Cross-Source Reasoning-based Correction for Author Name Disambiguation
Pith reviewed 2026-06-27 18:55 UTC · model grok-4.3
The pith
CrossND corrects author name disambiguation by reasoning over inconsistent assignments across data sources without human input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
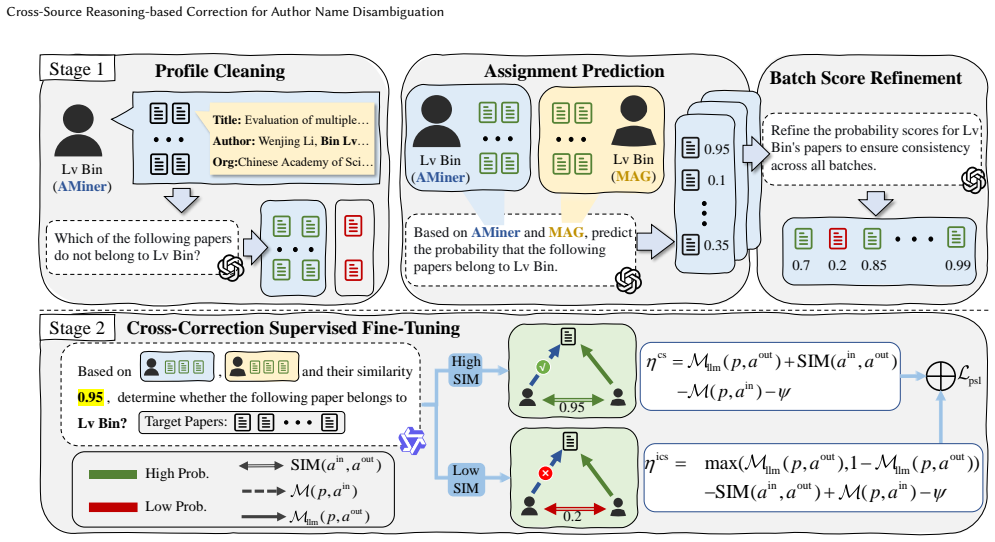
CrossND is a full-stack framework that integrates data refinement, cross-source reasoning, and test-time scaling. A chain-of-refinement pipeline first denoises author profiles and produces more accurate paper-author matching probabilities. A supervised fine-tuning process then incorporates these refined signals and a probabilistic soft logic-based cross-correction module to infer the assignments of which sources are incorrect. Test-time scaling further enhances the accuracy and robustness of the predictions. Experiments on real-world datasets indicate that CrossND consistently outperforms 17 baselines by leveraging cross-source reasoning without human intervention.
What carries the argument
The probabilistic soft logic-based cross-correction module that infers incorrect source assignments from refined paper-author matching probabilities and cross-source inconsistencies.
If this is right
- Author name disambiguation systems can improve by correcting cumulative assignment errors using existing multi-source data.
- Academic search accuracy rises when models learn to flag and override wrong source assignments automatically.
- The need for expert annotation drops because cross-source signals replace manual correction.
- Test-time scaling can be combined with refinement pipelines to make predictions more robust across datasets.
Where Pith is reading between the lines
- The same inconsistency-driven correction idea could extend to other multi-source entity resolution problems such as product matching or citation cleaning.
- If sources share hidden correlated errors, the method might require an additional check for common bias patterns before applying the cross-correction step.
- This approach suggests treating data-source disagreement as a usable training signal rather than noise in large-scale academic databases.
Load-bearing premise
That inconsistent assignments across sources provide reliable signals for inferring which sources are incorrect, without the inconsistencies themselves being dominated by systematic biases or errors common to multiple sources.
What would settle it
A collection of sources where the same systematic error pattern appears in all of them, so that cross-source inconsistencies no longer point to the true correct assignments.
