Better Accuracies, Worse Reasoning: A Step-Level Audit of Medical Chain-of-Thought Distillation
Pith reviewed 2026-06-29 12:52 UTC · model grok-4.3
The pith
In medical chain-of-thought distillation, gains in answer accuracy coincide with rises in reasoning-step factual errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
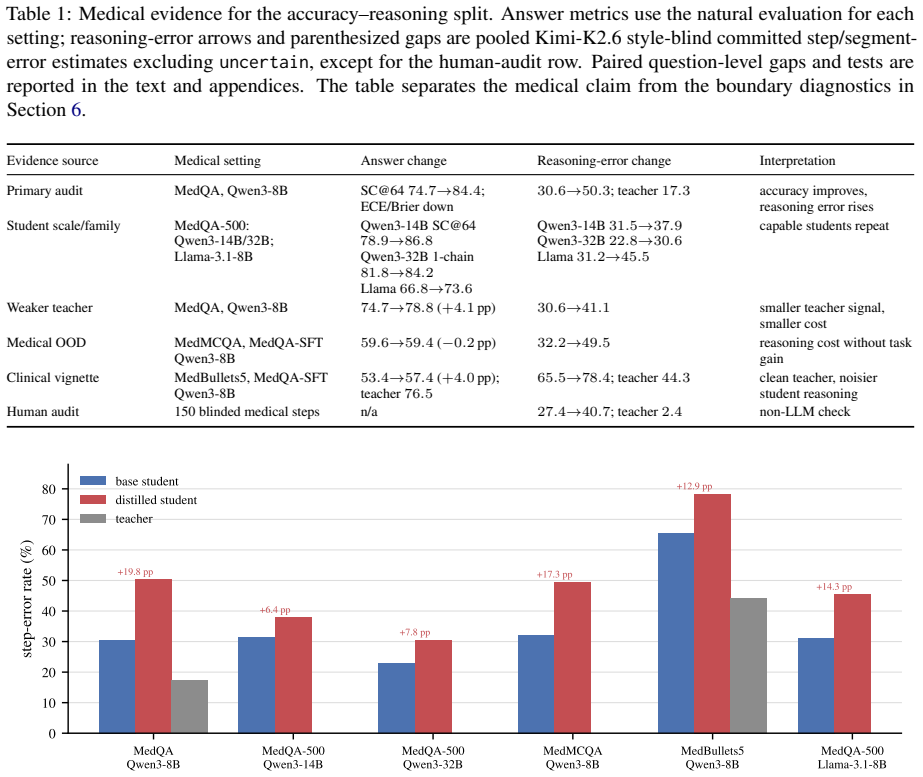
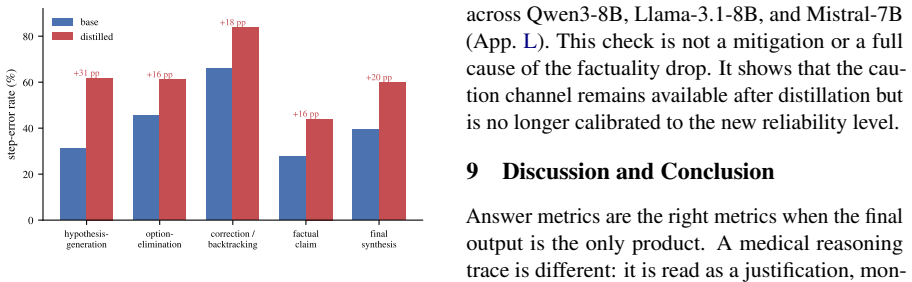
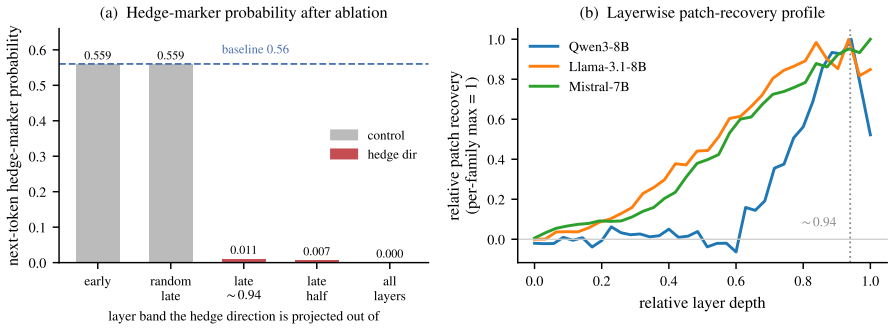
The paper shows that in medical QA, CoT distillation improves final-answer metrics like accuracy and calibration but increases the rate of factual errors per non-abstained reasoning step, as measured by both LLM judges and expert audit. This opposite movement between answer quality and trace factuality persists across variations in setup.
