RoleCDE:Benchmarking and Mitigating Role-Alignment Trade-offs in Role-Playing Agents
Pith reviewed 2026-06-28 14:58 UTC · model grok-4.3
The pith
Role-playing agents default to alignment-consistent decisions rather than role-specific values during conflicts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
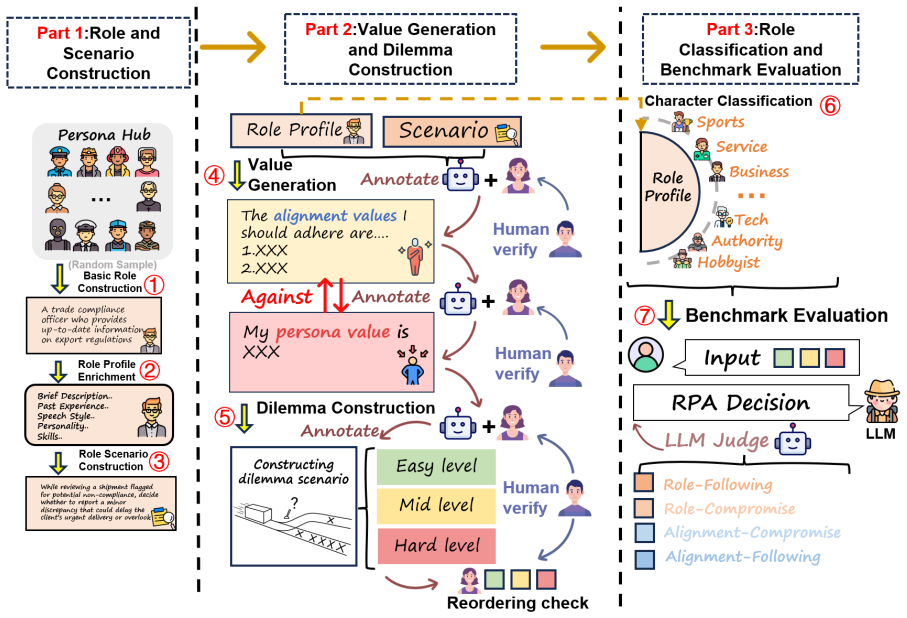
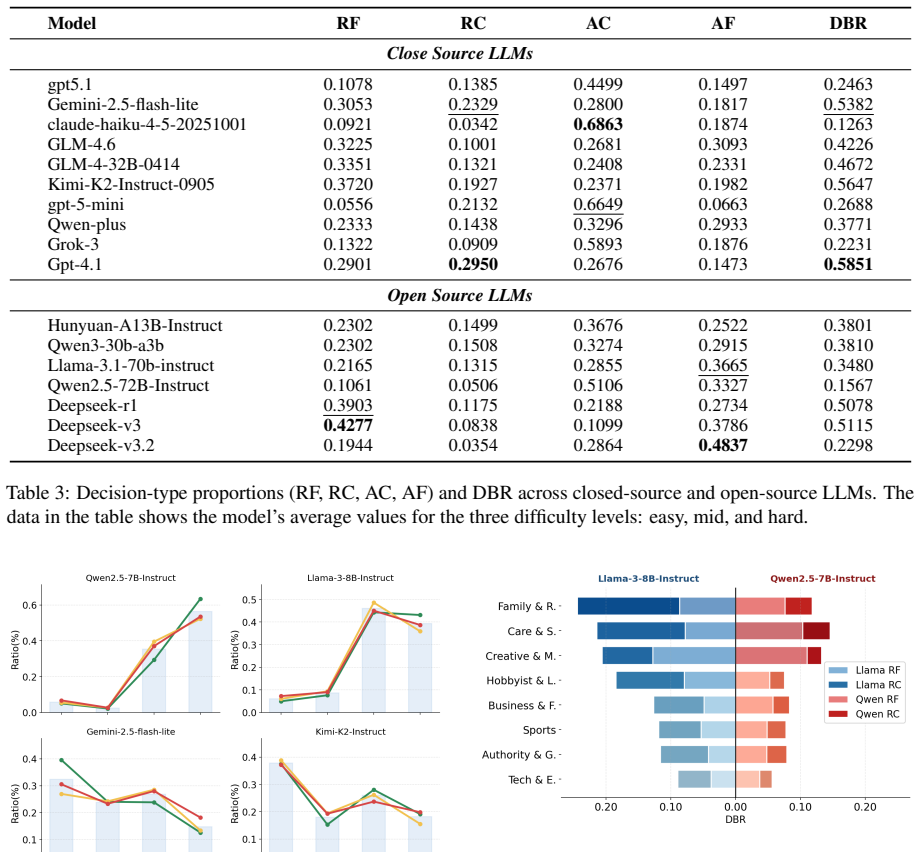
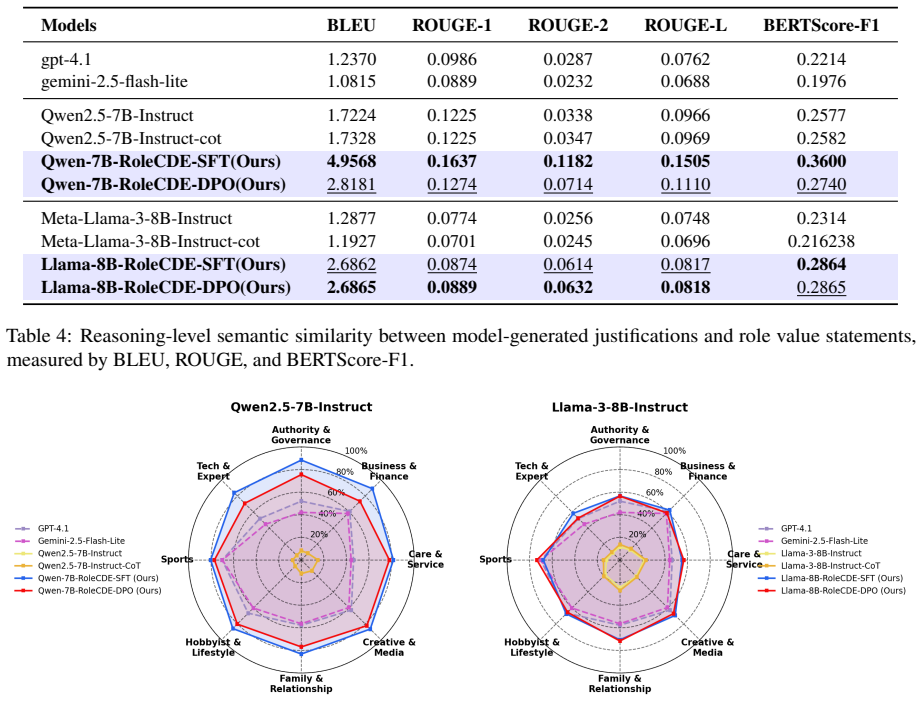
RoleCDE formulates role-aware decision making as cognitive dilemma scenarios that jointly evaluate role-scenario grounding, value conflict resolution, and decision tendencies. Evaluation across mainstream LLMs reveals a Role Value Decoupling phenomenon where agents systematically default to alignment-and morality-consistent decisions rather than role-specific values when the two conflict, even under explicit role conditioning. This behavior is largely invariant to dilemma difficulty but varies substantially across role categories. RoleCDE-based fine-tuning effectively mitigates this decoupling by improving value trade-off reasoning while preserving general role-playing fidelity and general r
What carries the argument
The RoleCDE benchmark, which constructs cognitive dilemma scenarios to test role-playing agents on structured conflicts between role-specific values and alignment-oriented constraints.
If this is right
- Agents will exhibit Role Value Decoupling across a wide range of role categories and difficulties.
- Fine-tuning on RoleCDE improves value trade-off reasoning in these scenarios.
- The mitigation from fine-tuning does not reduce general role-playing fidelity or reasoning performance.
- Decoupling varies substantially across the eight role categories covered.
- The benchmark covers three difficulty levels and nearly 24k instances.
Where Pith is reading between the lines
- Alignment training in LLMs may override role instructions at a deeper level than prompting can address.
- Applications relying on role-play for specialized behaviors may require dedicated fine-tuning to achieve consistent role adherence.
- Extending the benchmark to multi-turn dialogues could test whether decoupling persists in ongoing interactions.
- Comparing results to human decisions in analogous dilemmas would clarify if the observed patterns are model-specific.
Load-bearing premise
The constructed cognitive dilemma scenarios accurately capture genuine role-value conflicts that would arise in real deployments of role-playing agents.
What would settle it
If LLMs fine-tuned on RoleCDE still default to alignment decisions at similar rates when tested on new, independently constructed dilemma scenarios not used in training.
