SEED: Simple ViT and Evolving Harness for Explainable Text Forgery Detection
Pith reviewed 2026-06-26 14:35 UTC · model grok-4.3
The pith
A single LoRA-adapted ViT plus evolving MLLM harness detects, localizes, and explains text forgeries in images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
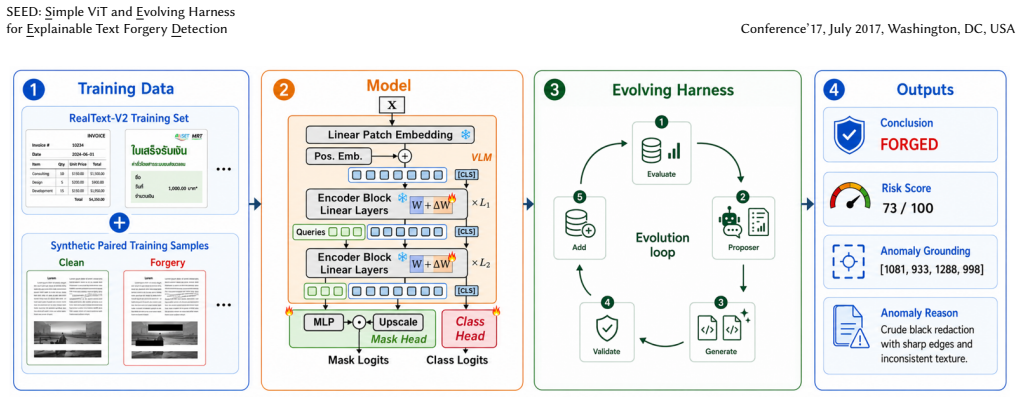
SEED shows that a similarity-guided augmentation pipeline, a single LoRA-adapted ViT built on DINOv3, and an evolving MLLM harness with a proposer-evaluator loop can jointly perform detection, pixel-level localization, and generation of complete multilingual forensic reports for text-centric forgeries.
What carries the argument
The evolving harness that iteratively refines MLLM-generated reports by running a proposer-evaluator loop on the detector outputs.
If this is right
- The single ViT can jointly output detection scores and pixel-level masks while keeping most pre-trained weights frozen.
- Similarity-guided augmentation supplies enough varied synthetic forgeries to train the detector without large external datasets.
- The modular design separates the vision detection stage from the language explanation stage, allowing each to be updated independently.
- The full pipeline produces the structured reports required by the GenText-Forensics Challenge.
Where Pith is reading between the lines
- The same modular split between a lightweight detector and an iterative language stage could be tested on other image-manipulation tasks that need both localization and explanation.
- If the proposer-evaluator loop generalizes, it could reduce reliance on hand-crafted prompts when turning model outputs into human-readable forensic text.
- Because the vision model uses minimal adaptation, the approach might scale to larger pre-trained backbones without proportional increases in training cost.
Load-bearing premise
The proposer-evaluator loop inside the evolving harness reliably improves the quality of the natural-language forensic reports.
What would settle it
An external human evaluation of the generated reports on a new set of forgery images, scored independently of the challenge metric, would show whether the loop adds measurable quality.
Figures


read the original abstract
AI-assisted image editing threatens trust in financial, legal, and identity records. The GenText-Forensics Challenge at ACM MM 2026 addresses this by requiring structured forensic reports, in which integrating detection, pixel-level localization, and natural language explanation for multilingual text-centric forgery images. We present SEED, a modular system with three components. First, a similarity-guided pipeline augments training with diverse synthetic forgeries. Second, a single ViT, built on DINOv3 with LoRA adaptation, jointly performs detection and pixel-level localization while preserving pre-trained priors with minimal trainable parameters. Third, an evolving harness takes the detector's predictions and generates a complete forensic report via an MLLM, iteratively improved through a proposer-evaluator loop optimizing report quality. SEED ranked 3rd in the GenText-Forensics Challenge. Code and data are available at https://github.com/KahimWong/GenText-Forensics-3rd-Place.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SEED, a modular pipeline for explainable text forgery detection consisting of (1) a similarity-guided augmentation pipeline to create diverse synthetic forgeries, (2) a single LoRA-adapted ViT (DINOv3 backbone) that jointly performs binary detection and pixel-level localization while preserving pre-trained priors, and (3) an evolving MLLM harness that iteratively refines forensic reports via a proposer-evaluator loop. The system is reported to have placed 3rd in the GenText-Forensics Challenge at ACM MM 2026; code and data are released.
Significance. If the ranking can be attributed to the described components, the work would be significant for efficient, low-parameter forgery detection and localization in text-centric images together with the generation of structured natural-language explanations. The competition outcome supplies external validation of the end-to-end system, and public code release is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract and experimental description: the central claim that the full pipeline (including the evolving harness) produced the 3rd-place ranking is asserted without any reported quantitative metrics, ablation tables, or error analysis that would isolate the contribution of each module.