What carries the argument
The step-level factuality audit of reasoning traces using a style-blind LLM judge and blinded clinical expert review on medical benchmarks.
If this is right
- Answer-level metrics alone fail to detect declines in reasoning quality.
- Standard hedging rates and aggregate scores do not reveal the factual error increase.
- Releasing distilled traces requires step-level checks beyond final answers.
- The risk emerges when compact answers under-constrain the rationale and students can mimic form without substance.
Where Pith is reading between the lines
- Similar patterns may appear in other domains where final answers are multiple-choice but reasoning is complex.
- Training objectives might need to penalize step errors directly rather than just final answers.
- Deployment in clinical settings could lead to over-reliance on superficially correct but factually flawed traces.
Load-bearing premise
The assumption that the LLM judge and clinical expert audit correctly identify factual errors in individual steps without introducing their own systematic biases or inconsistencies.
What would settle it
A replication using a different judge or a larger expert audit that finds no increase or a decrease in step-level error rates would falsify the central claim.
Figures
read the original abstract
Chain-of-thought (CoT) distillation trains a smaller model to imitate a teacher's reasoning trace, but it is typically evaluated by final-answer metrics including accuracy. We ask whether gains in answer quality are accompanied by improvements in the trace. In medical QA, where short answer options can leave a richer clinical justification under-specified, a Qwen3-8B student distilled from a DeepSeek-V3-family teacher improves on MedQA-USMLE answer metrics (SC@64 74.7% to 84.4%; expected calibration error (ECE) 0.096 to 0.034). Yet under a Kimi-K2.6 style-blind LLM-judge audit, its error rate over non-abstained steps rises from 30.6% to 50.3%. In this primary medical setting, answer quality and trace factuality move in opposite directions. This before--after pattern persists across evaluators, teacher strengths, student scales and families, medical benchmarks, and style, segmentation, and answer-correctness controls. A 150-step blinded audit by a clinical expert reproduces the same ordering. Boundary checks narrow the scope of the claim: the risk appears when a compact answer under-constrains the rationale and a capable student can imitate expert-like form without reliably grounding each local claim. Standard answer metrics and aggregate hedging rates do not reveal the shift. When such traces are released or reused, answer-level metrics alone are insufficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that CoT distillation in medical QA improves final-answer metrics (e.g., SC@64 from 74.7% to 84.4%, ECE from 0.096 to 0.034) while increasing per-step factual error rates (30.6% to 50.3%) under a style-blind LLM judge; the inverse relationship holds across multiple controls, teacher/student variants, benchmarks, and a 150-step blinded clinical-expert audit. The risk is localized to cases where compact answers under-constrain the rationale.
Significance. If the result holds, the work shows that answer-level metrics alone are insufficient to certify reasoning quality after distillation in medicine, where local factual grounding matters. Strengths include the direct before-after design, persistence across controls, and the expert audit reproducing the ordering. This supplies a concrete, falsifiable warning for reuse of distilled traces.
major comments (2)
- [Abstract] Abstract: the central opposite-direction claim rests on the Kimi-K2.6 judge correctly identifying factual errors at the step level. The 150-step expert audit reproduces the ordering but reports neither inter-rater agreement, step-selection protocol, nor whether the expert received the identical segmentation and abstention rules used by the judge; this validation gap is load-bearing for interpreting the 30.6%→50.3% shift as genuine rather than judge artifact.
