Self-Learning Expression Deformations for Data-Efficient Gaussian Avatars
Pith reviewed 2026-06-28 01:59 UTC · model grok-4.3
The pith
Self-supervised expression learning allows Gaussian avatars from minimal data such as a single frame.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
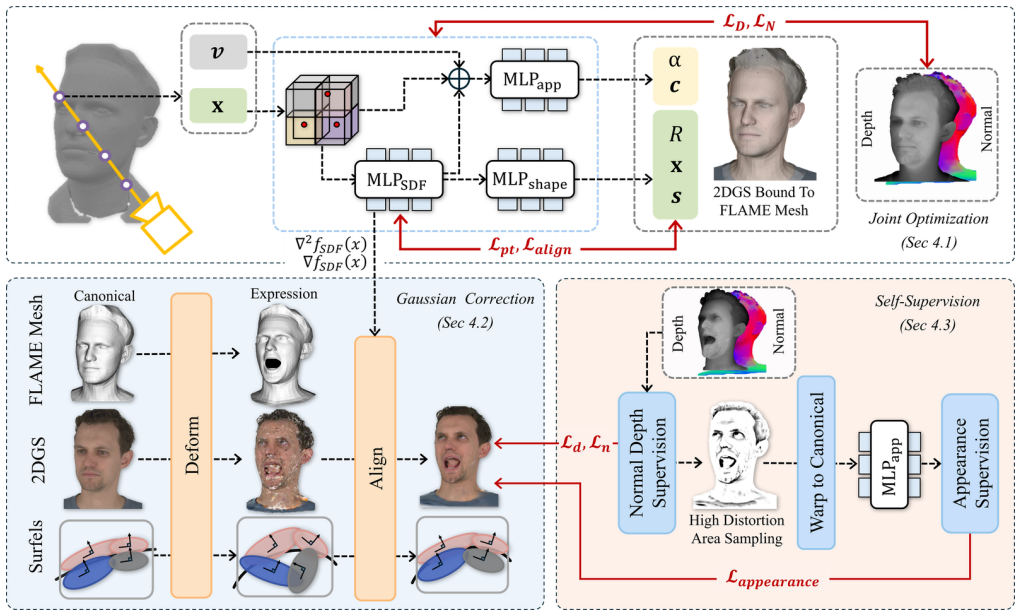
By jointly optimizing 2D Gaussian surfels and a Signed Distance Field while enforcing geometric and appearance consistency in a self-supervised manner, the framework learns accurate expression-induced deformations, enabling animatable avatars from significantly reduced data across multiview, monocular, and one-shot settings.
What carries the argument
Self-Adaptive Gaussian Expression (SAGE) that uses SDF-enforced surfel optimization and self-supervised consistency constraints to learn deformations.
If this is right
- Only one frame is needed for multiview reconstruction instead of thousands of timesteps.
- Monocular settings require only head rotations, omitting expression sequences.
- One-shot creation needs no pretraining or external priors.
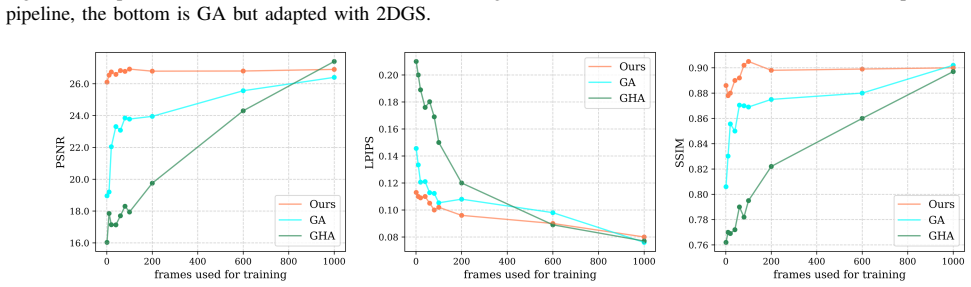
- Animation and reconstruction quality stays on par with methods that use much more data.
