REALM: A Unified Red-Teaming Benchmark for Physical-World VLMs
Pith reviewed 2026-06-26 08:42 UTC · model grok-4.3
The pith
REALM unifies red-teaming for physical-world VLMs by aligning attack objectives across methods via an agentic pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
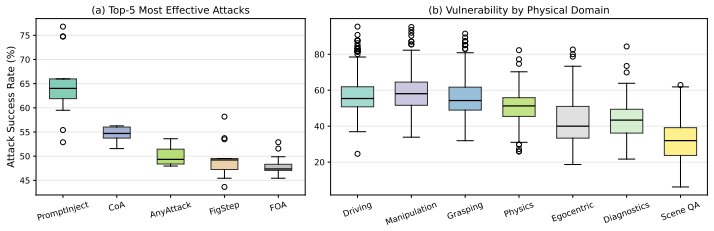
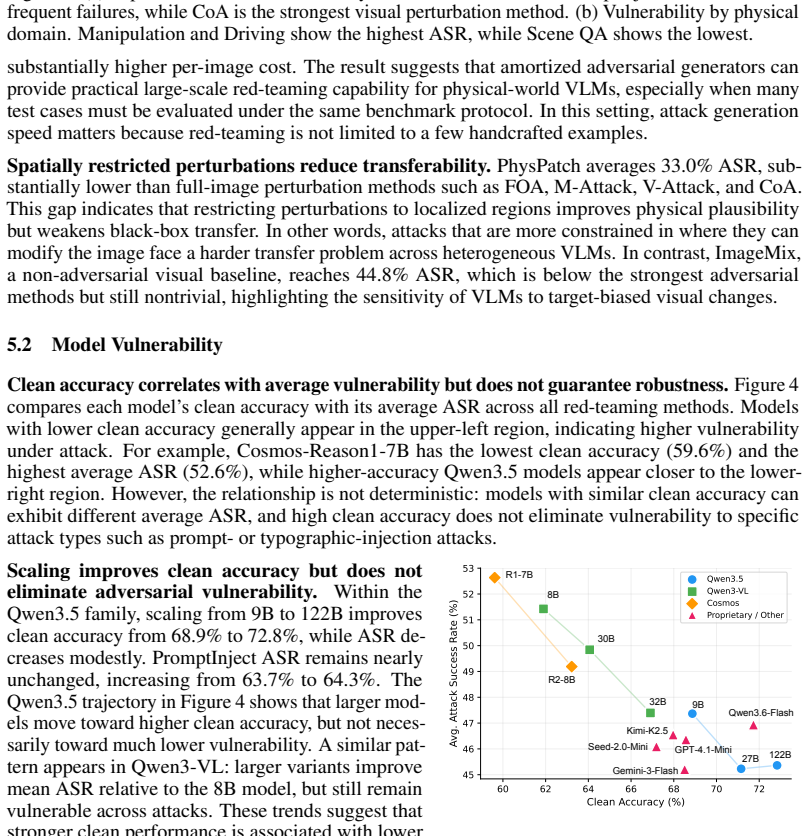
REALM integrates 12 red-teaming methods, 3 model-agnostic defenses, and 13 VLMs under a practical black-box threat model with shared datasets and metrics. To align adversarial objectives across attack families, REALM introduces an agentic target-generation pipeline that constructs shared, scenario-specific, and physically grounded attack objectives for each scene, enabling fair comparison of diverse red-teaming methods under aligned adversarial goals. Evaluation shows that text and typographic injection attacks induce the most failures, multimodal co-optimization yields the strongest visual-perturbation transfer, single-pass attacks approach iterative methods at much lower cost, and model sc
What carries the argument
The agentic target-generation pipeline, which builds shared, scenario-specific, physically grounded attack objectives for each scene to align goals across attack families.
If this is right
- Text and typographic injection attacks cause more failures than other families under the aligned objectives.
- Multimodal co-optimization produces the strongest transfer of visual perturbations across models.
- Single-pass attacks reach performance close to iterative methods while using far less computation.
- Larger model scale does not increase resistance to the tested attacks.
Where Pith is reading between the lines
- Future defenses may need to prioritize blocking text and typographic inputs in addition to visual changes.
- The cost advantage of single-pass attacks suggests they could become the default choice for practical red-teaming.
- Benchmarks built on aligned physical objectives could be applied to other embodied systems that use vision-language components.
