Analyzing Stream Collapse in Hyper-Connections: From Diagnosis to Mitigation
Pith reviewed 2026-06-28 11:25 UTC · model grok-4.3
The pith
Hyper-connections in language models resolve their permutation symmetry by concentrating signal in a single dominant stream after an early seeding phase.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
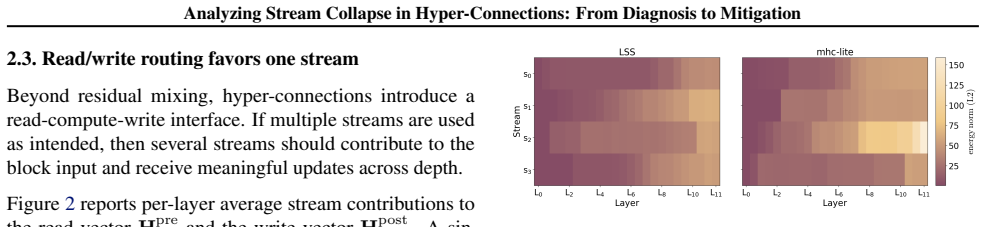
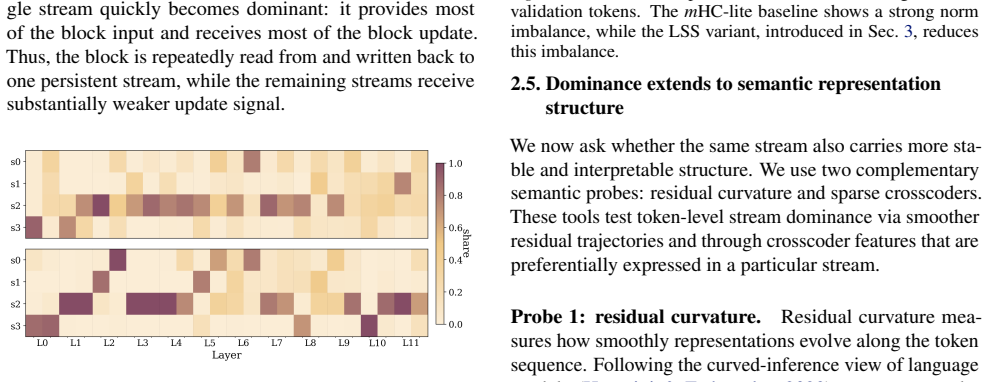
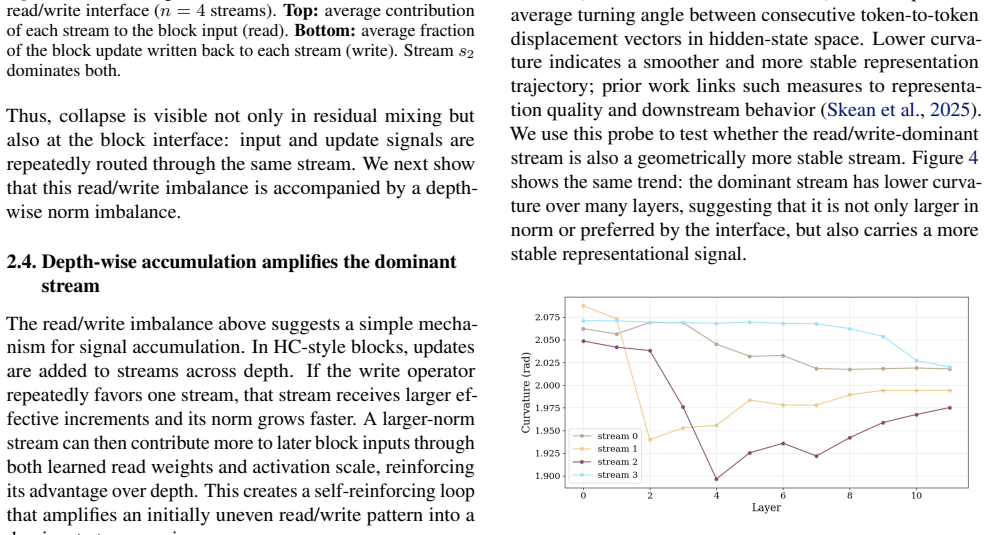
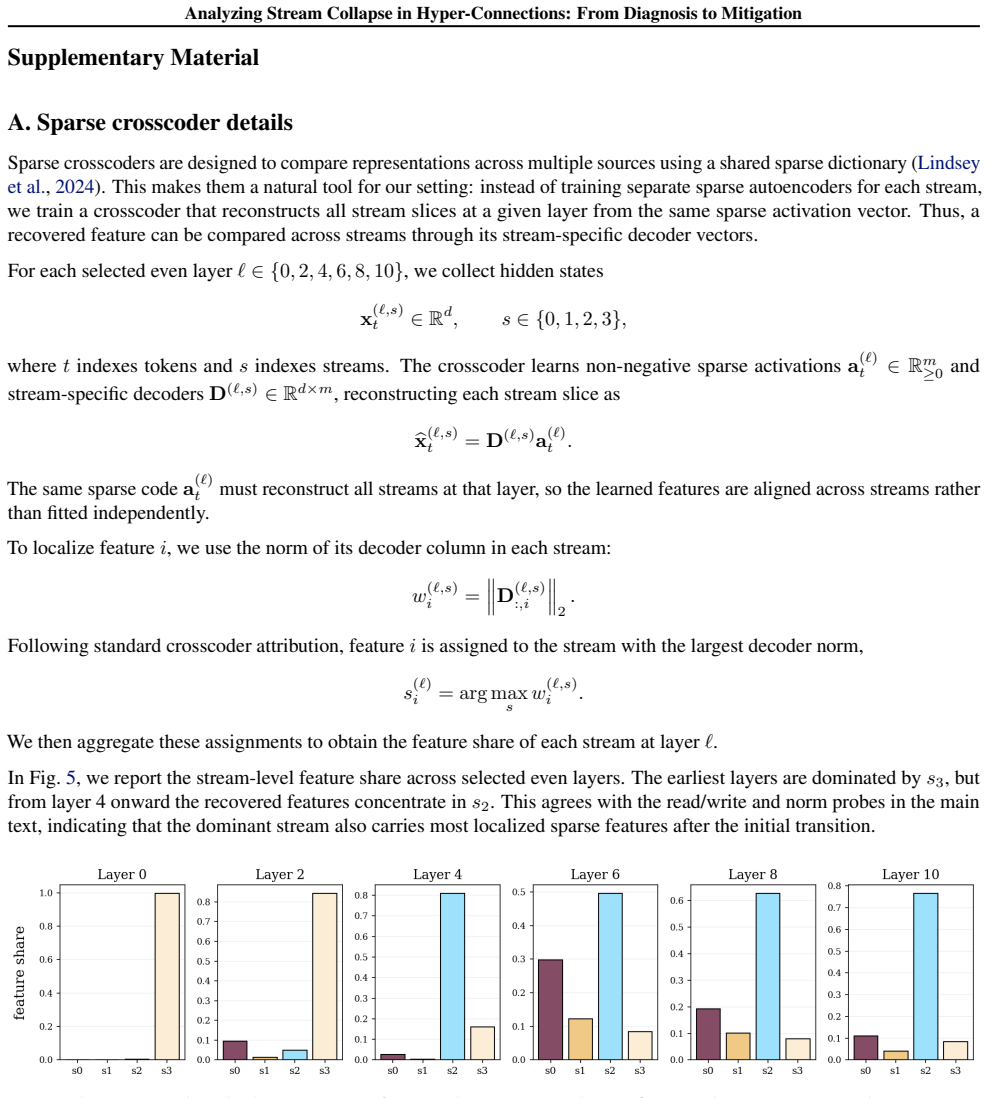
After an early seeding stage, residual mixing often remains close to identity, limiting a core HC mechanism for exchanging information between streams. Moreover, both signal and interpretable features concentrate in a dominant stream, and the nominally multi-stream residual connection can underutilize its capacity, behaving closer to a single-stream residual pathway. Breaking symmetry at stream initialization reduces dominant behavior and improves performance across mHC variants.
