Implementation and Workflows for INLA-Based Approximate Bayesian Structural Equation Modelling
Pith reviewed 2026-05-21 10:32 UTC · model grok-4.3
The pith
Approximate Bayesian methods allow structural equation models to yield posterior summaries in seconds instead of hours of MCMC sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By developing specific architectural decisions and computational strategies for embedding the integrated nested Laplace approximation within structural equation model specifications, the work demonstrates that accurate Bayesian inference becomes practical for high-dimensional models, delivering results in seconds where traditional methods require hours and careful monitoring for convergence.
What carries the argument
The integrated nested Laplace approximation applied to structural equation models, which computes marginal posterior distributions efficiently without full sampling.
If this is right
- Psychometric model building cycles can proceed with rapid feedback from posterior inferences.
- Complex specifications such as bifactor models become accessible to Bayesian analysis without prohibitive computation times.
- Missing data in multilevel models can be handled in a full-information Bayesian manner efficiently.
- Practitioners gain the benefits of principled uncertainty quantification and small-sample regularisation in structural equation modelling.
Where Pith is reading between the lines
- This speed could encourage wider adoption of Bayesian methods in fields relying on latent variable models.
- Similar approximations might be developed for related models like item response theory or factor analysis extensions.
- Validation against MCMC on additional benchmark datasets would further establish reliability.
- The approach opens the door to real-time model exploration in large-scale applications.
Load-bearing premise
The Laplace approximation provides sufficiently accurate posterior summaries for the demonstrated high-dimensional structural equation models.
What would settle it
A direct comparison of posterior means, variances, and interval coverage between the approximate method and a converged MCMC run on the 256-parameter bifactor model; systematic differences would indicate the approximation is not calibrated.
Figures









read the original abstract
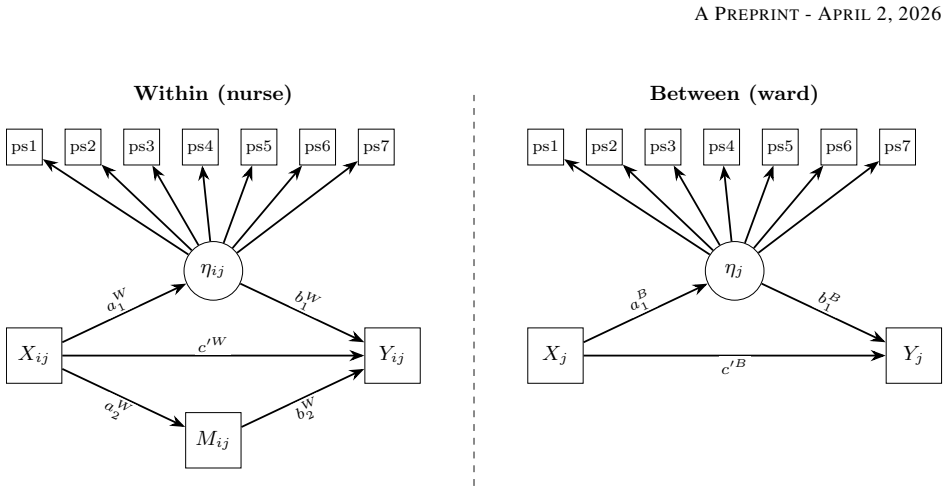
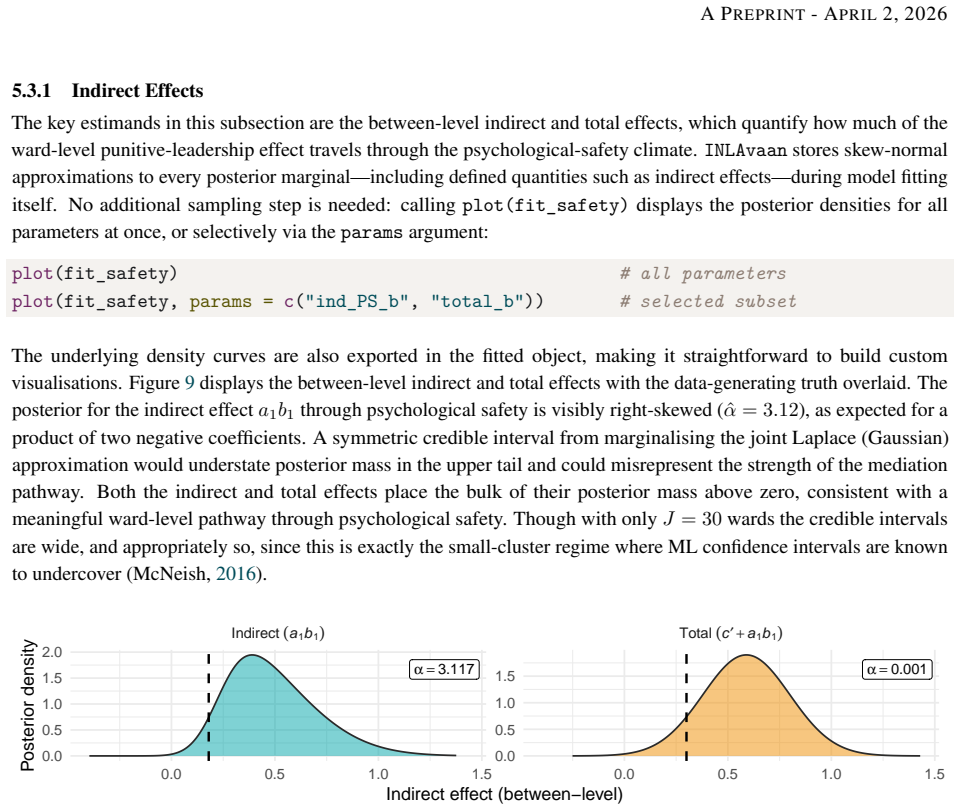
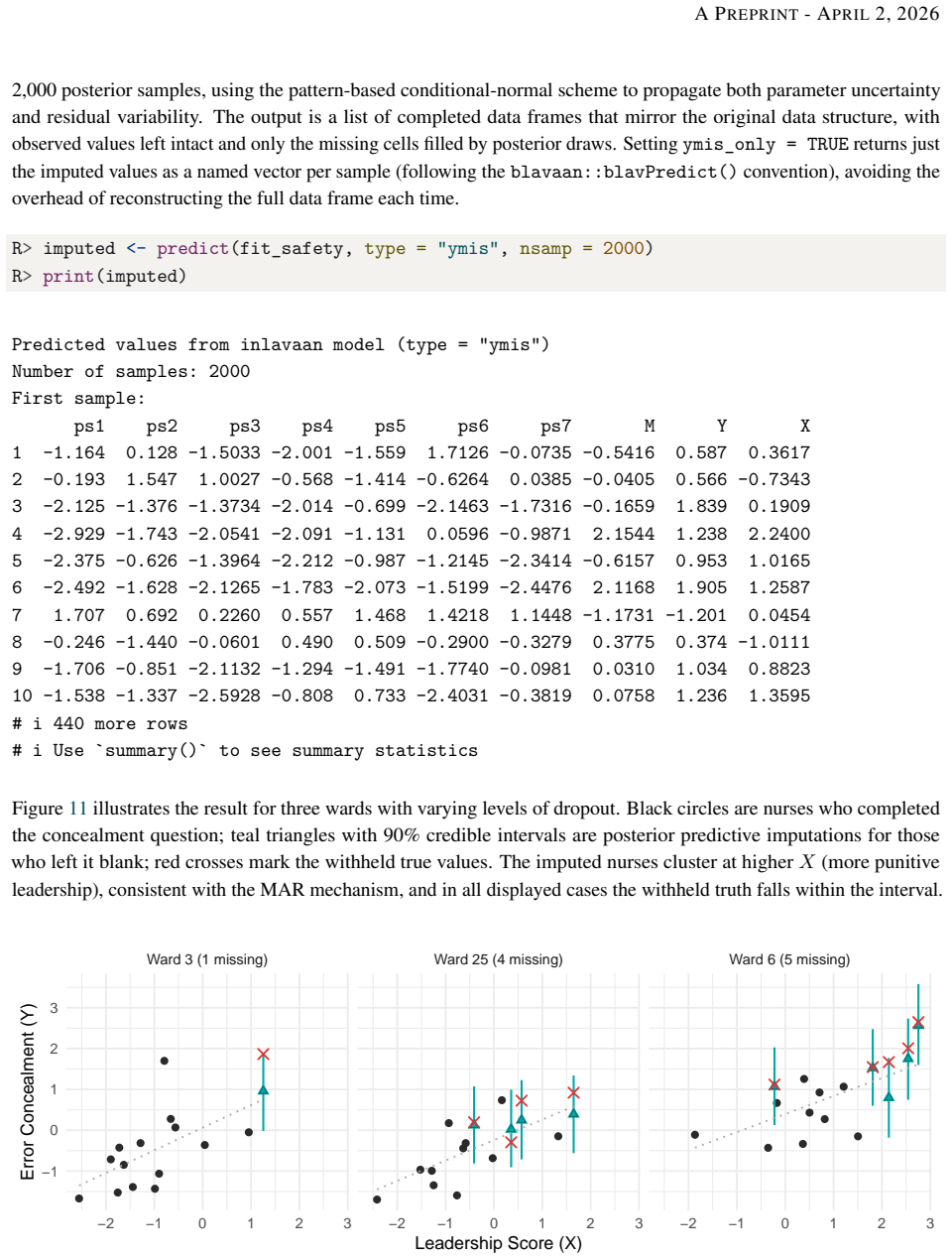
