JD Oxygen AI Item Center (Oxygen AIIC) V1: An Industrial-Scale LLM/VLM-Centric Solution for Item Understanding, Management, and Applications
Pith reviewed 2026-06-29 04:07 UTC · model grok-4.3
The pith
An industrial platform uses self-evolving LLMs and VLMs to generate structured knowledge for tens of billions of product items.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
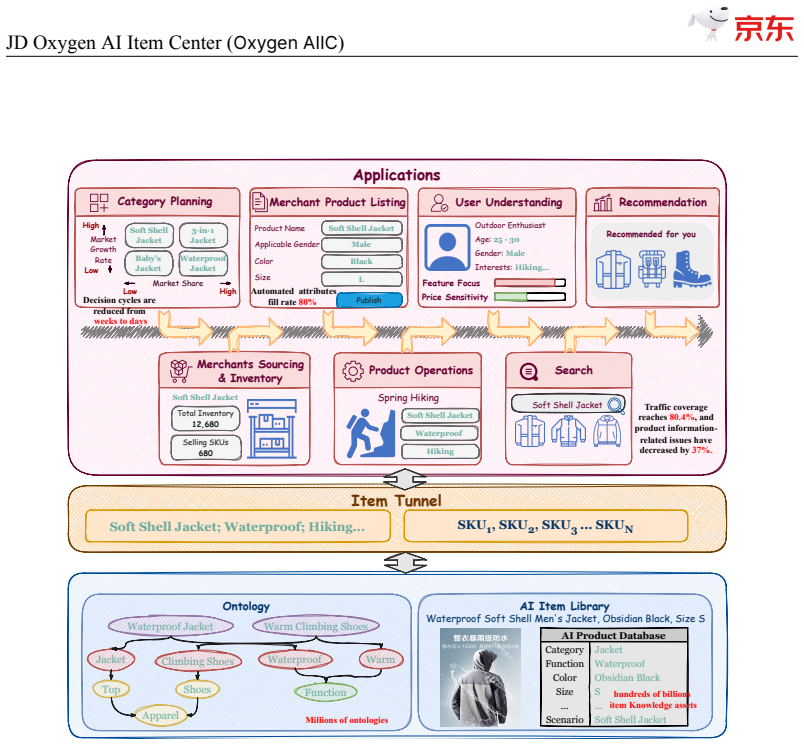
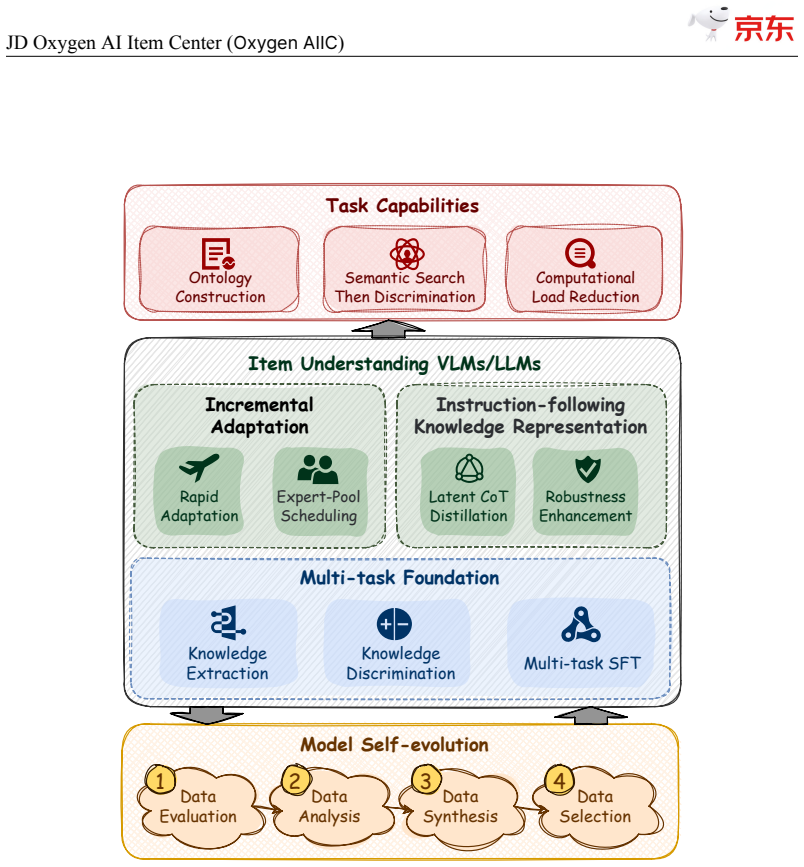
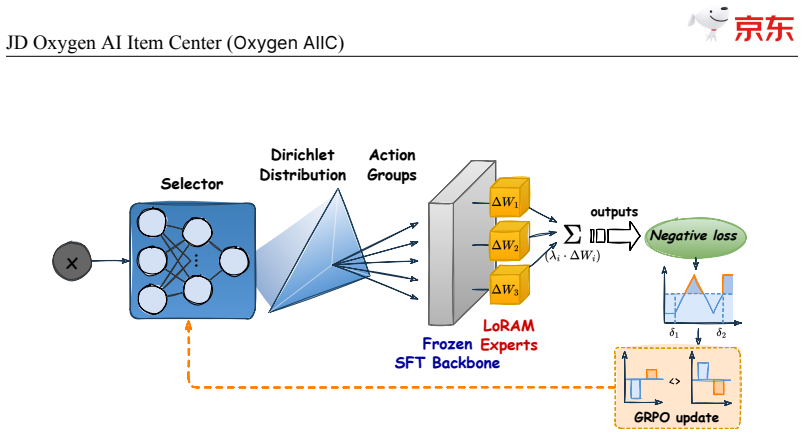
The central claim is that the S2D knowledge identification architecture, when paired with