- [Abstract] Abstract: while the text states the pattern 'persists across ... style, segmentation, and answer-correctness controls,' the abstract supplies no quantitative error-rate deltas or statistical tests for those specific controls, preventing assessment of whether any single control eliminates the effect.
minor comments (1)
- [Abstract] Abstract: 'non-abstained steps' is used without defining the abstention criterion; a brief parenthetical or reference to the methods section would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential implications of our findings. We address each major comment below with specific plans for revision. We agree that the expert audit protocol requires more explicit documentation and that the abstract would benefit from additional quantitative detail on the controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central opposite-direction claim rests on the Kimi-K2.6 judge correctly identifying factual errors at the step level. The 150-step expert audit reproduces the ordering but reports neither inter-rater agreement, step-selection protocol, nor whether the expert received the identical segmentation and abstention rules used by the judge; this validation gap is load-bearing for interpreting the 30.6%→50.3% shift as genuine rather than judge artifact.
Authors: We acknowledge the validation gap. The audit used a single board-certified clinician blinded to model origin. Steps were randomly sampled (stratified by answer correctness) from the MedQA-USMLE test set. The expert received the identical step segmentation and abstention rules as the Kimi-K2.6 judge. Because only one expert participated, inter-rater agreement is not applicable. We will revise the Methods and Results sections to explicitly state the sampling protocol, blinding procedure, and that the expert instructions matched the judge's rules verbatim. This addition will allow readers to evaluate whether the ordering reflects genuine factual differences rather than judge artifact. revision: yes
-
Referee: [Abstract] Abstract: while the text states the pattern 'persists across ... style, segmentation, and answer-correctness controls,' the abstract supplies no quantitative error-rate deltas or statistical tests for those specific controls, preventing assessment of whether any single control eliminates the effect.
Authors: The abstract prioritizes brevity while directing readers to the main text, where Tables 3–5 and the associated statistical tests report the per-control error-rate deltas (ranging from +12.4 to +24.7 percentage points) and p-values. To address the concern directly in the abstract, we will insert a concise clause stating that the increase remained statistically significant (p < 0.01) under all listed controls and provide the observed range of deltas. This change preserves abstract length while enabling immediate assessment of robustness. revision: yes
Circularity Check
No circularity: direct empirical before-after measurements
full rationale
The paper reports direct empirical comparisons of answer metrics (SC@64, ECE) and per-step error rates before and after distillation, using an LLM judge and a small expert audit. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the derivation of the central claim. The observed opposite-direction pattern is presented as a measured outcome across controls, not derived from prior results by the same authors or by construction from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The style-blind LLM judge provides an accurate assessment of factual errors in medical reasoning steps.
Reference graph
Works this paper leans on
-
[1]
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation
Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083. Amos Azaria and Tom Mitchell. 2023. The internal state of an llm knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976. Bowen Baker, Joost Huizinga, Leo Gao, Zehao Dou, Me...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Teaching Models to Express Their Uncertainty in Words
Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601. Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Teaching models to express their uncertainty in words.arXiv preprint arXiv:2205.14334. Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chen...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, and Aliaksei Severyn. 2023. Teaching small language models to reason. InPro- ceedings of the 61st Annual Meeting of the Associa- tion for Computational Linguistics (Volume 2: Short Papers), pages 1773–1781. Guy M McKhann, D...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Investigating mysteries of cot-augmented dis- tillation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6071–6086. Jiageng Wu, Kevin Xie, Bowen Gu, Nils Krüger, Kueiyu Joshua Lin, and Jie Yang. 2025a. Why chain of thought fails in clinical text understanding.arXiv preprint arXiv:2509.21933. Juncheng Wu, Wen...
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Zijun Yao, Yantao Liu, Yanxu Chen, Jianhui Chen, Jun- feng Fang, Lei Hou, Juanzi Li, and Tat-Seng Chua
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Are reasoning models more prone to halluci- nation?arXiv preprint arXiv:2505.23646. Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, and 1 others. 2025. Jus- tice or prejudice? quantifying biases in llm-as-a- judge. InInternational Conference on Learning Rep- resentations, volume 202...
-
[7]
X is” vs. “X may be
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Kaitlyn Zhou, Jena Hwang, Xiang Ren, and Maarten Sap. 2024. Relying on the unreliable: The impact of language models’ reluctance to express uncertainty. InProceedings of the 62nd Annual Meeting of the Association for Computational Li...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.