Characterizing initial human-AI proof formalization workflows
Pith reviewed 2026-06-28 09:28 UTC · model grok-4.3
The pith
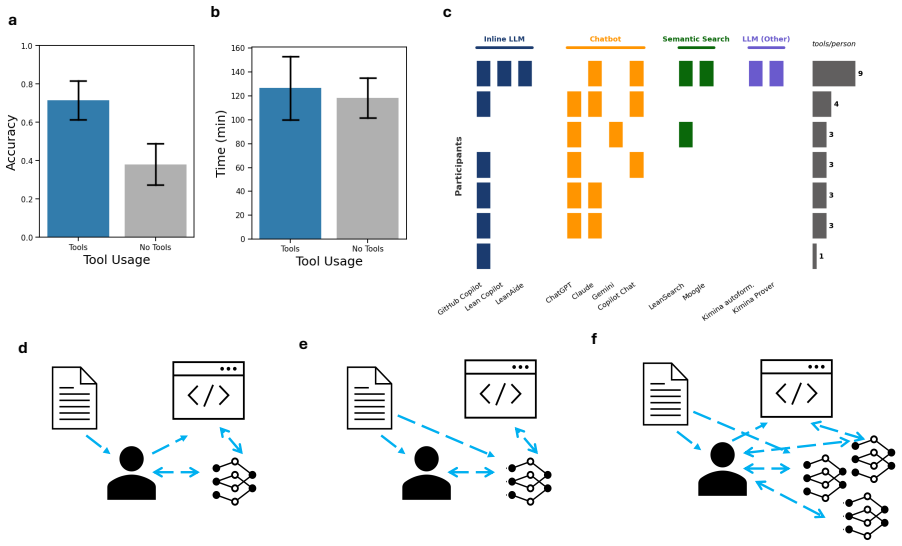
Participants achieve higher accuracy formalizing math proofs with AI tool access than without it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
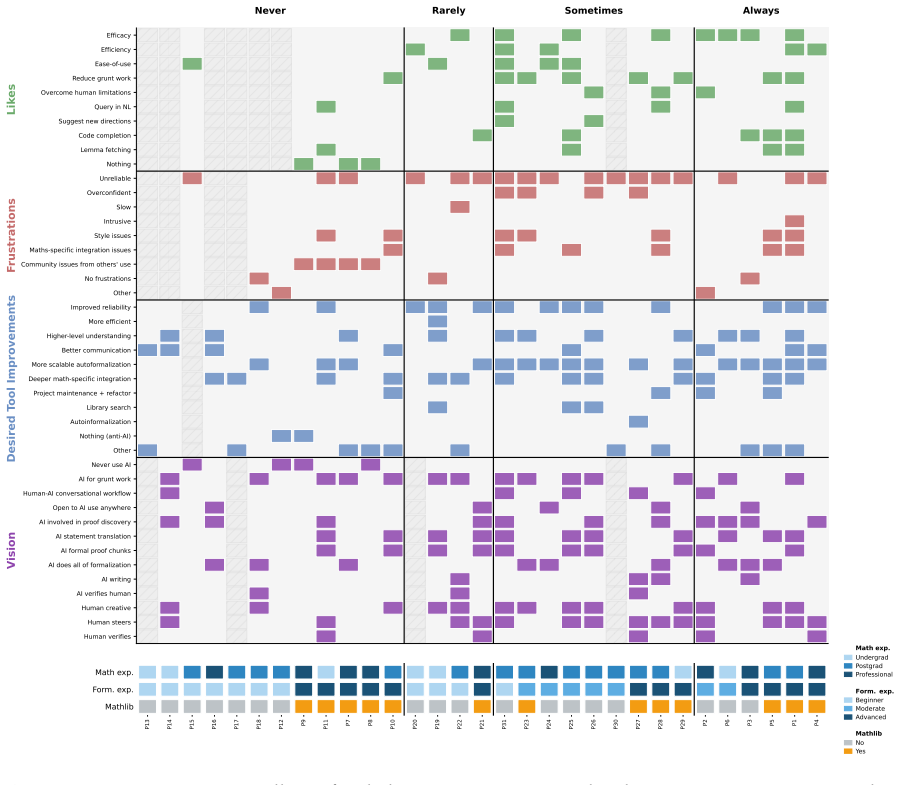
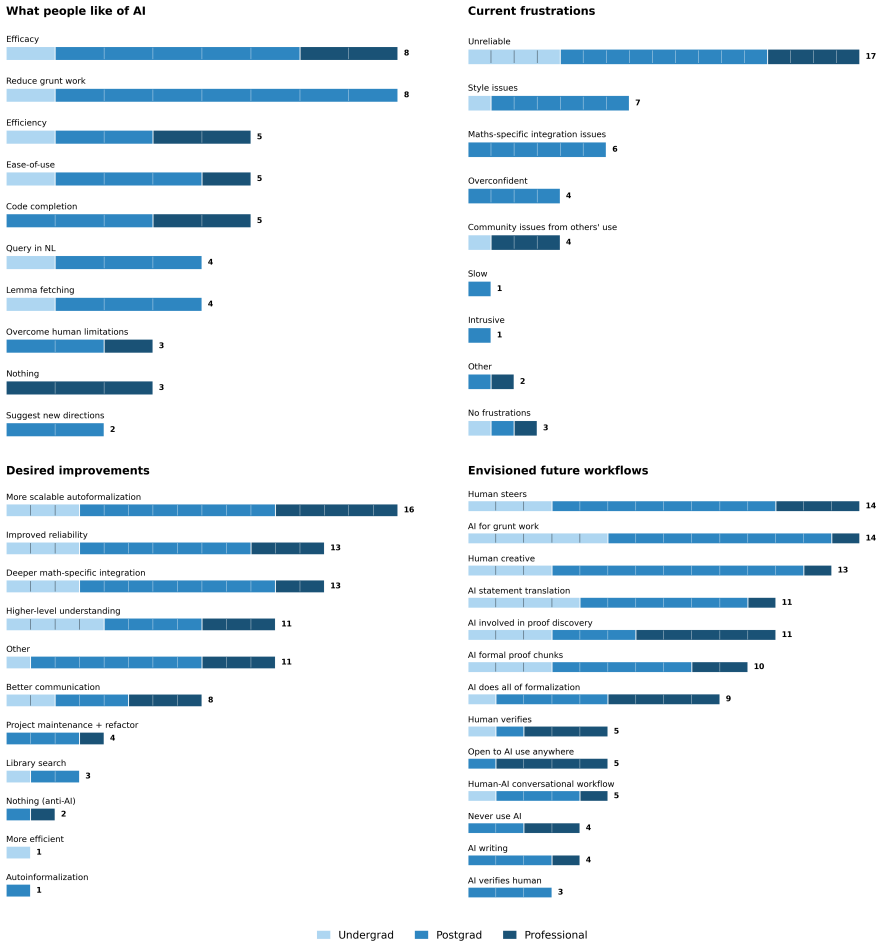
A qualitative survey shows diverse user preferences centered on AI assistance that preserves high-level human control over proof discovery. In the accompanying controlled user study, participants formalizing informal math problems and proofs attained higher accuracy with access to AI tools than when working alone, even though the tools had known autoformalization limits at the time; most participants chose to use multiple different AI tools in flexible combinations.
What carries the argument
The mixed-methods design that pairs a preference survey with a controlled user study comparing AI-assisted versus unaided formalization accuracy across mathematical domains and difficulty levels.
If this is right
- AI tools can raise formalization accuracy even before they reach full autoformalization capability.
- Users adapt workflows by combining several AI tools rather than relying on one.
- Desired AI support keeps humans directing the high-level proof structure.
- Early AI integration in formalization already shows close human-AI alternation rather than full replacement.
Where Pith is reading between the lines
- Interfaces that make switching among tools seamless may improve adoption more than single-tool optimization.
- The accuracy benefit could compound as AI reasoning improves, altering how formal verification is taught or practiced.
- Similar mixed human-AI patterns may appear in related tasks such as code verification or hardware specification.
- Survey preferences for retained human control suggest design targets for future tools that avoid over-automation.
Load-bearing premise
The AI-assisted and unaided study conditions are comparable without hidden differences in task setup or participant effort, and self-reported tool choices match what participants actually did.
What would settle it
A follow-up experiment that logs actual tool usage and finds no accuracy gain (or a loss) in the AI-access condition, or that shows reported multi-tool usage does not match recorded behavior.