Bayesian structural equation modelling (BSEM) offers many advantages such as principled uncertainty quantification, small-sample regularisation, and flexible model specification. However, the Markov chain Monte Carlo (MCMC) methods on which it relies are computationally prohibitive for the iterative cycle of specification, criticism, and refinement that careful psychometric practice demands. We present INLAvaan, an R package for fast, approximate Bayesian SEM built around the Integrated Nested Laplace Approximation (INLA) framework for structural equation models developed by Jamil & Rue (2026, arXiv:2603.25690 [stat.ME]). This paper serves as a companion manuscript that describes the architectural decisions and computational strategies underlying the package. Two substantive applications -- a 256-parameter bifactor circumplex model and a multilevel mediation model with full-information missing-data handling -- demonstrate the approach on specifications where MCMC would require hours of run time and careful convergence work. In constrast, INLAvaan delivers calibrated posterior summaries in seconds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the INLAvaan R package for approximate Bayesian structural equation modeling using the INLA framework from the companion paper by Jamil & Rue (arXiv:2603.25690). It details architectural and computational decisions for the implementation and demonstrates the package on two applications: a 256-parameter bifactor circumplex model and a multilevel mediation model with full-information missing-data handling. The central claim is that INLAvaan produces calibrated posterior summaries in seconds for models where MCMC would require hours.
Significance. If the calibration and accuracy claims hold for the demonstrated high-dimensional specifications, the work would meaningfully advance practical Bayesian SEM by enabling rapid iterative specification, criticism, and refinement cycles in psychometrics. The emphasis on reproducible workflows, missing-data handling, and open implementation provides concrete value for users transitioning from MCMC.
major comments (2)
- Abstract: the assertion that INLAvaan 'delivers calibrated posterior summaries' for the 256-parameter bifactor circumplex model is not supported by any quantitative validation (e.g., parameter recovery rates, coverage probabilities, or bias metrics) within this manuscript.
- Applications section (bifactor circumplex model): no simulation study, side-by-side MCMC comparison on an overlapping specification, or posterior predictive/calibration diagnostics are reported, so the claim that posteriors remain calibrated (rather than merely fast) rests on untested transfer of accuracy from the companion paper.
minor comments (1)
- The manuscript would benefit from explicit statements of the package's core functions, input/output formats, and a minimal reproducible example workflow for the bifactor model.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address the major comments point by point below and have revised the manuscript to better clarify the division of labour between this implementation paper and the companion methodological paper.