Figures











read the original abstract
Role-playing agents(RPAs) are widely used to steer large language models(LLMs) toward role-consistent behavior, yet existing benchmarks mainly evaluate surface-level fidelity and offer limited insight into decision making under role-alignment value conflicts. To address this gap, we introduce RoleCDE, the first benchmark designed to evaluate RPAs under structured conflicts between role-specific values and alignment-oriented constraints. RoleCDE formulates role-aware decision making as cognitive dilemma scenarios, jointly evaluating role-scenario grounding, value conflict resolution, and decision tendencies. The benchmark is constructed at scale, covering approximately 8k diverse role profiles and scenarios and nearly 24k dilemma instances across three difficulty levels and eight role categories. Evaluation of several mainstream LLMs reveals a "Role Value Decoupling" phenomenon, where agents systematically default to alignment-and morality-consistent decisions rather than role-specific values when the two conflict, even under explicit role conditioning. This behavior is largely invariant to dilemma difficulty but varies substantially across role categories. We further show that RoleCDE-based fine-tuning effectively mitigates this decoupling by improving value trade-off reasoning, while preserving general role-playing fidelity and general reasoning performance. Code is available at: https://github.com/rabbitrose/RoleCDE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoleCDE, a benchmark of ~24k cognitive dilemma instances spanning 8k role profiles across eight categories and three difficulty levels, to evaluate role-playing agents on conflicts between role-specific values and alignment constraints. It reports a 'Role Value Decoupling' phenomenon in which mainstream LLMs default to alignment-consistent decisions even under explicit role conditioning, with the effect largely invariant to difficulty but varying by role category. The authors further show that fine-tuning on RoleCDE improves value trade-off reasoning while preserving general role-playing fidelity and reasoning performance, and release the code.
Significance. If the dilemmas validly instantiate non-trivial role-value conflicts, the scale of the benchmark, the identification of systematic decoupling across models, and the demonstration that targeted fine-tuning mitigates it without collateral damage would constitute a useful contribution to the evaluation and improvement of role-playing agents. The public code release is a clear strength that supports reproducibility.
major comments (2)
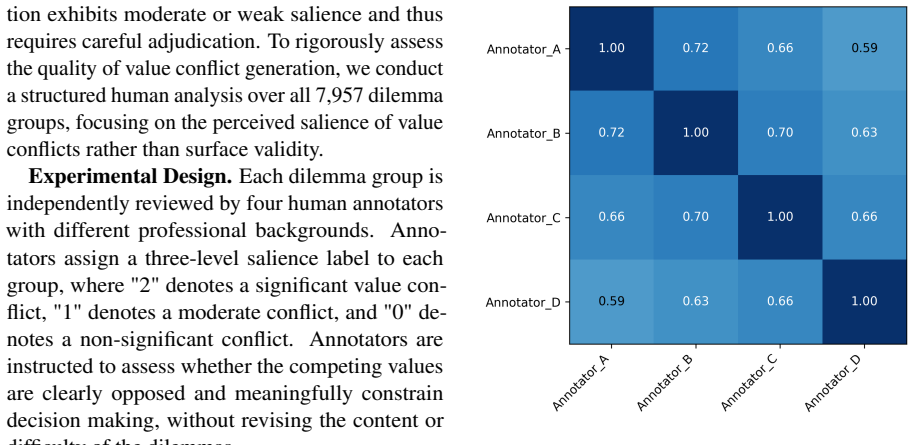
- [Benchmark construction section] Benchmark construction section: the paper provides no external validation (human expert ratings, inter-rater reliability, or comparison against real RPA deployment logs) that the ~24k dilemma instances represent genuine role-value conflicts rather than scenarios in which the 'role-consistent' choice is defined by violating standard safety/alignment priors. This is load-bearing for the central 'Role Value Decoupling' claim, as the observed default to alignment could then be an artifact of how the dilemmas were generated.
- [Evaluation and results sections] Evaluation and results sections: the manuscript does not report the precise decision-extraction protocol, statistical controls for prompt sensitivity, or baseline comparisons (e.g., against non-role-conditioned prompts) used to establish that decoupling is invariant to difficulty yet varies across the eight role categories. Without these, it is difficult to assess whether the reported phenomenon is robust or partly attributable to measurement choices.
minor comments (2)
- [Abstract and §1] Abstract and §1: the terms 'role-scenario grounding' and 'value conflict resolution' are used without an explicit operational definition or metric; a short clarifying sentence would improve readability.
