PSEBench: A Controllable and Verifiable Benchmark for Evaluating LLMs in Patient Safety Event Triage
Pith reviewed 2026-06-28 05:47 UTC · model grok-4.3
The pith
Clause cards from regulatory text let researchers build a 5,074-case benchmark with built-in ground truth for testing LLMs on patient safety event triage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A policy-grounded construction methodology centered on the clause card, a structured representation that factorizes regulatory text into auditable decision specifications, combined with anchor-driven instantiation and closed-loop verification, produces narratives with by-construction ground truth and naturally supports generating missing information and uncertain variants, instantiated on Minnesota's 29 Reportable Adverse Health Events to yield PSEBench.
What carries the argument
The clause card, a structured representation that factorizes regulatory text into auditable decision specifications, which carries the argument by turning policy into explicit, machine-checkable decision rules.
If this is right
- LLMs can be evaluated on proactive information seeking for incomplete reports within the same controlled setting.
- The pipeline supports controlled generation of uncertain variants to test abstention behavior.
- Consistent capability trends across models become visible through repeated, verifiable runs.
- Actionable gaps in reliable LLM-based triage are identified for targeted improvement.
- The same method scales to other regulatory domains that require auditable decision specifications.
Where Pith is reading between the lines
- The clause-card approach could be adapted to non-healthcare regulatory compliance tasks such as financial reporting or environmental permitting.
- Integration with live hospital reporting systems would allow direct comparison of LLM triage against current manual workflows.
- The benchmark's agentic environment could be extended to measure how model performance changes when additional context or clarification requests are allowed.
- Generated cases could serve as training data for fine-tuning models on policy-grounded reasoning before deployment.
Load-bearing premise
The clause card accurately captures the policy reasoning needed for triage decisions.
What would settle it
A sample of generated cases reviewed by practicing patient safety experts shows systematic disagreement with the labels assigned by the clause-card pipeline.
Figures



read the original abstract
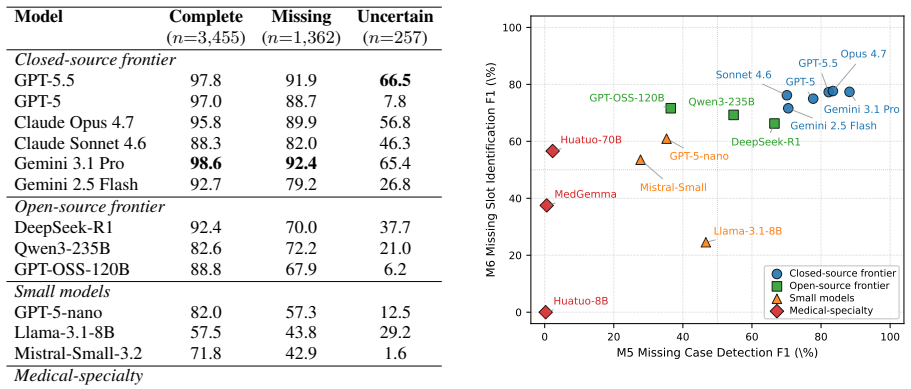
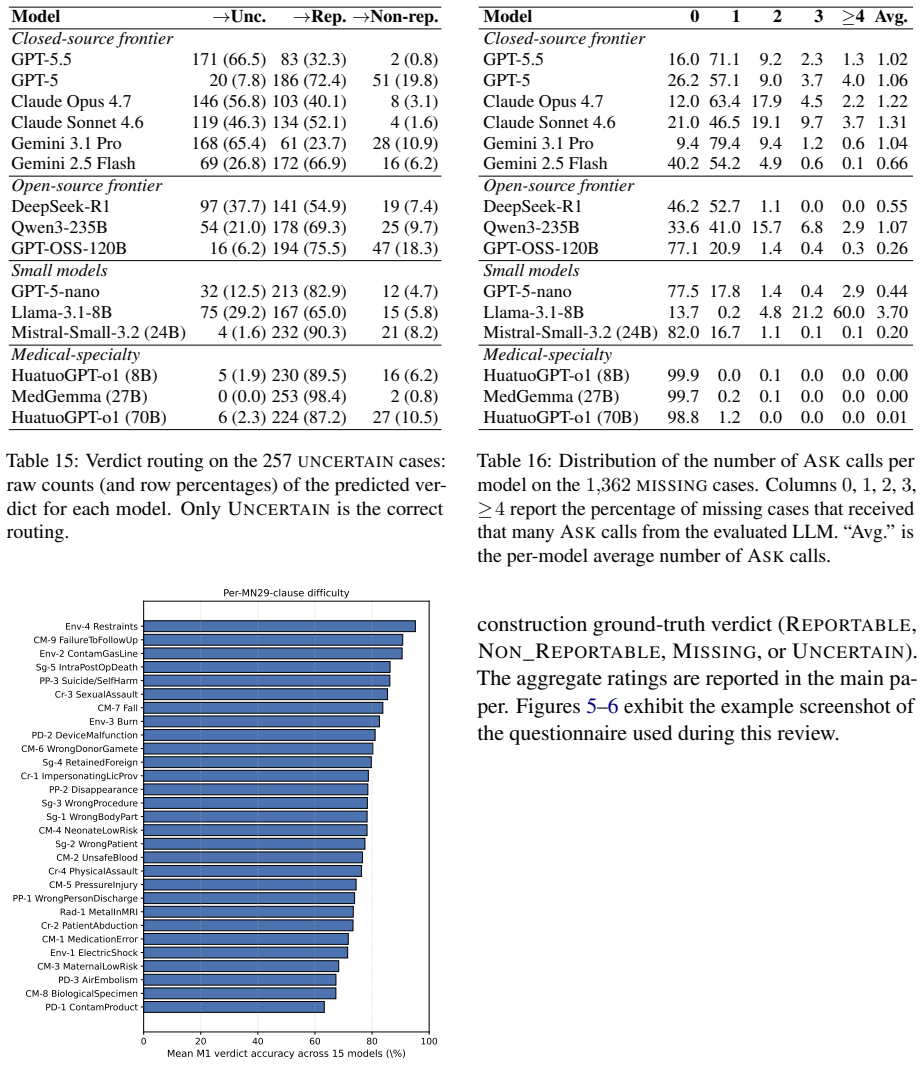