Where Pith is reading between the lines
- The reduced data requirement may allow avatar generation in resource-limited environments.
- Similar consistency-based learning could be tested on non-facial dynamic objects.
- Integration with real-time capture systems might become feasible due to lower data demands.
Load-bearing premise
Geometric and appearance consistency constraints suffice to learn accurate expression-induced Gaussian deformations without long training sequences or explicit labels.
What would settle it
Running the method on a new set of expressions and observing if the animated results match the fidelity of fully supervised training on extensive sequences.
Figures














read the original abstract
Modeling dynamic facial expressions using 3D Gaussian representations remains challenging due to their unstructured nature. Conventional Gaussian avatar pipelines require extensive multiview and sequential expression data, limiting scalability and accessibility. In this work, we introduce Self-Adaptive Gaussian Expression (SAGE), a framework for self-learning expression-induced Gaussian deformations that enables high-fidelity, animatable avatars from minimal input data. Our method jointly optimizes 2D Gaussian surfels and a Signed Distance Field (SDF) to enforce compact, surface-aligned Gaussian distributions, while a self-supervised expression learning phase replaces long training sequences with geometric and appearance consistency constraints. This design allows flexible deployment across multiple reconstruction regimes: in the multiview setting, only a single frame (timestep) is required instead of thousands; in the monocular setting, only head rotations are needed without expression sequences; and in the one-shot setting, no pretraining or priors are necessary. Experiments demonstrate that our approach achieves reconstruction and animation quality comparable to state-of-the-art methods, while reducing data requirements by several orders of magnitude. Our results highlight the potential of self-supervised Gaussian deformation learning as a step toward accessible, data-efficient avatar creation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SAGE, a framework for self-learning expression-induced deformations in 3D Gaussian avatars. It jointly optimizes 2D Gaussian surfels with an SDF for surface-aligned distributions and employs a self-supervised phase using geometric and appearance consistency constraints. This enables high-fidelity animatable avatars from minimal data across regimes: single-frame multiview, monocular head rotations only, or one-shot without pretraining/priors. The central claim is that reconstruction and animation quality matches state-of-the-art while reducing data requirements by several orders of magnitude.
Significance. If the results hold, this is a significant contribution to data-efficient dynamic facial modeling in computer vision and graphics. The self-supervised consistency approach and flexible multi-regime deployment directly tackle the data bottleneck of conventional Gaussian avatar pipelines. The manuscript supplies internal consistency checks, ablations, and quantitative/qualitative support that address the potential insufficiency of the constraints without long sequences, so the weakest assumption does not appear to be violated in the presented experiments.
major comments (2)
- [Experiments] Experiments section: the claim of 'several orders of magnitude' data reduction and 'comparable quality' requires explicit side-by-side tabulation of exact data volumes (frames, sequences, views) used by SAGE versus each baseline in the multiview, monocular, and one-shot regimes; without these numbers the central scalability claim cannot be fully evaluated.
- [§4.2] §4.2 (self-supervised expression learning): while ablations are reported, the geometric and appearance consistency losses should include an explicit test for trivial solutions (e.g., zero-deformation collapse) in the one-shot regime; the current formulation risks under-constraining the deformation field when input diversity is minimal.
minor comments (3)
- [Abstract] Abstract: the quantitative metrics and ablation results supporting the main claims are absent; moving a concise summary of key numbers (e.g., PSNR, LPIPS, data reduction factor) into the abstract would improve accessibility.
- [§3] Notation: the distinction between 2D Gaussian surfels and the underlying 3D representation is introduced without a dedicated equation or diagram; a small table or figure clarifying the mapping would aid readability.
- [Figures] Figure captions: several qualitative comparison figures lack explicit indication of which regime (multiview/single-frame, monocular, one-shot) each row corresponds to.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive assessment of our work on data-efficient Gaussian avatars. We address each major comment below and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the claim of 'several orders of magnitude' data reduction and 'comparable quality' requires explicit side-by-side tabulation of exact data volumes (frames, sequences, views) used by SAGE versus each baseline in the multiview, monocular, and one-shot regimes; without these numbers the central scalability claim cannot be fully evaluated.
