PENet+: A Lightweight Residual Transformer Framework for Efficient Image Steganalysis
Pith reviewed 2026-06-27 13:27 UTC · model grok-4.3
The pith
PENet+ cuts up to 45.5% parameters and 97% FLOPs from a residual transformer for image steganalysis while holding accuracy steady on ALASKA2.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
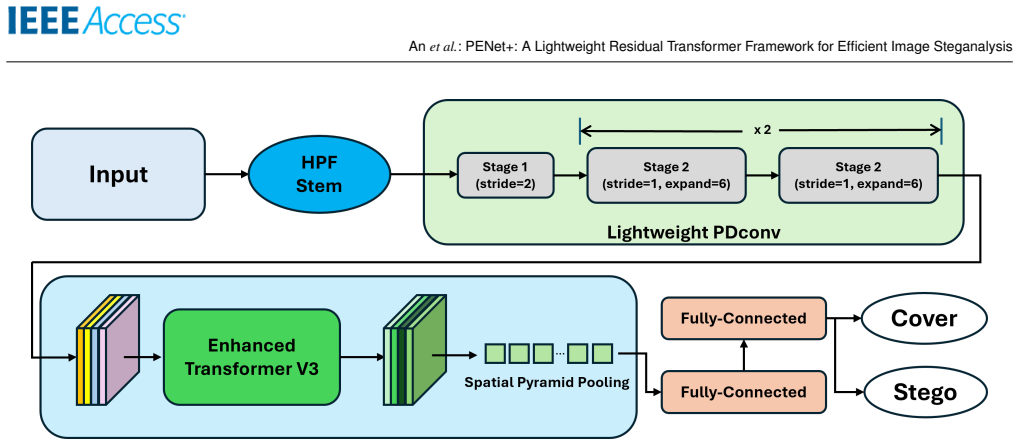
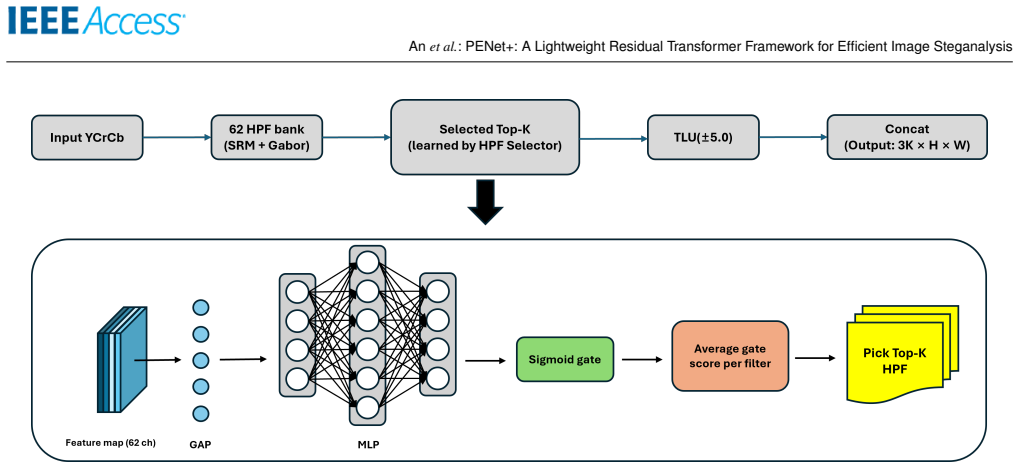
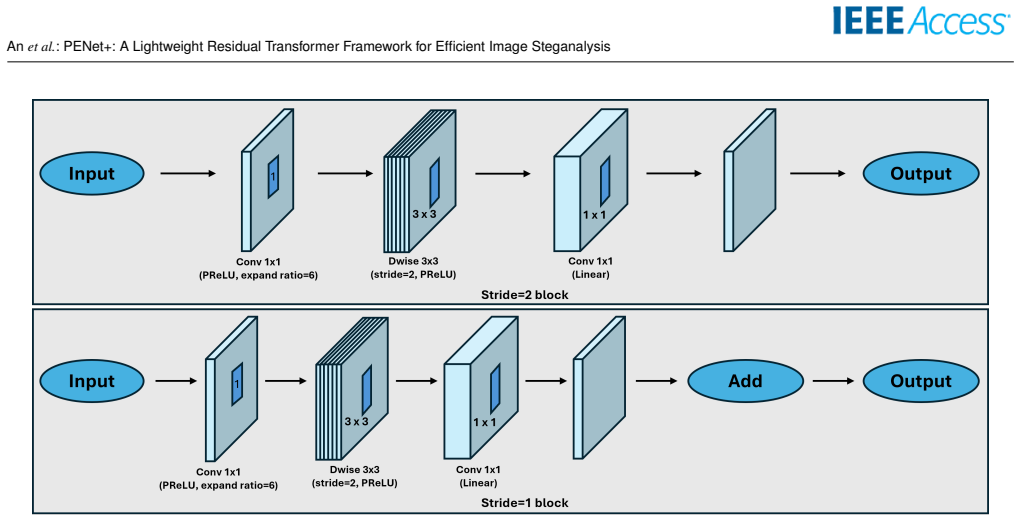
PENet+ matches or exceeds the detection accuracy of the re-evaluated PENet baseline on a disjoint ALASKA2 JPEG QF90 test set of 19,000 cover images by applying three targeted changes: a progressive narrowing of channels between spatial pyramid pooling and the first fully connected layer, an activation-aware early aggregation that selects a balanced set of 31 SRM-Gabor high-pass filters, and replacement of the backbone with MobileNetV2-style inverted residual blocks. The balanced K=31 configuration yields up to 45.5 percent fewer parameters and roughly 97 percent fewer FLOPs at 512 by 512 resolution.
What carries the argument