- Robustness may require changes in training or architecture rather than relying on increased model size.
Load-bearing premise
The agentic target-generation pipeline produces attack objectives that are aligned and physically grounded enough for fair comparison across different red-teaming methods on the same scenes.
What would settle it
An experiment showing that the same scenes and models produce inconsistent failure modes when the agentic pipeline is removed or when different methods are allowed to choose their own targets.
Figures

read the original abstract
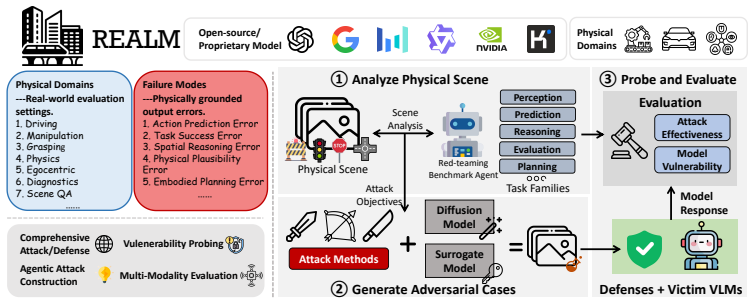
Vision-language models (VLMs) are increasingly used as perception-reasoning backbones for embodied intelligence in safety-critical physical systems, where perception or reasoning errors can lead to unsafe decisions or actions. Although many red-teaming methods have been developed to probe VLM vulnerabilities, their evaluation remains fragmented across datasets, metrics, and threat models, making direct comparison difficult and obscuring whether observed differences arise from stronger attacks, more vulnerable models, or incompatible evaluation settings. Existing chatbot-centric red-teaming benchmarks mainly standardize jailbreak and content-safety evaluation, but they do not systematically capture physically grounded functional failures or cover red-teaming methods that target physical-world VLMs. This raises the key challenge of comparing diverse attack methods under a unified protocol while targeting the same scenario-specific failures. We introduce REALM, to our knowledge the first unified red-teaming benchmark for physical-world VLMs. REALM integrates 12 red-teaming methods, 3 model-agnostic defenses, and 13 VLMs under a practical black-box threat model with shared datasets and metrics. To align adversarial objectives across attack families, REALM introduces an agentic target-generation pipeline that constructs shared, scenario-specific, and physically grounded attack objectives for each scene, enabling fair comparison of diverse red-teaming methods under aligned adversarial goals. Our evaluation shows that text and typographic injection attacks induce the most failures, multimodal co-optimization yields the strongest visual-perturbation transfer, single-pass attacks approach iterative methods at much lower cost, and model scale alone does not confer adversarial robustness. Code is available at https://github.com/UCF-ML-Research/REALM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REALM, the first unified red-teaming benchmark for physical-world VLMs. It integrates 12 red-teaming methods, 3 model-agnostic defenses, and 13 VLMs under a shared black-box threat model with common datasets and metrics. An agentic target-generation pipeline produces scenario-specific, physically grounded attack objectives to enable aligned comparisons across attack families. Evaluation results indicate that text and typographic injection attacks induce the most failures, multimodal co-optimization yields the strongest visual-perturbation transfer, single-pass attacks approach iterative methods at lower cost, and model scale alone does not confer robustness. Code is released at the provided GitHub link.
Significance. If the agentic pipeline produces consistently fair and physically realizable targets, REALM would provide a much-needed standardized protocol for comparing diverse red-teaming approaches on embodied VLMs, addressing fragmentation in current evaluations. The open-source code and shared metrics are clear strengths that could facilitate reproducible follow-up work. The reported findings on attack families and transfer would be actionable for safety-critical applications if the core alignment assumption holds.
major comments (2)
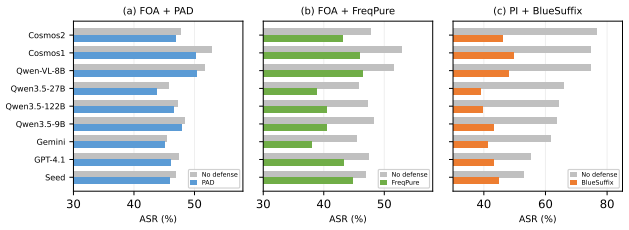
- [§3] §3 (Agentic Target-Generation Pipeline): The central claim of fair head-to-head comparison across 12 methods rests on the pipeline producing identical, scenario-specific, physically grounded targets. No validation details—such as inter-annotator agreement scores, expert review of realizability, or consistency checks across attack families—are provided, leaving open the possibility that targets are easier to satisfy via text/typographic injection than via visual perturbations.