self-evolving item-understanding LLMs and VLMs, enables stable and controllable model improvement that produces item knowledge at 94.2 percent precision and 82.8 percent recall while supporting dynamic ontology evolution with millions of entries and a unified item tunnel for service delivery across core business scenarios.
What carries the argument
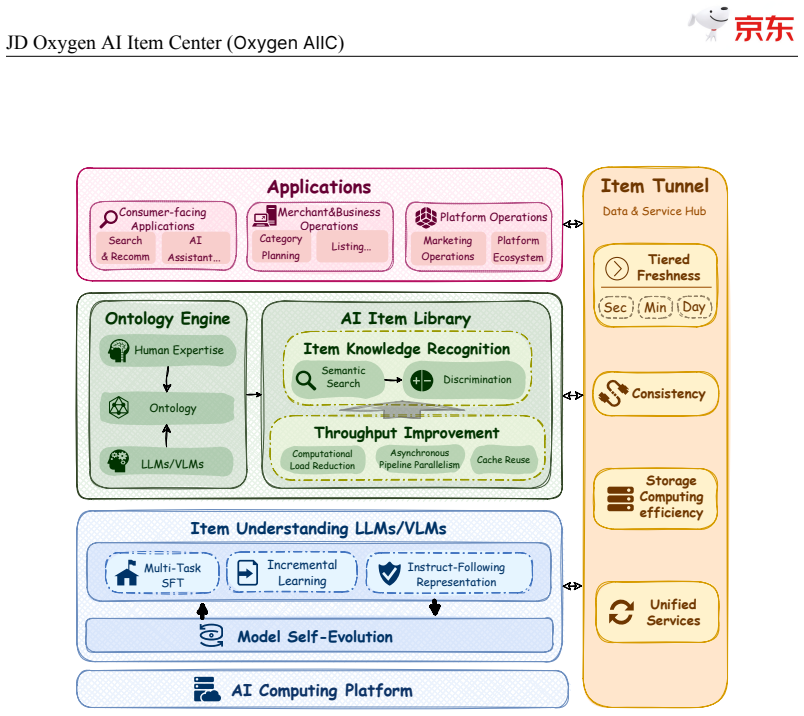
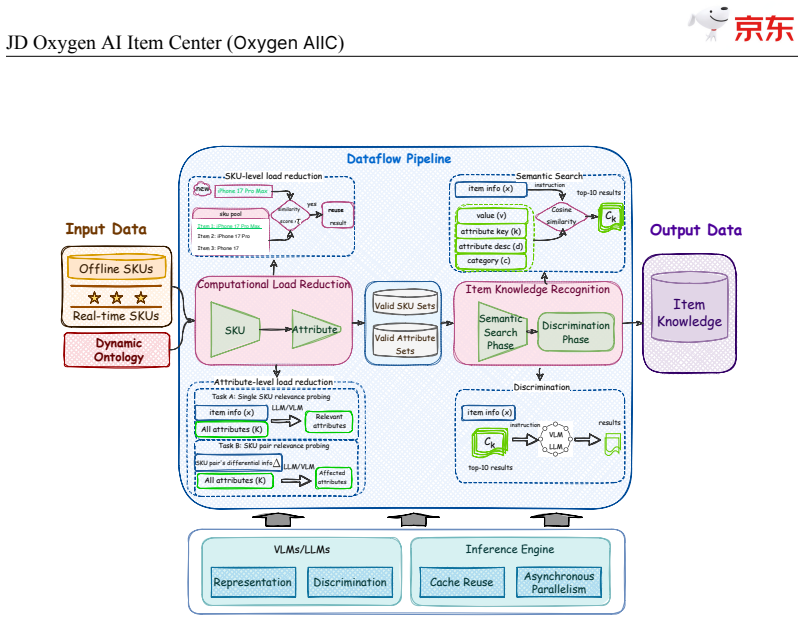
The Semantic Search then Discrimination (S2D) architecture that identifies and discriminates item knowledge at high throughput when combined with self-evolving LLMs and VLMs.