Figures


read the original abstract
Author name disambiguation is a critical challenge in academic search systems, often addressed through from-scratch and real-time disambiguation approaches. However, current algorithms remain vulnerable to cumulative errors of paper-author assignments and overlook inconsistent assignments across different sources. Resorting to expert annotation is resource-intensive. To this end, this paper explores a new perspective for author name disambiguation: cross-source correction by leveraging inconsistent assignments across sources. We propose CrossND, a full-stack framework that integrates data refinement, cross-source reasoning, and test-time scaling. First, a chain-of-refinement pipeline denoises author profiles and produces more accurate paper-author matching probabilities. Second, a supervised fine-tuning process incorporates these refined signals and a probabilistic soft logic-based cross-correction module to infer the assignments of which sources are incorrect. Third, test-time scaling further enhances the accuracy and robustness of the predictions. Experiments on real-world datasets indicate that CrossND consistently outperforms 17 baselines by leveraging cross-source reasoning without human intervention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CrossND, a full-stack framework for author name disambiguation that performs cross-source correction by exploiting inconsistent paper-author assignments across sources. It integrates a chain-of-refinement pipeline for denoising author profiles, supervised fine-tuning that incorporates refined signals into a probabilistic soft logic (PSL) cross-correction module to identify incorrect source assignments, and test-time scaling. The central claim is that this approach consistently outperforms 17 baselines on real-world datasets without requiring human intervention.
Significance. If the results hold under proper controls, the work offers a practical advance by turning existing multi-source inconsistencies into a correction signal, reducing dependence on expert annotation for disambiguation. The integration of refinement, PSL-based reasoning, and scaling is a coherent architecture, though its broader impact depends on demonstrating that the correction signal is robust rather than dataset-specific.
major comments (3)
- [Abstract] Abstract: the claim of consistent outperformance over 17 baselines provides no details on baseline selection criteria, statistical significance testing, error bars, or how train/test splits prevent leakage across sources; this information is load-bearing for the central empirical claim.
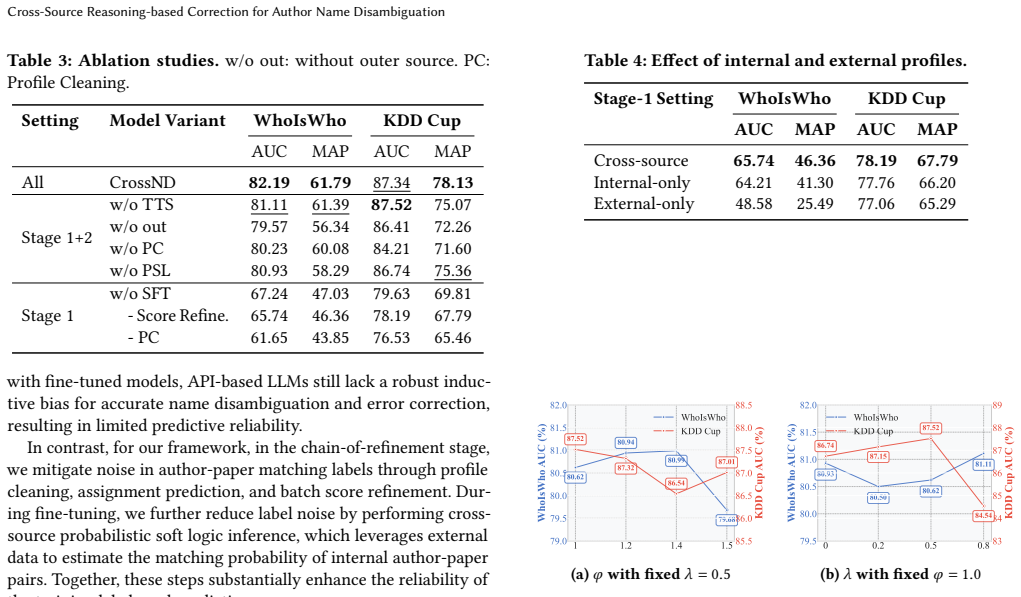
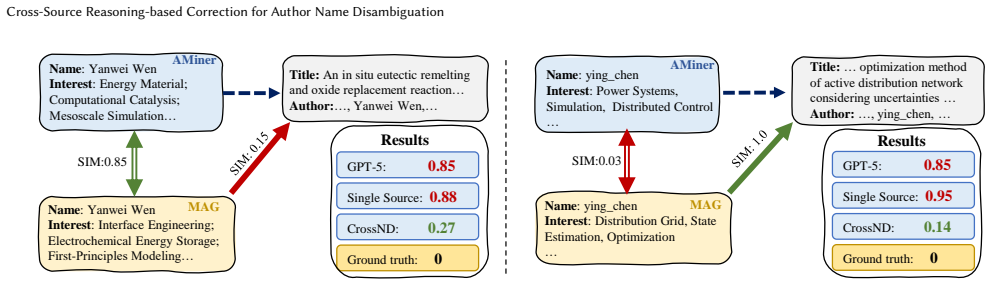
- [Method overview] Cross-correction module (described in the method overview): the PSL-based inference assumes that observed inconsistencies predominantly reflect independent per-source errors, yet no analysis or ablation tests whether shared systematic biases (identical name-matching heuristics, common upstream databases, or scraping pipelines) dominate the signal and render the correction uninformative.