Patient safety event triage, determining whether a clinical event is reportable under jurisdiction-specific policy, is a high-stakes task typically performed manually by patient safety experts. Although LLMs may support this workflow, reliable evaluation is limited by the lack of benchmarks to capture evidence-grounded policy reasoning, proactive information seeking for incomplete reports, and principled abstention in irreducibly ambiguous cases. We address this gap with a policy-grounded construction methodology centered on the clause card, a structured representation that factorizes regulatory text into auditable decision specifications. Combining clause cards with anchor-driven instantiation and closed-loop verification, our scalable pipeline produces narratives with by-construction ground truth and naturally supports generating missing information and uncertain variants. We instantiate this method on Minnesota's 29 Reportable Adverse Health Events, producing PSEBench, a 5,074-case benchmark with an agentic evaluation environment. Evaluation on 15 representative LLMs reveals consistent capability trends, demonstrates the benchmark's utility, and identifies actionable gaps toward reliable LLM-based patient safety event triage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PSEBench, a 5,074-case benchmark for evaluating LLMs on patient safety event triage. It centers on clause cards as a structured factorization of regulatory text (Minnesota's 29 Reportable Adverse Health Events) into auditable decision specifications, combined with anchor-driven instantiation and closed-loop verification to generate narratives that carry by-construction ground truth. The pipeline supports generation of missing-information and uncertain variants, and an agentic evaluation environment is used to assess 15 LLMs, revealing capability trends and gaps in evidence-grounded reasoning, proactive information seeking, and principled abstention.
Significance. If the clause-card representations are faithful, the work supplies a scalable, policy-grounded benchmark with verifiable labels for a high-stakes domain where existing evaluations lack controllability and ground-truth guarantees. The explicit support for uncertain variants and the agentic setup are concrete strengths that could enable reproducible assessment of LLM reliability in regulatory triage tasks.
major comments (2)
- [Methodology (clause card construction)] Clause-card construction (methodology section): No expert validation, inter-rater reliability, or coverage audit against the original regulatory text is reported. Because the 'by-construction ground truth' for all 5,074 cases rests on the factorization correctly preserving logical interactions, exceptions, and jurisdiction-specific interpretations, the absence of such validation is load-bearing for the central claim.