What carries the argument
Fine-grained diagnostics that trace how multi-stream representations are used and measure stream dominance in hyper-connection based models.
If this is right
- Residual mixing between streams remains near identity after early training, restricting information exchange.
- Both signal and interpretable features concentrate in one dominant stream.
- The multi-stream setup underutilizes capacity and behaves like a single-stream pathway.
- Breaking symmetry at initialization reduces dominant-stream behavior and improves performance.
Where Pith is reading between the lines
- Similar collapse may occur in other multi-branch or multi-stream architectures if symmetry is not broken early.
- Future designs could incorporate mechanisms to maintain stream diversity throughout training.
- Diagnostics like these could be applied to study information flow in other modified residual connections.
Load-bearing premise
The fine-grained diagnostics accurately measure true stream specialization and information flow without being artifacts of the chosen model scales, datasets, or training hyperparameters.
What would settle it
Finding balanced stream usage and substantial residual mixing throughout training in a hyper-connection model would falsify the collapse diagnosis.
Figures

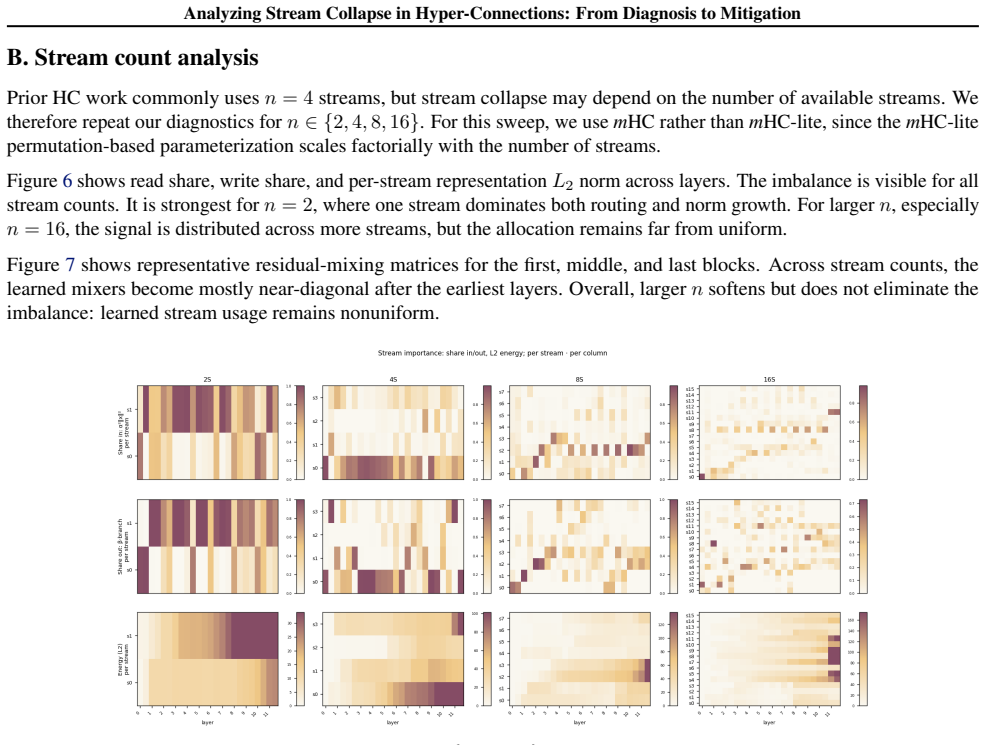
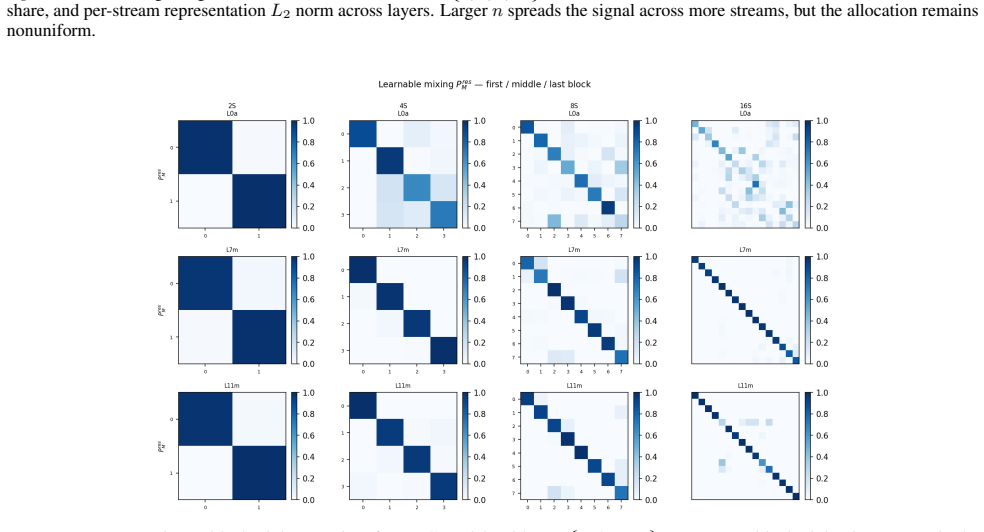



read the original abstract
Hyper-Connections (HC) replace the single Transformer residual stream with multiple streams, introducing a permutation symmetry over stream indices. We study how this symmetry is resolved in practice: whether streams specialize in a balanced way or exhibit dominant-stream usage. Using fine-grained diagnostics for HC-based language models, we trace how multi-stream representations are actually used. We find that after an early seeding stage, residual mixing often remains close to identity, limiting a core HC mechanism for exchanging information between streams. Moreover, both signal and interpretable features concentrate in a dominant stream, and the