- [Experiments] Experiments: the evaluation does not report any diagnostic for error correlation structure across the 17 baseline datasets, which directly tests the weakest assumption underlying the cross-source reasoning claim.
minor comments (2)
- [Method] Clarify the exact PSL rules and predicates used in the cross-correction module, including how soft truth values are initialized from the refined matching probabilities.
- [Method] Provide the precise definition of the chain-of-refinement pipeline stages and any hyperparameters involved.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the presentation of our empirical claims and the validation of key assumptions in CrossND. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of consistent outperformance over 17 baselines provides no details on baseline selection criteria, statistical significance testing, error bars, or how train/test splits prevent leakage across sources; this information is load-bearing for the central empirical claim.
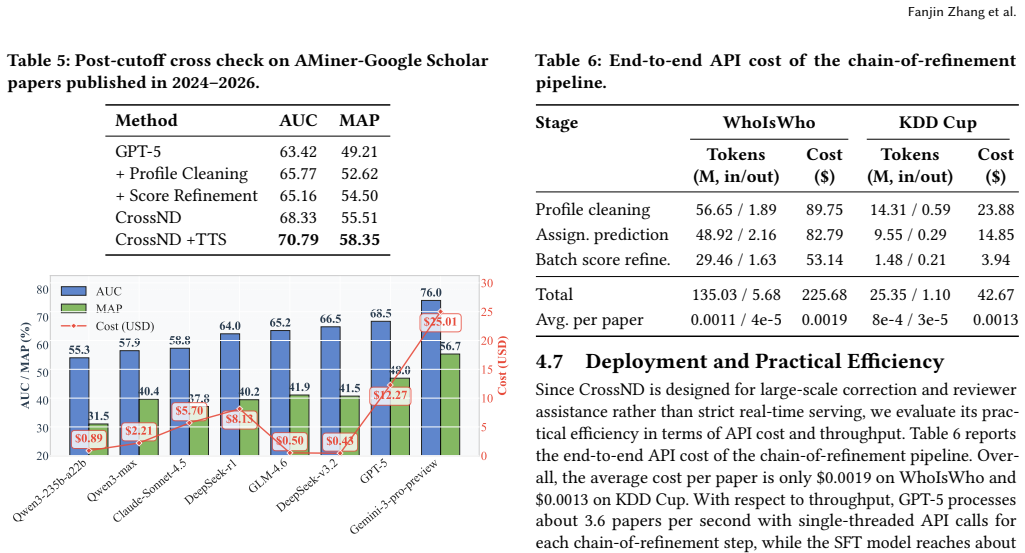
Authors: We agree that the abstract is too concise on these load-bearing details. In the revised manuscript we will expand the abstract (or add a clarifying footnote) to state: the 17 baselines comprise representative recent methods spanning from-scratch and real-time disambiguation; statistical significance is evaluated with paired t-tests (p < 0.05 reported); results include standard-error bars from 5-fold cross-validation; and train/test splits are performed independently per source with no shared papers to avoid leakage. These elements already appear in Section 4 but will be foregrounded in the abstract. revision: yes
-
Referee: [Method overview] Cross-correction module (described in the method overview): the PSL-based inference assumes that observed inconsistencies predominantly reflect independent per-source errors, yet no analysis or ablation tests whether shared systematic biases (identical name-matching heuristics, common upstream databases, or scraping pipelines) dominate the signal and render the correction uninformative.