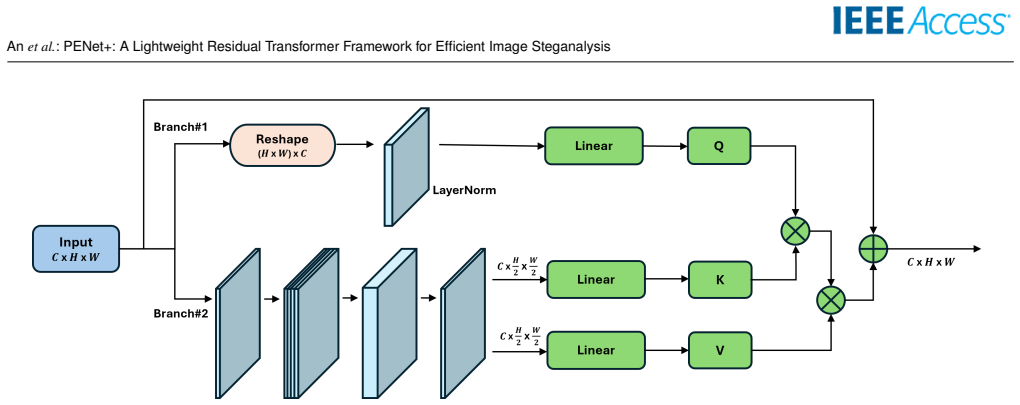
Classifier-streamlining stage that progressively narrows SPP-to-FC1 input channels, paired with activation-aware top-K SRM-Gabor HPF selection and a MobileNetV2-style inverted residual backbone.
If this is right
- Resource-limited devices become practical hosts for residual-transformer steganalysis without redesigning the attention layers.
- The same narrowing and top-K refinement steps can be applied to other residual transformer steganalysis models to reduce their compute footprint.
- Preserving negative filter responses via PReLU retains weak stego signals that ReLU would discard.
- A balanced 16-Gabor plus 15-SRM filter set at K=31 performs at least as well as larger or unbalanced sets at lower cost.
Where Pith is reading between the lines
- The approach could transfer to related forensic tasks such as detecting manipulated images where memory and latency constraints are similar.
- Hardware measurements on actual edge devices would be needed to confirm whether the reported FLOP reductions translate into proportional speed or power savings.
