SBM With Multiple Samples: Improved Spectral Recovery
Pith reviewed 2026-06-25 21:58 UTC · model grok-4.3
The pith
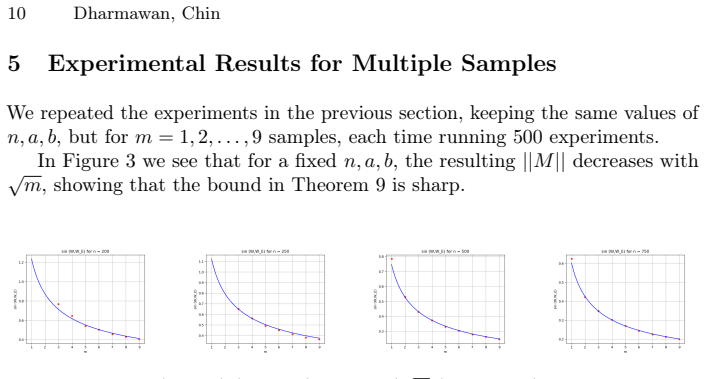
Averaging m independent samples from the two-block stochastic block model improves the spectral recovery threshold by a factor of m.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
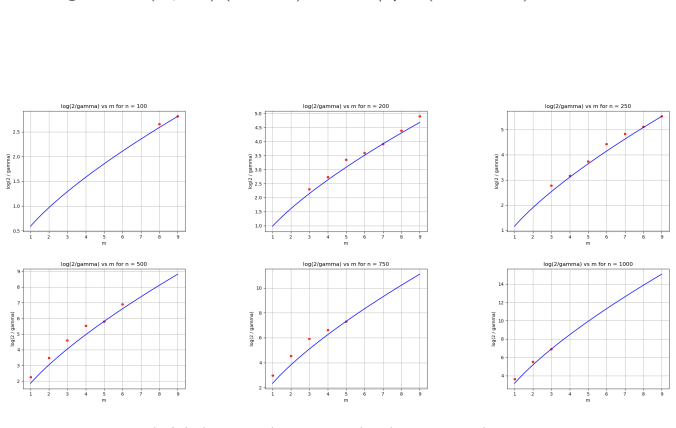
Averaging m independent adjacency matrices from the two-block SBM and then applying spectral partitioning produces a gamma-correct partition with high probability whenever (a-b)^2/(a+b) is at least (C/m) log(2/gamma). The argument rests on a multi-sample analogue of the spectral norm bound for the centered noise matrix that feeds directly into the Davis-Kahan theorem.
What carries the argument
The multi-sample analogue of the spectral norm bound on the noise matrix, which replaces the single-sample bound inside the Davis-Kahan subspace angle analysis while keeping adjacency entries independent.
If this is right
- The minimum signal strength required for reliable recovery decreases linearly with the number of independent samples.
- Even two or three samples produce large gains in the probability of correct partition recovery.
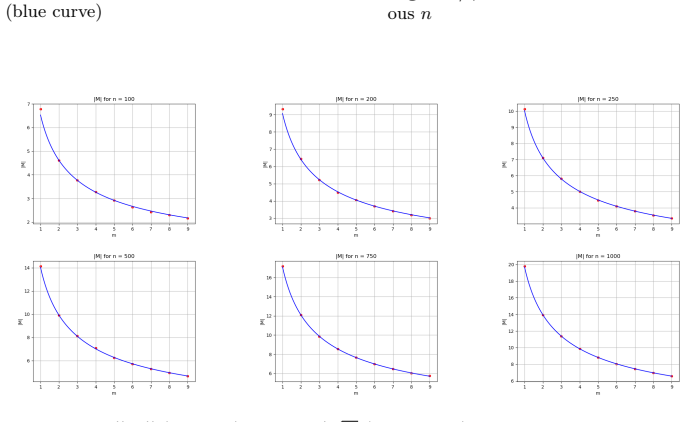
- The derived bounds match observed behavior in simulations up to n=1000 and m=9.
- The same averaging step supplies a rigorous justification for data-augmentation techniques that duplicate graph observations.
Where Pith is reading between the lines
- Collecting a modest number of repeated network observations could substitute for collecting a much larger single graph in some regimes.
- The same averaging-plus-spectral strategy may extend to other models where a noise-norm bound is already available.
- Practitioners could use the 1/m scaling to decide how many independent samples are worth acquiring before running community detection.
Load-bearing premise
A multi-sample version of the spectral norm bound on the noise matrix exists and carries through the Davis-Kahan argument to produce exactly the stated 1/m improvement.
What would settle it
An experiment or calculation showing that the recovery probability fails to improve proportionally to 1/m when the averaged adjacency matrix is used would falsify the central claim.
Figures


read the original abstract
We study community detection in the two-block stochastic block model under the setting where multiple independent graph samples drawn from the same distribution are available. Building on a recently simplified spectral algorithm that preserves the independence of adjacency matrix entries throughout, we show that averaging $m$ independent samples before applying spectral partitioning reduces the error bound $\gamma$ exponentially in $m$: specifically, one can find a $\gamma$-correct partition with probability $1 - o(1)$ whenever $\frac{(a-b)^2}{a+b} \geq \frac{C}{m} \log \frac{2}{\gamma}$, improving the single-sample requirement by a factor of $m$. The key technical contribution is a multi-sample analogue of the spectral norm bound on the noise matrix, which propagates through the Davis-Kahan subspace angle analysis to yield the improved recovery guarantee. We provide experimental validation across a range of graph sizes ($n$ up to $1000$) and sample counts ($m$ up to $9$), demonstrating that the derived bounds are sharp and that even two or three samples yield dramatic improvements in recovery accuracy. Our results offer a rigorous theoretical foundation for graph data augmentation strategies used in modern graph representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies community detection in the two-block stochastic block model when m independent graph samples from the same distribution are available. It shows that averaging the m samples before applying spectral partitioning yields a gamma-correct partition with probability 1-o(1) whenever (a-b)^2/(a+b) >= (C/m) log(2/gamma), improving the single-sample threshold by a factor of m. The central technical step is a multi-sample analogue of the spectral-norm bound on the centered noise matrix, which is asserted to propagate through the Davis-Kahan subspace-angle argument; experiments for n up to 1000 and m up to 9 are reported to confirm that the derived bounds are sharp.