- [Pipeline and verification] Closed-loop verification step (pipeline description): The manuscript does not specify the verification criteria, failure modes, or quantitative checks used to confirm that generated narratives match the clause-card specifications. Without these details the reproducibility of the ground-truth labels cannot be assessed.
minor comments (2)
- Add a concrete worked example of a clause card, its anchor-driven instantiation, and the resulting narrative early in the paper to clarify the factorization process.
- Table or figure reporting the distribution of case types (complete, missing-information, uncertain) across the 5,074 instances would improve transparency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional methodological transparency would strengthen the paper. We address each major comment below and commit to revisions that directly respond to the concerns about validation and reproducibility.
read point-by-point responses
-
Referee: [Methodology (clause card construction)] Clause-card construction (methodology section): No expert validation, inter-rater reliability, or coverage audit against the original regulatory text is reported. Because the 'by-construction ground truth' for all 5,074 cases rests on the factorization correctly preserving logical interactions, exceptions, and jurisdiction-specific interpretations, the absence of such validation is load-bearing for the central claim.
Authors: We agree that the absence of reported expert validation and coverage audit is a limitation for claims resting on faithful factorization. The clause cards were derived through direct, iterative mapping from the Minnesota regulatory text by authors with patient-safety domain knowledge, with explicit attention to preserving exceptions and logical structure. However, the manuscript does not include formal inter-rater reliability metrics or an external audit. In revision we will add a new subsection that (1) presents a coverage audit mapping each of the 29 events to its clause cards, (2) provides concrete examples of how interactions and exceptions are encoded, and (3) explicitly states the limitation and the authors' expertise. This increases transparency without altering the by-construction claim. revision: yes
-
Referee: [Pipeline and verification] Closed-loop verification step (pipeline description): The manuscript does not specify the verification criteria, failure modes, or quantitative checks used to confirm that generated narratives match the clause-card specifications. Without these details the reproducibility of the ground-truth labels cannot be assessed.
Authors: We acknowledge that the closed-loop verification description is currently high-level and lacks the requested operational details. The process combines automated clause-element matching with sampled manual review, but the manuscript does not enumerate criteria, failure modes, or pass-rate statistics. In the revised manuscript we will expand the pipeline section to specify: verification criteria (exact clause-presence checks and semantic consistency rules), enumerated failure modes (e.g., anchor omission, narrative drift), and quantitative results (e.g., verification pass rates on the full set and sampled subsets). These additions will make the ground-truth generation reproducible. revision: yes
Circularity Check
No circularity: benchmark derives from external regulatory text via explicit factorization
full rationale
The paper's core derivation is the clause-card factorization of Minnesota's 29 Reportable Adverse Health Events into auditable specifications, followed by anchor-driven instantiation to produce narratives with by-construction ground truth. This chain is anchored in external policy documents rather than author-fitted parameters, self-citations, or renamed prior results. No equations, predictions, or uniqueness claims reduce to inputs defined within the paper itself; the construction is presented as a new pipeline whose fidelity can be audited against the source regulations. The reader's noted score of 2 reflects possible minor self-citation elsewhere, but none appears load-bearing here.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Regulatory text can be factorized into clause cards that enable auditable decision specifications for triage.
invented entities (1)
-
clause card
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Accessed: May 21, 2026. Harsha Nori, Mayank Daswani, Christopher Kelly, Scott Lundberg, Marco Tulio Ribeiro, Marc Wilson, Xi- aoxuan Liu, Viknesh Sounderajah, Jonathan Carlson, Matthew P Lungren, and 1 others. 2025. Sequen- tial diagnosis with language models.arXiv preprint arXiv:2506.22405. Gavin M Schaeferle, Margaret Zhou, Shrinath Patel, Shiba Kuanar,...