- The top-K selection rule might be tested on other embedding algorithms beyond the ALASKA2 protocol to check its generality.
Load-bearing premise
The chosen channel-narrowing schedule, K=31 filter selection, and backbone swap preserve the original model's detection accuracy on the ALASKA2 split without any post-hoc loss.
What would settle it
A statistically significant drop in detection accuracy below the PENet baseline when the K=31 balanced configuration is evaluated on the separate 19,000-cover ALASKA2 JPEG QF90 set.
Figures

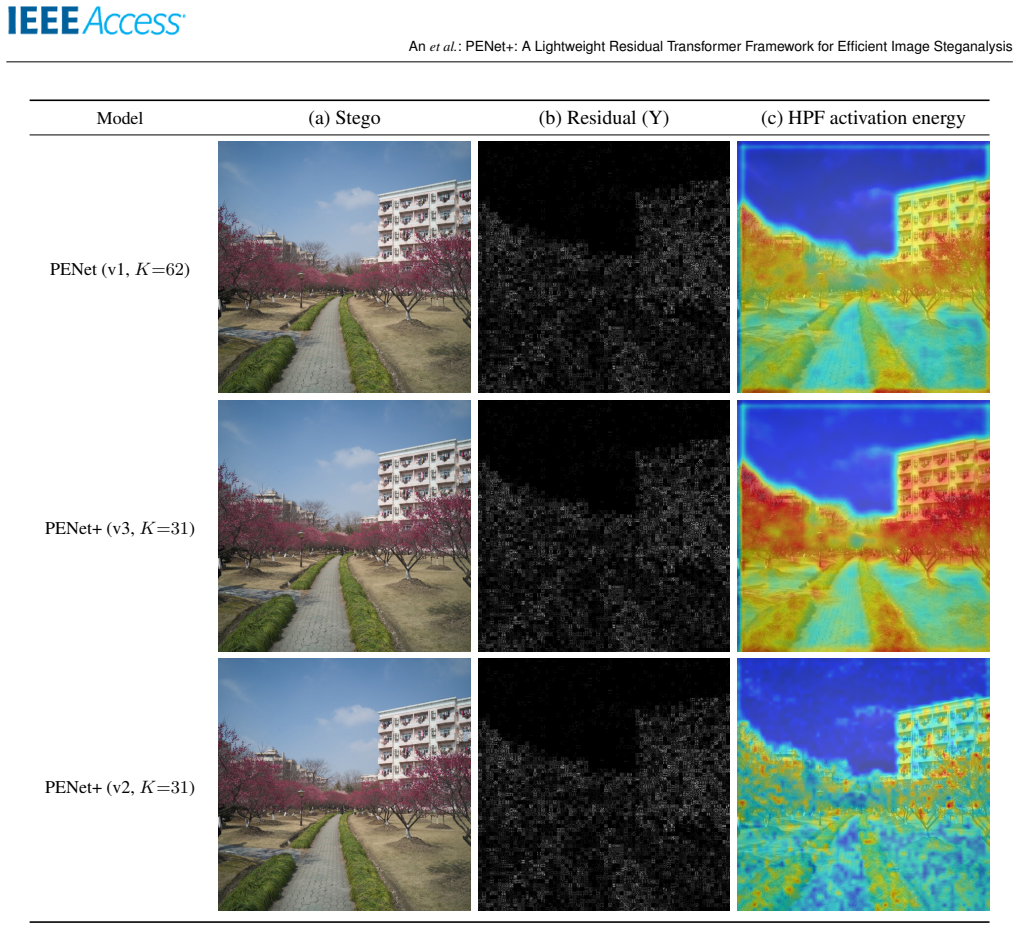
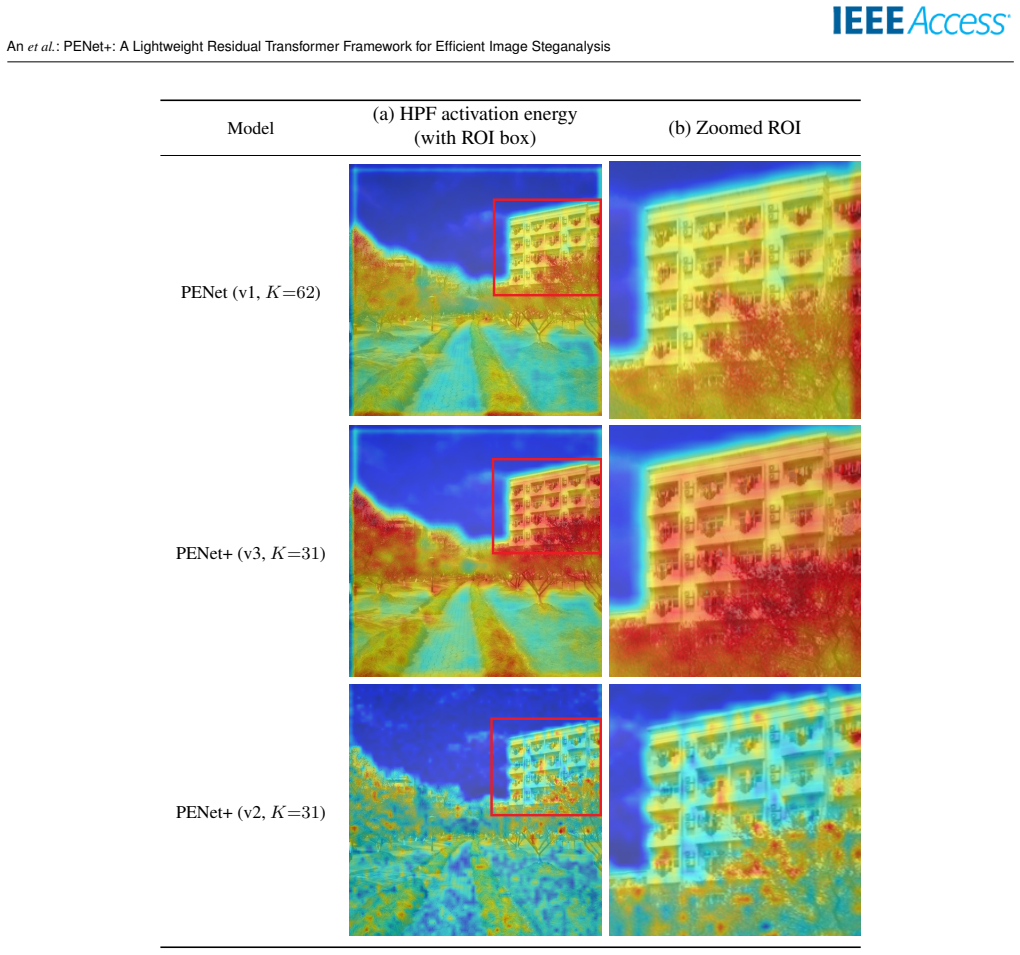
read the original abstract
Image steganalysis, the detection of hidden information embedded in digital images, is a core component of modern cybersecurity and digital forensics. Recent residual Transformer architectures, such as the Pixel-Difference-Convolution and Enhanced-Transformer-Network (PENet) [1], achieve strong detection accuracy, but their computational and memory demands hinder deployment in resource-constrained settings. We present PENet+, a lightweight steganalysis framework that preserves PENet's discriminative structure while substantially improving efficiency. Rather than redesigning or compressing the attention blocks, we retain PENet's self-attention topology for reproducibility and add a classifier-streamlining stage that progressively narrows the SPP-to-FC1 input channels (SPP: spatial pyramid pooling; FC1: first fully connected layer), yielding large reductions in parameters and FLOPs with negligible accuracy loss. We further refine the high-pass-filter (HPF) stem with an