Advancing DialNav through Automatic Embodied Dialog Augmentation
Pith reviewed 2026-06-26 17:26 UTC · model grok-4.3
The pith
An automatic pipeline converts VLN datasets into 238K multi-turn dialog episodes, enabling Dual-Strategy Training and a VLN-based localization model to reach new state-of-the-art success rates on DialNav.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
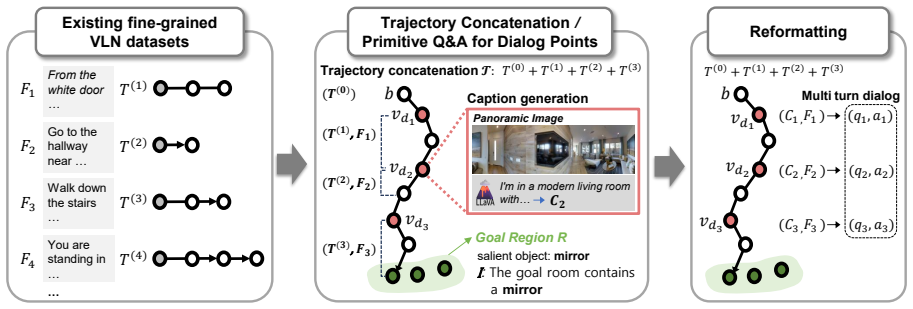
The central claim is that converting VLN datasets into multi-turn embodied dialogs via an automatic pipeline yields the RAINbow dataset of 238K episodes, and that pairing this data with Dual-Strategy Training and a localization model leveraging VLN knowledge produces success rates of 58.24 (+89%) on Val Seen and 29.05 (+100%) on Val Unseen, establishing a new state of the art for DialNav.
What carries the argument
The automatic generation pipeline that converts existing VLN datasets into multi-turn dialog episodes for the RAINbow dataset, together with Dual-Strategy Training and a VLN-leveraging localization model.
If this is right
- Embodied agents achieve substantially higher success rates when dialog and navigation are trained together rather than separately.
- Data scarcity for dialog-execution loops in photorealistic navigation can be addressed by automatic conversion of existing VLN resources.
- Localization performance improves when models retain access to VLN knowledge inside the dialog setting.
- The new dataset size supports training that generalizes better to unseen environments.
Where Pith is reading between the lines
- The same conversion pipeline could be applied to other embodied tasks that combine language and physical action to reduce their data requirements.
- Human evaluation of a sample of the generated dialogs would provide an independent check on whether quality matches the reported performance gains.
- Further scaling of the pipeline might allow training on millions of episodes and reveal whether gains continue to increase with data volume.
Load-bearing premise
The dialogs produced by the automatic pipeline are high-quality enough and representative enough of real dialog-navigation interactions to train models that generalize.
What would settle it
If a model trained on RAINbow episodes shows no comparable gains when tested on a fresh collection of human-generated multi-turn dialog navigation episodes, the claim that the pipeline supplies effective training data would be falsified.
Figures











read the original abstract
For embodied agents capable of physical interaction, the capability to create and understand dialog is crucial to ensure both safety and effectiveness. While DialNav~\cite{han2025dialnav} provides a framework for holistic evaluation of the dialog--execution loop in photorealistic indoor navigation, its performance remains limited by a critical scarcity of training data (2K episodes). To address this, we propose an automatic generation pipeline, and construct the \textbf{RAINbow} dataset, a large-scale training dataset with 238K episodes for DialNav. Our pipeline converts existing VLN datasets into multi-turn dialog and creates cost-efficient and high-quality dataset. Then, we introduce two additional complementary advances to unlock the data's full potential: (1) Dual-Strategy Training, a navigation training scheme to align the navigation training with the dynamic dialog-navigation loop, and (2) a localization model that leverages VLN knowledge. By combining these complementary solutions, our model substantially outperforms the baseline in success rate on both \textbf{Val Seen} (58.24, \textbf{+89\%}) and \textbf{Val Unseen} (29.05, \textbf{+100\%}) splits, establishing a new state of the art.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an automatic pipeline can convert existing VLN datasets into a large-scale multi-turn dialog dataset (RAINbow, 238K episodes) for DialNav, and that combining this data with Dual-Strategy Training and a VLN-leveraging localization model yields large gains over the DialNav baseline: success rate 58.24 (+89%) on Val Seen and 29.05 (+100%) on Val Unseen, establishing a new state of the art.
Significance. If the generated dialogs prove high-quality and the reported gains hold under rigorous controls, the work would address a genuine data-scarcity bottleneck in embodied dialog navigation and demonstrate a scalable augmentation approach. The scale of RAINbow (238K episodes) would be a concrete asset for the community if accompanied by reproducible generation code and validation.
major comments (2)
- [Abstract] Abstract: The central claim that the pipeline 'creates cost-efficient and high-quality dataset' is load-bearing for all reported gains, yet the manuscript supplies no human evaluation, dialog-trajectory alignment metrics, turn-taking fidelity checks, or artifact analysis for the generated multi-turn dialogs. Without these, it is impossible to rule out that the Dual-Strategy Training and localization model are fitting to pipeline artifacts rather than genuine dialog-execution loops.
