Synthetic Hallucinations, Real Gains: Hard Negatives from Frontier Models for FIM Hallucination Mitigation
Pith reviewed 2026-06-28 11:32 UTC · model grok-4.3
The pith
Frontier code models can generate plausible-but-wrong completions that serve as effective hard negatives for fine-tuning smaller models on fill-in-the-middle tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
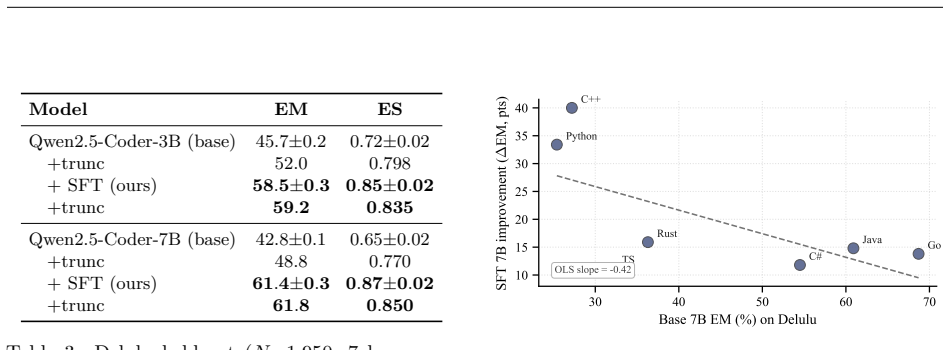
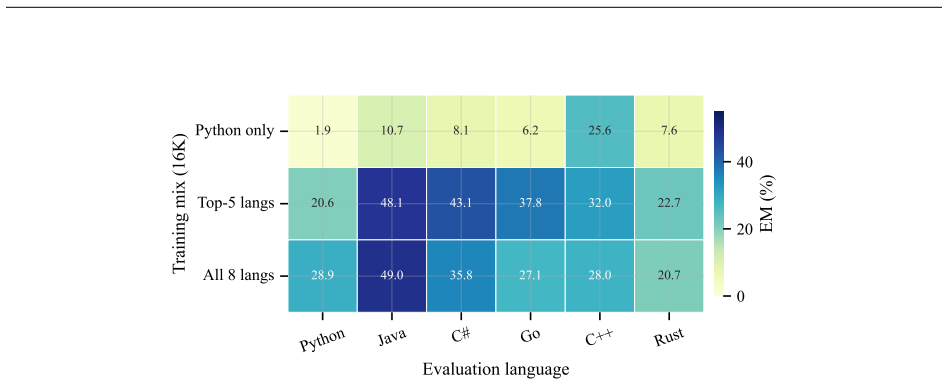
A pipeline that scrapes multilingual FIM contexts, prompts three frontier generators to produce one hard negative per context for each of four hallucination types, and then performs supervised fine-tuning on the resulting chosen/rejected pairs lifts exact match by 18.8 points and edit similarity by 0.22 on the Delulu benchmark for every language and type while also raising scores on every HumanEval-Infilling split and every SAFIM subset; the same recipe at 3B scale yields a 12.8-point exact-match gain with a small characterised general-FIM trade-off.
What carries the argument
The contrast between synthetic hallucinations generated by frontier models and ground-truth developer edits, used as paired chosen/rejected examples for supervised fine-tuning.
If this is right
- The measured gains hold uniformly across all eight languages and all four hallucination types in the benchmark.
- The same training data improves performance on every split of HumanEval-Infilling and every subset of SAFIM.
- The recipe produces usable gains at both 7B and 3B model scales.
- Five-axis ablations identify data size, type mix, language coverage, base-model family, and difficulty-aware fool rate as drivers of the observed improvement.
- The released generation, judging, curation, and fine-tuning code allows the method to be reproduced on any permissively licensed corpus.
Where Pith is reading between the lines
- The same frontier-to-small synthetic-negative recipe could be tested on non-FIM code generation tasks that also suffer from plausible hallucinations.