If this is right
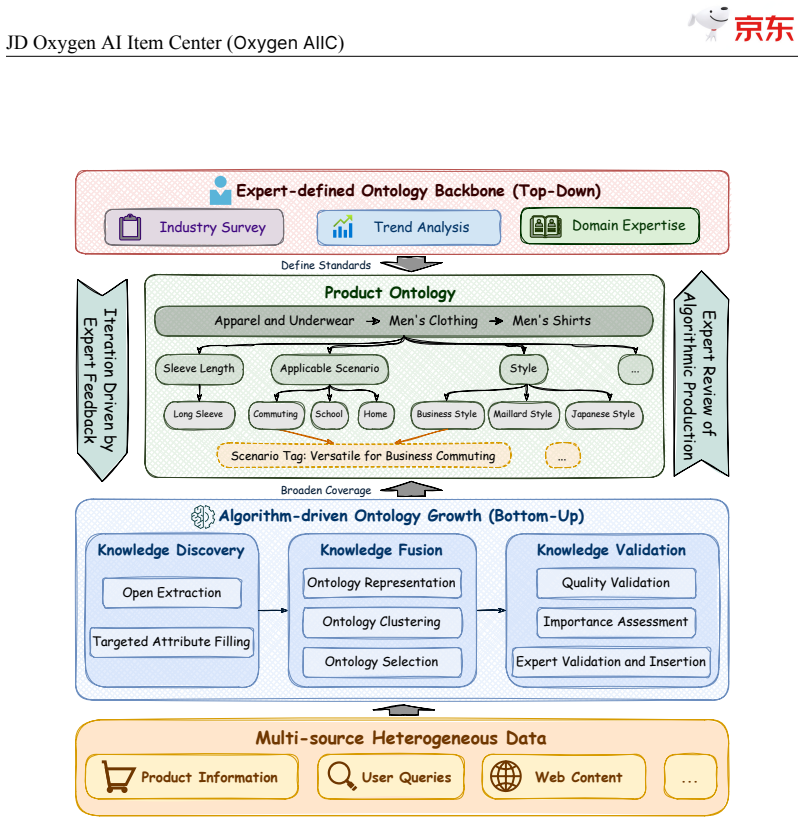
- The ontology can expand agilely to millions of entries through ongoing human-AI collaboration.
- Knowledge production scales to hundreds of millions of item updates per day on available hardware.
- Search traffic coverage reaches 80.4 percent with an 80 percent automated fill rate for core attributes.
- Item information quality issues decrease by 37 percent when the system is deployed in search, recommendation, and operations.
- Hundreds of billions of item-knowledge assets accumulate over time as the platform runs.
Where Pith is reading between the lines
- The same four-pillar structure could be tested on other large, frequently updated catalogs such as scientific publications or supply-chain inventories.
- If the self-evolving property holds, long-term operating costs might decline as manual oversight requirements shrink relative to catalog size.
- The unified tunnel might allow direct real-time feedback loops from downstream applications back into model improvement.
- Extending the ontology engineering pillar to incorporate user-generated content could further accelerate concept emergence handling.
Load-bearing premise
The self-evolving LLMs and VLMs together with the S2D architecture maintain their stated precision and recall across tens of billions of SKUs and hundreds of millions of daily updates without degradation or heavy manual intervention.
What would settle it
Observation of precision falling below 90 percent or recall below 75 percent on a production sample of several hundred million updates after initial deployment would falsify the performance claim.