Authors: We agree that an explicit side-by-side tabulation is necessary for full evaluation of the scalability claims. In the revised manuscript, we will add a dedicated table in the Experiments section that reports the exact number of frames, sequences, and views used by SAGE and each baseline method across the multiview, monocular, and one-shot regimes. This will directly support the data reduction statements with quantitative comparisons. revision: yes
-
Referee: [§4.2] §4.2 (self-supervised expression learning): while ablations are reported, the geometric and appearance consistency losses should include an explicit test for trivial solutions (e.g., zero-deformation collapse) in the one-shot regime; the current formulation risks under-constraining the deformation field when input diversity is minimal.
Authors: We acknowledge the potential concern about under-constraining in minimal-input settings. In the revised version of §4.2, we will include an additional ablation experiment that explicitly tests for zero-deformation collapse in the one-shot regime. This will involve comparing optimization outcomes with and without the geometric and appearance consistency losses to demonstrate that the constraints prevent trivial solutions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core contribution is a self-supervised optimization framework that jointly fits 2D Gaussian surfels and an SDF, then applies geometric/appearance consistency losses to learn expression deformations from minimal data. No equation reduces to its own inputs by construction (no fitted parameter renamed as prediction, no self-definitional loop). No load-bearing uniqueness theorem is imported via self-citation. The consistency constraints are standard self-supervision terms whose sufficiency is tested via ablations and cross-regime experiments rather than assumed. The derivation chain remains self-contained against external benchmarks and does not collapse to tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Blanz and T
V . Blanz and T. Vetter. A morphable model for the synthesis of 3D faces. InProceedings of the 26th annual conference on Computer graphics and interactive techniques, SIGGRAPH ’99, pages 187–194, USA, July 1999. ACM Press/Addison-Wesley Publishing Co
1999
-
[4]
T. Bolkart, T. Li, and M. J. Black. Instant Multi-View Head Capture through Learnable Registration, June 2023. arXiv:2306.07437 [cs]
arXiv 2023
-
[5]
M. C. B ¨uhler, K. Sarkar, T. Shah, G. Li, D. Wang, L. Helminger, S. Orts-Escolano, D. Lagun, O. Hilliges, T. Beeler, and A. Meka. Preface: A Data-driven V olumetric Prior for Few-shot Ultra High- resolution Face Synthesis, Sept. 2023. arXiv:2309.16859 [cs]
arXiv 2023
-
[6]
C. Cao, Y . Weng, S. Zhou, Y . Tong, and K. Zhou. FaceWarehouse: A 3D Facial Expression Database for Visual Computing.IEEE Transactions on Visualization and Computer Graphics, 20(3):413–425, Mar. 2014. Conference Name: IEEE Transactions on Visualization and Computer Graphics