Authors: This assumption is central and merits explicit testing. The chain-of-refinement stage first denoises profiles using supervised signals before PSL inference, and the probabilistic rules can down-weight consistent errors. Nevertheless, we did not provide a dedicated ablation on shared biases. We will add a controlled experiment in the revision that constructs source subsets sharing name-matching heuristics and shows that CrossND retains gains via refinement and test-time scaling; we welcome further suggestions on the exact diagnostic. revision: partial
-
Referee: [Experiments] Experiments: the evaluation does not report any diagnostic for error correlation structure across the 17 baseline datasets, which directly tests the weakest assumption underlying the cross-source reasoning claim.
Authors: We acknowledge the missing diagnostic. In the revised experiments section we will report pairwise error correlations (Cohen's kappa on misassigned papers) across sources on the evaluation datasets. This will quantify the degree of independence and demonstrate that residual inconsistencies remain informative, consistent with the observed performance improvements. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical ML framework (data refinement pipeline, supervised fine-tuning, probabilistic soft logic cross-correction module, and test-time scaling) whose outputs are trained on refined signals and cross-source inconsistencies rather than being defined as equivalent to those inputs by construction. No equations, self-definitional loops, or load-bearing self-citations are indicated in the provided text that would reduce claimed predictions to fitted parameters or prior author results. The central claim of outperformance against 17 baselines on real-world datasets is presented as externally testable, satisfying the condition for a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025.Claude 4.5 Haiku System Card
Anthropic. 2025.Claude 4.5 Haiku System Card. Technical Report. Anthropic. https://www.anthropic.com/claude-haiku-4-5-system-card Accessed: 2026-02- 02
2025
-
[2]
Devansh Arpit, Stanisław Jastrzebski, Nicolas Ballas, David Krueger, Emmanuel Bengio, Maxinder S Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, et al. 2017. A closer look at memorization in deep networks. In Proceedings of the 34th International Conference on Machine Learning. 233–242
2017
-
[3]
Markus M Breunig, Hans-Peter Kriegel, Raymond T Ng, and Jörg Sander. 2000. LOF: identifying density-based local outliers. InProceedings of the 2000 ACM SIGMOD international conference on Management of data. 93–104
2000
-
[4]
Bo Chen, Jing Zhang, Jie Tang, Lingfan Cai, Zhaoyu Wang, Shu Zhao, Hong Chen, and Cuiping Li. 2022. CONNA: Addressing Name Disambiguation on 9 Fanjin Zhang et al. the Fly.IEEE Transactions on Knowledge and Data Engineering34, 07 (2022), 3139–3152
2022
-
[5]
Bo Chen, Jing Zhang, Fanjin Zhang, Tianyi Han, Yuqing Cheng, Xiaoyan Li, Yuxiao Dong, and Jie Tang. 2023. Web-scale academic name disambiguation: the WhoIsWho benchmark, leaderboard, and toolkit. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3817–3828
2023
-
[6]
Bo Chen, Jing Zhang, Xiaokang Zhang, Yuxiao Dong, Jian Song, Peng Zhang, Kaibo Xu, Evgeny Kharlamov, and Jie Tang. 2022. Gccad: Graph contrastive cod- ing for anomaly detection.IEEE Transactions on Knowledge and Data Engineering 35, 8 (2022), 8037–8051
2022
-
[7]
Xuelu Chen, Muhao Chen, Changjun Fan, Ankith Uppunda, Yizhou Sun, and Carlo Zaniolo. 2020. Multilingual Knowledge Graph Completion via Ensemble Knowledge Transfer. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings. 3227–3238
2020
-
[8]
Hao Cheng, Zhaowei Zhu, Xingyu Li, Yifei Gong, Xing Sun, and Yang Liu. 2021. Learning with Instance-Dependent Label Noise: A Sample Sieve Approach. In International Conference on Learning Representations
2021
-
[9]
Yuqing Cheng, Bo Chen, Fanjin Zhang, and Jie Tang. 2024. BOND: Bootstrapping from-scratch name disambiguation with multi-task promoting. InProceedings of the ACM Web Conference 2024. 4216–4226
2024
-
[10]