activation-aware mechanism that aggregates HPF responses early and selects a balanced SRM-Gabor top-K subset, and we replace PENet's backbone with a MobileNetV2-style inverted residual network. A balanced configuration with K=31 filters (16 Gabor + 15 SRM) matches or surpasses heavier settings at lower compute. Finally, we motivate PReLU from a steganalysis standpoint, arguing that preserving negative responses helps capture weak stego cues that ReLU suppresses. On a disjoint ALASKA2 JPEG QF90 protocol at 512x512 resolution (5,000 cover images for training, validation, and internal testing; a separate 19,000-cover evaluation set), PENet+ achieves up to 45.5% fewer parameters and about 97% fewer FLOPs than the re-evaluated PENet baseline, offering a computationally efficient direction for resource-constrained steganalysis. Device-level latency and power measurements remain future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PENet+, a lightweight variant of the PENet residual Transformer for image steganalysis. It retains the original self-attention topology while adding a classifier-streamlining stage that narrows SPP-to-FC1 channels, refines the HPF stem via an activation-aware SRM-Gabor top-K selection (balanced K=31), substitutes a MobileNetV2-style inverted residual backbone, and motivates PReLU to preserve negative responses for weak stego cues. On a disjoint ALASKA2 JPEG QF90 512x512 protocol (5k training/validation/internal test covers; separate 19k evaluation covers), it claims up to 45.5% fewer parameters and ~97% fewer FLOPs than the re-evaluated PENet baseline with negligible accuracy loss.
