FSC-Net: Integrating Fast Fourier Convolutions and Progressive Learning for Speech Bandwidth Extension
Pith reviewed 2026-06-27 21:12 UTC · model grok-4.3
The pith
FSC-Net reconstructs wideband speech from narrowband inputs by modeling full-spectrum frequency dependencies with fast Fourier convolutions and progressive learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
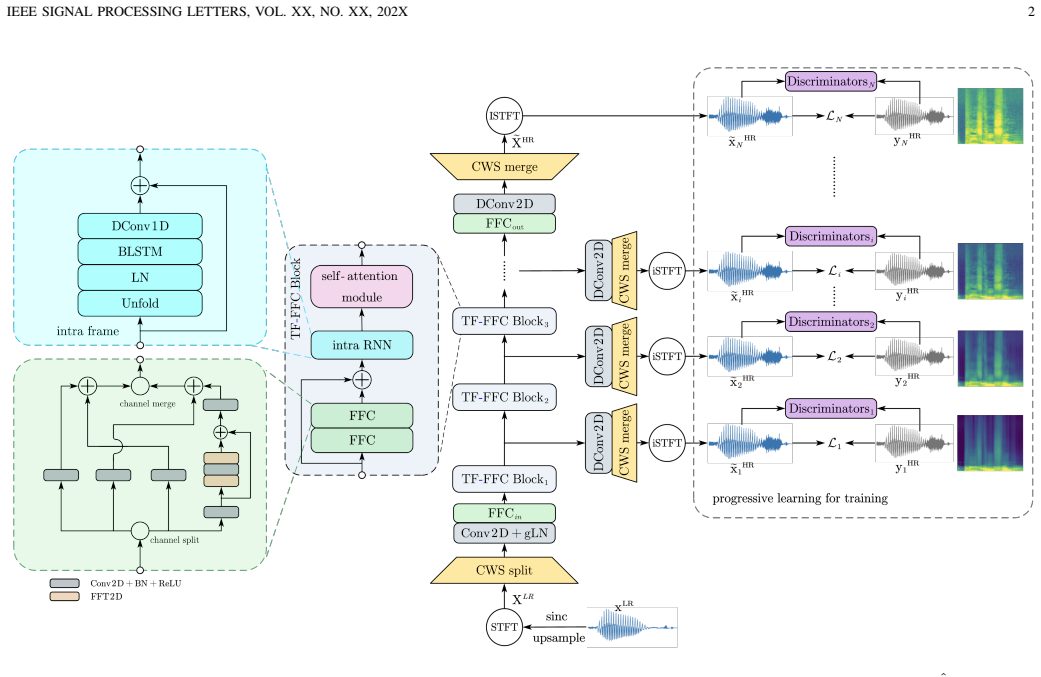
FSC-Net integrates Fast Fourier Convolutions into a complex spectral mapping framework to expand the receptive field across the entire spectrum and capture long-range frequency interactions. Combined with a frequency-progressive learning curriculum, the network addresses the ill-posed high-frequency generation problem by reconstructing details progressively from coarse to fine, leading to improved reconstruction quality and generalization on tasks like 4 kHz to 48 kHz upsampling.
What carries the argument
The integration of Fast Fourier Convolutions into the complex spectral mapping framework, which allows modeling of cross-band harmonic dependencies across the full spectrum.
Load-bearing premise
Integrating fast Fourier convolutions into the spectral mapping will expand the receptive field to the full spectrum and capture long-range interactions without creating new artifacts.
What would settle it
Experiments showing that on the VCTK 4 kHz-to-48 kHz task, FSC-Net does not attain the leading LSD and PESQ scores or introduces more artifacts than baselines.