read point-by-point responses
-
Referee: Abstract: the assertion that INLAvaan 'delivers calibrated posterior summaries' for the 256-parameter bifactor circumplex model is not supported by any quantitative validation (e.g., parameter recovery rates, coverage probabilities, or bias metrics) within this manuscript.
Authors: We agree that the abstract statement would benefit from greater precision. This manuscript is the implementation companion and does not contain new simulation-based validation metrics for the 256-parameter model. The calibration properties of the underlying INLA approximation for high-dimensional SEMs are established in the companion methodological paper (Jamil & Rue, arXiv:2603.25690). We have revised the abstract to read that INLAvaan delivers posterior summaries whose calibration follows from the results reported in that companion paper. revision: yes
-
Referee: Applications section (bifactor circumplex model): no simulation study, side-by-side MCMC comparison on an overlapping specification, or posterior predictive/calibration diagnostics are reported, so the claim that posteriors remain calibrated (rather than merely fast) rests on untested transfer of accuracy from the companion paper.
Authors: We accept the observation that this paper reports neither new simulation studies nor direct MCMC comparisons for the bifactor specification. The purpose of the applications section is to illustrate computational performance and reproducible workflows on models that are practically intractable for routine MCMC use. Validation of the approximation accuracy, including for models of this dimensionality, is contained in the companion methodological paper. We have added an explicit cross-reference in the applications section directing readers to those calibration results, thereby removing any implication of untested transfer. revision: yes
Circularity Check
Calibration claim for 256-parameter bifactor model rests on untested transfer of INLA accuracy from companion paper without direct validation
specific steps
-
self citation load bearing
[Abstract]
"We present INLAvaan, an R package for fast, approximate Bayesian SEM built around the Integrated Nested Laplace Approximation (INLA) framework for structural equation models developed by Jamil & Rue (2026, arXiv:2603.25690 [stat.ME]). This paper serves as a companion manuscript that describes the architectural decisions and computational strategies underlying the package. ... In constrast, INLAvaan delivers calibrated posterior summaries in seconds."