2014
-
[7]
D. Charatan, S. Li, A. Tagliasacchi, and V . Sitzmann. pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction, Apr. 2024. arXiv:2312.12337 [cs]
arXiv 2024
-
[8]
H. Chen, C. Li, and G. H. Lee. NeuSG: Neural Implicit Surface Reconstruction with 3D Gaussian Splatting Guidance, Dec. 2023. arXiv:2312.00846 [cs]
arXiv 2023
-
[9]
P. Chen, X. Wei, Q. Wuwu, X. Wang, X. Xiao, and M. Lu. Mixedgaus- sianavatar: Realistically and geometrically accurate head avatar via mixed 2d-3d gaussians, 2025
2025
-
[10]
X. Chen, M. Mihajlovic, S. Wang, S. Prokudin, and S. Tang. Mor- phable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation, Apr. 2024. arXiv:2401.04728 [cs]
arXiv 2024
-
[11]
Y . Chen, L. Wang, Q. Li, H. Xiao, S. Zhang, H. Yao, and Y . Liu. MonoGaussianAvatar: Monocular Gaussian Point-based Head Avatar, Dec. 2023. arXiv:2312.04558 [cs]
arXiv 2023
-
[12]
Y . Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T.-J. Cham, and J. Cai. MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images. InComputer Vision – ECCV 2024, volume 15079, pages 370–386. Springer Nature Switzerland, 2025. arXiv:2403.14627 [cs]
arXiv 2024
-
[13]
X. Chu, Y . Li, A. Zeng, T. Yang, L. Lin, Y . Liu, and T. Harada. GPAvatar: Generalizable and Precise Head Avatar from Image(s), Jan
-
[14]
arXiv:2401.10215 [cs]
-
[15]
Y . Deng, D. Wang, X. Ren, X. Chen, and B. Wang. Portrait4D: Learning One-Shot 4D Head Avatar Synthesis using Synthetic Data, June 2024. arXiv:2311.18729 [cs]
arXiv 2024
- [16]
-
[17]
Y . Feng, H. Feng, M. J. Black, and T. Bolkart. Learning an animatable detailed 3D face model from in-the-wild images.ACM Trans. Graph., 40(4):88:1–88:13, July 2021
2021
-
[18]
Gafni, J
G. Gafni, J. Thies, M. Zollh ¨ofer, and M. Nießner. Dynamic Neural Radiance Fields for Monocular 4D Facial Avatar Reconstruction, Dec
-
[19]
arXiv:2012.03065 [cs]
arXiv 2012
-
[20]
J. Gao, C. Gu, Y . Lin, H. Zhu, X. Cao, L. Zhang, and Y . Yao. Relightable 3D Gaussian: Real-time Point Cloud Relighting with BRDF Decomposition and Ray Tracing, Nov. 2023. arXiv:2311.16043 [cs]
arXiv 2023
-
[21]
X. Gao, C. Zhong, J. Xiang, Y . Hong, Y . Guo, and J. Zhang. Reconstructing Personalized Semantic Facial NeRF Models From Monocular Video.ACM Transactions on Graphics, 41(6):1–12, Dec
-
[22]
arXiv:2210.06108 [cs]
-
[23]
S. Giebenhain, T. Kirschstein, M. Georgopoulos, M. R ¨unz, L. Agapito, and M. Nießner. Learning Neural Parametric Head Models, Apr. 2023. arXiv:2212.02761 [cs]
arXiv 2023
-
[24]
S. Giebenhain, T. Kirschstein, M. Georgopoulos, M. R ¨unz, L. Agapito, and M. Nießner. MonoNPHM: Dynamic Head Reconstruction from Monocular Videos, May 2024. arXiv:2312.06740 [cs]
arXiv 2024
-
[25]
S. Giebenhain, T. Kirschstein, M. R ¨unz, L. Agapito, and M. Nießner. NPGA: Neural Parametric Gaussian Avatars, Sept. 2024. arXiv:2405.19331
arXiv 2024
-
[26]
Grassal, M
P.-W. Grassal, M. Prinzler, T. Leistner, C. Rother, M. Nießner, and J. Thies. Neural Head Avatars from Monocular RGB Videos, Mar
-
[27]