- [§5] §5 (Evaluation Results): The finding that text/typographic attacks induce the most failures and that multimodal co-optimization transfers best is presented as intrinsic to the methods. Without reported metrics on target difficulty or realizability per attack family (e.g., success-rate baselines on clean targets or human-rated physical feasibility), these conclusions risk reflecting pipeline artifacts rather than attack strength.
minor comments (2)
- The abstract and introduction would benefit from a brief table summarizing the 12 methods, 3 defenses, and 13 VLMs with their categories to improve readability.
- Figure captions for attack visualizations should explicitly state whether examples are from the agentic pipeline or hand-crafted to allow readers to assess physical grounding.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the agentic target-generation pipeline and the interpretation of the evaluation results. We address each major comment below and will revise the manuscript to strengthen the claims where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Agentic Target-Generation Pipeline): The central claim of fair head-to-head comparison across 12 methods rests on the pipeline producing identical, scenario-specific, physically grounded targets. No validation details—such as inter-annotator agreement scores, expert review of realizability, or consistency checks across attack families—are provided, leaving open the possibility that targets are easier to satisfy via text/typographic injection than via visual perturbations.
Authors: We acknowledge that the current manuscript does not report explicit inter-annotator agreement scores, expert reviews of physical realizability, or per-family consistency checks for the generated targets. The pipeline constructs targets from scene descriptions and task requirements using an LLM agent before any attack method is selected, ensuring the objectives are method-agnostic. However, we agree that additional validation would better substantiate the fairness of the comparisons. In the revised version we will include human-rated feasibility scores, inter-annotator agreement on a subset of targets, and consistency statistics across attack families. revision: yes
-
Referee: [§5] §5 (Evaluation Results): The finding that text/typographic attacks induce the most failures and that multimodal co-optimization transfers best is presented as intrinsic to the methods. Without reported metrics on target difficulty or realizability per attack family (e.g., success-rate baselines on clean targets or human-rated physical feasibility), these conclusions risk reflecting pipeline artifacts rather than attack strength.
Authors: We agree that the absence of per-family target-difficulty metrics leaves open the possibility that observed differences partly reflect target properties rather than attack efficacy alone. The reported results are conditioned on the shared targets produced by the pipeline. To address this concern, the revision will add baseline success rates on clean targets, human-rated physical feasibility scores broken down by attack family, and a brief analysis of target difficulty distributions. revision: yes
Circularity Check
No circularity: benchmark construction with no derivations or fitted predictions.
full rationale
The paper introduces REALM as an empirical benchmark integrating 12 existing red-teaming methods, 3 defenses, and 13 VLMs under a shared black-box protocol. The agentic target-generation pipeline is presented as a methodological contribution for aligning objectives, not as a derived quantity or fitted parameter. No equations, self-referential predictions, uniqueness theorems, or ansatzes appear in the provided text. The work is self-contained via code release and does not reduce any central claim to its own inputs by construction. This is the expected outcome for a benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agentharm: A benchmark for measuring harmfulness of llm agents.arXiv preprint arXiv:2410.09024, 2024
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, et al. Agentharm: A benchmark for measuring harmfulness of llm agents.arXiv preprint arXiv:2410.09024, 2024
Pith/arXiv arXiv 2024
-
[2]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[3]
Impedancegpt: Vlm-driven impedance control of swarm of mini-drones for intelligent navigation in dynamic environment
Faryal Batool, Yasheerah Yaqoot, Malaika Zafar, Roohan Ahmed Khan, Muhammad Haris Khan, Aleksey Fedoseev, and Dzmitry Tsetserukou. Impedancegpt: Vlm-driven impedance control of swarm of mini-drones for intelligent navigation in dynamic environment. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2592–2597. IEEE, 2025
2025
-
[4]
Tim Beyer, Jonas Dornbusch, Jakob Steimle, Moritz Ladenburger, Leo Schwinn, and Stephan Günnemann. Adversariallm: A unified and modular toolbox for llm robustness research.arXiv preprint arXiv:2511.04316, 2025
arXiv 2025
-
[5]
Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity
ByteDance Seed. Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity. https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0%20Model%20Card.pdf, 2026. Model card
2026
-
[6]
Robo2VLM: Improving visual question answering using large-scale robot manipulation data
Kaiyuan Chen, Shuangyu Xie, Zehan Ma, Pannag R Sanketi, and Ken Goldberg. Robo2VLM: Improving visual question answering using large-scale robot manipulation data. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. URLhttps://openreview.net/forum?id=OChorZcZnY
2025
-
[7]
Physbench: Benchmarking and enhancing vision-language models for physi- cal world understanding
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Campagnolo Guizilini, and Yue Wang. Physbench: Benchmarking and enhancing vision-language models for physi- cal world understanding. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, edi- tors,International Conference on Learning Representations, volume 2025, pages 97959– 98108, 2025. URL https://proceedi...