nominally multi-stream residual connection can underutilize its capacity, behaving closer to a single-stream residual pathway. Finally, we show that breaking symmetry at stream initialization reduces dominant behavior and improves performance across \textit{m}HC variants. Our code is publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes hyper-connections (HC) in Transformers, which replace the single residual stream with multiple streams that introduce permutation symmetry. Using fine-grained diagnostics on HC-based language models, it reports that after an early seeding stage residual mixing stays close to identity (limiting inter-stream information exchange), that both signal and interpretable features concentrate in a dominant stream (so the multi-stream connection behaves like a single-stream pathway), and that breaking symmetry at stream initialization reduces dominant-stream behavior and improves performance across mHC variants. The code is released publicly.
Significance. If the diagnostics prove robust, the work supplies a concrete diagnosis of why HC may under-deliver on its intended capacity and a simple, effective mitigation. Public code strengthens reproducibility. The empirical nature of the claims, however, makes the absence of systematic scale/dataset/hyperparameter ablations a material limitation on how far the conclusions can be generalized.
major comments (1)
- [Experimental results] Experimental results section: the central claims—that residual mixing remains near identity, that signal concentrates in a dominant stream, and that symmetry breaking reliably mitigates collapse—rest on diagnostics whose sensitivity to model scale, dataset choice, and training hyperparameters is not ablated. Without such controls it is unclear whether the observed dominant-stream behavior is intrinsic to HC or an artifact of the reported experimental regime.
minor comments (2)
- [Abstract] Notation for mHC is introduced only in the abstract and results; a brief definition or pointer to the relevant section would improve readability.