arXiv:2112.01554 [cs]
-
[28]
A. Gu ´edon and V . Lepetit. SuGaR: Surface-Aligned Gaussian Splat- ting for Efficient 3D Mesh Reconstruction and High-Quality Mesh Rendering, Dec. 2023. arXiv:2311.12775 [cs]
arXiv 2023
-
[29]
Y . He, X. Gu, X. Ye, C. Xu, Z. Zhao, Y . Dong, W. Yuan, Z. Dong, and L. Bo. LAM: Large Avatar Model for One-shot Animatable Gaussian Head, Apr. 2025. arXiv:2502.17796 [cs]
arXiv 2025
-
[30]
Y . Hong, B. Peng, H. Xiao, L. Liu, and J. Zhang. Head- NeRF: A Real-time NeRF-based Parametric Head Model, Apr. 2022. arXiv:2112.05637 [cs]
arXiv 2022
- [31]
- [32]
-
[33]
R. Jena, G. S. Iyer, S. Choudhary, B. Smith, P. Chaudhari, and J. Gee. SplatArmor: Articulated Gaussian splatting for animatable humans from monocular RGB videos, Nov. 2023. arXiv:2311.10812 [cs]
arXiv 2023
- [34]
- [35]
-
[36]
H. Kim, P. Garrido, A. Tewari, W. Xu, J. Thies, M. Nießner, P. P ´erez, C. Richardt, M. Zollh ¨ofer, and C. Theobalt. Deep Video Portraits, May 2018. arXiv:1805.11714 [cs]
Pith/arXiv arXiv 2018
-
[37]
T. Kirschstein, S. Giebenhain, and M. Nießner. DiffusionAvatars: Deferred Diffusion for High-fidelity 3D Head Avatars, Apr. 2024. arXiv:2311.18635 [cs]
arXiv 2024
-
[38]
T. Kirschstein, S. Giebenhain, J. Tang, M. Georgopoulos, and M. Nießner. GGHead: Fast and Generalizable 3D Gaussian Heads. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, Dec. 2024. arXiv:2406.09377 [cs]
arXiv 2024
-
[39]
T. Kirschstein, S. Qian, S. Giebenhain, T. Walter, and M. Nießner. NeRSemble: Multi-view Radiance Field Reconstruction of Human Heads.ACM Transactions on Graphics, 42(4):1–14, Aug. 2023. arXiv:2305.03027 [cs]
arXiv 2023
-
[40]
J. Lee, T. Kang, M. C. B ¨uhler, M.-J. Kim, S. Hwang, J. Hyung, H. Jang, and J. Choo. SurFhead: Affine Rig Blending for Geo- metrically Accurate 2D Gaussian Surfel Head Avatars, Apr. 2025. arXiv:2410.11682 [cs]
arXiv 2025
-
[41]
L. Li, Y . Li, Y . Weng, Y . Zheng, and K. Zhou. RGBAvatar: Reduced Gaussian Blendshapes for Online Modeling of Head Avatars, Mar
-
[42]
arXiv:2503.12886 [cs] version: 1
-
[43]
T. Li, T. Bolkart, M. J. Black, H. Li, and J. Romero. Learning a model of facial shape and expression from 4D scans.ACM Transactions on Graphics, 36(6):1–17, Dec. 2017
2017
-
[44]
S. Lombardi, T. Simon, G. Schwartz, M. Zollhoefer, Y . Sheikh, and J. Saragih. Mixture of V olumetric Primitives for Efficient Neural Rendering, May 2021. arXiv:2103.01954 [cs]
arXiv 2021
-
[45]
W. Lyu, Y . Zhou, M.-H. Yang, and Z. Shu. FaceLift: Learning Generalizable Single Image 3D Face Reconstruction from Synthetic Heads, Aug. 2025. arXiv:2412.17812 [cs]
arXiv 2025
-
[46]
X. Lyu, Y .-T. Sun, Y .-H. Huang, X. Wu, Z. Yang, Y . Chen, J. Pang, and X. Qi. 3DGSR: Implicit Surface Reconstruction with 3D Gaussian Splatting, Mar. 2024. arXiv:2404.00409 [cs]
arXiv 2024
-
[47]
S. Ma, T. Simon, J. Saragih, D. Wang, Y . Li, F. D. L. Torre, and Y . Sheikh. Pixel Codec Avatars, Apr. 2021. arXiv:2104.04638 [cs]
arXiv 2021
-
[48]