2025
-
[8]
How robust is google’s bard to adversarial image attacks?arXiv preprint arXiv:2309.11751, 2023
Yinpeng Dong, Huanran Chen, Jiawei Chen, Zhengwei Fang, Xiao Yang, Yichi Zhang, Yu Tian, Hang Su, and Jun Zhu. How robust is google’s bard to adversarial image attacks?arXiv preprint arXiv:2309.11751, 2023
arXiv 2023
-
[9]
Red- teaming for generative ai: Silver bullet or security theater? InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 7, pages 421–437, 2024
Michael Feffer, Anusha Sinha, Wesley H Deng, Zachary C Lipton, and Hoda Heidari. Red- teaming for generative ai: Silver bullet or security theater? InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 7, pages 421–437, 2024
2024
-
[10]
Figstep: Jailbreaking large vision-language models via typographic visual prompts
Yichen Gong, Delong Ran, Jinyuan Liu, Conglei Wang, Tianshuo Cong, Anyu Wang, Sisi Duan, and Xiaoyun Wang. Figstep: Jailbreaking large vision-language models via typographic visual prompts. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23951–23959, 2025
2025
-
[11]
Gemini 3 Flash: Model Card
Google DeepMind. Gemini 3 Flash: Model Card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf , December 2025. Model card
2025
-
[12]
Qi Guo, Xiaojun Jia, Shanmin Pang, Simeng Qin, Lin Wang, Ju Jia, Yang Liu, and Qing Guo. Physpatch: A physically realizable and transferable adversarial patch attack for multimodal large language models-based autonomous driving systems.arXiv preprint arXiv:2508.05167, 2025
arXiv 2025
-
[13]
Qi Guo, Shanmin Pang, Xiaojun Jia, Yang Liu, and Qing Guo. Efficient generation of targeted and transferable adversarial examples for vision-language models via diffusion models.IEEE Transactions on Information Forensics and Security, 20:1333–1348, 2025. doi: 10.1109/TIFS. 2024.3518072. 10
-
[14]
Playing the fool: Jailbreaking llms and multimodal llms with out-of-distribution strategy
Joonhyun Jeong, Seyun Bae, Yeonsung Jung, Jaeryong Hwang, and Eunho Yang. Playing the fool: Jailbreaking llms and multimodal llms with out-of-distribution strategy. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29937–29946, 2025
2025
-
[15]
Xiaojun Jia, Sensen Gao, Simeng Qin, Tianyu Pang, Chao Du, Yihao Huang, Xinfeng Li, Yiming Li, Bo Li, and Yang Liu. Adversarial attacks against closed-source mllms via feature optimal alignment.arXiv preprint arXiv:2505.21494, 2025
arXiv 2025
-
[16]
Pad: Patch-agnostic defense against adversarial patch attacks
Lihua Jing, Rui Wang, Wenqi Ren, Xin Dong, and Cong Zou. Pad: Patch-agnostic defense against adversarial patch attacks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24472–24481, 2024
2024
-
[17]
Freqpure: a high-frequency preservation diffusion-based purification method for protective perturbation removal
Yan Ju, Hongfei Xue, and Siwei Lyu. Freqpure: a high-frequency preservation diffusion-based purification method for protective perturbation removal. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2025
2025
-
[18]
A frustratingly simple yet highly effective attack baseline: Over 90% success rate against the strong black-box models of GPT-4.5/4o/o1
Zhaoyi Li, Xiaohan Zhao, Dong-Dong Wu, Jiacheng Cui, and Zhiqiang Shen. A frustratingly simple yet highly effective attack baseline: Over 90% success rate against the strong black-box models of GPT-4.5/4o/o1. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=9xXjWwAoUF
2025
-
[19]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
Pith/arXiv arXiv 2024
-
[20]
Hefei Mei, Zirui Wang, Chang Xu, Jianyuan Guo, and Minjing Dong. Pa-attack: Guid- ing gray-box attacks on lvlm vision encoders with prototypes and attention.arXiv preprint arXiv:2602.19418, 2026
