Exploring Dualistic Meta-Learning to Enhance Domain Generalization in Open Set Scenarios
Pith reviewed 2026-06-26 09:16 UTC · model grok-4.3
The pith
MEDIC uses simultaneous inter-domain and inter-class gradient matching in meta-learning to balance one-vs-all classifier boundaries for open set domain generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By considering implicit gradient matching towards inter-domain and inter-class task splits simultaneously, MEDIC finds optimal boundaries balanced for both domains and classes, correcting the skew that one-vs-all classifiers exhibit under sample imbalance in open set domain generalization.
What carries the argument
dualistic meta-learning with joint domain-class matching (MEDIC), which performs simultaneous implicit gradient matching on inter-domain and inter-class splits to produce balanced boundaries.
If this is right
- MEDIC outperforms prior open-set domain generalization methods.
- The approach maintains competitive performance on standard closed-set domain generalization tasks.
- It reduces over-rejection of out-of-distribution samples that belong to known classes.
- The same meta-learning procedure can be applied when both domain and label shifts are present.
Where Pith is reading between the lines
- The dual-matching idea might transfer to other multi-objective meta-learning problems that involve simultaneous shifts of different types.
- If the balancing effect holds, similar joint-split training could be tested in federated or continual learning settings with both domain and class imbalance.
- The method suggests exploring whether explicit rather than implicit gradient matching yields further gains when the number of splits increases.
Load-bearing premise
That sample imbalance is the main cause of skewed boundaries in one-vs-all classifiers and that simultaneous gradient matching on domain and class splits will produce balanced boundaries without creating new problems.
What would settle it
An ablation experiment in which the joint domain-class matching component is removed yet open-set performance remains unchanged, or a controlled setting where balanced boundaries appear without the dualistic split.
Figures


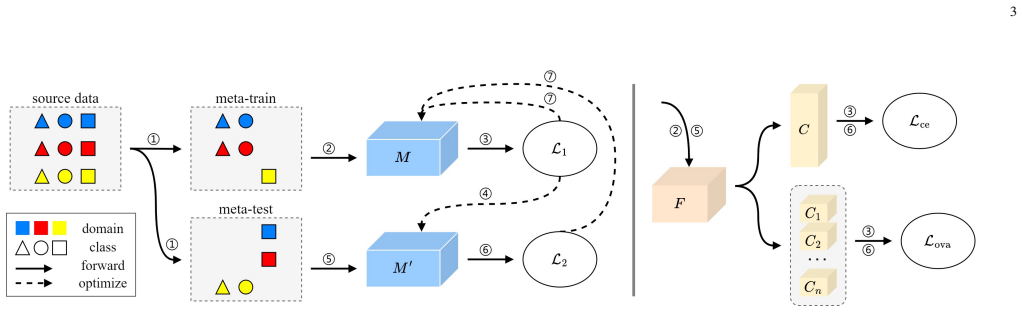
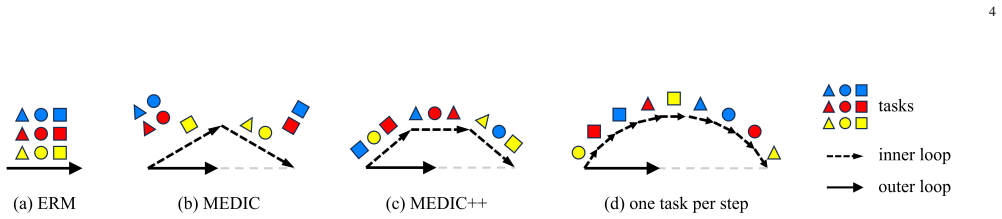


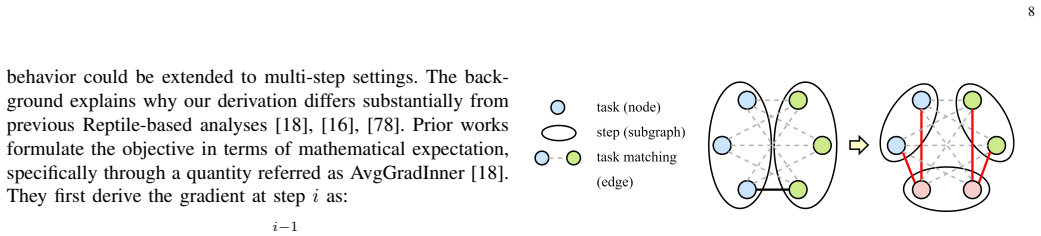
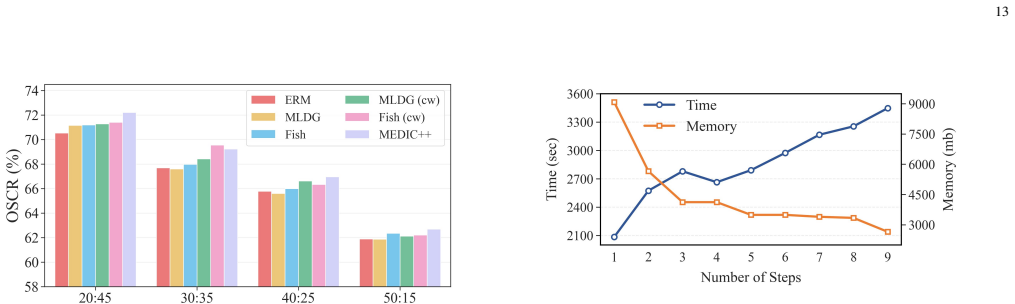

read the original abstract