S. Ma, Y . Weng, T. Shao, and K. Zhou. 3D Gaussian Blendshapes for Head Avatar Animation. InSpecial Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers ’24, pages 1–10, July 2024. arXiv:2404.19398 [cs]
arXiv 2024
-
[49]
G. Moon, W. Xu, R. Joshi, C. Wu, and T. Shiratori. Authentic Hand Avatar from a Phone Scan via Universal Hand Model, May 2024. arXiv:2405.07933 [cs] version: 1
arXiv 2024
-
[50]
M ¨uller
T. M ¨uller. tiny-cuda-nn, Apr. 2021. original-date: 2021-04- 16T17:53:10Z
2021
-
[51]
D. Pan, L. Zhuo, J. Piao, H. Luo, W. Cheng, Y . Wang, S. Fan, S. Liu, L. Yang, B. Dai, Z. Liu, C. C. Loy, C. Qian, W. Wu, D. Lin, and K.-Y . Lin. RenderMe-360: A Large Digital Asset Library and Benchmarks Towards High-fidelity Head Avatars, May 2023. arXiv:2305.13353 [cs]
arXiv 2023
-
[52]
K. Park, U. Sinha, J. T. Barron, S. Bouaziz, D. B. Goldman, S. M. Seitz, and R. Martin-Brualla. Nerfies: Deformable Neural Radiance Fields, Sept. 2021. arXiv:2011.12948 [cs]. 9
arXiv 2021
-
[53]
K. Park, U. Sinha, P. Hedman, J. T. Barron, S. Bouaziz, D. B. Goldman, R. Martin-Brualla, and S. M. Seitz. HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields, Sept. 2021. arXiv:2106.13228 [cs]
arXiv 2021
-
[54]
G. Pavlakos, V . Choutas, N. Ghorbani, T. Bolkart, A. A. A. Osman, D. Tzionas, and M. J. Black. Expressive Body Capture: 3D Hands, Face, and Body from a Single Image, Apr. 2019. arXiv:1904.05866 [cs]
Pith/arXiv arXiv 2019
-
[55]
A. Pumarola, E. Corona, G. Pons-Moll, and F. Moreno-Noguer. D- NeRF: Neural Radiance Fields for Dynamic Scenes, Nov. 2020. arXiv:2011.13961 [cs]
arXiv 2020
-
[56]
S. Qian. Vhap: Versatile head alignment with adaptive appearance priors, sep 2024
2024
-
[57]
S. Qian, T. Kirschstein, L. Schoneveld, D. Davoli, S. Giebenhain, and M. Nießner. GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians, Mar. 2024. arXiv:2312.02069 [cs]
arXiv 2024
-
[58]
A. Ranjan, T. Bolkart, S. Sanyal, and M. J. Black. Generat- ing 3D faces using Convolutional Mesh Autoencoders, July 2018. arXiv:1807.10267 [cs]
Pith/arXiv arXiv 2018
-
[59]
Y . Ren, G. Li, Y . Chen, T. H. Li, and S. Liu. PIRenderer: Controllable Portrait Image Generation via Semantic Neural Rendering, Sept. 2021. arXiv:2109.08379 [cs]
arXiv 2021
-
[60]
J. Saunders, C. Hewitt, Y . Jian, M. Kowalski, T. Baltrusaitis, Y . Chen, D. Cosker, V . Estellers, N. Gyde, V . P. Namboodiri, and B. E. Lundell. GASP: Gaussian Avatars with Synthetic Priors, Dec. 2024. arXiv:2412.07739 [cs]
arXiv 2024
-
[61]
Schoneveld, Z
L. Schoneveld, Z. Chen, D. Davoli, J. Tang, S. Terazawa, K. Nishino, and M. Nießner. Sheap: Self-supervised head geometry predictor learned via 2d gaussians, 2025
2025
-
[62]
A. Siarohin, S. Lathuili `ere, S. Tulyakov, E. Ricci, and N. Sebe. First Order Motion Model for Image Animation, Oct. 2020. arXiv:2003.00196 [cs]
arXiv 2020
-
[63]
J. Tang, D. Davoli, T. Kirschstein, L. Schoneveld, and M. Niessner. GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion, Apr. 2025. arXiv:2412.10209 [cs]
arXiv 2025
- [64]
-
[65]
