GoQuant: Geometric Orthogonal Residual Projection for Multiplier-Free Power-of-Two Transformer Quantization
Pith reviewed 2026-06-29 22:14 UTC · model grok-4.3
The pith
GoQuant mitigates low angular resolution in power-of-two quantization by projecting residuals onto an orthogonal dual basis using only shifts and adds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
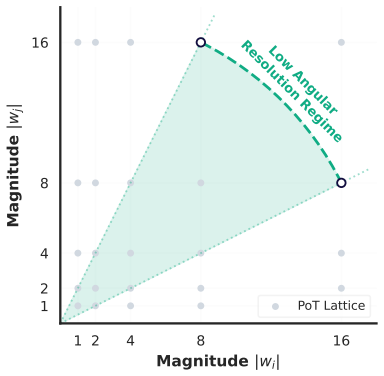
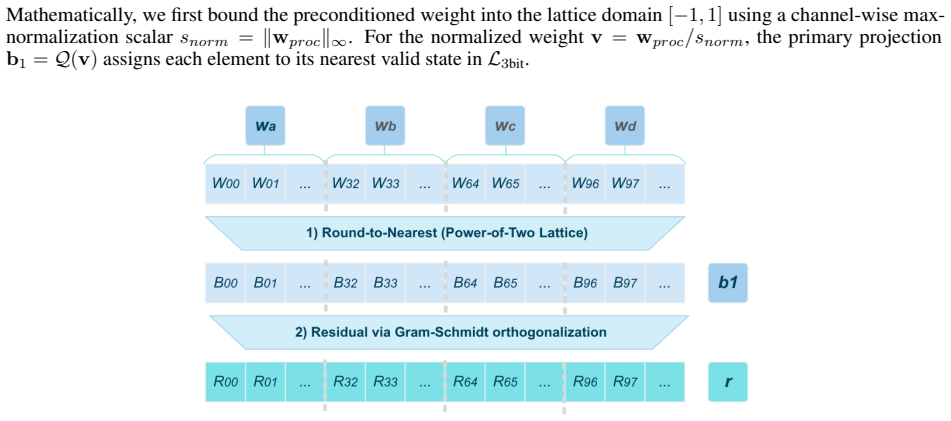
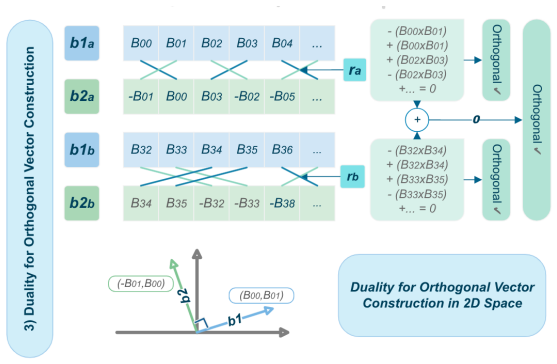
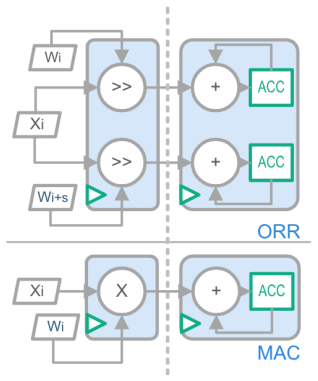
By formulating quantization as a dual-basis geometric projection, GoQuant adaptively synthesizes a higher-resolution residual lattice using strictly shift-and-add operations, overcoming the structural limitation of exponential PoT lattices in the ultra-low bit regime without relying on asymmetric scaling or gradient-based optimization.
What carries the argument
Geometric Orthogonal Residual Projection: a formulation of quantization as dual-basis geometric projection that creates higher-resolution residual lattice via shift-and-add operations.
Load-bearing premise
The low angular resolution of exponential power-of-two lattices can be fixed by an analytical dual-basis orthogonal residual projection that uses only shifts and adds and does not harm high-dimensional data manifolds.
What would settle it
A test where GoQuant on LLaMA-2-7B produces perplexity much worse than 6.10 or where the synthesized hardware still requires multiplier logic in the datapath.