- [Abstract] Abstract / experimental results: The headline improvements (+89% Val Seen, +100% Val Unseen) are presented without error bars, baseline re-implementation details, data-split statistics, or ablation isolating the contribution of the 238K episodes versus the two new training components. This omission prevents verification that the numbers reflect genuine generalization rather than uncontrolled variance.
minor comments (1)
- [Abstract] The abstract cites DialNav as han2025dialnav but provides no expanded reference list or comparison table placing the new numbers against prior DialNav results.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the concerns about the validation of the automatically generated RAINbow dataset and the reporting of experimental results below. We plan to incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] The central claim that the pipeline 'creates cost-efficient and high-quality dataset' is load-bearing for all reported gains, yet the manuscript supplies no human evaluation, dialog-trajectory alignment metrics, turn-taking fidelity checks, or artifact analysis for the generated multi-turn dialogs. Without these, it is impossible to rule out that the Dual-Strategy Training and localization model are fitting to pipeline artifacts rather than genuine dialog-execution loops.
Authors: We acknowledge that explicit validation of the generated dialogs would strengthen the claims. The substantial gains on the Val Unseen split (doubling the success rate) provide indirect evidence that the dialogs enable genuine generalization rather than overfitting to artifacts. Nevertheless, to directly address this, we will include human evaluations of dialog quality, metrics for dialog-trajectory alignment, and analysis of potential artifacts in the revised version. revision: yes
-
Referee: [Abstract] Abstract / experimental results: The headline improvements (+89% Val Seen, +100% Val Unseen) are presented without error bars, baseline re-implementation details, data-split statistics, or ablation isolating the contribution of the 238K episodes versus the two new training components. This omission prevents verification that the numbers reflect genuine generalization rather than uncontrolled variance.
Authors: We agree that additional experimental details are necessary for rigorous verification. In the revision, we will report error bars from multiple random seeds, provide full details on baseline re-implementations, include data-split statistics, and present ablations that isolate the contributions of the RAINbow dataset, Dual-Strategy Training, and the localization model separately. revision: yes
Circularity Check
No circularity: empirical results on standard splits with independent dataset construction
full rationale
The paper reports measured success rates on Val Seen and Val Unseen splits of an existing VLN benchmark after constructing a new training set via an automatic pipeline. No equations, fitted parameters, or self-referential definitions are presented that would make the reported gains equivalent to the inputs by construction. The cited DialNav framework provides the evaluation setting but is not invoked as a uniqueness theorem or load-bearing premise that forces the outcome. The performance numbers are external measurements, not renamings or predictions derived from the pipeline itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Matterport3D: Learning from RGB-D Data in Indoor Environments
The robotslang benchmark: Dialog-guided robot localization and navigation. InConference on Robot Learning, pages 1384–1393. PMLR. Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. 2017. Matter- port3d: Learning from rgb-d data in indoor environ- ments.arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Where are you? localization from embodied dialog.arXiv preprint arXiv:2011.08277. Meera Hahn and James M Rehg. 2022. Transformer- based localization from embodied dialog with large- scale pre-training.arXiv preprint arXiv:2210.04864. Leekyeung Han, Hyunji Min, Gyeom Hwangbo, Jonghyun Choi, and Paul Hongsuck Seo. 2025. Di- alnav: Multi-turn dialog navigati...
-
[3]
For CVDN dataset, we use its answer and pair its path with the next 5 shortest path from the question node based on its data collecton description
We concatenated 2-4 trajectories from R2R (Anderson et al., 2018), RxR (Ku et al., 2020), CVDN (Thomason et al., 2020) answer trajectories into a single episode. For CVDN dataset, we use its answer and pair its path with the next 5 shortest path from the question node based on its data collecton description
2018
-
[4]
The endpoint of one trajectory and the start of the next must be within 1 meter in the naviga- tion graph
-
[5]
To prevent overly circuitous paths, the detour ratio, the concatenated path length divided by the shortest path length between the start and end nodes, was constrained to be less than 1.3. Dataset Task Size Total Cost Cost/Ep Source CerealBar (Suhr et al., 2019) Game 1K $5.8K $5.80 Human IGLU (Kiseleva et al., 2022) Game 8.9K - - Human HoloAssist (Wang et...
2019
-
[6]
Episodes in which the goal region contained no selectable object were discarded
-
[7]
To avoid overly generic references, we excluded a predefined set of objects (e.g.,wall,floor,ceiling, etc.)
The ambiguous instruction I was derived from the Matterport3D (Chang et al., 2017) meta- data by randomly selecting one visible object in the goal region. To avoid overly generic references, we excluded a predefined set of objects (e.g.,wall,floor,ceiling, etc.)