Domain generalization learns from multiple source domains to generalize to unseen target domains. However, it often neglects the realistic case of label mismatch between source and target. Open set domain generalization is then proposed to recognize unseen classes in unseen domains. A simple approach trains one-vs-all classifiers to separate each class and detect outliers as unknown. Yet, the imbalance between few positive samples and many negative samples skews the decision boundary towards the positive ones, leading the model to over-reject out-of-distribution data, even from known classes in unseen domains. In this paper, we propose a novel meta-learning stategy called dualistic MEta-learning with joint DomaIn-Class matching (MEDIC), which considers implicit gradient matching towards inter-domain and inter-class task splits simultaneously to find optimal boundaries balanced for both domains and classes. Experimental results show that MEDIC not only outperforms prior methods in open set scenarios, but also maintains competitive close set generalization ability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MEDIC, a dualistic meta-learning strategy for open set domain generalization. It identifies that one-vs-all classifiers suffer from positive-negative sample imbalance that skews decision boundaries toward positives, causing over-rejection of known classes from unseen domains. MEDIC performs implicit gradient matching simultaneously on inter-domain and inter-class task splits to produce boundaries balanced for both, and reports experimental outperformance over prior methods in open-set settings while remaining competitive on closed-set generalization.
Significance. If the central claim holds, the work supplies a mechanistic meta-learning solution that jointly targets domain and class imbalance via gradient matching, which could strengthen robustness in realistic open-set DG scenarios. The explicit construction linking the identified skew problem to dualistic matching is a clear strength of the approach as described.
minor comments (2)
- Ensure that the full methods section provides the precise formulation of the joint implicit gradient matching objective (including any weighting between domain and class splits) so that the balancing mechanism can be directly inspected and reproduced.
- The abstract states that MEDIC 'maintains competitive close set generalization ability'; include quantitative tables comparing closed-set accuracy against the same baselines used for open-set evaluation to support this claim.
Simulated Author's Rebuttal
We thank the referee for the summary of our MEDIC approach for open-set domain generalization. The report provides no specific major comments despite the 'uncertain' recommendation, so we have no points to address point-by-point at this time. We remain available to respond to any additional feedback or concerns the referee may have.