- [Figures] Figure captions for the diagnostic plots should explicitly state the number of runs and any statistical aggregation used.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to clarify the scope and robustness of our experimental findings. We address this point directly below and outline planned revisions.
read point-by-point responses
-
Referee: [Experimental results] Experimental results section: the central claims—that residual mixing remains near identity, that signal concentrates in a dominant stream, and that symmetry breaking reliably mitigates collapse—rest on diagnostics whose sensitivity to model scale, dataset choice, and training hyperparameters is not ablated. Without such controls it is unclear whether the observed dominant-stream behavior is intrinsic to HC or an artifact of the reported experimental regime.
Authors: We agree that the reported experiments focus on a specific set of model scales, datasets, and training regimes, and that systematic ablations across these axes would strengthen claims about generality. Our diagnostics were applied consistently across multiple mHC variants (with different stream counts and mixing mechanisms), yielding qualitatively similar collapse patterns and mitigation benefits from symmetry-breaking initialization. This provides some evidence that the behavior is not an isolated artifact, but we do not claim invariance to all scales or hyperparameters. To address the concern, we will revise the manuscript to (1) add a new subsection in the experimental results explicitly discussing the tested regimes and their limitations, (2) include additional experiments on at least one larger model scale and an alternative dataset (where compute permits), and (3) release the full set of hyperparameters and seeds for reproducibility. These changes will help readers evaluate whether the dominant-stream phenomenon is intrinsic to HC or regime-dependent. revision: yes
Circularity Check
No circularity: empirical diagnostics and ablations are self-contained
full rationale
The paper reports empirical measurements of stream behavior in hyper-connection models using fine-grained diagnostics, followed by ablation experiments on symmetry breaking at initialization. No derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All central claims rest on direct observation of model activations and performance metrics rather than any reduction to author-defined quantities by construction. This is the expected non-finding for an analysis paper whose results are externally falsifiable via replication on the released code.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
Deep Residual Learning for Image Recognition , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
-
[2]
arXiv preprint arXiv:2304.14802 , year =
Residual: Transformer with Dual Residual Connections , author =. arXiv preprint arXiv:2304.14802 , year =
-
[3]
arXiv preprint arXiv:2506.22696 , year =
Residual Matrix Transformers: Scaling the Size of the Residual Stream , author =. arXiv preprint arXiv:2506.22696 , year =
-
[4]
Bhendawade, Nikhil and Najibi, Mahyar and Naik, Devang and Belousova, Irina , booktitle =
-
[5]
arXiv preprint arXiv:2409.19606 , year =
Hyper-Connections , author =. arXiv preprint arXiv:2409.19606 , year =
-
[6]
Xie, Zhenda and Wei, Yixuan and Cao, Huanqi and Zhao, Chenggang and Deng, Chengqi and Li, Jiashi and Dai, Damai and Gao, Huazuo and Chang, Jiang and Yu, Kuai and others , journal =
-
[7]
Yang, Yongyi and Gao, Jianyang , journal =
-
[8]
Zhou, Wuyang and Gu, Yuxuan and Iacovides, Giorgos and Mandic, Danilo , journal =
-
[9]
Advances in Neural Information Processing Systems , volume =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , volume =
-
[10]
Advances in Neural Information Processing Systems , volume =
Language Models Are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =
-
[11]
arXiv preprint arXiv:2010.11929 , year =
An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. arXiv preprint arXiv:2010.11929 , year =
Pith/arXiv arXiv 2010
-
[12]
arXiv preprint arXiv:2302.13971 , year =
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. arXiv preprint arXiv:2302.13971 , year =
-
[13]
International Conference on Machine Learning , pages =
On Layer Normalization in the Transformer Architecture , author =. International Conference on Machine Learning , pages =. 2020 , organization =
2020
-
[14]
2024 , publisher =