- If the fool-rate judging step generalises, it could serve as an automatic filter for curating training data in other code-related domains.
- Repeated application of the pipeline might allow successive generations of smaller models to approach frontier performance on FIM without direct access to the larger models at inference time.
Load-bearing premise
The completions produced by the frontier generators are sufficiently plausible yet incorrect hard negatives whose contrast with ground-truth edits supplies an effective supervised fine-tuning signal without introducing new biases or distribution shifts that would harm general FIM performance.
What would settle it
A held-out set of FIM contexts where the fine-tuned model shows no gain or a net drop in exact match and edit similarity compared with the base model.
Figures


read the original abstract
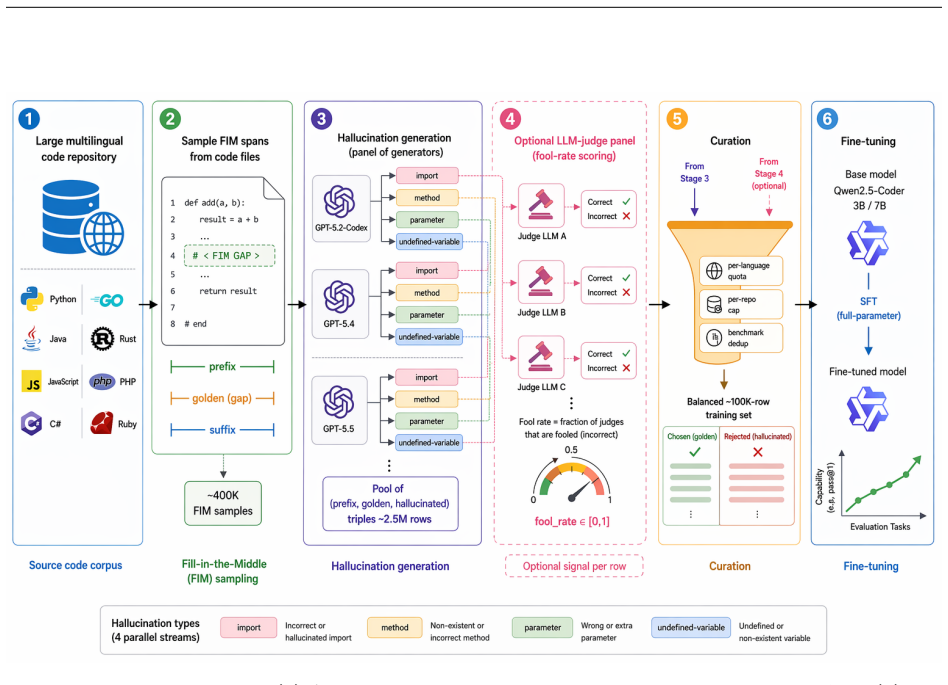
Small open-source code models that power IDE autocomplete still emit hallucinated Fill-in-the-Middle (FIM) completions: syntactically natural calls to methods, parameters, variables, and imports that do not exist in the surrounding project. Existing mitigations either require per-language execution sandboxes that do not apply at mid-keystroke or preference-optimisation pipelines that need large human-labelled corpora. We propose an execution-free alternative: use frontier code models to synthesise plausible-but-wrong completions as hard negatives, then leverage the contrast between these synthetic hallucinations and the ground-truth developer edit as a supervised fine-tuning signal. Our pipeline scrapes multilingual FIM contexts from public GitHub across eight languages and asks a panel of three frontier generators to produce one hard negative per context for each of four hallucination types drawn from the Delulu taxonomy, a Docker-verified multilingual FIM hallucination benchmark, yielding a paired chosen/rejected dataset. Fine-tuning Qwen2.5-Coder-7B-Instruct on a 100K-row curated subset lifts Delulu exact match by +18.8 points and edit similarity by +0.22 on every language and every type, while also improving every HumanEval-Infilling split and every SAFIM subset. The same recipe at 3B lifts Delulu by +12.8 EM with a small, characterised general-FIM trade-off. Five-axis ablations (size, type mix, language coverage, base-model family, and a difficulty-aware fool rate) plus a head-to-head SFT vs. DPO/ORPO comparison map which design choices drive the gain. We release the full pipeline source code -- generation, fool-rate LLM judging, curation, and the FIM fine-tuning recipe -- so that the experiments in this paper can be reproduced end-to end on any permissively licensed corpus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that frontier code models can generate plausible-but-wrong FIM completions as hard negatives for contexts scraped from public GitHub repositories across eight languages and four hallucination types from the Delulu taxonomy. These synthetic pairs are used to create a supervised fine-tuning dataset; fine-tuning Qwen2.5-Coder-7B-Instruct on a 100K-row curated subset produces +18.8 exact-match and +0.22 edit-similarity gains on every Delulu language and type, plus improvements on all HumanEval-Infilling splits and SAFIM subsets. Parallel gains (with a small general-FIM trade-off) are reported for a 3B model. Five-axis ablations (size, type mix, language coverage, base-model family, difficulty-aware fool rate) and an SFT-vs-DPO/ORPO comparison are presented, and the full generation/judging/curation/fine-tuning pipeline is released for end-to-end reproduction.