Circularity Check
No significant circularity detected
full rationale
The paper presents MEDIC as a novel meta-learning strategy that applies implicit gradient matching simultaneously to inter-domain and inter-class task splits to address boundary skew in one-vs-all classifiers for open-set domain generalization. The abstract and description supply a direct mechanistic motivation without any equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claim to its own inputs by construction. The method is constructed to target the stated imbalance problem rather than deriving from prior results of the same authors or re-labeling known patterns. This is the most common honest finding for a method paper whose core contribution is an explicit algorithmic design choice.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Research on overfitting of deep learning,
H. Li, J. Li, X. Guan, B. Liang, Y . Lai, and X. Luo, “Research on overfitting of deep learning,” in2019 15th International Conference on Computational Intelligence and Security, 2019, pp. 78–81
2019
-
[2]
Generalizing to unseen domains: A survey on domain generalization,
J. Wang, C. Lan, C. Liu, Y . Ouyang, T. Qin, W. Lu, Y . Chen, W. Zeng, and P. Yu, “Generalizing to unseen domains: A survey on domain generalization,”IEEE Transactions on Knowledge and Data Engineering, 2022
2022
-
[3]
Learning to generalize: Meta-learning for domain generalization,
D. Li, Y . Yang, Y .-Z. Song, and T. Hospedales, “Learning to generalize: Meta-learning for domain generalization,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 32, no. 1, 2018
2018
-
[4]
Episodic training for domain generalization,
D. Li, J. Zhang, Y . Yang, C. Liu, Y .-Z. Song, and T. M. Hospedales, “Episodic training for domain generalization,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 1446–1455
2019
-
[5]
Domain generalization with mixstyle,
K. Zhou, Y . Yang, Y . Qiao, and T. Xiang, “Domain generalization with mixstyle,” inInternational Conference on Learning Representations, 2020
2020
-
[6]
Understanding hessian alignment for domain generalization,
S. Hemati, G. Zhang, A. Estiri, and X. Chen, “Understanding hessian alignment for domain generalization,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 19 004– 19 014
2023
-
[7]
Toward open set recognition,
W. J. Scheirer, A. de Rezende Rocha, A. Sapkota, and T. E. Boult, “Toward open set recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 7, pp. 1757–1772, 2012
2012
-
[8]
Clinical research for rare disease: opportunities, challenges, and solutions,
R. C. Griggs, M. Batshaw, M. Dunkle, R. Gopal-Srivastava, E. Kaye, J. Krischer, T. Nguyen, K. Paulus, P. A. Merkelet al., “Clinical research for rare disease: opportunities, challenges, and solutions,”Molecular genetics and metabolism, vol. 96, no. 1, pp. 20–26, 2009
2009
-
[9]
Open domain gener- alization with domain-augmented meta-learning,
Y . Shu, Z. Cao, C. Wang, J. Wang, and M. Long, “Open domain gener- alization with domain-augmented meta-learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9624–9633
2021
-
[10]
Open-set domain generalization via metric learning,
K. Katsumata, I. Kishida, A. Amma, and H. Nakayama, “Open-set domain generalization via metric learning,” in2021 IEEE International Conference on Image Processing, 2021, pp. 459–463
2021
-
[11]
Con- ditional variational capsule network for open set recognition,
Y . Guo, G. Camporese, W. Yang, A. Sperduti, and L. Ballan, “Con- ditional variational capsule network for open set recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 103–111
2021
-
[12]
Conditional gaussian distribution learning for open set recognition,
X. Sun, Z. Yang, C. Zhang, K.-V . Ling, and G. Peng, “Conditional gaussian distribution learning for open set recognition,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13 480–13 489
2020
-
[13]
Ovanet: One-vs-all network for universal domain adaptation,
K. Saito and K. Saenko, “Ovanet: One-vs-all network for universal domain adaptation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9000–9009