Figures
read the original abstract
Speech bandwidth extension (BWE) aims to reconstruct high-fidelity wideband audio from narrowband inputs. While recent approaches have made significant progress, they often struggle to reconstruct realistic high-frequency phase and harmonic structures, leading to perceptual artifacts. In this paper, we propose FSC-Net (Full-Spectrum Context Network), a parameter-efficient architecture designed to explicitly model cross-band harmonic dependencies. By integrating Fast Fourier Convolutions (FFCs) into a complex spectral mapping framework, FSC-Net expands its receptive field to the entire spectrum, capturing long-range frequency interactions effectively. To address the ill-posed nature of high-frequency generation, our novel frequency-progressive learning curriculum guides the network to reconstruct spectral details from coarse to fine. Experimental results on the VCTK and unseen EARS datasets demonstrate that FSC-Net delivers consistently strong reconstruction quality and generalization, particularly in the challenging VCTK 4 kHz-to-48 kHz task. Compared to scaled-up baselines, our model attains leading LSD and PESQ scores while maintaining a highly compact parameter footprint (1.54 M).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
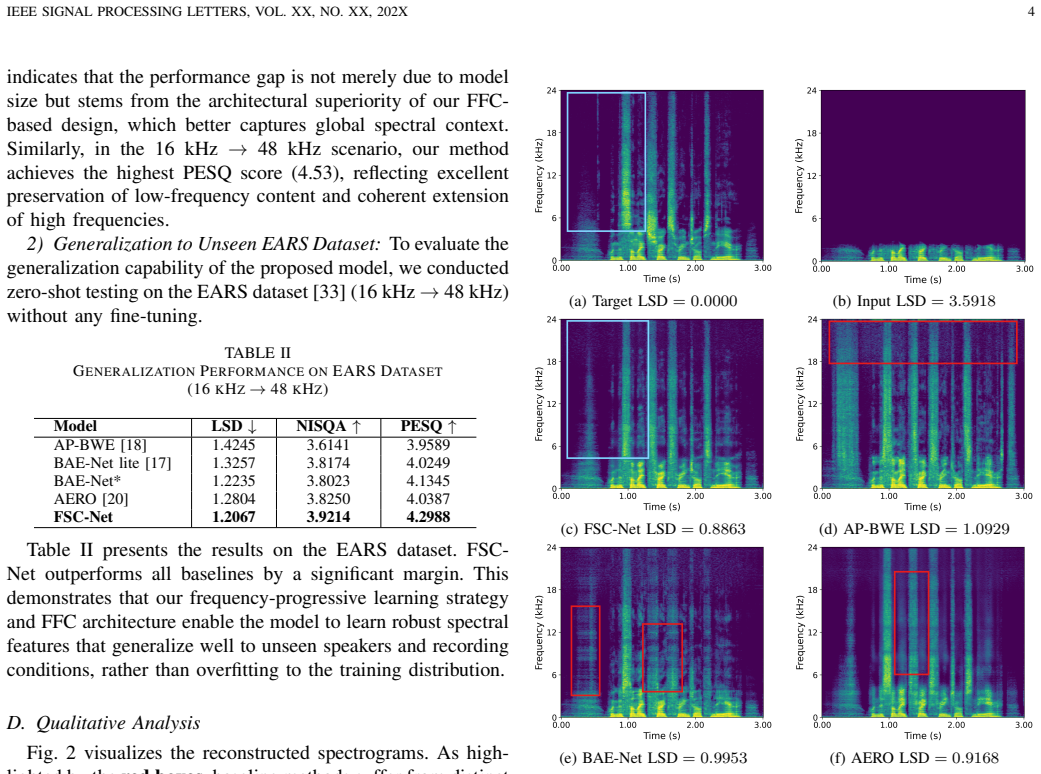
Summary. The paper proposes FSC-Net, a compact (1.54 M parameter) architecture for speech bandwidth extension that integrates Fast Fourier Convolutions into a complex spectral mapping backbone to expand the receptive field across the full spectrum and employs a frequency-progressive learning curriculum to reconstruct high-frequency content from coarse to fine. It reports leading LSD and PESQ scores on the VCTK 4 kHz-to-48 kHz task and on the unseen EARS dataset relative to scaled baselines.