Significance. If the accuracy-preservation claim holds, the work supplies a concrete efficiency direction for resource-constrained steganalysis, an area where existing high-accuracy detectors are often impractical. Retaining the original self-attention topology for reproducibility is a positive design choice that aids verification.
major comments (1)
- [Abstract] Abstract: The central claim that the three modifications (classifier-channel narrowing, K=31 SRM-Gabor top-K, MobileNetV2-style backbone) incur only 'negligible accuracy loss' and that the K=31 configuration 'matches or surpasses heavier settings' is unsupported by any reported detection error rates, AUC values, or ablation tables on the 19,000-cover evaluation set. Without these numbers the efficiency gains (45.5% params, 97% FLOPs) cannot be assessed against possible degradation in discriminative power.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the claims regarding accuracy preservation require explicit supporting metrics on the evaluation set to allow proper assessment of the efficiency gains.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the three modifications (classifier-channel narrowing, K=31 SRM-Gabor top-K, MobileNetV2-style backbone) incur only 'negligible accuracy loss' and that the K=31 configuration 'matches or surpasses heavier settings' is unsupported by any reported detection error rates, AUC values, or ablation tables on the 19,000-cover evaluation set. Without these numbers the efficiency gains (45.5% params, 97% FLOPs) cannot be assessed against possible degradation in discriminative power.
Authors: We agree that the abstract as written does not include the specific detection error rates or AUC values on the 19,000-cover evaluation set, making the 'negligible accuracy loss' and 'matches or surpasses' claims difficult to evaluate directly from the abstract alone. In the revised version we will add these metrics (e.g., the error rates and AUC for the K=31 configuration versus the baseline and heavier K settings) to the abstract so that the efficiency numbers can be assessed against any accuracy impact. The experimental section already reports results on the disjoint evaluation protocol; the revision will simply make the abstract self-contained with the key numbers. revision: yes
Circularity Check
No circularity; efficiency and accuracy claims are direct empirical measurements on external ALASKA2 benchmark
full rationale
The paper describes three architectural modifications (classifier-channel narrowing, K=31 SRM-Gabor top-K selection, MobileNetV2-style backbone) to the cited PENet baseline and reports measured parameter/FLOP reductions plus an assertion of negligible accuracy loss on a disjoint 19k-image ALASKA2 evaluation set. No equations, fitted parameters, or self-citation chains are shown that would make the reported numbers equivalent to the inputs by construction. The central claims rest on external benchmark evaluation rather than any self-definitional or fitted-input reduction. Absence of explicit ablation numbers is an evidence gap, not circularity. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- K =
31
- classifier channel narrowing schedule
axioms (1)
- domain assumption Preserving negative filter responses via PReLU captures weak stego cues that ReLU would suppress.