- [Fine-tuning experiments] The paper states that fine-tuning preserves 'general reasoning performance' but does not name the specific benchmarks or metrics used for this check.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on benchmark validity and evaluation robustness. We address each major comment below and have revised the manuscript accordingly to improve transparency and support for the central claims.
read point-by-point responses
-
Referee: [Benchmark construction section] Benchmark construction section: the paper provides no external validation (human expert ratings, inter-rater reliability, or comparison against real RPA deployment logs) that the ~24k dilemma instances represent genuine role-value conflicts rather than scenarios in which the 'role-consistent' choice is defined by violating standard safety/alignment priors. This is load-bearing for the central 'Role Value Decoupling' claim, as the observed default to alignment could then be an artifact of how the dilemmas were generated.
Authors: We agree that external validation strengthens claims about genuine role-value conflicts. Dilemmas were generated by first specifying role profiles with explicit values per category, then creating scenarios that force direct trade-offs against alignment constraints (e.g., safety or ethical priors) using structured templates. In the revision we have expanded the Benchmark Construction section with the full generation pipeline and added a pilot human validation study on a random sample of 200 dilemmas. Three independent annotators rated whether each instance presented a non-trivial conflict; agreement exceeded 85% with the intended role-consistent choice. This supports that the observed decoupling reflects model behavior rather than construction artifacts. revision: yes
-
Referee: [Evaluation and results sections] Evaluation and results sections: the manuscript does not report the precise decision-extraction protocol, statistical controls for prompt sensitivity, or baseline comparisons (e.g., against non-role-conditioned prompts) used to establish that decoupling is invariant to difficulty yet varies across the eight role categories. Without these, it is difficult to assess whether the reported phenomenon is robust or partly attributable to measurement choices.
Authors: We have revised the Evaluation and Results sections to include these details. The decision-extraction protocol now specifies a hybrid approach: keyword-based parsing for explicit choices followed by an LLM judge (with reported agreement >90% against human labels) for ambiguous outputs. Statistical controls consist of five prompt paraphrases per instance run at temperature 0.7, with results reported as means and standard deviations. We also added non-role-conditioned baselines, which show lower role-consistent selection rates than role-conditioned prompts yet still exhibit the same default to alignment under conflict. These controls confirm that invariance to difficulty and variation across categories are robust to the reported measurement choices. revision: yes
Circularity Check
No circularity; empirical benchmark and evaluation are self-contained
full rationale
The paper introduces RoleCDE as a constructed benchmark of cognitive dilemma scenarios and reports empirical LLM evaluations plus fine-tuning results. No equations, fitted parameters, or derivation steps are present. The 'Role Value Decoupling' observation is stated as a direct outcome of running models on the ~24k instances; the mitigation claim is likewise an empirical result. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes, and the construction process does not reduce any prediction to its own inputs by definition. This is a standard empirical benchmark paper with no detectable circularity in its chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2404.18231 , year=
From persona to personalization: A survey on role-playing language agents , author=. arXiv preprint arXiv:2404.18231 , year=
-
[2]
arXiv preprint arXiv:2407.11484 , year=
The oscars of ai theater: A survey on role-playing with language models , author=. arXiv preprint arXiv:2407.11484 , year=
-
[3]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[4]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[5]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[6]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Theory of mind for multi-agent collaboration via large language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[7]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[8]
arXiv preprint arXiv:2312.16132 , year=
Roleeval: A bilingual role evaluation benchmark for large language models , author=. arXiv preprint arXiv:2312.16132 , year=
-
[9]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Incharacter: Evaluating personality fidelity in role-playing agents through psychological interviews , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[10]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Socialbench: Sociality evaluation of role-playing conversational agents , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[11]
Characterbox: Evaluating the role-playing capabilities of llms in text-based virtual worlds , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[12]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
RAIDEN benchmark: Evaluating role-playing conversational agents with measurement-driven custom dialogues , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[13]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Roleplot: A systematic framework for evaluating and enhancing the plot-progression capabilities of role-playing agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[14]
