inspected for equivalence to inputs. Per the rules, absence of quotable load-bearing steps that collapse to self-definition or fitted renaming means the derivation is treated as self-contained; honest non-finding is the required outcome when no concrete reduction is exhibitable.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A geometric projection can decorrelate semantic and artifact cues without loss of detection-critical information.
- domain assumption Modeling epistemic conflict between views yields calibrated uncertainty estimates.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Generative adversarial nets , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[3]
Heliyon , volume=
Exploring autonomous methods for deepfake detection: A detailed survey on techniques and evaluation , author=. Heliyon , volume=. 2025 , publisher=
2025
-
[4]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Towards Universal AI-Generated Image Detection by Variational Information Bottleneck Network , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[5]
European conference on computer vision , pages=
Fake it till you make it: Curricular dynamic forgery augmentations towards general deepfake detection , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[6]
arXiv preprint arXiv:2503.02857 , year=
Deepfake-eval-2024: A multi-modal in-the-wild benchmark of deepfakes circulated in 2024 , author=. arXiv preprint arXiv:2503.02857 , year=
Pith/arXiv arXiv 2024
-
[7]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Faceforensics++: Learning to detect manipulated facial images , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[8]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[9]
IEEE transactions on pattern analysis and machine intelligence , volume=
Trusted multi-view classification with dynamic evidential fusion , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2022 , publisher=
2022
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[11]
European conference on computer vision , pages=
Thinking in frequency: Face forgery detection by mining frequency-aware clues , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[12]
IEEE transactions on pattern analysis and machine intelligence , year=
Fakecatcher: Detection of synthetic portrait videos using biological signals , author=. IEEE transactions on pattern analysis and machine intelligence , year=
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Cao, Junyi and Ma, Chao and Yao, Taiping and Chen, Shen and Ding, Shouhong and Yang, Xiaokang , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
-
[14]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Tall: Thumbnail layout for deepfake video detection , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[15]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Forensics adapter: Adapting clip for generalizable face forgery detection , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[16]
arXiv preprint arXiv:2508.06248 , year=
Deepfake Detection that Generalizes Across Benchmarks , author=. arXiv preprint arXiv:2508.06248 , year=
-
[17]
Neurocomputing , volume=
FDML: Feature Disentangling and Multi-view Learning for face forgery detection , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[18]
Orthogonal Subspace Decomposition for Generalizable
Yan, Zhiyuan and Wang, Jiangming and Jin, Peng and Zhang, Ke-Yue and Liu, Chengchun and Chen, Shen and Yao, Taiping and Ding, Shouhong and Wu, Baoyuan and Yuan, Li , booktitle =. Orthogonal Subspace Decomposition for Generalizable. 2025 , publisher =
2025
-
[19]
Advances in neural information processing systems , volume=
What uncertainties do we need in bayesian deep learning for computer vision? , author=. Advances in neural information processing systems , volume=
-
[20]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Multi-attentional deepfake detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[21]
Advances in neural information processing systems , volume=
Evidential deep learning to quantify classification uncertainty , author=. Advances in neural information processing systems , volume=
-
[22]
2018 , publisher=
Subjective Logic: A formalism for reasoning under uncertainty , author=. 2018 , publisher=
2018
-
[23]
2011 , publisher=
Dirichlet and related distributions: Theory, methods and applications , author=. 2011 , publisher=
2011
-
[24]
Journal of the Royal Statistical Society: Series B (Methodological) , volume=
A generalization of Bayesian inference , author=. Journal of the Royal Statistical Society: Series B (Methodological) , volume=. 1968 , publisher=
1968
-
[25]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[26]
International conference on learning representations , year=
beta-vae: Learning basic visual concepts with a constrained variational framework , author=. International conference on learning representations , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
DeepfakeBench: A Comprehensive Benchmark of Deepfake Detection , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[29]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Celeb-df: A large-scale challenging dataset for deepfake forensics , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[30]
Deepfake Detection Challenge , year =
-
[31]
2020 , howpublished =
Contributing Data to. 2020 , howpublished =
2020
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
Proceedings of the 28th ACM international conference on multimedia , pages=
Wilddeepfake: A challenging real-world dataset for deepfake detection , author=. Proceedings of the 28th ACM international conference on multimedia , pages=
-
[34]
arXiv preprint arXiv:2507.18015 , year=
Celeb-df++: A large-scale challenging video deepfake benchmark for generalizable forensics , author=. arXiv preprint arXiv:2507.18015 , year=
-
[35]
Advances in Neural Information Processing Systems , volume=
Df40: Toward next-generation deepfake detection , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Spatial-phase shallow learning: rethinking face forgery detection in frequency domain , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[37]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Generalizing face forgery detection with high-frequency features , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Core: Consistent representation learning for face forgery detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Detecting deepfakes with self-blended images , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[40]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Ucf: Uncovering common features for generalizable deepfake detection , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[41]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Implicit identity driven deepfake face swapping detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Transcending forgery specificity with latent space augmentation for generalizable deepfake detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[43]
Advances in Neural Information Processing Systems , volume=
Can we leave deepfake data behind in training deepfake detector? , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , month =
Yermakov, Andrii and Cech, Jan and Matas, Jiri and Fritz, Mario , title =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , month =
-
[45]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Face x-ray for more general face forgery detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[46]
European conference on computer vision , pages=
What makes fake images detectable? understanding properties that generalize , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[47]
IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , year=
Exposing DeepFake Videos By Detecting Face Warping Artifacts , author=. IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , year=
-
[48]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Exploring Temporal Coherence for More General Video Face Forgery Detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[49]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Lips Don't Lie: A Generalisable and Robust Approach To Face Forgery Detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[50]
arXiv preprint arXiv:2512.04837 , year=
A Sanity Check for Multi-In-Domain Face Forgery Detection in the Real World , author=. arXiv preprint arXiv:2512.04837 , year=
-
[51]
IEEE Transactions on Image Processing , year=
Ed ˆ4: Explicit data-level debiasing for deepfake detection , author=. IEEE Transactions on Image Processing , year=
-
[52]
Advances in Neural Information Processing Systems , volume=
Diffusionfake: Enhancing generalization in deepfake detection via guided stable diffusion , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Generalization-Preserved Learning: Closing the Backdoor to Catastrophic Forgetting in Continual Deepfake Detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.