arXiv 2026
-
[21]
Sen Nie, Jie Zhang, Jianxin Yan, Shiguang Shan, and Xilin Chen. V-attack: Targeting disentangled value features for controllable adversarial attacks on lvlms.arXiv preprint arXiv:2511.20223, 2025
arXiv 2025
-
[22]
Cosmos-Reason1-7B
NVIDIA. Cosmos-Reason1-7B. https://huggingface.co/nvidia/ Cosmos-Reason1-7B. Hugging Face model card
-
[23]
GPT-4.1 mini Model
OpenAI. GPT-4.1 mini Model. https://developers.openai.com/api/docs/models/ gpt-4.1-mini, 2025. OpenAI API documentation
2025
-
[24]
Red teaming language models with language models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419–3448, 2022
2022
-
[25]
Qwen3.6.https://qwen3lm.com/qwen3.6/, 2026
Qwen. Qwen3.6.https://qwen3lm.com/qwen3.6/, 2026. Model documentation
2026
-
[26]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5
2026
-
[27]
Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
Pith/arXiv arXiv 2025
-
[28]
Xin Wang, Yunhao Chen, Juncheng Li, Yixu Wang, Yang Yao, Tianle Gu, Jie Li, Yan Teng, Yingchun Wang, and Xia Hu. Openrt: An open-source red teaming framework for multimodal llms.arXiv preprint arXiv:2601.01592, 2026
arXiv 2026
-
[29]
AdvEDM: Fine-grained adversarial attack against VLM-based embodied agents
Yichen Wang, Hangtao Zhang, Hewen Pan, Ziqi Zhou, Xianlong Wang, Peijin Guo, Lulu Xue, Shengshan Hu, Minghui Li, and Leo Yu Zhang. AdvEDM: Fine-grained adversarial attack against VLM-based embodied agents. InThe Thirty-ninth Annual Conference on Neu- ral Information Processing Systems, 2025. URL https://openreview.net/forum?id= jmLCBLeEC4. 11
2025
-
[30]
Jailbroken: How does llm safety training fail? In A
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does llm safety training fail? In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 80079–80110. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/ 2023/file/...
2023
-
[31]
Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
Pith/arXiv arXiv 2025
-
[32]
Chain of attack: On the robustness of vision-language models against transfer-based adversarial attacks
Peng Xie, Yequan Bie, Jianda Mao, Yangqiu Song, Yang Wang, Hao Chen, and Kani Chen. Chain of attack: On the robustness of vision-language models against transfer-based adversarial attacks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14679–14689, 2025
2025
-
[33]
Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives
Shaoyuan Xie, Lingdong Kong, Yuhao Dong, Chonghao Sima, Wenwei Zhang, Qi Alfred Chen, Ziwei Liu, and Liang Pan. Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6585–6597, October 2025
2025
-
[34]
Trojllm: A black-box trojan prompt attack on large language models.Advances in Neural Information Processing Systems, 36:65665–65677, 2023
Jiaqi Xue, Mengxin Zheng, Ting Hua, Yilin Shen, Yepeng Liu, Ladislau Bölöni, and Qian Lou. Trojllm: A black-box trojan prompt attack on large language models.Advances in Neural Information Processing Systems, 36:65665–65677, 2023
2023
-
[35]
Jiaqi Xue, Mengxin Zheng, Yebowen Hu, Fei Liu, Xun Chen, and Qian Lou. Badrag: Identifying vulnerabilities in retrieval augmented generation of large language models.arXiv preprint arXiv:2406.00083, 2024
arXiv 2024
-
[36]
Jiaqi Xue, Yifei Zhao, Mansour Al Ghanim, Shangqian Gao, Ruimin Sun, Qian Lou, and Mengxin Zheng. Pro: Enabling precise and robust text watermark for open-source llms.arXiv preprint arXiv:2510.23891, 2025
arXiv 2025
-
[37]
R2-router: A new paradigm for llm routing with reasoning.arXiv preprint arXiv:2602.02823, 2026