Wang, Hongyu and Ma, Shuming and Dong, Li and Huang, Shaohan and Zhang, Dongdong and Wei, Furu , journal =. 2024 , publisher =
2024
-
[15]
2021 , organization =
Bachlechner, Thomas and Majumder, Bodhisattwa Prasad and Mao, Henry and Cottrell, Gary and McAuley, Julian , booktitle =. 2021 , organization =
2021
-
[16]
Advances in Neural Information Processing Systems , volume =
Dao, Tri and Fu, Dan and Ermon, Stefano and Rudra, Atri and R. Advances in Neural Information Processing Systems , volume =
-
[17]
Pacific Journal of Mathematics , volume =
Concerning Nonnegative Matrices and Doubly Stochastic Matrices , author =. Pacific Journal of Mathematics , volume =. 1967 , publisher =
1967
-
[18]
Universidad Nacional de Tucuman
Tres observaciones sobre el algebra lineal , author =. Universidad Nacional de Tucuman. Revista, Serie A , volume =
-
[19]
European Conference on Computer Vision , pages =
Identity Mappings in Deep Residual Networks , author =. European Conference on Computer Vision , pages =. 2016 , organization =
2016
-
[20]
arXiv preprint arXiv:1603.08983 , year =
Adaptive Computation Time for Recurrent Neural Networks , author =. arXiv preprint arXiv:1603.08983 , year =
-
[21]
arXiv preprint arXiv:1807.03819 , year =
Universal Transformers , author =. arXiv preprint arXiv:1807.03819 , year =
-
[22]
Transformers Are
Katharopoulos, Angelos and Vyas, Apoorv and Pappas, Nikolaos and Fleuret, Fran. Transformers Are. International Conference on Machine Learning , pages =. 2020 , organization =
2020
-
[23]
Advances in Neural Information Processing Systems , volume =
Root Mean Square Layer Normalization , author =. Advances in Neural Information Processing Systems , volume =
-
[24]
2024 , publisher =
Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Bo, Wen and Liu, Yunfeng , journal =. 2024 , publisher =
2024
-
[25]
Shazeer, Noam , journal =
-
[26]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , pages =
Understanding the Difficulty of Training Transformers , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , pages =
2020
-
[27]
IEEE Transactions on Neural Networks , volume =
Learning Long-Term Dependencies with Gradient Descent Is Difficult , author =. IEEE Transactions on Neural Networks , volume =. 1994 , publisher =
1994
-
[28]
Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =
Understanding the Difficulty of Training Deep Feedforward Neural Networks , author =. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =. 2010 , organization =
2010
-
[29]
Advances in Neural Information Processing Systems , volume =
Large Language Models Implicitly Learn to Straighten Neural Sentence Trajectories to Construct a Predictive Representation of Natural Language , author =. Advances in Neural Information Processing Systems , volume =
-
[30]
Transformer Circuits Thread , pages =
Sparse Crosscoders for Cross-Layer Features and Model Diffing , author =. Transformer Circuits Thread , pages =
-
[31]
arXiv preprint arXiv:1701.06538 , year =
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author =. arXiv preprint arXiv:1701.06538 , year =
-
[32]
Journal of Machine Learning Research , volume =
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author =. Journal of Machine Learning Research , volume =. 2022 , note =
2022
-
[33]
Proceedings of the 38th International Conference on Machine Learning , series =
Geometry of the Loss Landscape in Overparameterized Neural Networks: Symmetries and Invariances , author =. Proceedings of the 38th International Conference on Machine Learning , series =
-
[34]
Proceedings of the 42nd International Conference on Machine Learning , year =
Layer by Layer: Uncovering Hidden Representations in Language Models , author =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[35]
Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and Presser, Shawn and Leahy, Connor , journal =. The
-
[36]
GitHub repository , howpublished =
Karpathy, Andrej , title =. GitHub repository , howpublished =. 2022 , publisher =
2022
-
[37]
arXiv preprint arXiv:2203.15556 , volume =
Training Compute-Optimal Large Language Models , author =. arXiv preprint arXiv:2203.15556 , volume =
-
[38]
Journal of Machine Learning Research , volume =
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author =. Journal of Machine Learning Research , volume =
-
[39]
OpenWebText Corpus , author =
-
[40]
arXiv preprint arXiv:1609.07843 , year =
Pointer Sentinel Mixture Models , author =. arXiv preprint arXiv:1609.07843 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.