Figures









read the original abstract
For centuries, human mathematicians have written proofs to substantiate their mathematical arguments; yet, the ability to automatically verify the validity of proofs has long been a challenge. Advances in AI systems' ability to generate code and engage in increasingly high-level mathematical reasoning promise to transform people's ability to formalize and thereby verify proofs. While many works focus on benchmarking the current frontier, we instead study how people use these tools. We conduct a mixed-methods analysis into the initial impact of AI on people's formalization workflows: what people claim they want, what they see as the barriers to those visions, and how they actually use and adapt AI in practice. A qualitative survey shows that people's preferences are diverse, but with a general desire for AI assistance in formalization that preserves high-level human control over the proof discovery process. To assess how people actually engage with AI for formalization under such limitations, we conduct a controlled user study in which participants formalize informal math problems and their proofs, with and without AI, across a range of mathematical problems at varying levels of difficulty and domains. Despite limitations of the tools at the time for autoformalization, participants tend to attain higher formalization accuracy when allowed access to AI tools than when formalizing on their own, with most participants flexibly choosing to use multiple different AI tools. Taken together, our work sheds light on the early stages of AI integration into formalization workflows, involving an intimate interplay of human and AI engagement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a mixed-methods investigation into how humans use AI tools for formalizing mathematical proofs. It reports results from a qualitative survey on desired AI assistance features and a controlled within-subjects user study comparing formalization accuracy on informal math problems with and without access to AI tools. The central empirical claim is that participants achieve higher formalization accuracy when using AI tools, with most opting to use multiple tools in a flexible manner.
Significance. Should the findings prove robust, the work offers timely empirical insights into the nascent integration of AI into mathematical formalization practices. It underscores the preference for AI that supports rather than replaces human proof discovery and documents practical usage patterns despite current tool limitations. This contributes to the growing literature on human-AI collaboration in formal methods and can inform the design of more effective proof assistants.