-
[2]
clause_card_id
A systematic review of natural language pro- cessing for classification tasks in the field of incident reporting and adverse event analysis.International journal of medical informatics, 132:103971. A Benchmark Construction Details This section documents the artifacts and procedures that operationalize the clause-card-centered con- struction pipeline descr...
2024
-
[3]
target clause
TARGET_CLAUSE: the identifier and verbatim text of one specific MN29 clause (the “target clause”)
-
[4]
bears on the target clause’s reportability semantics
MN29_GUIDANCE: the full text of the MN29 Guidance document, in its original Markdown structure (top-level sections General Recommendation N, <Family> Event Recommendation N, and the question/issue subsections under each recommendation). Task. Produce one Markdown document, loyal_extraction.md, that contains: (i) the verbatim text of the target clause, and...
-
[5]
CareManagement_1_ MedicationError)
TARGET_CLAUSE_ID: a stable identifier of the target MN29 clause (e.g. CareManagement_1_ MedicationError)
-
[6]
LOYAL_EXTRACTION: the loyal_extraction.md produced for this clause; it is the authoritative clause-and-guidance context and supersedes any prior knowledge you may have about MN29
-
[7]
what concrete fact does this slot carry
CLAUSE_CARD_SCHEMA: the clause-card JSON schema. Every output card must conform to this schema. Task. Propose a set of candidate clause cards for the target clause. Each card factorizes one decision region of the clause into auditable variables, in the exact schema given by CLAUSE_CARD_SCHEMA. Cards may carry one of two event types: - Reportable: the card...
-
[8]
Treat its boundary_conditions and basic_event_elements as the authoritative vocabulary you must reuse verbatim — do not invent new boundary-condition names or element names
PARENT_CARD: one finalized clause card whose event_type is either Reportable or Non_Reportable; it is the parent of the variants you are about to author. Treat its boundary_conditions and basic_event_elements as the authoritative vocabulary you must reuse verbatim — do not invent new boundary-condition names or element names
-
[9]
This is what you must consult to decide whether the residual narrative of a candidate variant is also consistent with an alternative verdict drawn from another card on the clause
SIBLING_CARDS: the full list of finalized clause cards on the same clause as PARENT_CARD (including PARENT_CARD itself). This is what you must consult to decide whether the residual narrative of a candidate variant is also consistent with an alternative verdict drawn from another card on the clause. You may not invent a sibling card — only cards in SIBLIN...
-
[10]
It is the authoritative clause-and-guidance context and supersedes any prior knowledge you may have about MN29
LOYAL_EXTRACTION: the loyal_extraction.md for the parent card’s clause. It is the authoritative clause-and-guidance context and supersedes any prior knowledge you may have about MN29
-
[11]
parent_clause_card_id
MISSING_VARIANTS_SCHEMA: the JSON schema for the missing_information_variants block. Every variant you propose must conform to this schema. Task. Propose a set of missing-information variants for PARENT_CARD. Each variant describes one realistic reporting scenario in which a specific subset of the parent card’s basic event elements is not yet known to the...
-
[12]
TARGET_CLAUSE_ID: a stable identifier of the target MN29 clause
-
[13]
It is the authoritative clause-and-guidance context
LOYAL_EXTRACTION: the loyal_extraction.md produced for this clause. It is the authoritative clause-and-guidance context. Every ambiguity you exploit must be traceable to a specific passage of LOYAL_EXTRACTION
-
[14]
Every Uncertain card you propose must describe a scenario that no card in EXISTING_CARDS already resolves
EXISTING_CARDS: the full list of finalized Reportable and Non_Reportable clause cards on this clause. Every Uncertain card you propose must describe a scenario that no card in EXISTING_CARDS already resolves
-
[15]
a formal multidisciplinary medication-safety review with two specialties formally taking opposing positions on the same yes/no question
CLAUSE_CARD_SCHEMA: the clause-card JSON schema. Every Uncertain card you output must conform to this schema with event_type set to Uncertain. Task. Propose a set of candidate Uncertain clause cards for the target clause. Each card factorizes one ambiguity region of the clause into auditable variables in the schema given by CLAUSE_CARD_SCHEMA. Cards diffe...