Significance. If the multi-sample noise bound is correctly established, the result supplies a clean theoretical justification for graph-data augmentation: the m-fold reduction in the required SNR threshold together with the exponential improvement in misclassification probability. The claim rests on a standard matrix-concentration argument (Bernstein-type bound on the averaged noise) rather than any fitted parameter or circular construction, and the experimental regime is large enough to test the predicted scaling.
major comments (1)
- [Key technical contribution paragraph / abstract] The abstract and key-technical-contribution paragraph assert that the multi-sample spectral-norm bound propagates through Davis-Kahan to produce the stated 1/m improvement, yet no explicit derivation of the constant C, the precise operator-norm tail, or the resulting subspace-angle bound appears in the provided abstract; the manuscript must supply these steps (with the same level of detail used for the single-sample case) so that the propagation can be verified.
minor comments (3)
- [Abstract] The phrase 'recently simplified spectral algorithm that preserves the independence of adjacency matrix entries' should be accompanied by a precise citation to the referenced single-sample work.
- [Experiments] The experimental section claims the bounds are 'sharp'; the manuscript should report the quantitative metric (e.g., empirical misclassification rate versus the theoretical gamma) used to reach that conclusion.
- [Model definition] Notation for the two-block parameters a and b should be introduced once in the main text with a clear statement of the normalization (e.g., whether they are scaled by n or not).
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the constructive comment on the abstract. We address the point below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: The abstract and key-technical-contribution paragraph assert that the multi-sample spectral-norm bound propagates through Davis-Kahan to produce the stated 1/m improvement, yet no explicit derivation of the constant C, the precise operator-norm tail, or the resulting subspace-angle bound appears in the provided abstract; the manuscript must supply these steps (with the same level of detail used for the single-sample case) so that the propagation can be verified.
Authors: We agree that the abstract and key-technical-contribution paragraph would benefit from an explicit outline of the propagation steps. In the revision we will add a concise derivation: the averaged noise matrix is (1/m) sum_{k=1}^m (A_k - E[A_k]), each centered term is independent with variance proxy bounded by (a+b)/4; a vector Bernstein inequality then yields ||averaged noise||_2 <= C sqrt( (a+b) log(2/gamma) / m ) with probability 1-o(1), where C is the same absolute constant appearing in the single-sample case. Substituting this tail into the Davis-Kahan sin Theta bound produces a subspace angle of order sqrt( (a+b) log(2/gamma) / (m (a-b)^2) ), which is at most gamma/2 precisely when the SNR condition holds with the factor 1/m. This paragraph will be written at the same level of detail as the single-sample argument already present in the body. revision: yes
Circularity Check
No significant circularity; improvement follows from standard concentration
full rationale
The paper's central claim rests on deriving a multi-sample analogue of the spectral norm bound on the noise matrix (via matrix concentration) and propagating it through Davis-Kahan. This is a standard 1/sqrt(m) reduction and does not reduce to a fitted parameter, self-definition, or load-bearing self-citation chain. The base single-sample algorithm is cited as prior work, but the m-factor improvement is independently justified by the new bound. No equations or steps in the provided abstract or description collapse by construction to the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- C
axioms (1)
- standard math Davis-Kahan theorem bounds the subspace angle between perturbed and unperturbed eigenvectors
Reference graph
Works this paper leans on
-
[1]
2015 , eprint=
Stochastic Block Model and Community Detection in the Sparse Graphs: A spectral algorithm with optimal rate of recovery , author=. 2015 , eprint=
2015
-
[2]
Combinatorica , year=
Graph bisection algorithms with good average case behavior , author=. Combinatorica , year=
-
[3]
The Solution of Some Random NP-Hard Problems in Polynomial Expected Time , author=. J. Algorithms , year=
-
[4]
Proceedings 2001 IEEE International Conference on Cluster Computing , year=
Spectral partitioning of random graphs , author=. Proceedings 2001 IEEE International Conference on Cluster Computing , year=
2001
-
[5]
Combinatorics, Probability and Computing , year=
Graph Partitioning via Adaptive Spectral Techniques , author=. Combinatorics, Probability and Computing , year=
-
[6]
Random Graphs , publisher=
Bollobás, Béla , year=. Random Graphs , publisher=
-
[7]
2015 , eprint=
Minimax Rates of Community Detection in Stochastic Block Models , author=. 2015 , eprint=
2015
-
[8]
2000 , eprint=
On the concentration of eigenvalues of random symmetric matrices , author=. 2000 , eprint=
2000
-
[9]
Combinatorica , year=
The eigenvalues of random symmetric matrices , author=. Combinatorica , year=
-
[10]
The rotation of eigenvectors by a perturbation , journal =. 1963 , issn =. doi:https://doi.org/10.1016/0022-247X(63)90001-5 , url =
-
[11]
2026 , eprint=
Simplify to Amplify: Achieving Information-Theoretic Bounds with Fewer Steps in Spectral Community Detection , author=. 2026 , eprint=
2026
-
[12]
Davis, Chandler and Kahan, W. M. , title =. SIAM Journal on Numerical Analysis , volume =. 1970 , doi =
1970
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.