Figures


read the original abstract
The deployment of Large Language Models (LLMs) and Vision Transformers (ViTs) on edge devices is significantly constrained by memory limitations and the critical timing bottlenecks introduced by dense Multiply-Accumulate (MAC) arrays. In the ultra-low bit regime, logarithmic Power-of-Two (PoT) quantization provides a hardware-efficient alternative by replacing MAC operations with bit-shifts. However, the non-uniform exponential lattice is inherently limited by a \textbf{Low Angular Resolution Regime}, a structural flaw that becomes particularly pronounced at sub-4-bit thresholds, leading to a notable degradation of high-dimensional feature manifolds. To address this geometric limitation, we propose Geometric Orthogonal Residual Projection Quantization (GoQuant), an algorithm-hardware co-design framework. By formulating quantization as a dual-basis geometric projection, GoQuant adaptively synthesizes a higher-resolution residual lattice using strictly shift-and-add operations. Furthermore, its analytical solver offers a practical alternative to computationally intensive gradient-based optimization, reducing the full-model calibration time for LLaMA-2-7B to approximately 15 minutes. Extensive evaluations demonstrate GoQuant's applicability across modalities and its hardware efficiency. Under the 3-bit (W3/A16) constraint, it achieves a perplexity of 6.10 on LLaMA-2-7B, comparing favorably to conventional MAC-intensive baselines like AWQ without relying on asymmetric scaling, while maintaining competitive accuracy in 4-bit scenarios. At the silicon level, standard-cell RTL synthesis at a 28nm node indicates that GoQuant effectively mitigates the timing bottlenecks associated with dense multiplier trees. By flattening the combinational logic depth, our parallel shift-and-add datapath reduces the critical path delay to 0.35 ns.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GoQuant, a quantization framework for LLMs and ViTs that formulates power-of-two (PoT) quantization as a dual-basis geometric orthogonal residual projection. This is intended to mitigate the low angular resolution of exponential PoT lattices in the sub-4-bit regime while remaining strictly multiplier-free through shift-and-add operations. An analytical solver replaces gradient-based optimization, reducing calibration time. The central empirical claim is that under W3/A16, GoQuant achieves 6.10 perplexity on LLaMA-2-7B (competitive with AWQ without asymmetric scaling) and that 28 nm RTL synthesis yields a 0.35 ns critical path delay by flattening combinational logic.
Significance. If the dual-basis projection is shown to be multiplier-free, analytically solvable, and to preserve high-dimensional manifold structure without introducing hidden parameters or MAC operations, the work would provide a concrete hardware-efficient alternative to standard quantization methods for edge deployment of transformers. The reported reduction in calibration time to ~15 minutes and the explicit hardware timing result would be practical strengths.
major comments (2)
- [Abstract] Abstract: the performance numbers (perplexity 6.10 on LLaMA-2-7B at W3/A16, 0.35 ns delay at 28 nm) are stated without any derivation, error bounds, dataset details, or comparison methodology. This prevents verification that the geometric projection actually supports the accuracy and hardware claims.
- [Abstract] Abstract: the central geometric claim—that an analytical dual-basis orthogonal residual projection mitigates the low angular resolution regime while remaining strictly multiplier-free—is presented without equations, lattice definitions, or proof that the residual lattice synthesis uses only shift-and-add. This is load-bearing for both the algorithmic and hardware contributions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. The manuscript body contains the full derivations, equations, dataset details, and proofs referenced in the abstract summary. We address each point below and note that abstracts are intentionally concise; we are prepared to revise the abstract for additional context if the editor requires it.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance numbers (perplexity 6.10 on LLaMA-2-7B at W3/A16, 0.35 ns delay at 28 nm) are stated without any derivation, error bounds, dataset details, or comparison methodology. This prevents verification that the geometric projection actually supports the accuracy and hardware claims.
Authors: The abstract summarizes key results; full experimental protocol, including WikiText-2 perplexity evaluation, comparison methodology against AWQ and other baselines without asymmetric scaling, and any error bounds or variance reporting, appears in Sections 4.1–4.2. Hardware results (28 nm RTL synthesis, critical-path flattening via shift-and-add datapath) are derived and reported in Section 5. We can insert a brief clause in the abstract directing readers to these sections if requested, but the claims are fully supported and verifiable in the main text. revision: partial
-
Referee: [Abstract] Abstract: the central geometric claim—that an analytical dual-basis orthogonal residual projection mitigates the low angular resolution regime while remaining strictly multiplier-free—is presented without equations, lattice definitions, or proof that the residual lattice synthesis uses only shift-and-add. This is load-bearing for both the algorithmic and hardware contributions.
Authors: The abstract is a high-level summary. The complete formulation—including dual-basis geometric projection, lattice definitions for the higher-resolution residual, analytical solver, and explicit proof that all operations reduce to shift-and-add (no hidden multipliers or MACs)—is given in Section 3 with Equations (3)–(7) and Theorem 2. The low-angular-resolution mitigation is analyzed geometrically in Section 3.1. These elements are therefore present and load-bearing in the manuscript; the abstract does not repeat them due to length constraints. revision: no
Circularity Check
No significant circularity
full rationale
The paper introduces GoQuant as a geometric dual-basis projection method for PoT quantization, supported by an analytical solver and empirical perplexity/hardware results on LLaMA-2-7B compared to AWQ. No equations, predictions, or derivations in the abstract or described framework reduce by construction to fitted inputs, self-definitions, or self-citation chains; the central claims rest on external benchmarks and stated shift-and-add operations without internal reduction to the target metrics.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Fast-TurboQuant: A Multiplier-Free Online Vector Quantization Approach
Fast-TurboQuant substitutes a structured fast Johnson-Lindenstrauss transform for dense random projections in 1-bit vector quantization, cutting arithmetic to additions only and reporting 19.7x speedup plus lower MSE ...