Significance. If the synthetic negatives supply a clean contrastive signal, the work supplies a scalable, execution-free route to hallucination mitigation that avoids per-language sandboxes and large human preference corpora. The consistent cross-language, cross-type, and cross-benchmark gains, together with the released pipeline code, would constitute a practical contribution to open-source code-model fine-tuning. The multilingual scope and explicit comparison of SFT against preference methods further increase the result's utility if the core assumption on negative quality holds.
major comments (2)
- [Abstract and pipeline description] Abstract / Pipeline description: The headline claim that the +18.8 EM / +0.22 edit-sim lift on Delulu (and the gains on HumanEval-Infilling and SAFIM) arises from contrastive SFT on hard negatives requires that the frontier-generated completions are verifiably incorrect. The manuscript relies on an LLM-based fool-rate judge and a subsequent curation step; no independent verification (execution, static analysis, or compilation checks against the ground-truth edit) is reported to confirm the negatives are actually erroneous rather than merely judged as such. This verification gap is load-bearing for interpreting the uniform gains as evidence of an effective hard-negative signal rather than an artifact of the judge or curation process.
- [Results (curated subset)] Results section (curated 100K subset): The reported numbers are obtained on a curated 100K-row subset whose selection criteria and any explicit controls for distribution shift relative to the base model's pre-training corpus or the Delulu test distribution are not detailed. Without such controls it remains possible that the consistent improvements across languages, hallucination types, and held-out benchmarks are partly attributable to data selection rather than the synthetic-negative contrast.
minor comments (2)
- [Abstract] The abstract states that five-axis ablations were performed; listing the exact axes and the corresponding quantitative outcomes in a single summary table would improve readability.
- [Abstract] The manuscript mentions release of the full pipeline source code; adding an explicit GitHub or Zenodo link (or DOI) in the abstract would make the reproducibility claim immediately actionable for readers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating where the manuscript will be revised.
read point-by-point responses
-
Referee: [Abstract and pipeline description] Abstract / Pipeline description: The headline claim that the +18.8 EM / +0.22 edit-sim lift on Delulu (and the gains on HumanEval-Infilling and SAFIM) arises from contrastive SFT on hard negatives requires that the frontier-generated completions are verifiably incorrect. The manuscript relies on an LLM-based fool-rate judge and a subsequent curation step; no independent verification (execution, static analysis, or compilation checks against the ground-truth edit) is reported to confirm the negatives are actually erroneous rather than merely judged as such. This verification gap is load-bearing for interpreting the uniform gains as evidence of an effective hard-negative signal rather than an artifact of the judge or curation process.