minor comments (3)
- [Abstract] Abstract: the claim of 'higher formalization accuracy' would benefit from a brief parenthetical note on how accuracy was operationalized (e.g., Lean compilation success plus human review) to allow readers to gauge the strength of the directional result without consulting the methods section.
- [User study] User study section: while counterbalancing and logged usage are noted, a short table summarizing per-participant tool combinations and accuracy deltas would make the 'flexibly choosing multiple tools' observation more concrete and easier to verify.
- [Discussion] Discussion: the limitations paragraph could explicitly address the within-subjects design's potential carry-over effects and the modest number of problems per domain, even if these do not undermine the main directional finding.
Simulated Author's Rebuttal
We thank the referee for their positive summary and significance assessment, as well as the recommendation for minor revision. We appreciate the recognition that the work provides timely empirical insights into human-AI collaboration for mathematical formalization.
Circularity Check
Empirical user study; no derivation chain or circular steps present
full rationale
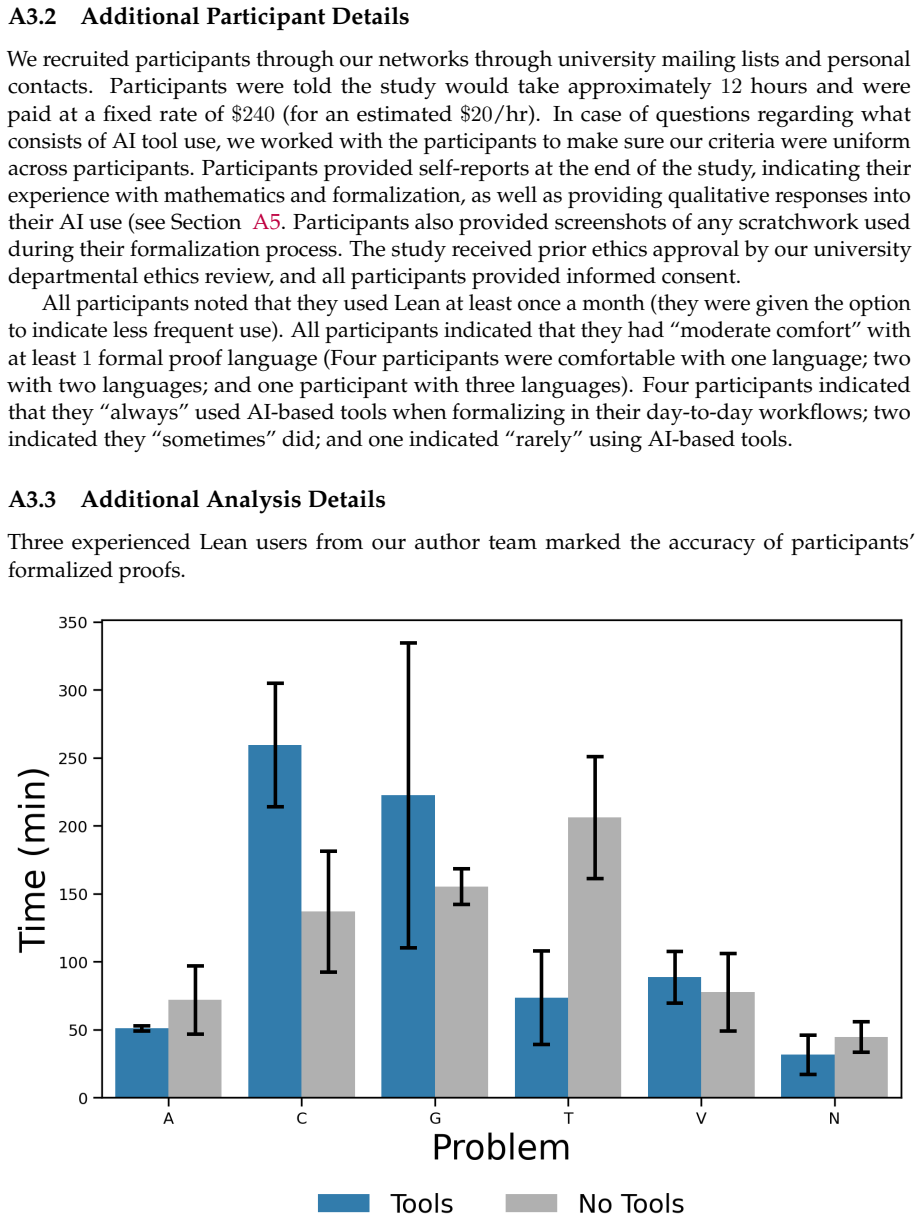
The paper reports results from a qualitative survey and a controlled within-subjects user study measuring formalization accuracy with/without AI tools. Central claims rest on direct empirical observations (accuracy scores via Lean compilation and human review, logged tool usage) rather than any first-principles derivation, fitted parameters renamed as predictions, or self-citation chains. No equations, uniqueness theorems, or ansatzes appear; the work is self-contained against external benchmarks of participant performance and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bulletin of the American Mathematical Society , year =
Commelin, Johan and Topaz, Adam , title =. Bulletin of the American Mathematical Society , year =
-
[2]
arXiv preprint arXiv:2510.09801 , year=
How can we assess human-agent interactions? Case studies in software agent design , author=. arXiv preprint arXiv:2510.09801 , year=
-
[3]
Luoxin Chen and Jinming Gu and Liankai Huang and Wenhao Huang and Zhicheng Jiang and Allan Jie and Xiaoran Jin and Xing Jin and Chenggang Li and Kaijing Ma and Cheng Ren and Jiawei Shen and Wenlei Shi and Tong Sun and He Sun and Jiahui Wang and Siran Wang and Zhihong Wang and Chenrui Wei and Shufa Wei and Yonghui Wu and Yuchen Wu and Yihang Xia and Huajia...