Reference graph
Works this paper leans on
-
[1]
The Geometry of LLM Quantization: GPTQ as Babai's Nearest Plane Algorithm
Jiale Chen, Yalda Shabanzadeh, Elvir Crn ˇcevi´c, Torsten Hoefler, and Dan Alistarh. The geometry of llm quantization: Gptq as babai’s nearest plane algorithm.arXiv preprint arXiv:2507.18553, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023
2023
-
[3]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024. 12
2024
-
[5]
Repq-vit: Scale reparameterization for post-training quantization of vision transformers
Zhikai Li, Junrui Xiao, Lianwei Yang, and Qingyi Gu. Repq-vit: Scale reparameterization for post-training quantization of vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17227–17236, 2023
2023
-
[6]
Yuhang Li, Ruihao Gong, Xu Tan, Yang Yang, Peng Hu, Qi Zhang, Fengwei Yu, Wei Wang, and Shi Gu. BRECQ: Pushing the Limit of Post-Training Quantization by Block Reconstruction, July 2021. arXiv:2102.05426 [cs]
-
[7]
Xiuying Wei, Ruihao Gong, Yuhang Li, Xianglong Liu, and Fengwei Yu. QDrop: Randomly Dropping Quantiza- tion for Extremely Low-bit Post-Training Quantization, February 2023. arXiv:2203.05740 [cs]
-
[8]
Aiqvit: Architecture-informed post-training quantization for vision transformers
Runqing Jiang, Ye Zhang, Longguang Wang, Pengpeng Yu, and Yulan Guo. Aiqvit: Architecture-informed post-training quantization for vision transformers. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 17635–17643, 2025
2025
-
[9]
Quip: 2-bit quantization of large language models with guarantees.Advances in neural information processing systems, 36:4396–4429, 2023
Jerry Chee, Yaohui Cai, V olodymyr Kuleshov, and Christopher M De Sa. Quip: 2-bit quantization of large language models with guarantees.Advances in neural information processing systems, 36:4396–4429, 2023
2023
-
[10]
Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks.Proceedings of machine learning research, 235:48630, 2024
Albert Tseng, Jerry Chee, Qingyao Sun, V olodymyr Kuleshov, and Christopher De Sa. Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks.Proceedings of machine learning research, 235:48630, 2024
2024
-
[11]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213–100240, 2024
2024
-
[12]
SpinQuant: LLM quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: Llm quantization with learned rotations. arXiv preprint arXiv:2405.16406, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
BitNet: Scaling 1-bit Transformers for Large Language Models
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei. Bitnet: Scaling 1-bit transformers for large language models.arXiv preprint arXiv:2310.11453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Shiftaddllm: Accelerating pretrained llms via post-training multiplication-less reparameterization.Advances in Neural Information Processing Systems, 37:24822–24848, 2024
Haoran You, Yipin Guo, Yichao Fu, Wei Zhou, Huihong Shi, Xiaofan Zhang, Souvik Kundu, Amir Yazdan- bakhsh, and Yingyan Celine Lin. Shiftaddllm: Accelerating pretrained llms via post-training multiplication-less reparameterization.Advances in Neural Information Processing Systems, 37:24822–24848, 2024
2024
-
[15]
PTQ4ViT: Post-training Quantization for Vision Transformers with Twin Uniform Quantization
Zhihang Yuan, Chenhao Xue, Yiqi Chen, Qiang Wu, and Guangyu Sun. PTQ4ViT: Post-training Quantization for Vision Transformers with Twin Uniform Quantization. In Shai Avidan, Gabriel Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, editors,Computer Vision – ECCV 2022, volume 13672, pages 191–207. Springer Nature Switzerland, Cham, 2022. ...
2022
-
[16]
Towards accurate post-training quantization for vision transformer
Yifu Ding, Haotong Qin, Qinghua Yan, Zhenhua Chai, Junjie Liu, Xiaolin Wei, and Xianglong Liu. Towards accurate post-training quantization for vision transformer. InProceedings of the 30th ACM international conference on multimedia, pages 5380–5388, 2022
2022
-
[17]
Llmc+: Benchmarking vision-language model compression with a plug-and-play toolkit
Chengtao Lv, Bilang Zhang, Yang Yong, Ruihao Gong, Yushi Huang, Shiqiao Gu, Jiajun Wu, Yumeng Shi, Jinyang Guo, and Wenya Wang. Llmc+: Benchmarking vision-language model compression with a plug-and-play toolkit. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 24189–24197, 2026. 13
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.