2021
-
[14]
Separate to adapt: Open set domain adaptation via progressive separation,
H. Liu, Z. Cao, M. Long, J. Wang, and Q. Yang, “Separate to adapt: Open set domain adaptation via progressive separation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2927–2936
2019
-
[15]
Meta- learning in neural networks: A survey,
T. Hospedales, A. Antoniou, P. Micaelli, and A. Storkey, “Meta- learning in neural networks: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 9, pp. 5149–5169, 2021
2021
-
[16]
Gradient matching for domain generalization,
Y . Shi, J. Seely, P. Torr, N. Siddharth, A. Hannun, N. Usunier, and G. Synnaeve, “Gradient matching for domain generalization,” in International Conference on Learning Representations, 2021
2021
-
[17]
Generalizable decision bound- aries: Dualistic meta-learning for open set domain generalization,
X. Wang, J. Zhang, L. Qi, and Y . Shi, “Generalizable decision bound- aries: Dualistic meta-learning for open set domain generalization,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 11 564–11 573
2023
-
[18]
On First-Order Meta-Learning Algorithms
A. Nichol, J. Achiam, and J. Schulman, “On first-order meta-learning algorithms,”arXiv preprint arXiv:1803.02999, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Domain generalization with adversarial feature learning,
H. Li, S. J. Pan, S. Wang, and A. C. Kot, “Domain generalization with adversarial feature learning,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 5400–5409
2018
-
[20]
Domain-adversarial training of neural networks,
Y . Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Lavio- lette, M. Marchand, and V . Lempitsky, “Domain-adversarial training of neural networks,”The Journal of Machine Learning Research, vol. 17, no. 1, pp. 2096–2030, 2016
2096
-
[21]
Domain adversarial neural networks for domain generalization: When it works and how to improve,
A. Sicilia, X. Zhao, and S. J. Hwang, “Domain adversarial neural networks for domain generalization: When it works and how to improve,”Machine Learning, pp. 1–37, 2023
2023
-
[22]
Domain adversarial active learning for domain generalization classification,
J. Chen, L. Ding, Y . Yang, Z. Di, and Y . Xiang, “Domain adversarial active learning for domain generalization classification,”IEEE Transac- tions on Knowledge and Data Engineering, vol. 37, no. 1, pp. 226–238, 2024
2024
-
[23]
Invariant risk minimization,
M. Arjovsky, L. Bottou, I. Gulrajani, and D. Lopez-Paz, “Invariant risk minimization,”Stat, vol. 1050, p. 27, 2020
2020
-
[24]
Invariance principle meets information bottleneck for out-of-distribution generalization,
K. Ahuja, E. Caballero, D. Zhang, J.-C. Gagnon-Audet, Y . Bengio, I. Mitliagkas, and I. Rish, “Invariance principle meets information bottleneck for out-of-distribution generalization,”Advances in Neural Information Processing Systems, vol. 34, pp. 3438–3450, 2021
2021
-
[25]
Learning to balance specificity and invariance for in and out of domain generalization,
P. Chattopadhyay, Y . Balaji, and J. Hoffman, “Learning to balance specificity and invariance for in and out of domain generalization,” in European Conference on Computer Vision, 2020, pp. 301–318
2020
-
[26]
Causality inspired representation learning for domain generalization,
F. Lv, J. Liang, S. Li, B. Zang, C. H. Liu, Z. Wang, and D. Liu, “Causality inspired representation learning for domain generalization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8046–8056
2022
-
[27]
Heterogeneous domain generalization via domain mixup,
Y . Wang, H. Li, and A. C. Kot, “Heterogeneous domain generalization via domain mixup,” inIEEE International Conference on Acoustics, Speech and Signal Processing, 2020, pp. 3622–3626
2020
-
[28]
A fourier- based framework for domain generalization,
Q. Xu, R. Zhang, Y . Zhang, Y . Wang, and Q. Tian, “A fourier- based framework for domain generalization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 383–14 392
2021
-
[29]
Aloft: A lightweight mlp-like architecture with dynamic low-frequency transform for domain gener- 15 alization,