The assertion that posteriors are 'calibrated' (rather than merely fast) is justified only by citing the INLA SEM approximation developed in the authors' overlapping prior paper; the present manuscript reports no independent validation, simulation recovery, or MCMC benchmark for the 256-parameter or multilevel models shown.
full rationale
The manuscript is an implementation companion that demonstrates runtime advantages on complex SEMs. The central substantive claim—that INLAvaan produces calibrated posterior summaries—rests entirely on the accuracy properties established in the authors' own prior work (arXiv:2603.25690). No recovery simulations, MCMC side-by-side comparisons, or calibration diagnostics are reported for the demonstrated models, including the high-dimensional bifactor case. This is a load-bearing self-citation for the accuracy assertion while the speed claim remains independently observable, producing a moderate circularity score without reducing the entire result to definition or forcing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The INLA approximation developed in Jamil & Rue (2026) yields calibrated posteriors for the class of SEM models considered
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
INLAvaan delivers calibrated posterior summaries in seconds for specifications where MCMC would require hours... 256-parameter bifactor circumplex model
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The approximation recipe of Jamil and Rue (2026)... four main stages: (i) transform... locate posterior mode; (ii) shift... variational correction; (iii) profile each marginal and fit a skew-normal; (iv) reconstruct joint samples through a Gaussian copula
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J., Kochurov, M., Kumar, R., Lao, J., Luhmann, C
Abril-Pla, O., Andreani, V ., Carroll, C., Dong, L., Fonnesbeck, C. J., Kochurov, M., Kumar, R., Lao, J., Luhmann, C. C., Martin, O. A., Osthege, M., Vieira, R., Wiecki, T., & Zinkov, R. (2023). PyMC: A modern and comprehensive probabilistic programming framework in Python.PeerJ Computer Science,9(e1516). https://doi.org/10.7717/p eerj-cs.1516 Arbuckle, J...
work page doi:10.7717/p 2023
-
[2]
https://doi.org/10.1186/s12912-025-03043-7 32 A PREPRINT- APRIL2, 2026 Enders, C. K. (2022).Applied missing data analysis. Guilford Publications. Erosheva, E. A., & Curtis, S. M. (2017). Dealing with reflection invariance in Bayesian factor analysis.Psychometrika, 82(2), 295–307. https://doi.org/10.1007/s11336-017-9564-y Fabrigar, L. R., Visser, P. S., & ...
-
[3]
Anderson localization in an interacting fermionic system
https://doi.org/10.1207/s15327957pspr0103_1 Frazier, M. L., Fainshmidt, S., Klinger, R. L., Pezeshkan, A., & Vracheva, V . (2017). Psychological safety: A meta- analytic review and extension.Personnel Psychology,70(1), 113–165. https://doi.org/10.1111/peps.12183 Garnier-Villarreal, M., & Jorgensen, T. D. (2020). Adapting fit indices for Bayesian structura...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1207/s15327957pspr0103_1 2017
-
[4]
MacCallum, R. C., Edwards, M. C., & Cai, L. (2012). Hopes and cautions in implementing Bayesian structural equation modeling.Psychological Methods,17(3), 340–345, discussion 346–353. https://doi.org/10.1037/a0027131 MacKinnon, D. P. (2008).Introduction to statistical mediation analysis. Lawrence Erlbaum Associates. Martin, J. K., & McDonald, R. P. (1975)....
-
[5]
https://doi.org/10.1037/0021-9010.91.4.946 Nielsen, H. B., & Mortensen, S. B. (2024).ucminf: General-purpose unconstrained non-linear optimization(R package version 1.2.2). https://doi.org/10.32614/CRAN.package.ucminf Owen, A. B. (1998). Scrambling Sobol and Niederreiter–Xing points.Journal of Complexity,14(4), 466–489. https://do i.org/10.1006/jcom.1998....
-
[6]
https://doi.org/10.1186/s12912-022-01123-6 Skrondal, A., & Rabe-Hesketh, S. (2004).Generalized latent variable modeling: Multilevel, longitudinal, and structural equation models. Chapman & Hall/CRC. Skrondal, A., & Rabe-Hesketh, S. (2009). Prediction in multilevel generalized linear models.Journal of the Royal Statistical Society Series A: Statistics in S...
-
[7]
https://www.stata.com Stegmueller, D
College Station, TX. https://www.stata.com Stegmueller, D. (2013). How many countries for multilevel modeling? A comparison of frequentist and bayesian approaches.American Journal of Political Science,57(3), 748–761. https://doi.org/10.1111/ajps.12001 35 A PREPRINT- APRIL2, 2026 Talts, S., Betancourt, M., Simpson, D., Vehtari, A., & Gelman, A. (2020).Vali...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.