Reference graph
Works this paper leans on
-
[1]
Color image steganalysis based on pixel difference convolution and enhanced transformer with selective pooling,
S. Yin, X. Li, Y . Zhang, S. Liu, and L. Wang, “Color image steganalysis based on pixel difference convolution and enhanced transformer with selective pooling,”IEEE Transactions on Information Forensics and Security, vol. 18, pp. 5129–5143, 2023
2023
-
[2]
Deep learning for steganalysis via convolutional neural networks,
Y . Qian, J. Dong, W. Wang, T. Tanet al., “Deep learning for steganalysis via convolutional neural networks,” inIS&T Electronic Imaging: Media Watermarking, Security, and Forensics, 2015
2015
-
[3]
Deep learning hierarchical representations for image steganalysis,
J. Ye, J. Ni, and Y . Yi, “Deep learning hierarchical representations for image steganalysis,” inProceedings of the ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec). ACM, 2017, pp. 67–73
2017
-
[4]
Structural design of convolutional neural networks for steganalysis,
G. Xu, H.-Z. Wu, and Y .-Q. Shi, “Structural design of convolutional neural networks for steganalysis,” in2016 IEEE International Conference on Image Processing (ICIP), 2016, pp. 4044–4048
2016
-
[5]
Yedroudj-net: An efficient cnn for spatial steganalysis,
M. Yedroudj, F. Comby, and M. Chaumont, “Yedroudj-net: An efficient cnn for spatial steganalysis,”IEEE Access, vol. 6, pp. 18 065–18 077, 2018
2018
-
[6]
Deep residual network for steganalysis of digital images,
M. Boroumand, M. Chen, and J. Fridrich, “Deep residual network for steganalysis of digital images,”IEEE Transactions on Information Forensics and Security, vol. 14, no. 5, pp. 1181–1193, 2019
2019
-
[7]
Steganalyzing images of arbitrary size with cnns,
C.-F. Tsang and J. Fridrich, “Steganalyzing images of arbitrary size with cnns,” inElectronic Imaging, vol. 30, no. 7, 2018, pp. 121–1–121–8
2018
-
[8]
A siamese cnn for image steganalysis,
W. You, J. Ni, Y . Zhang, and Z. Qian, “A siamese cnn for image steganalysis,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 291– 306, 2021
2021
-
[9]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021, arXiv:2010.11929
Pith/arXiv arXiv 2021
-
[10]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 10 012–10 022
2021
-
[11]
Rich models for steganalysis of digital images,
J. Fridrich and T. Kodovský, “Rich models for steganalysis of digital images,”IEEE Transactions on Information Forensics and Security, vol. 7, no. 3, pp. 868–882, 2012
2012
-
[12]
Mo- bilenetv2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mo- bilenetv2: Inverted residuals and linear bottlenecks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 4510–4520
2018
-
[13]
Shufflenet: An extremely efficient convolutional neural network for mobile devices,
X. Zhang, X. Zhou, M. Lin, and J. Sun, “Shufflenet: An extremely efficient convolutional neural network for mobile devices,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 6848–6856
2018
-
[14]
Efficientnet: Rethinking model scaling for convolu- tional neural networks,
M. Tan and Q. V . Le, “Efficientnet: Rethinking model scaling for convolu- tional neural networks,” inProceedings of the International Conference on Machine Learning (ICML), 2019, pp. 6105–6114
2019
-
[15]
Towards faster training of global covariance pooling networks by iterative matrix square root normalization,
P. Li, J. Xie, Q. Wang, and Z. Gao, “Towards faster training of global covariance pooling networks by iterative matrix square root normalization,” inProc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 947–955
2018
-
[16]
Fast and effective global covari- ance pooling network for image steganalysis,
X. Deng, B. Chen, W. Luo, and D. Luo, “Fast and effective global covari- ance pooling network for image steganalysis,” inProc. ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec), 2019, pp. 230–234
2019
-
[17]
Depth-wise separable convolutions and multi-level pooling for an efficient spatial cnn-based steganalysis,