-
[4]
Current Directions in Psychological Science , pages=
Meaningful Long-Term Thought Partnerships of Minds and Machines , author=. Current Directions in Psychological Science , pages=
-
[5]
2026 , eprint=
On Talagrand's Convexity Conjecture , author=. 2026 , eprint=
2026
-
[6]
For the learning of mathematics , volume=
On proof and progress in mathematics , author=. For the learning of mathematics , volume=. 1995 , publisher=
1995
-
[7]
2025 , month = July, note =
Advanced version of. 2025 , month = July, note =
2025
-
[8]
arXiv preprint arXiv:2110.14168 , year =
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =. 2110.14168 , archivePrefix =
-
[9]
2025 , month = feb, howpublished =
Claude 3.7. 2025 , month = feb, howpublished =
2025
-
[10]
2025 , month = may, howpublished =
Introducing. 2025 , month = may, howpublished =
2025
-
[12]
Communications of the ACM , volume=
Formal Reasoning Meets LLMs: Toward AI for Mathematics and Verification , author=. Communications of the ACM , volume=. 2026 , publisher=
2026
-
[13]
Proceedings of the National Academy of Sciences , volume=
Rapid trial-and-error learning with simulation supports flexible tool use and physical reasoning , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
2020
-
[14]
Documenting Deployment with Fabric: A Repository of Real-World
Jorgensen, Mackenzie and Brogle, Kendall and Collins, Katherine M and Ibrahim, Lujain and Shah, Arina and Ivanovic, Petra and Broestl, Noah and Piles, Gabriel and Dongha, Paul and Abdulhussein, Hatim and others , journal=. Documenting Deployment with Fabric: A Repository of Real-World
-
[15]
Yang, Kaiyu and Swope, Aidan and Gu, Alex and Chalamala, Rahul and Song, Peiyang and Yu, Shixing and Godil, Saad and Prenger, Ryan J and Anandkumar, Animashree , booktitle =
-
[16]
Z. Z. Ren and Zhihong Shao and Junxiao Song and Huajian Xin and Haocheng Wang and Wanjia Zhao and Liyue Zhang and Zhe Fu and Qihao Zhu and Dejian Yang and Z. F. Wu and Zhibin Gou and Shirong Ma and Hongxuan Tang and Yuxuan Liu and Wenjun Gao and Daya Guo and Chong Ruan , year=. 2504.21801 , archivePrefix=
-
[17]
arXiv preprint arXiv:2605.06651 , year=
AI Co-Mathematician: Accelerating Mathematicians with Agentic AI , author=. arXiv preprint arXiv:2605.06651 , year=
-
[18]
Interactive Theorem Proving-Modelling the User in the Proof Process , author=
-
[19]
Design, Specification and Verification of Interactive Systems’ 96: Proceedings of the Eurographics Workshop in Namur, Belgium, June 5--7, 1996 , pages=
Evaluating the interfaces of three theorem proving assistants , author=. Design, Specification and Verification of Interactive Systems’ 96: Proceedings of the Eurographics Workshop in Namur, Belgium, June 5--7, 1996 , pages=. 1996 , organization=
1996
-
[20]
J.S. Aitken and P. Gray and T. Melham and M. Thomas , abstract =. Interactive Theorem Proving: An Empirical Study of User Activity , journal =. 1998 , issn =. doi:https://doi.org/10.1006/jsco.1997.0175 , url =
-
[21]
Proceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
Are NLP models really able to solve simple math word problems? , author=. Proceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
2021
-
[22]
Nature , pages=
Olympiad-level formal mathematical reasoning with reinforcement learning , author=. Nature , pages=. 2025 , publisher=
2025
-
[23]
Nature , volume=
Mathematical discoveries from program search with large language models , author=. Nature , volume=. 2024 , publisher=
2024
-
[24]
arXiv preprint arXiv:2503.11061 , year=
Generative modeling for mathematical discovery , author=. arXiv preprint arXiv:2503.11061 , year=
-
[25]
Lessons for interactive theorem proving researchers from a survey of
de Almeida Borges, Ana and Casanueva Art. Lessons for interactive theorem proving researchers from a survey of. Journal of Automated Reasoning , volume=. 2025 , publisher=
2025
-
[26]
Proceedings of the 2nd International Workshop on User Interface Design for Theorem Proving Systems , pages=