2017
-
[8]
post-goal
Since goal regions in DialNav correspond to rooms rather than single nodes, we excluded cases where the agent had already reached the goal room before subsequent dialog turns were appended, avoiding unnatural “post-goal” interactions
-
[9]
We consider three types of variations:mislocalization,mis- navigation, andexploration
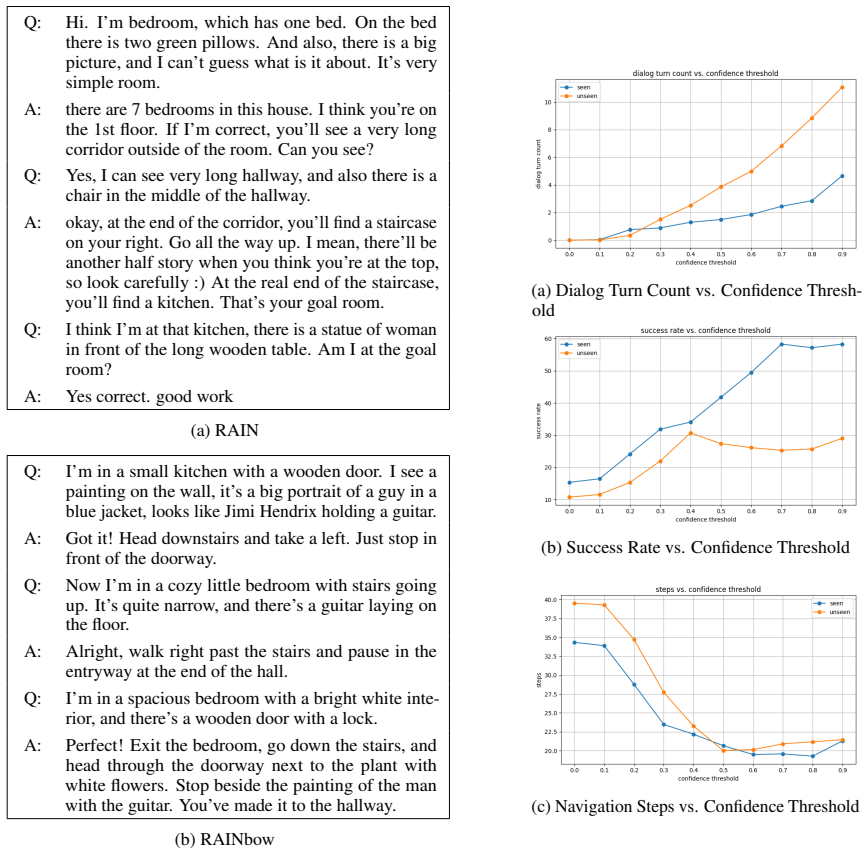
To further increase diversity, we addition- ally introduced variations in 10% of the con- structed episodes, simulating potential devia- tions in real dialog navigation. We consider three types of variations:mislocalization,mis- navigation, andexploration. In the case of mislocalization, the Guide intentionally pro- vides an incorrect path description tha...
-
[10]
Our aim was to ensure that the resulting utter- ances contained sufficient local detail for Guide- side localization, while generating diverse content even for the same node
for visual description and Llama-3.1-8B for text synthesis with different visual/textual contexts. Our aim was to ensure that the resulting utter- ances contained sufficient local detail for Guide- side localization, while generating diverse content even for the same node. We experimented with three variants and randomly used one of these schemes for capt...
-
[11]
You have reached your destination
Instruction Refining.First, we refine the raw VLN instructions. We prompt the LLM to make each instruction concise while preserv- ing key spatial references, preventing overly verbose text that is unnatural in conversation. Moreover, since the original VLN instructions are for single-turn tasks, they often prema- turely mention reaching the final goal. To...
-
[12]
you have to go to the dining room
Conversational Smoothing.We then con- struct a draft dialog by sequencing the orig- inal scene captions and their corresponding refined, goal-conditioned instructions (from Step 1). This entire sequence is then para- phrased by GPT-4o-mini into fluent, conver- sational language, resulting in the final multi- turn dialog. This step retains all navigation- ...
2020
-
[13]
with_goal: A version that includes reaching the final destination
-
[14]
Ok", "Alright
without_goal: A version that excludes any mention of reaching the destination Both versions should: - Be concise while preserving key spatial references - Focus on objects, rooms, and layout - Use directions only when necessary - Remove terms implying current situation (Start facing , You’re in a , You’re facing) For with_goal version, Always mention that...
-
[15]
Keep the same number of turns and same speakers (Navigator/Guide)
-
[16]
Do not add or remove turns
-
[17]
Do not add new objects, rooms, or details not in input
-
[18]
You’re looking at
Never use phrases like "You’re looking at. . . " or "You are facing. . . ". - Instead: ask questions ("Do you see. . . ?") or omit
-
[19]
Do not drop or shorten navigation instructions
-
[20]
- Room names and types
Preserve all key details: - Objects and attributes (color, shape, material). - Room names and types. - Spatial relations and directions
-
[21]
and". OUTPUT FORMAT: Return ONLY valid JSON:
Do not use em dashes (—). Use commas, periods, or "and". OUTPUT FORMAT: Return ONLY valid JSON: "reformatted": [ "Navigator": "...", "Guide": "..." , "Navigator": "...", "Guide": "..." ] No extra text, no markdown, no explanations. (b) Prompt template for natural dialog reformatting. Figure 12: Prompt for dialog reformatting. Example Original Instruction ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.