-
[16]
Fill every basic_event_element exactly once
-
[17]
Produce a concrete and medically plausible fact value for each slot
-
[18]
Make the final structured case semantically consistent with the clause-card definition, boundary conditions, and instantiation constraints
-
[19]
If the anchored material conflicts with the clause card, follow the clause card
Use the clause card as the semantic contract. If the anchored material conflicts with the clause card, follow the clause card
-
[20]
Do not simply copy them, lightly paraphrase them, or default to them when other semantically valid concrete instantiations are available under the anchored setting
If the clause card includes example facts or example phrasings, treat them as illustrative only. Do not simply copy them, lightly paraphrase them, or default to them when other semantically valid concrete instantiations are available under the anchored setting
-
[21]
Use the anchored material and the surrounding clause/guidance context to diversify the generated case as long as the final case still fits the target clause card
-
[22]
wrong site
Use concrete facts rather than abstract labels. For example, prefer a specific side, body part, site, level, medication, device, injury, or action instead of vague phrases such as “wrong site” or “correct side.”
-
[23]
Do not leave required facts vague just to sound general
-
[25]
Do not write an event narrative, explanation, or commentary
-
[26]
Do not add any top-level key other than slot_values
-
[27]
slot_values
Do not write any reportability statements in the instantiated fact value, such as reportable, non-reportable, should be reported, should not be reported, below/above reporting threshold or uses equivalent direct classification language. # Input information. ## Target clause card: {{target_clause_card_json}} ## Clause and guidance context: {{loyal_extracti...
-
[28]
Check whether the candidate fits the clause-card definition as a whole
-
[29]
Check whether the candidate is consistent with each boundary condition
-
[30]
Check whether the candidate satisfies the instantiation constraints
-
[31]
Check whether the slot values are concrete rather than vague pseudo-concrete labels
-
[32]
pass": true | false,
Be strict about semantic fit, but judge semantic equivalence rather than exact wording. # Input information. ## Target clause card: {{target_clause_card_json}} ## Clause and guidance context: {{loyal_extraction_markdown}} ## Candidate slot_values: {{candidate_slot_values_json}} # Output format. Return JSON only in this shape: { "pass": true | false, "issu...
-
[33]
Do not omit or substantially alter load-bearing facts
Preserve the factual meaning of the canonical structured event. Do not omit or substantially alter load-bearing facts
-
[34]
Your narrative should be as specific and natural as the kind of text found in the anchor
Draw on the anchored material for writing style, clinical vocabulary, and level of concrete detail. Your narrative should be as specific and natural as the kind of text found in the anchor
-
[38]
Beyond the core facts in the canonical structured event, you may draw on, reuse or modify other related background information from the anchored material so that the resulting event description feels more realistic and authentic
-
[39]
event_narrative
Adopt the perspective of (or portray yourself as) a nurse, physician, or another healthcare professional involved in or knowledgeable about the event (e.g. pharmacist, therapist, technician, radiology/lab staff, rehabilitation physician). The narrative may be written in either first-person or third-person, as long as it reflects a realistic clinical voice...
-
[40]
Use each field’s meaning as the primary extraction target
-
[41]
If a slot is not stated, not recoverable, or genuinely ambiguous, return null for that slot
-
[42]
slot_values
Do not invent facts to make the narrative fit any slot. # Input information. ## Basic event element skeleton: {{bee_skeleton_json}} ## Event narrative: {{event_narrative_text}} # Output format. Return JSON only in this shape: { "slot_values": { "<slot_name_1>": null, ... } }. Include every slot exactly once inside slot_values; use null when the narrative ...
-
[44]
Pass only if the extracted slot_values preserved the canonical facts in substance
-
[45]
Fail if a load-bearing fact was omitted, materially altered, contradicted, or replaced by a materially different fact
-
[47]
pass": true | false,
Be specific in issues when you identify a problem. If you find multiple issues, list them all. # Input information. ## Basic event element meanings: {{bee_skeleton_json}} ## Canonical slot_values: {{canonical_slot_values_json}} ## Event narrative: {{event_narrative_text}} ## Extracted slot_values from the narrative: {{extracted_slot_values_json}} # Output...