Two modelling approaches applied to user interfaces to theorem proving assistants , author=. Proceedings of the 2nd International Workshop on User Interface Design for Theorem Proving Systems , pages=
-
[27]
12th Workshop of the Psychology of Programming Interest Group (PPIG) , pages=
A Cognitive Dimensions view of the differences between designers and users of theorem proving assistants , author=. 12th Workshop of the Psychology of Programming Interest Group (PPIG) , pages=
-
[28]
Communications Psychology , volume=
Effortful leisure is a source of meaning in everyday life , author=. Communications Psychology , volume=. 2025 , publisher=
2025
-
[29]
Trends in cognitive sciences , volume=
The effort paradox: Effort is both costly and valued , author=. Trends in cognitive sciences , volume=. 2018 , publisher=
2018
-
[30]
Calibrating Histopathology Image Classifiers using Label Smoothing , publisher =
Wei, Jerry and Torresani, Lorenzo and Wei, Jason and Hassanpour, Saeed , keywords =. Calibrating Histopathology Image Classifiers using Label Smoothing , publisher =. 2022 , copyright =. doi:10.48550/ARXIV.2201.11866 , url =
-
[31]
International Statistical Review , volume =
Fortuin, Vincent , title =. International Statistical Review , volume =. doi:https://doi.org/10.1111/insr.12502 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/insr.12502 , abstract =
-
[32]
Welleck, Sean and Liu, Jiacheng and Lu, Ximing and Hajishirzi, Hannaneh and Choi, Yejin , keywords =. 2022 , copyright =. doi:10.48550/ARXIV.2205.12910 , url =
-
[33]
arXiv preprint arXiv:2403.04814 , year=
Evaluation of LLMs on Syntax-Aware Code Fill-in-the-Middle Tasks , author=. arXiv preprint arXiv:2403.04814 , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
International conference on machine learning , pages=
Do imagenet classifiers generalize to imagenet? , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[36]
arXiv preprint arXiv:2403.04132 , year=
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference , author=. arXiv preprint arXiv:2403.04132 , year=
-
[37]
Simulating Iterative Human-
Mozannar, Hussein and Chen, Valerie and Wei, Dennis and Sattigeri, Prasanna and Nagireddy, Manish and Das, Subhro and Talwalkar, Ameet and Sontag, David , booktitle=. Simulating Iterative Human-
-
[38]
IEEE Transactions on Software Engineering , year=
MultiPL-E: a scalable and polyglot approach to benchmarking neural code generation , author=. IEEE Transactions on Software Engineering , year=
-
[39]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[40]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Large language models meet NL2Code: A survey , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[41]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Aligning Offline Metrics and Human Judgments of Value for Code Generation Models , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[42]
arXiv preprint arXiv:2303.03004 , year=
xcodeeval: A large scale multilingual multitask benchmark for code understanding, generation, translation and retrieval , author=. arXiv preprint arXiv:2303.03004 , year=
-
[43]
Vera and Wortman Vaughan, Jennifer , title =
Vasconcelos, Helena and Bansal, Gagan and Fourney, Adam and Liao, Q. Vera and Wortman Vaughan, Jennifer , title =. ACM Trans. Comput.-Hum. Interact. , month = apr, articleno =. 2025 , issue_date =. doi:10.1145/3702320 , abstract =
- [44]
-
[45]
arXiv preprint arXiv:2311.08588 , year=
Codescope: An execution-based multilingual multitask multidimensional benchmark for evaluating llms on code understanding and generation , author=. arXiv preprint arXiv:2311.08588 , year=
-
[46]
Shuai Lu and Daya Guo and Shuo Ren and Junjie Huang and Alexey Svyatkovskiy and Ambrosio Blanco and Colin Clement and Dawn Drain and Daxin Jiang and Duyu Tang and Ge Li and Lidong Zhou and Linjun Shou and Long Zhou and Michele Tufano and MING GONG and Ming Zhou and Nan Duan and Neel Sundaresan and Shao Kun Deng and Shengyu Fu and Shujie LIU , booktitle=. ...