- [Evolving harness description] Evolving harness section: the claim that the proposer-evaluator loop improves report quality rests exclusively on the challenge’s internal natural-language explanation scores; no ablation against a non-iterative MLLM baseline or external human forensic evaluation is provided, leaving the explanatory component of the title unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger isolation of component contributions. We agree that the current manuscript lacks explicit ablations and will revise to address this where feasible. Responses to each major comment follow.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental description: the central claim that the full pipeline (including the evolving harness) produced the 3rd-place ranking is asserted without any reported quantitative metrics, ablation tables, or error analysis that would isolate the contribution of each module.
Authors: We agree that the manuscript does not report ablations or error analysis that isolate the contribution of the similarity-guided augmentation, the LoRA ViT detector, or the evolving harness to the final 3rd-place ranking. The ranking reflects end-to-end system performance in the challenge. In revision we will add ablation tables using the challenge metrics to quantify the effect of removing or replacing each module. revision: yes
-
Referee: [Evolving harness description] Evolving harness section: the claim that the proposer-evaluator loop improves report quality rests exclusively on the challenge’s internal natural-language explanation scores; no ablation against a non-iterative MLLM baseline or external human forensic evaluation is provided, leaving the explanatory component of the title unsupported.
Authors: The iterative loop's benefit is supported only by the challenge's internal explanation scores for the submitted system. No non-iterative MLLM ablation or external human evaluation appears in the manuscript. We will add a non-iterative MLLM baseline comparison in the revision. External human forensic evaluation was not performed and cannot be supplied without new annotation effort. revision: partial
- External human forensic evaluation of the generated reports, which was outside the original challenge protocol and would require new resources.
Circularity Check
No circularity: external competition ranking and modular system description
full rationale
The paper presents an engineering system (similarity-guided augmentation, LoRA-adapted ViT detector, evolving MLLM harness) whose primary claim is a 3rd-place ranking in the GenText-Forensics Challenge. This ranking is an external, independent outcome rather than an internally derived prediction. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the text. The harness improvement is asserted via challenge scoring, but this does not reduce to a self-definitional or constructionally forced result. The derivation chain is self-contained against the external benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhongxi Chen, Shen Chen, Taiping Yao, Ke Sun, Shouhong Ding, Xianming Lin, Liujuan Cao, and Rongrong Ji. 2024. Enhancing tampered text detection through frequency feature fusion and decomposition. InProc. Eur. Conf. Comput. Vis. 200–217
2024
-
[2]
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. 2022. Masked-attention mask transformer for universal image segmen- tation. InProc. IEEE Comput. Vis. Pattern Recogn.1290–1299
2022
- [3]
-
[4]
Li Dong, Weipeng Liang, and Rangding Wang. 2024. Robust text image tampering localization via forgery traces enhancement and multiscale attention.IEEE Trans. Consum. Electron.(2024), 3495–3507
2024
-
[5]
Bo Du, Xuekang Zhu, Xiaochen Ma, Chenfan Qu, Kaiwen Feng, Zhe Yang, Chi- Man Pun, Jian Liu, and Ji-Zhe Zhou. 2025. Forensichub: A unified benchmark & codebase for all-domain fake image detection and localization. InAdv. Neural Inf. Process. Syst
2025
-
[6]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InProc. Int. Conf. Learn. Representat
2022
-
[7]
Xuan Ju, Xian Liu, Xintao Wang, Yuxuan Bian, Ying Shan, and Qiang Xu. 2024. Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion. InProc. Eur. Conf. Comput. Vis.150–168
2024
-
[8]
Tommie Kerssies, Niccolo Cavagnero, Alexander Hermans, Narges Norouzi, Giuseppe Averta, Bastian Leibe, Gijs Dubbelman, and Daan De Geus. 2025. Your vit is secretly an image segmentation model. InProc. IEEE Comput. Vis. Pattern Recogn.25303–25313