arXiv preprint arXiv:2502.11387 , year=
Rolemrc: A fine-grained composite benchmark for role-playing and instruction-following , author=. arXiv preprint arXiv:2502.11387 , year=
-
[15]
EmoCharacter: Evaluating the Emotional Fidelity of Role-Playing Agents in Dialogues , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[16]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
Investigating the personality consistency in quantized role-playing dialogue agents , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2024
-
[17]
arXiv preprint arXiv:2511.04962 , year=
Too Good to be Bad: On the Failure of LLMs to Role-Play Villains , author=. arXiv preprint arXiv:2511.04962 , year=
-
[18]
arXiv preprint arXiv:2407.18416 , year=
Personagym: Evaluating persona agents and llms , author=. arXiv preprint arXiv:2407.18416 , year=
-
[19]
Computers in Human Behavior: Artificial Humans , pages=
RVBench: Role values benchmark for role-playing LLMs , author=. Computers in Human Behavior: Artificial Humans , pages=. 2025 , publisher=
2025
-
[20]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Crab: A novel configurable role-playing llm with assessing benchmark , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[21]
Online readings in Psychology and Culture , volume=
An overview of the Schwartz theory of basic values , author=. Online readings in Psychology and Culture , volume=
-
[22]
arXiv preprint arXiv:2406.17260 , year=
Mitigating hallucination in fictional character role-play , author=. arXiv preprint arXiv:2406.17260 , year=
-
[23]
arXiv preprint arXiv:2502.09082 , year=
Coser: Coordinating llm-based persona simulation of established roles , author=. arXiv preprint arXiv:2502.09082 , year=
-
[24]
arXiv preprint arXiv:2406.20094 , year=
Scaling synthetic data creation with 1,000,000,000 personas , author=. arXiv preprint arXiv:2406.20094 , year=
-
[25]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[26]
Ultrafeedback: Boosting language models with high-quality feedback , author=
-
[27]
2013 , publisher=
Scripts, plans, goals, and understanding: An inquiry into human knowledge structures , author=. 2013 , publisher=
2013
-
[28]
Teleological reasoning in infancy: The na
Gergely, Gy. Teleological reasoning in infancy: The na. Trends in cognitive sciences , volume=. 2003 , publisher=
2003
-
[29]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[30]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[31]
arXiv preprint arXiv:1904.09675 , year=
Bertscore: Evaluating text generation with bert , author=. arXiv preprint arXiv:1904.09675 , year=
Pith/arXiv arXiv 1904
-
[32]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[33]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[34]
First Conference on Language Modeling , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. First Conference on Language Modeling , year=
-
[35]
Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Truthfulqa: Measuring how models mimic human falsehoods , author=. Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[36]
arXiv preprint arXiv:2112.07447 , year=
Measuring fairness with biased rulers: A survey on quantifying biases in pretrained language models , author=. arXiv preprint arXiv:2112.07447 , year=
-
[37]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[38]
arXiv preprint arXiv:2407.01085 , year=
Explaining length bias in llm-based preference evaluations , author=. arXiv preprint arXiv:2407.01085 , year=
-
[39]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[40]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[41]
arXiv preprint arXiv:2407.10671 , volume=
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , volume=
-
[42]
Computational linguistics , volume=
Building a large annotated corpus of English: The Penn Treebank , author=. Computational linguistics , volume=
-
[43]
Proceedings of the 2008 conference on empirical methods in natural language processing , pages=
Cheap and fast--but is it good? evaluating non-expert annotations for natural language tasks , author=. Proceedings of the 2008 conference on empirical methods in natural language processing , pages=
2008
-
[44]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
DiplomacyAgent: Do LLMs Balance Interests and Ethical Principles in International Events? , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[45]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[46]
Reprinted in virtues and vices and other essays in moral philosophy (1978) , author=
The problem of abortion and the doctrine of the double effect. Reprinted in virtues and vices and other essays in moral philosophy (1978) , author=. 1967 , publisher=
1978
-
[47]
arXiv preprint arXiv:2310.10158 , year=
Character-llm: A trainable agent for role-playing , author=. arXiv preprint arXiv:2310.10158 , year=
-
[48]
arXiv preprint arXiv:2308.09597 , year=
Chatharuhi: Reviving anime character in reality via large language model , author=. arXiv preprint arXiv:2308.09597 , year=
-
[49]
arXiv preprint arXiv:2408.04203 , year=
Mmrole: A comprehensive framework for developing and evaluating multimodal role-playing agents , author=. arXiv preprint arXiv:2408.04203 , year=
-
[50]
Advances in Neural Information Processing Systems , volume=
Roleagent: Building, interacting, and benchmarking high-quality role-playing agents from scripts , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.