2021
-
[47]
Queue , volume=
Taking Flight with Copilot: Early insights and opportunities of AI-powered pair-programming tools , author=. Queue , volume=. 2022 , publisher=
2022
-
[48]
IEEE Transactions on Software Engineering , volume=
Automatically assessing code understandability , author=. IEEE Transactions on Software Engineering , volume=. 2019 , publisher=
2019
-
[49]
Transactions on Machine Learning Research , issn=
Evaluating Human-Language Model Interaction , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[50]
arXiv preprint arXiv:2306.01694 , year=
Evaluating language models for mathematics through interactions , author=. arXiv preprint arXiv:2306.01694 , year=
-
[51]
Human-AI pAIr Programming , author=
Is AI the better programming partner? Human-Human Pair Programming vs. Human-AI pAIr Programming , author=. arXiv preprint arXiv:2306.05153 , year=
-
[52]
arXiv preprint arXiv:2309.03914 , year=
DevGPT: Studying Developer-ChatGPT Conversations , author=. arXiv preprint arXiv:2309.03914 , year=
-
[53]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
ReCode: Robustness Evaluation of Code Generation Models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[54]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Python Code Generation by Asking Clarification Questions , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[55]
The impact of
Peng, Sida and Kalliamvakou, Eirini and Cihon, Peter and Demirer, Mert , journal=. The impact of
-
[56]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[57]
arXiv preprint arXiv:2410.21276 , year =
GPT-4o System Card , author =. arXiv preprint arXiv:2410.21276 , year =
-
[58]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Language Models of Code are Few-Shot Commonsense Learners , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[59]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[60]
The Twelfth International Conference on Learning Representations , year=
OctoPack: Instruction Tuning Code Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[61]
ICLR , year=
SWE-bench: Can Language Models Resolve Real-world Github Issues? , author=. ICLR , year=
-
[62]
Advances in Neural Information Processing Systems , volume=
Large language models of code fail at completing code with potential bugs , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
arXiv preprint arXiv:2401.03065 , year=
Cruxeval: A benchmark for code reasoning, understanding and execution , author=. arXiv preprint arXiv:2401.03065 , year=
-
[64]
arXiv preprint arXiv:2308.10620 , year=
Large language models for software engineering: A systematic literature review , author=. arXiv preprint arXiv:2308.10620 , year=
-
[65]
ChatGPT: Introducing ChatGPT , author=
-
[66]
Available at SSRN 4375283 , year=
Experimental evidence on the productivity effects of generative artificial intelligence , author=. Available at SSRN 4375283 , year=
-
[67]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[68]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Contrastive Code Representation Learning , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[69]
Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=
CodeBERT: A Pre-Trained Model for Programming and Natural Languages , author=. Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=
2020
-
[70]
arXiv preprint arXiv:2303.10130 , year=
Gpts are gpts: An early look at the labor market impact potential of large language models , author=. arXiv preprint arXiv:2303.10130 , year=
-
[71]
arXiv preprint arXiv:2301.08653 , year=
An analysis of the automatic bug fixing performance of chatgpt , author=. arXiv preprint arXiv:2301.08653 , year=
-
[72]
arXiv preprint arXiv:2311.05584 , year=
Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations , author=. arXiv preprint arXiv:2311.05584 , year=
-
[73]
2023 , institution=
Generative AI at work , author=. 2023 , institution=
2023
-
[74]
International archives of occupational and environmental health , volume=
A systematic review on the effect of work-related stressors on mental health of young workers , author=. International archives of occupational and environmental health , volume=. 2020 , publisher=
2020
-
[75]
SAGE Open , volume=
Examining the Impact of Technology Overload at the Workplace: A Systematic Review , author=. SAGE Open , volume=. 2022 , publisher=
2022
-
[76]
International Journal of Environmental Research and Public Health , volume=
Technostress dark side of technology in the workplace: A scientometric analysis , author=. International Journal of Environmental Research and Public Health , volume=. 2020 , publisher=
2020
-
[77]
IEEE MultiMedia , volume=
Automating the recognition of stress and emotion: From lab to real-world impact , author=. IEEE MultiMedia , volume=. 2016 , publisher=
2016
-
[78]
Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems , pages=
Cogcam: Contact-free measurement of cognitive stress during computer tasks with a digital camera , author=. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems , pages=
2016
-
[79]
2014 36th annual international conference of the IEEE engineering in medicine and biology society , pages=
Remote measurement of cognitive stress via heart rate variability , author=. 2014 36th annual international conference of the IEEE engineering in medicine and biology society , pages=. 2014 , organization=
2014
-
[80]
IEEE Transactions on intelligent transportation systems , volume=
Detecting stress during real-world driving tasks using physiological sensors , author=. IEEE Transactions on intelligent transportation systems , volume=. 2005 , publisher=
2005
-
[81]
Engineering Reports , volume=
Text-based emotion detection: Advances, challenges, and opportunities , author=. Engineering Reports , volume=. 2020 , publisher=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.