2025
-
[9]
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. 2026. Meta-harness: End-to-end optimization of model harnesses. arXiv preprint arXiv:2603.28052(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Kemou Li, Qizhou Wang, Yue Wang, Fengpeng Li, Jun Liu, Bo Han, and Jiantao Zhou. 2026. LLM Unlearning with LLM Beliefs. InProc. Int. Conf. Learn. Repre- sentat
2026
-
[11]
Dongliang Luo, Yuliang Liu, Rui Yang, Xianjin Liu, Jishen Zeng, Yu Zhou, and Xiang Bai. 2025. Toward real text manipulation detection: New dataset and new solution.Pattern Recognition(2025), 110828
2025
-
[12]
GenText-Forensics Organizers. 2026. GenText-Forensics: Challenge on Explain- able Forensics and Adversarial Generation for Text-Centric Images. ACM Multi- media 2026 Challenge. https://gentext-forensics-acm-mm-2026.github.io/
2026
-
[13]
Chenfan Qu, Chongyu Liu, Yuliang Liu, Xinhong Chen, Dezhi Peng, Fengjun Guo, and Lianwen Jin. 2023. Towards robust tampered text detection in document image: New dataset and new solution. InProc. IEEE Comput. Vis. Pattern Recogn. 5937–5946
2023
-
[14]
Chenfan Qu, Yiwu Zhong, Fengjun Guo, and Lianwen Jin. 2025. Revisiting tampered scene text detection in the era of generative AI. InProc. AAAI Conf. Arti. Intell.694–702
2025
-
[15]
Chenfan Qu, Yiwu Zhong, Jian Liu, Xuekang Zhu, Bohan Yu, and Lianwen Jin
-
[16]
Textshield-r1: Reinforced reasoning for tampered text detection. InProc. AAAI Conf. Arti. Intell.8621–8629
-
[17]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proc. IEEE Comput. Vis. Pattern Recogn.10684–10695
2022
-
[18]
Oriane Siméoni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Rama- monjisoa, et al. 2025. Dinov3.arXiv preprint arXiv:2508.10104(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Yalin Song, Wenbin Jiang, Xiuli Chai, Zhihua Gan, Mengyuan Zhou, and Lei Chen. 2025. Cross-attention based two-branch networks for document image forgery localization in the metaverse.ACM Trans. Multimedia Comput. Commun. Appl.(2025), 1–24
2025
-
[20]
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. 2022. Resolution-robust large mask inpainting with fourier convolutions. InProc. IEEE/CVF Winter Conf. Appl. Comput. Vis. (W ACV). 2149–2159
2022
-
[21]
Yuxiang Tuo, Wangmeng Xiang, Jun-Yan He, Yifeng Geng, and Xuansong Xie
-
[22]
Anytext: Multilingual visual text generation and editing. InProc. Int. Conf. Learn. Representat.56783–56799
-
[23]
Yuxin Wang, Hongtao Xie, Mengting Xing, Jing Wang, Shenggao Zhu, and Yongdong Zhang. 2022. Detecting tampered scene text in the wild. InProc. Eur. Conf. Comput. Vis.215–232
2022
-
[24]
Yuxin Wang, Boqiang Zhang, Hongtao Xie, and Yongdong Zhang. 2022. Tampered text detection via RGB and frequency relationship modeling.Chin. J. Netw. Inf. Secur.(2022), 29–40
2022
-
[25]
Kahim Wong, Kemou Li, Haiwei Wu, and Jiantao Zhou. 2026.𝑘 NNProxy: Efficient Training-Free Proxy Alignment for Black-Box Zero-Shot LLM-Generated Text Detection.arXiv preprint arXiv:2604.02008(2026)
-
[26]
Kahim Wong, Jicheng Zhou, Kemou Li, Yain-Whar Si, Xiaowei Wu, and Jiantao Zhou. 2025. FontGuard: A Robust Font Watermarking Approach Leveraging Deep Font Knowledge.IEEE Trans. Multimedia(2025), 7876–7890
2025
-
[27]
Kahim Wong, Jicheng Zhou, Haiwei Wu, Yain-Whar Si, and Jiantao Zhou. 2025. ADCD-Net: Robust Document Image Forgery Localization via Adaptive DCT Fea- ture and Hierarchical Content Disentanglement. InProc. IEEE Int. Conf. Comput. Vis.19280–19289
2025
-
[28]
Ka Him Wong, Jicheng Zhou, Jiantao Zhou, and Yain-Whar Si. 2025. An End-to- End Model for Logits-Based Large Language Models Watermarking. InProc. Int. Conf. Mach. Learn.66971–66991
2025
-
[29]
Haiwei Wu, Fengpeng Li, Zhilin Tu, Yuanman Li, Xiong Li, and Jiantao Zhou
-
[30]
Zero-shot Detection of AI-Generated Image via RAW-RGB Alignment. In Proc. IEEE Comput. Vis. Pattern Recogn.42997–43007
-
[31]
Haiwei Wu, Kemou Li, Yuanman Li, and Jiantao Zhou. 2026. Editprint: General digital image forensics via editing fingerprint with self-augmentation training. InProc. IEEE Comput. Vis. Pattern Recogn.35483–35493
2026
-
[32]
Zhiyuan Yan, Jiangming Wang, Peng Jin, Ke-Yue Zhang, Chengchun Liu, Shen Chen, Taiping Yao, Shouhong Ding, Baoyuan Wu, and Li Yuan. 2025. Orthogonal subspace decomposition for generalizable ai-generated image detection. InProc. Int. Conf. Mach. Learn.70268–70288. ,
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.