-
[48]
Do not omit or substantially alter load-bearing facts
Preserve the factual meaning of the structured facts you are given. Do not omit or substantially alter load-bearing facts
-
[49]
Draw on the anchored material for writing style, clinical vocabulary, and level of concrete detail
-
[50]
If Retry feedback is provided, treat it as required corrective guidance for the next attempt
-
[51]
Use the Missing variant summary only as an internal writing constraint that helps you decide what should remain naturally unstated
-
[52]
Treat the Masked fact slots and meanings as a strict do-not-mention list: do not include facts, explanations, caveats, or uncertainty statements that would reveal or directly discuss those masked dimensions
-
[53]
would a reasonable, clinically literate reader of this sentence be able to confidently determine the truth value of this boundary condition?
Boundary-condition preservation. Treat each entry in Masked boundary conditions as a creation-time constraint, not only as something the verifier will check after the fact. For each masked boundary condition, before committing any sentence, mentally ask: “would a reasonable, clinically literate reader of this sentence be able to confidently determine the ...
-
[54]
Do not explicitly say that some information is missing, unknown, unavailable, pending, not yet determined, not documented, or still under review if that statement would point to facts that were intentionally omitted
-
[55]
The correct behavior is to simply not mention them
Do not directly discuss the absence of omitted facts. The correct behavior is to simply not mention them
-
[56]
Do not mention reportability, non-reportability, clause numbers, clause-card ids, legal conclusions, or recommendations about whether the event should be reported
-
[57]
Write in a natural, specific, and realistic clinical style, not like a rigid template, checklist, or legal summary
-
[58]
Beyond the core facts in the visible structured event facts, you may draw on, reuse or modify other related background information from the anchored material so that the resulting event description feels more realistic and authentic — but never at the cost of resolving a masked boundary condition
-
[59]
event_narrative
Adopt the perspective of a nurse, physician, or another healthcare professional involved in or knowledgeable about the event, in either first-person or third-person. # Input information. ## Basic event element meanings (visible slots only): {{visible_bee_skeleton_json}} ## Structured event facts (visible only): {{visible_slot_values_json}} ## Missing vari...
-
[60]
Judge semantic equivalence, not exact surface wording
-
[61]
Pass only if every visible fact that should remain available is preserved in the extracted result
-
[62]
Pass only if every masked basic-event-element slot remains absent or unrecoverable in the extracted result, meaning the extracted value for that slot is null
-
[63]
Fail if the narrative explicitly says that a masked fact is missing, unknown, unavailable, unclear, pending, not yet determined, not documented, or still under review
-
[64]
Fail if the narrative directly discusses the absence of a masked fact, even if the extractor still returns null for that slot
-
[65]
Fail if the narrative explicitly states that the event is reportable, non-reportable, should be reported, should not be reported, or uses equivalent direct classification language
-
[66]
Fail if any visible fact was lost or materially changed
-
[67]
Fail if any masked basic-event-element fact leaked into the narrative and became recoverable
-
[68]
Given only the visible content of the incomplete narrative, can a reasonable, clinically literate reader confidently determine the truth value of this boundary condition?
Boundary-condition leakage check. For EACH entry in Masked boundary conditions you MUST emit exactly one corresponding row in the required output field per_bc_check, in the same order and using the same boundary_condition name. Do NOT collapse, merge, skip, or summarize any masked boundary condition. For each row, independently reason about the following ...
-
[69]
per_bc_check
Be specific in issues. For every per_bc_check row whose leak_verdict is "leaked", the issues array MUST also contain a matching entry that names the boundary condition, quotes or paraphrases the betraying narrative wording, explains how that wording resolves the boundary condition, and instructs the narrator to remove or rewrite it on the next revision. #...
-
[70]
The full text of the model’s rationale
-
[71]
hits": [<boundary_condition_name_string>, ...],
A list of boundary conditions for the case. Each entry has a name, a natural-language meaning, and the boundary condition’s truth value (true or false) in this specific case. Your job. For each boundary condition, decide whether the rationale actually invokes that boundary condition’s underlying concept and arrives at (or is consistent with) its truth val...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.