Figures



read the original abstract
JD$.$com, one of the world's largest e-commerce platforms, serves over 700 million active users and millions of merchants, with a catalog of tens of billions of SKUs. At this scale, high-quality, structured item knowledge underpins a better consumer experience, lower management costs, and higher operational efficiency-yet producing and serving it poses three industrial-scale challenges: fast-emerging concepts, high-quality knowledge production for massive SKUs, and diverse downstream requirements. To address these challenges, we present the JD Oxygen AI Item Center (Oxygen AIIC), an industrial-scale platform built on LLMs/VLMs for item-knowledge production and service. Oxygen AIIC is built around four core pillars: (i) ontology engineering driven by efficient human-AI collaboration, which supports the dynamic evolution and agile expansion of an ontology with millions of entries; (ii) a "Semantic Search then Discrimination"(S2D) knowledge identification architecture that, combined with throughput improvement strategies, enables scalable, extensible, and high-throughput AI Item Library production for tens of billions of SKUs; (iii) self-evolving item-understanding LLMs/VLMs that improve in a stable and controllable manner, enabling knowledge production with 94.2% precision and 82.8% recall; and (iv) a unified item tunnel that serves as the data and service hub. Oxygen AIIC now covers tens of thousands of JD categories and processes hundreds of millions of item updates per day on Huawei Ascend NPUs. It has accumulated hundreds of billions of item-knowledge assets. Deployed across core business scenarios-including search, recommendation, operations, category planning-Oxygen AIIC has delivered measurable gains at scale. Search-traffic coverage reaches 80.4%, item-information quality issues drop by 37%, the automated fill rate of core attributes during item listing exceeds 80%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the JD Oxygen AI Item Center (Oxygen AIIC), an industrial platform for item knowledge production and service using LLMs and VLMs at JD.com's scale of tens of billions of SKUs. It is structured around four pillars: (i) ontology engineering via human-AI collaboration for dynamic ontology evolution, (ii) Semantic Search then Discrimination (S2D) architecture for scalable knowledge identification, (iii) self-evolving LLMs/VLMs achieving 94.2% precision and 82.8% recall, and (iv) a unified item tunnel for data and services. The system processes hundreds of millions of updates daily and reports business impacts like 80.4% search traffic coverage and 37% reduction in quality issues.
Significance. If the performance claims are substantiated, this work would be significant as one of the largest reported deployments of LLM/VLM systems in e-commerce, demonstrating practical solutions to challenges of scale, dynamic concepts, and diverse requirements. It provides a case study in integrating AI for knowledge management with measurable operational benefits.
major comments (1)
- [Abstract, pillar (iii)] Abstract, pillar (iii): The assertion that self-evolving item-understanding LLMs/VLMs improve in a stable and controllable manner, enabling knowledge production with 94.2% precision and 82.8% recall, is presented without any description of the evaluation methodology, test sets, baselines, ground-truth labeling process, or protocols for measuring stability across catalog size and update rates. This is central to validating the core technical contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of our industrial deployment. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract, pillar (iii)] Abstract, pillar (iii): The assertion that self-evolving item-understanding LLMs/VLMs improve in a stable and controllable manner, enabling knowledge production with 94.2% precision and 82.8% recall, is presented without any description of the evaluation methodology, test sets, baselines, ground-truth labeling process, or protocols for measuring stability across catalog size and update rates. This is central to validating the core technical contribution.
Authors: We agree that the evaluation methodology, test sets, baselines, ground-truth labeling process, and stability protocols are essential to substantiate the reported 94.2% precision and 82.8% recall. The current manuscript does not provide these details. In the revised version we will add a dedicated subsection under pillar (iii) that describes: (1) the construction and size of the held-out test sets, (2) the multi-stage human-expert ground-truth labeling protocol, (3) the baselines against which the self-evolving models are compared, and (4) the quantitative stability and controllability measurements across catalog scale and daily update volume. These additions will directly address the concern while preserving the industrial confidentiality constraints on proprietary data. revision: yes
Circularity Check
No circularity: high-level industrial system description with no derivations or self-referential predictions
full rationale
The paper is a descriptive account of an industrial platform (Oxygen AIIC) built around four pillars, with performance numbers (94.2% precision, 82.8% recall, 80.4% search coverage) asserted as outcomes of the deployed system. No equations, formal derivations, fitted parameters, or predictive claims appear in the provided text. The architecture claims (S2D, self-evolving models, ontology engineering) are presented as engineering choices rather than results derived from prior steps within the paper. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The numerical claims rest on undisclosed evaluation protocols rather than any internal reduction to inputs, so no circular step exists by the enumerated criteria.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.