Jiaqi Xue, Qian Lou, Jiarong Xing, and Heng Huang. R2-router: A new paradigm for llm routing with reasoning.arXiv preprint arXiv:2602.02823, 2026
Pith/arXiv arXiv 2026
-
[38]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[39]
Anyattack: Towards large-scale self-supervised adversarial attacks on vision-language models
Jiaming Zhang, Junhong Ye, Xingjun Ma, Yige Li, Yunfan Yang, Yunhao Chen, Jitao Sang, and Dit-Yan Yeung. Anyattack: Towards large-scale self-supervised adversarial attacks on vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19900–19909, 2025
2025
-
[40]
Physreason: A comprehensive benchmark towards physics-based reasoning
Xinyu Zhang, Yuxuan Dong, Yanrui Wu, Jiaxing Huang, Chengyou Jia, Basura Fernando, Mike Zheng Shou, Lingling Zhang, and Jun Liu. Physreason: A comprehensive benchmark towards physics-based reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16593–16615, 2025
2025
-
[41]
Sif: Semantically in-distribution fingerprints for large vision-language models
Yifei Zhao, Qian Lou, and Mengxin Zheng. Sif: Semantically in-distribution fingerprints for large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17399–17408, June 2026
2026
-
[42]
Bluesuffix: Reinforced blue teaming for vision-language models against jailbreak attacks
Yunhan Zhao, Xiang Zheng, Lin Luo, Yige Li, Xingjun Ma, and Yu-Gang Jiang. Bluesuffix: Reinforced blue teaming for vision-language models against jailbreak attacks. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,In- ternational Conference on Learning Representations, volume 2025, pages 35443– 35462, 2025. URL https://proceedings.iclr.cc/paper_fi...
2025
-
[43]
Trojfsp: Trojan insertion in few-shot prompt tuning
Mengxin Zheng, Jiaqi Xue, Xun Chen, Yanshan Wang, Qian Lou, and Lei Jiang. Trojfsp: Trojan insertion in few-shot prompt tuning. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1141–1151, 2024. 12
2024
-
[44]
Ssl-cleanse: Trojan detection and mitigation in self-supervised learning
Mengxin Zheng, Jiaqi Xue, Zihao Wang, Xun Chen, Qian Lou, Lei Jiang, and Xiaofeng Wang. Ssl-cleanse: Trojan detection and mitigation in self-supervised learning. InEuropean Conference on Computer Vision, pages 405–421. Springer, 2024
2024
-
[45]
Andy Zhou, Kevin Wu, Francesco Pinto, Zhaorun Chen, Yi Zeng, Yu Yang, Shuang Yang, Sanmi Koyejo, James Zou, and Bo Li. Autoredteamer: Autonomous red teaming with lifelong attack integration.arXiv preprint arXiv:2503.15754, 2025
arXiv 2025
-
[46]
Main object: stop sign
Fengzhe Zhou, Jiannan Huang, Jialuo Li, Deva Ramanan, and Humphrey Shi. Pai-bench: A comprehensive benchmark for physical ai. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 13 Appendix Contents A. Model Details15 B. Dataset Composition15 C. Pre-Attack Target-Choice Calibration15 D. Attack Method Details D...
2026
-
[47]
Identify the physical domain and key objects
Examine the source image. Identify the physical domain and key objects
-
[48]
Determine which failure mode applies
Read the question. Determine which failure mode applies
-
[49]
For each wrong option: what single visual cue change would make it correct?
-
[50]
Pick the option where the cue change is most visually unambiguous
-
[51]
State the causal chain: SOURCE_CUE→CORRECT_ANSWER, TARGET_CUE→ WRONG_ANSWER
-
[52]
Write a generation prompt that depicts TARGET_CUE clearly. Output format: FAILURE_MODE:〈one of the six modes〉 ATTACK_TARGET:〈letter〉 SOURCE_CUE:〈visual cue in source image〉 TARGET_CUE:〈visual cue in target image〉 GENERATION_PROMPT:〈image generation prompt〉 H Compute Resources All experiments were conducted on a single NVIDIA B200 GPU (192 GB VRAM). Local ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.