J. Guo, N. Wang, L. Qi, and Y . Shi, “Aloft: A lightweight mlp-like architecture with dynamic low-frequency transform for domain gener- 15 alization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 24 132–24 141
2023
-
[30]
Progressive domain expansion network for single domain gen- eralization,
L. Li, K. Gao, J. Cao, Z. Huang, Y . Weng, X. Mi, Z. Yu, X. Li, and B. Xia, “Progressive domain expansion network for single domain gen- eralization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 224–233
2021
-
[31]
Learning to generate novel domains for domain generalization,
K. Zhou, Y . Yang, T. Hospedales, and T. Xiang, “Learning to generate novel domains for domain generalization,” inEuropean Conference on Computer Vision, 2020, pp. 561–578
2020
-
[32]
A simple feature augmentation for domain generalization,
P. Li, D. Li, W. Li, S. Gong, Y . Fu, and T. M. Hospedales, “A simple feature augmentation for domain generalization,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 8886–8895
2021
-
[33]
Feature-based style randomization for domain generalization,
Y . Wang, L. Qi, Y . Shi, and Y . Gao, “Feature-based style randomization for domain generalization,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 8, pp. 5495–5509, 2022
2022
-
[34]
Mvdg: A unified multi-view framework for domain generalization,
J. Zhang, L. Qi, Y . Shi, and Y . Gao, “Mvdg: A unified multi-view framework for domain generalization,” inEuropean Conference on Computer Vision, 2022, pp. 161–177
2022
-
[35]
Do- main generalization via model-agnostic learning of semantic features,
Q. Dou, D. Coelho de Castro, K. Kamnitsas, and B. Glocker, “Do- main generalization via model-agnostic learning of semantic features,” Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[36]
Metareg: Towards domain generalization using meta-regularization,
Y . Balaji, S. Sankaranarayanan, and R. Chellappa, “Metareg: Towards domain generalization using meta-regularization,”Advances in Neural Information Processing Systems, vol. 31, 2018
2018
-
[37]
Domain adaptive ensemble learning,
K. Zhou, Y . Yang, Y . Qiao, and T. Xiang, “Domain adaptive ensemble learning,”IEEE Transactions on Image Processing, vol. 30, pp. 8008– 8018, 2021
2021
-
[38]
Swad: Domain generalization by seeking flat minima,
J. Cha, S. Chun, K. Lee, H.-C. Cho, S. Park, Y . Lee, and S. Park, “Swad: Domain generalization by seeking flat minima,”Advances in Neural Information Processing Systems, vol. 34, pp. 22 405–22 418, 2021
2021
-
[39]
Ensemble of averages: Improving model selection and boosting performance in domain gener- alization,
D. Arpit, H. Wang, Y . Zhou, and C. Xiong, “Ensemble of averages: Improving model selection and boosting performance in domain gener- alization,”Advances in Neural Information Processing Systems, vol. 35, pp. 8265–8277, 2022
2022
-
[40]
Privacy-preserving con- strained domain generalization via gradient alignment,
C. X. Tian, H. Li, Y . Wang, and S. Wang, “Privacy-preserving con- strained domain generalization via gradient alignment,”IEEE Transac- tions on Knowledge and Data Engineering, vol. 36, no. 5, pp. 2142– 2150, 2023
2023
-
[41]
Self-challenging improves cross-domain generalization,
Z. Huang, H. Wang, E. P. Xing, and D. Huang, “Self-challenging improves cross-domain generalization,” inEuropean Conference on Computer Vision, 2020, pp. 124–140
2020
-
[42]
Domain generalization model of deep convolutional networks based on sand-mask,
J. Wang, L. Chen, and R. Wang, “Domain generalization model of deep convolutional networks based on sand-mask,”Algorithms, vol. 15, no. 6, p. 215, 2022
2022
-
[43]
Domain generalization via gradient surgery,
L. Mansilla, R. Echeveste, D. H. Milone, and E. Ferrante, “Domain generalization via gradient surgery,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6630–6638
2021
-
[44]
Deep visual domain adaptation: A survey,
M. Wang and W. Deng, “Deep visual domain adaptation: A survey,” Neurocomputing, vol. 312, pp. 135–153, 2018
2018
-
[45]
Recent advances in open set recognition: A survey,