R. Zhang, F. Zhu, J. Liu, and G. Liu, “Depth-wise separable convolutions and multi-level pooling for an efficient spatial cnn-based steganalysis,” IEEE Transactions on Information Forensics and Security, vol. 15, pp. 1138–1150, 2020
2020
-
[18]
How to pretrain for steganalysis,
J. Butora, Y . Yousfi, and J. Fridrich, “How to pretrain for steganalysis,” inProc. ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec), 2021, pp. 143–148
2021
-
[19]
Imagenet pretrained cnns for jpeg steganalysis,
Y . Yousfi, J. Butora, E. Khvedchenya, and J. Fridrich, “Imagenet pretrained cnns for jpeg steganalysis,” inProc. IEEE Int. Workshop on Information Forensics and Security (WIFS), 2020, pp. 1–6
2020
-
[20]
Improving efficientnet for jpeg ste- ganalysis,
Y . Yousfi, J. Butora, and J. Fridrich, “Improving efficientnet for jpeg ste- ganalysis,” inProc. ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec), 2021, pp. 149–157
2021
-
[21]
Mobilenets: Efficient convolutional neural networks for mobile vision applications,
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,”arXiv preprint arXiv:1704.04861, 2017
Pith/arXiv arXiv 2017
-
[22]
Rectifier nonlinearities improve neural network acoustic models,
A. L. Maas, A. Y . Hannun, and A. Y . Ng, “Rectifier nonlinearities improve neural network acoustic models,” inProc. ICML Workshop on Deep Learning for Audio, Speech and Language Processing, 2013
2013
-
[23]
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning,
S. Elfwing, E. Uchibe, and K. Doya, “Sigmoid-weighted linear units for neural network function approximation in reinforcement learning,”Neural Networks, vol. 107, pp. 3–11, 2018
2018
-
[24]
Delving deep into rectifiers: Surpass- ing human-level performance on imagenet classification,
K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpass- ing human-level performance on imagenet classification,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1026–1034
2015
-
[25]
Spatial pyramid pooling in deep convolutional networks for visual recognition,
——, “Spatial pyramid pooling in deep convolutional networks for visual recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, no. 9, pp. 1904–1916, 2015
1904
-
[26]
Minimizing the embedding impact in steganography,
T. Filler, J. Judas, and J. Fridrich, “Minimizing the embedding impact in steganography,” inMedia Watermarking, Security, and Forensics, ser. Proc. SPIE, vol. 6505, 2007, p. 650502
2007
-
[27]
Universal distortion function for steganography in an arbitrary domain,
V . Holub, J. Fridrich, and T. Denemark, “Universal distortion function for steganography in an arbitrary domain,”IEEE Transactions on Information Forensics and Security, vol. 10, no. 12, pp. 2408–2424, 2015
2015
-
[28]
Using statistical image model for jpeg steganography: Uniform embedding revisited,
L. Guo, J. Ni, W. Su, C. Tang, and Y . Q. Shi, “Using statistical image model for jpeg steganography: Uniform embedding revisited,”IEEE Transactions on Information Forensics and Security, vol. 10, no. 12, pp. 2669–2680, 2015
2015
-
[29]
A new cost function for spatial image steganography,
B. Li, M. Wang, J. Huang, and X. Li, “A new cost function for spatial image steganography,” inIEEE International Conference on Image Processing (ICIP), 2014, pp. 4206–4210
2014
-
[30]
The alaska steganalysis challenge: A first step towards steganalysis in the wild,
R. Cogranne, P. Bas, J. Fridrich, and et al., “The alaska steganalysis challenge: A first step towards steganalysis in the wild,” inProceedings 14 VOLUME 4, 2016 Anet al.: PENet+: A Lightweight Residual Transformer Framework for Efficient Image Steganalysis of the ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec), 2019, pp. 125–137
2016
-
[31]
Breaking alaska: Color separation for steganalysis in jpeg domain,
Y . Yousfi, J. Butora, J. Fridrich, and Q. Giboulot, “Breaking alaska: Color separation for steganalysis in jpeg domain,” inProc. ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec), 2019, pp. 138– 149. JINCHEOL ANreceived the B.S. degree in me- chanical engineering from Chung-Ang University, Seoul, South Korea, in 2025, where he is curr...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.