Authors: We acknowledge that the manuscript does not report independent execution or static-analysis verification of the synthetic negatives. This follows from the core design goal of an execution-free pipeline that avoids language-specific sandboxes. The fool-rate judge is applied conservatively with a multi-model panel, and the full judging and curation code is released. We will add a limitations paragraph explicitly discussing this verification gap and noting that future extensions could incorporate static checks where they do not conflict with the execution-free objective. revision: partial
-
Referee: [Results (curated subset)] Results section (curated 100K subset): The reported numbers are obtained on a curated 100K-row subset whose selection criteria and any explicit controls for distribution shift relative to the base model's pre-training corpus or the Delulu test distribution are not detailed. Without such controls it remains possible that the consistent improvements across languages, hallucination types, and held-out benchmarks are partly attributable to data selection rather than the synthetic-negative contrast.
Authors: The 100K subset was formed by selecting high-fool-rate examples balanced across the four hallucination types and eight languages. We will expand the methods section with the precise selection criteria, including any diversity and difficulty filters, plus summary statistics comparing the subset to the full generated corpus and the Delulu test distribution. These additions will make explicit that the reported gains are driven by the contrastive signal rather than selection effects. revision: yes
Circularity Check
No circularity: empirical pipeline evaluated on external held-out benchmarks
full rationale
The paper presents an empirical method: scraping GitHub contexts, generating synthetic negatives with external frontier models, curating a 100K subset, and fine-tuning Qwen2.5-Coder models, with all gains measured on independent benchmarks (Delulu, HumanEval-Infilling, SAFIM). No equations, derivations, or self-defined quantities exist that reduce to inputs by construction. No self-citations are load-bearing for any central claim, and the pipeline relies on external data and models rather than internal redefinitions or fitted predictions renamed as results. This is a standard self-contained empirical ML study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frontier models can reliably produce plausible-but-incorrect FIM completions that function as effective hard negatives for the four Delulu hallucination types.
Reference graph
Works this paper leans on
-
[1]
Efficient Training of Language Models to Fill in the Middle
doi: 10.48550/arXiv.2207.14255. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé, Jared Kaplan, Harrison Edwards, Yura Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.14255
-
[2]
Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida I
URLhttps://arxiv.org/abs/2605.07024. Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida I. Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer, and M. Lewis. Incoder: A generative model for code infilling and synthesis
-
[3]
InCoder: A Generative Model for Code Infilling and Synthesis
doi: 10.48550/arXiv.2204.05999. Linyuan Gong, Sida Wang, Mostafa Elhoushi, and Alvin Cheung. Evaluation of LLMs on syntax-aware code fill-in-the-middle tasks
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.05999
-
[4]
Linyuan Gong, Alvin Cheung, Mostafa Elhoushi, and Sida Wang
doi: 10.48550/arXiv.2403.04814. Linyuan Gong, Alvin Cheung, Mostafa Elhoushi, and Sida Wang. Structure-aware fill-in-the-middle pretraining for code
-
[5]
doi: 10.48550/arXiv.2506.00204. Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on LLM-as-a-judge
-
[6]