C. Geng, S.-j. Huang, and S. Chen, “Recent advances in open set recognition: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 10, pp. 3614–3631, 2020
2020
-
[46]
Reducing network agnosto- phobia,
A. R. Dhamija, M. G ¨unther, and T. Boult, “Reducing network agnosto- phobia,”Advances in Neural Information Processing Systems, vol. 31, 2018
2018
-
[47]
Deep anomaly detec- tion with outlier exposure,
D. Hendrycks, M. Mazeika, and T. Dietterich, “Deep anomaly detec- tion with outlier exposure,” inInternational Conference on Learning Representations, 2018
2018
-
[48]
Generative openmax for multi-class open set classification,
Z. Ge, S. Demyanov, Z. Chen, and R. Garnavi, “Generative openmax for multi-class open set classification,” inBritish Machine Vision Conference 2017, 2017
2017
-
[49]
Open set learning with counterfactual images,
L. Neal, M. Olson, X. Fern, W.-K. Wong, and F. Li, “Open set learning with counterfactual images,” inProceedings of the European Conference on Computer Vision, 2018, pp. 613–628
2018
-
[50]
Opengan: Open-set recognition via open data generation,
S. Kong and D. Ramanan, “Opengan: Open-set recognition via open data generation,” inProceedings of the IEEE/CVF International Con- ference on Computer Vision, 2021, pp. 813–822
2021
-
[51]
Towards open set deep networks,
A. Bendale and T. E. Boult, “Towards open set deep networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 1563–1572
2016
-
[52]
Extreme value theory,
R. L. Smith, “Extreme value theory,”Handbook of Applicable Mathe- matics, vol. 7, pp. 437–471, 1990
1990
-
[53]
C2ae: Class conditioned auto-encoder for open-set recognition,
P. Oza and V . M. Patel, “C2ae: Class conditioned auto-encoder for open-set recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2307–2316
2019
-
[54]
Classification-reconstruction learning for open-set recognition,
R. Yoshihashi, W. Shao, R. Kawakami, S. You, M. Iida, and T. Nae- mura, “Classification-reconstruction learning for open-set recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4016–4025
2019
-
[55]
Spectral-spatial latent reconstruction for open-set hyperspectral image classification,
J. Yue, L. Fang, and M. He, “Spectral-spatial latent reconstruction for open-set hyperspectral image classification,”IEEE Transactions on Image Processing, vol. 31, pp. 5227–5241, 2022
2022
-
[56]
Adversarial reciprocal points learning for open set recognition,
G. Chen, P. Peng, X. Wang, and Y . Tian, “Adversarial reciprocal points learning for open set recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
2021
-
[57]
Pmal: Open set recognition via robust prototype mining,
J. Lu, Y . Xu, H. Li, Z. Cheng, and Y . Niu, “Pmal: Open set recognition via robust prototype mining,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 2, 2022, pp. 1872–1880
2022
-
[58]
Thrun and L
S. Thrun and L. Pratt,Learning to learn. Springer Science & Business Media, 2012
2012
-
[59]
On data efficiency of meta-learning,
M. Al-Shedivat, L. Li, E. Xing, and A. Talwalkar, “On data efficiency of meta-learning,” inInternational Conference on Artificial Intelligence and Statistics. PMLR, 2021, pp. 1369–1377
2021
-
[60]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inInternational Conference on Machine Learning. PMLR, 2017, pp. 1126–1135
2017
-
[61]
One ring to bring them all: Towards open-set recognition under domain shift,
S. Yang, Y . Wang, K. Wang, S. Jui, and J. van de Weijer, “One ring to bring them all: Towards open-set recognition under domain shift,” ArXiv Preprint ArXiv:2206.03600, 2022
-
[62]
Activate and reject: Towards safe domain generalization under cate- gory shift,
C. Chen, L. Tang, L. Tao, H.-Y . Zhou, Y . Huang, X. Han, and Y . Yu, “Activate and reject: Towards safe domain generalization under cate- gory shift,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 11 552–11 563
2023
-
[63]
Crossmatch: Cross-classifier consistency regular- ization for open-set single domain generalization,
R. Zhu and S. Li, “Crossmatch: Cross-classifier consistency regular- ization for open-set single domain generalization,” inInternational Conference on Learning Representations, 2021