Zhoujun Cheng, Jungo Kasai, and Tao Yu. 2023. Batch Prompting: Efficient Inference with Large Language Model APIs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track. 792–810
2023
-
[11]
Xiaoming Fan, Jianyong Wang, Xu Pu, Lizhu Zhou, and Bing Lv. 2011. On graph- based name disambiguation.Journal of Data and Information Quality2, 2 (2011), 1–23
2011
-
[12]
Jerome H Friedman. 2001. Greedy function approximation: a gradient boosting machine.Annals of statistics(2001), 1189–1232
2001
-
[13]
Aritra Ghosh, Himanshu Kumar, and PS Sastry. 2017. Robust loss functions under label noise for deep neural networks. InProceedings of the 31th AAAI Conference on Artificial Intelligence
2017
-
[14]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. DeepSeek-R1 incen- tivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
-
[15]
Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor W Tsang, and Masashi Sugiyama. 2018. Co-teaching: robust training of deep neural networks with extremely noisy labels. InProceedings of the 32nd International Conference on Neural Information Processing Systems. 8536–8546
2018
-
[16]
Sebastian Hofstätter, Markus Zlabinger, and Allan Hanbury. 2020. Interpretable & Time-Budget-Constrained Contextualization for Re-Ranking. InProceedings of the 24th European Conference on Artificial Intelligence. 513–520
2020
-
[17]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[18]
Jian Huang, Seyda Ertekin, and C Lee Giles. 2006. Efficient name disambigua- tion for large-scale databases. InProceedings of the 10th European conference on principles of data mining and knowledge discovery. 536–544
2006
-
[19]
Angelika Kimmig, Stephen Bach, Matthias Broecheler, Bert Huang, and Lise Getoor. 2012. A short introduction to probabilistic soft logic. InProceedings of the 2012 NIPS Workshop on Probabilistic Programming: Foundations and Applications. 1–4
2012
-
[20]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
Pith/arXiv arXiv 2025
-
[21]
Li Liu, William K Cheung, Xin Li, and Lejian Liao. 2016. Aligning Users across So- cial Networks Using Network Embedding.. InProceedings of the 25th International Joint Conference on Artificial Intelligence. 1774–1780
2016
-
[22]
Xiao Liu, Da Yin, Jingnan Zheng, Xingjian Zhang, Peng Zhang, Hongxia Yang, Yuxiao Dong, and Jie Tang. 2022. Oag-bert: Towards a unified backbone language model for academic knowledge services. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3418–3428
2022
-
[23]
Gilles Louppe, Hussein T Al-Natsheh, Mateusz Susik, and Eamonn James Maguire
-
[24]
InProceedings of the 7th international conference on knowledge engineering and the semantic web
Ethnicity sensitive author disambiguation using semi-supervised learning. InProceedings of the 7th international conference on knowledge engineering and the semantic web. 272–287
-
[25]
when to update
Eran Malach and Shai Shalev-Shwartz. 2017. Decoupling" when to update" from" how to update". InProceedings of the 30th Conference on Advances in Neural Information Processing Systems. 960–970
2017
-
[26]
Rafael Müller, Simon Kornblith, and Geoffrey E Hinton. 2019. When does label smoothing help?. InProceedings of the 32nd Conference on Advances in Neural Information Processing Systems. 4694–4703
2019
-
[27]
2025.GPT-5 System Card
OpenAI. 2025.GPT-5 System Card. Technical Report. OpenAI. https://cdn. openai.com/gpt-5-system-card.pdf Accessed: 2026-02-02
2025
-
[28]
Yunhe Pang, Bo Chen, Fanjin Zhang, Yanghui Rao, Evgeny Kharlamov, and Jie Tang. 2025. Guard: Effective anomaly detection through a text-rich and graph- informed language model. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 2222–2233
2025
-
[29]
Kun Qian, Poornima Chozhiyath Raman, Yunyao Li, and Lucian Popa. 2020. Partner: Human-in-the-loop entity name understanding with deep learning. In Proceedings of the 34th the AAAI Conference on Artificial Intelligence, Vol. 34. 13634–13635
2020
-
[30]
Senjuti Basu Roy, Martine De Cock, Vani Mandava, Swapna Savanna, Brian Dalessandro, Claudia Perlich, William Cukierski, and Ben Hamner. 2013. The microsoft academic search dataset and kdd cup 2013. InProceedings of the 2013 KDD cup 2013 workshop. 1–6
2013
-
[31]