doi: 10.48550/arXiv.2411.15594. Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, Y. K. Li, et al. Deepseek-coder: When the large language model meets programming - the rise of code intelligence
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15594
-
[7]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
doi: 10.48550/arXiv.2401.14196. Jiwoo Hong, Noah Lee, and James Thorne. ORPO: Monolithic preference optimization without reference model. pp. 11170–11189. Association for Computational Linguistics,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.14196
-
[8]
ORPO: Monolithic Preference Optimization without Reference Model
doi: 10.48550/arXiv.2403.07691. Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, K. Dang, et al. Qwen2.5-coder technical report
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.07691
-
[9]
StarCoder 2 and The Stack v2: The Next Generation
doi: 10.48550/arXiv.2402.19173. Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. WizardCoder: Empowering code large language models with Evol-Instruct
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.19173
-
[10]
Rafael Rafailov, Archit Sharma, E
doi: 10.48550/arXiv.2404.02806. Rafael Rafailov, Archit Sharma, E. Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. pp. 53728–53741. Neural Information Processing Systems Foundation, Inc. (NeurIPS),
-
[11]
doi: 10.52202/075280-2338. Joshua Robinson, Ching-Yao Chuang, Suvrit Sra, and Stefanie Jegelka. Contrastive learning with hard negative samples. InInternational Conference on Learning Representations,
-
[12]
doi: 10.1109/ CVPR.2015.7298682. P. Shojaee, Aneesh Jain, Sindhu Tipirneni, and Chandan K. Reddy. Execution-based code generation using deep reinforcement learning
arXiv 2015
-
[13]
Yuchen Tian, Weixiang Yan, Qian Yang, Xuandong Zhao, Qian Chen, Wen Wang, Ziyang Luo, and Lei Ma
doi: 10.48550/arXiv.2301.13816. Yuchen Tian, Weixiang Yan, Qian Yang, Xuandong Zhao, Qian Chen, Wen Wang, Ziyang Luo, and Lei Ma. Codehalu: Investigating code hallucinations in llms via execution-based verification. InAAAI Conference on Artificial Intelligence,
-
[14]
URLhttps://api.semanticscholar.org/ CorpusID:269484644
doi: 10.1609/aaai.v39i24.34717. URLhttps://api.semanticscholar.org/ CorpusID:269484644. Pat Verga, Sebastian Hofstätter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating LLM generations with a panel of diverse models
-
[15]
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
doi: 10.48550/arXiv.2404.18796. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.18796
-
[16]
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang
doi: 10.48550/ arXiv.2212.10560. Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Empowering code generation with OSS-Instruct
-
[17]
doi: 10.48550/arXiv.2305.04087. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, E. Xing, et al. Judging LLM-as-a-judge with MT-Bench and chatbot arena. pp. 46595–46623. Neural Information Processing Systems Foundation, Inc. (NeurIPS),
-
[18]
19 Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, and Yongqiang Ma
doi: 10.52202/ 075280-2020. 19 Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, and Yongqiang Ma. LlamaFactory: Unified efficient fine-tuning of 100+ language models. pp. 400–410. Association for Computational Linguistics,
2020
-
[19]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
doi: 10.48550/arXiv.2403.13372. Albert Ziegler, Eirini Kalliamvakou, X. Alice Li, Andrew Rice, Devon Rifkin, Shawn Simister, Ganesh Sittampalam, and Edward Aftandilian. Productivity assessment of neural code completion. InMAPS@PLDI, pp. 21–29. ACM,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.13372
-
[20]
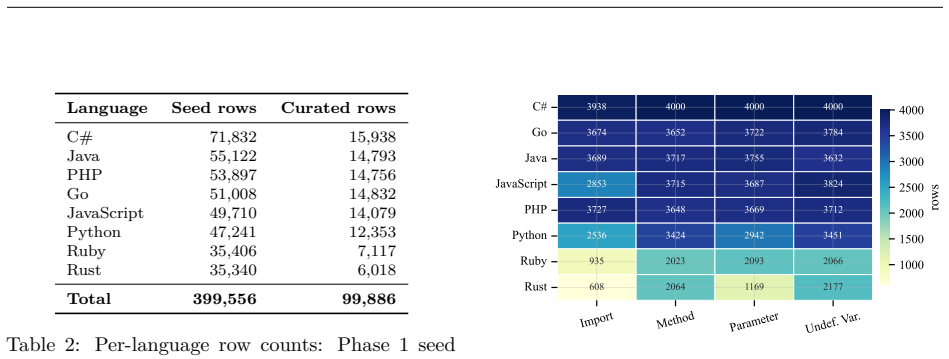
doi: 10.1145/3520312.3534864. A Generation pool statistics Phase 2 yields2,473,312valid rows distributed across the three generators and four taxonomy types as shown in Table
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.