2021
-
[64]
Unknown prompt the only lacuna: Unveiling clip’s potential for open domain generalization,
M. Singha, A. Jha, S. Bose, A. Nair, M. Abdar, and B. Banerjee, “Unknown prompt the only lacuna: Unveiling clip’s potential for open domain generalization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 309–13 319
2024
-
[65]
Meta- learning to teach semantic prompts for open domain generalization in vision-language models,
S. Bose, M. Singha, A. Jha, S. Mukhopadhyay, and B. Banerjee, “Meta- learning to teach semantic prompts for open domain generalization in vision-language models,”Transactions on Machine Learning Research, 2025
2025
-
[66]
Osloprompt: Bridging low-supervision challenges and open-set domain generalization in clip,
D. Gupta, M. Singha, S. B. Rongali, A. Jha, M. H. Khan, B. Banerjee et al., “Osloprompt: Bridging low-supervision challenges and open-set domain generalization in clip,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 10 110–10 120
2025
-
[67]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[68]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[70]
Learning to transport for open set domain generalization,
C. Li, S. Wang, Y . Long, and H. Zhang, “Learning to transport for open set domain generalization,”Pattern Recognition, p. 112988, 2025
2025
-
[71]
Advancing open-set domain gener- alization using evidential bi-level hardest domain scheduler,
K. Peng, D. Wen, K. Yang, A. Luo, Y . Chen, J. Fu, M. S. Sarfraz, A. Roitberg, and R. Stiefelhagen, “Advancing open-set domain gener- alization using evidential bi-level hardest domain scheduler,”Advances in Neural Information Processing Systems, vol. 37, pp. 85 412–85 440, 2024
2024
-
[72]
Mitigating label noise using prompt-based hyperbolic meta-learning in open-set domain generalization,
K. Peng, D. Wen, M. S. Sarfraz, Y . Chen, J. Zheng, D. Schneider, K. Yang, J. Wu, A. Roitberg, and R. Stiefelhagen, “Mitigating label noise using prompt-based hyperbolic meta-learning in open-set domain generalization,”International Journal of Computer Vision, vol. 134, no. 3, p. 99, 2026
2026
-
[73]
An overview of gradient descent optimization algorithms
S. Ruder, “An overview of gradient descent optimization algorithms,” arXiv preprint arXiv:1609.04747, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[74]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang, “On large-batch training for deep learning: Generalization gap and sharp minima,”arXiv preprint arXiv:1609.04836, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[75]
Neural networks for machine learning lecture 6a overview of mini-batch gradient descent,
G. Hinton, N. Srivastava, and K. Swersky, “Neural networks for machine learning lecture 6a overview of mini-batch gradient descent,” Cited on, vol. 14, no. 8, p. 2, 2012
2012
-
[76]
Three Factors Influencing Minima in SGD
S. Jastrzkebski, Z. Kenton, D. Arpit, N. Ballas, A. Fischer, Y . Bengio, and A. Storkey, “Three factors influencing minima in sgd,”arXiv preprint arXiv:1711.04623, 2017. 16
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[77]
Adaptive task sampling for meta-learning,
C. Liu, Z. Wang, D. Sahoo, Y . Fang, K. Zhang, and S. C. Hoi, “Adaptive task sampling for meta-learning,” inProceedings of the European Conference on Computer Vision (ECCV), 2020, pp. 752–769
2020
-
[78]
Sequential reptile: inter- task gradient alignment for multilingual learning,
S. Lee, H. B. Lee, J. Lee, and S. J. Hwang, “Sequential reptile: inter- task gradient alignment for multilingual learning,” inTenth Interna- tional Conference on Learning Representations, 2022
2022
-
[79]
Statistical learning theory,
V . V . Naumovich and V . Vlamimir, “Statistical learning theory,” 1998
1998
-
[80]
Deeper, broader and artier domain generalization,
D. Li, Y . Yang, Y .-Z. Song, and T. M. Hospedales, “Deeper, broader and artier domain generalization,” inProceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5542–5550
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.