Jan Schulz. 2016. Using Monte Carlo simulations to assess the impact of author name disambiguation quality on different bibliometric analyses.Scientometrics 107, 3 (2016), 1283–1298
2016
-
[32]
Arnab Sinha, Zhihong Shen, Yang Song, Hao Ma, Darrin Eide, Bo-June Hsu, and Kuansan Wang. 2015. An overview of microsoft academic service (mas) and applications. InProceedings of the 24th international conference on world wide web. 243–246
2015
-
[33]
Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, and Zhong Su. 2008. Ar- netminer: extraction and mining of academic social networks. InProceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 990–998
2008
-
[34]
Haiwen Wang, Ruijie Wan, Chuan Wen, Shuhao Li, Yuting Jia, Weinan Zhang, and Xinbing Wang. 2020. Author name disambiguation on heterogeneous information network with adversarial representation learning. InProceedings of the 34th the AAAI Conference on Artificial Intelligence. 238–245
2020
-
[35]
Song Wang, Zhen Tan, Ruocheng Guo, and Jundong Li. 2023. Noise-Robust Fine-Tuning of Pretrained Language Models via External Guidance. InFindings of the Association for Computational Linguistics: EMNLP 2023. 12528–12540
2023
-
[36]
Xuezhi Wang, Jie Tang, Hong Cheng, and S Yu Philip. 2011. Adana: Active name disambiguation. Inthe 11th international conference on data mining. 794–803
2011
-
[37]
Yanling Wang, Jing Zhang, Shasha Guo, Hongzhi Yin, Cuiping Li, and Hong Chen. 2021. Decoupling Representation Learning and Classification for GNN- based Anomaly Detection. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1239–1248
2021
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
-
[39]
Liqin Ye, Agam Shah, Chao Zhang, and Sudheer Chava. 2025. Calibrating Pre- trained Language Classifiers on LLM-generated Noisy Labels via Iterative Refine- ment. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 3598–3609
2025
-
[40]
Bo Yuan, Yulin Chen, Yin Zhang, and Wei Jiang. 2024. Hide and seek in noise labels: Noise-robust collaborative active learning with llms-powered assistance. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10977–11011
2024
-
[41]
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. 2025. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471 (2025)
Pith/arXiv arXiv 2025
-
[42]
Baichuan Zhang and Mohammad Al Hasan. 2017. Name disambiguation in anonymized graphs using network embedding. InProceedings of the 2017 ACM on Conference on Information and Knowledge Management. 1239–1248
2017
-
[43]
Fanjin Zhang, Xiao Liu, Jie Tang, Yuxiao Dong, Peiran Yao, Jie Zhang, Xiaotao Gu, Yan Wang, Evgeny Kharlamov, Bin Shao, et al. 2022. Oag: Linking entities across large-scale heterogeneous knowledge graphs.IEEE Transactions on Knowledge and Data Engineering35, 9 (2022), 9225–9239
2022
-
[44]
Fanjin Zhang, Xiao Liu, Jie Tang, Yuxiao Dong, Peiran Yao, Jie Zhang, Xiaotao Gu, Yan Wang, Bin Shao, Rui Li, et al. 2019. Oag: Toward linking large-scale het- erogeneous entity graphs. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2585–2595
2019
-
[45]
Fanjin Zhang, Shijie Shi, Yifan Zhu, Bo Chen, Yukuo Cen, Jifan Yu, Yelin Chen, Lulu Wang, Qingfei Zhao, Yuqing Cheng, et al . 2024. OAG-bench: a human- curated benchmark for academic graph mining. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 6214–6225
2024
-
[46]
Xiaocheng Zhang, Yang Zhou, Haoru Chen, Mengjiao Bao, and Peng Yan. 2024. Enhanced name disambiguation via iterative self-refining with LLMs. InOAG- Challenge KDD Cup
2024
-
[47]
Yutao Zhang, Fanjin Zhang, Peiran Yao, and Jie Tang. 2018. Name Disambiguation in AMiner: Clustering, Maintenance, and Human in the Loop.. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1002–1011
2018
-
[48]
fully consistent
Zhilu Zhang and Mert R Sabuncu. 2018. Generalized cross entropy loss for training deep neural networks with noisy labels. InProceedings of the 32nd Conference on Neural Information Processing Systems. 8792–8802. 10 Cross-Source Reasoning-based Correction for Author Name Disambiguation A Hallucination analysis of CrossND. Since Stage 1 uses LLM-generated e...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.