A. Tewari, M. Zollh ¨ofer, H. Kim, P. Garrido, F. Bernard, P. P ´erez, and C. Theobalt. MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction, Dec. 2017. arXiv:1703.10580 [cs]
Pith/arXiv arXiv 2017
-
[66]
D. Wang, P. Chandran, G. Zoss, D. Bradley, and P. Gotardo. MoRF: Morphable Radiance Fields for Multiview Neural Head Modeling. In ACM SIGGRAPH 2022 Conference Proceedings, SIGGRAPH ’22, pages 1–9, New York, NY , USA, July 2022. Association for Com- puting Machinery
2022
-
[67]
J. Wang, J.-C. Xie, X. Li, F. Xu, C.-M. Pun, and H. Gao. Gaussian- Head: High-fidelity Head Avatars with Learnable Gaussian Derivation, May 2024. arXiv:2312.01632 [cs]
arXiv 2024
-
[68]
L. Wang, Z. Chen, T. Yu, C. Ma, L. Li, and Y . Liu. FaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset, May 2022. arXiv:2203.14057 [cs]
arXiv 2022
-
[69]
P. Wang, L. Liu, Y . Liu, C. Theobalt, T. Komura, and W. Wang. NeuS: Learning Neural Implicit Surfaces by V olume Rendering for Multi- view Reconstruction, Feb. 2023. arXiv:2106.10689 [cs]
Pith/arXiv arXiv 2023
-
[70]
Y . Wang, Q. Han, M. Habermann, K. Daniilidis, C. Theobalt, and L. Liu. NeuS2: Fast Learning of Neural Implicit Surfaces for Multi- view Reconstruction, Nov. 2023. arXiv:2212.05231 [cs]
arXiv 2023
-
[71]
O. Wiles, A. S. Koepke, and A. Zisserman. X2Face: A network for controlling face generation by using images, audio, and pose codes, July 2018. arXiv:1807.10550 [cs]
Pith/arXiv arXiv 2018
- [72]
-
[73]
Y . Xu, B. Chen, Z. Li, H. Zhang, L. Wang, Z. Zheng, and Y . Liu. Gaussian Head Avatar: Ultra High-fidelity Head Avatar via Dynamic Gaussians, Mar. 2024. arXiv:2312.03029 [cs]
arXiv 2024
-
[74]
Y . Xu, Z. Su, Q. Wu, and Y . Liu. GPHM: Gaussian Parametric Head Model for Monocular Head Avatar Reconstruction, Oct. 2024. arXiv:2407.15070 [cs]
arXiv 2024
-
[75]
Y . Xu, L. Wang, X. Zhao, H. Zhang, and Y . Liu. AvatarMA V: Fast 3D Head Avatar Reconstruction Using Motion-Aware Neural V oxels. InSpecial Interest Group on Computer Graphics and Interactive Techniques Conference Conference Proceedings, pages 1–10, July
-
[76]
arXiv:2211.13206 [cs]
-
[77]
Y . Yan, Z. Zhou, Z. Wang, J. Gao, and X. Yang. DialogueNeRF: To- wards Realistic Avatar Face-to-Face Conversation Video Generation, Aug. 2023. arXiv:2203.07931 [cs]
arXiv 2023
-
[78]
G. Yang, S. Belongie, B. Hariharan, and V . Koltun. Geometry Process- ing with Neural Fields. InAdvances in Neural Information Processing Systems, volume 34, pages 22483–22497. Curran Associates, Inc., 2021
2021
-
[79]
H. Yang, M. Zheng, C. Ma, Y .-K. Lai, P. Wan, and H. Huang. VRMM: A V olumetric Relightable Morphable Head Model. InSpecial Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers ’24, pages 1–11, July 2024. arXiv:2402.04101 [cs]
arXiv 2024
-
[80]
T. Yenamandra, A. Tewari, F. Bernard, H.-P. Seidel, M. Elgharib, D. Cremers, and C. Theobalt. i3DMM: Deep Implicit 3D Morphable Model of Human Heads, Nov. 2020. arXiv:2011.14143 [cs]
arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.