Significance. If the empirical results hold under rigorous verification, the work would demonstrate that FFC-based long-range frequency modeling combined with progressive training can deliver strong reconstruction quality and generalization in a highly parameter-efficient model. This addresses receptive-field limitations in spectral mapping and the ill-posedness of high-frequency generation, with potential value for real-time audio applications. The manuscript provides no machine-checked proofs or open code, but the explicit linkage of architectural choices to the reported metrics is a positive feature.
major comments (1)
- [Experiments] Experiments section: the central claim of leading LSD/PESQ scores on VCTK 4 kHz-to-48 kHz rests on point estimates without reported error bars, statistical significance tests, or explicit data-split and training-hyperparameter details; this information is required to assess whether the improvements over scaled baselines are reliable and reproducible.
minor comments (2)
- [Method] Method section: the precise placement of FFC layers within the complex spectral mapping U-Net (e.g., which encoder/decoder stages) is described at a high level; a diagram or equation showing the modified forward pass would improve reproducibility.
- [Introduction] Abstract and §1: the phrase 'scaled-up baselines' is used without naming the exact models or their parameter counts in the opening paragraphs; this should be clarified for immediate context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript to strengthen the experimental reporting.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim of leading LSD/PESQ scores on VCTK 4 kHz-to-48 kHz rests on point estimates without reported error bars, statistical significance tests, or explicit data-split and training-hyperparameter details; this information is required to assess whether the improvements over scaled baselines are reliable and reproducible.
Authors: We agree that the current presentation relies on point estimates and that greater transparency is needed for reproducibility. In the revised manuscript we will: (1) provide explicit descriptions of the train/validation/test splits and any preprocessing steps, (2) list the complete set of training hyperparameters and optimization settings, and (3) report performance averaged over multiple random seeds together with standard deviations (error bars) and the results of appropriate statistical significance tests against the scaled baselines. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is an empirical neural architecture proposal for speech bandwidth extension. It describes design choices (integrating FFCs into complex spectral mapping and a frequency-progressive curriculum) as addressing receptive-field and ill-posedness issues, then reports LSD/PESQ results on VCTK and EARS. No equations, derivations, or first-principles claims are present that reduce by construction to fitted parameters, self-citations, or renamed inputs. Performance claims rest on external experimental comparisons rather than any self-referential fitting or uniqueness theorem. The derivation chain is therefore self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
B. Iser, W. Minker, and G. Schmidt,Bandwidth extension of speech signals. Springer, 2008
2008
-
[2]
High-frequency regeneration in speech coding systems,
J. Makhoul and M. Berouti, “High-frequency regeneration in speech coding systems,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), vol. 4, 1979, pp. 428–431
1979
-
[3]
Speech enhancement via frequency bandwidth extension using line spectral frequencies,
S. Chennoukh, A. Gerrits, G. Miet, and R. Sluijter, “Speech enhancement via frequency bandwidth extension using line spectral frequencies,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), vol. 1, 2001, pp. 665–668
2001
-
[4]
Bandwidth enhancement of narrowband speech signals,
H. Carl, “Bandwidth enhancement of narrowband speech signals,” in Proc. Eur . Signal Process. Conf. (EUSIPCO), vol. 2, 1994, pp. 1178– 1181
1994
-
[5]
A robust narrowband to wideband extension system featuring enhanced codebook mapping,
T. Unno and A. McCree, “A robust narrowband to wideband extension system featuring enhanced codebook mapping,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), vol. 1, 2005, pp. I–805–I– 808
2005
-
[6]
Artificial bandwidth extension of speech signals using MMSE estimation based on a hidden Markov model,
P. Jax and P. Vary, “Artificial bandwidth extension of speech signals using MMSE estimation based on a hidden Markov model,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), vol. 1, 2003, pp. I–680–I–683
2003
-
[7]
Narrowband to wideband conversion of speech using GMM based transformation,
K.-Y . Park and H. S. Kim, “Narrowband to wideband conversion of speech using GMM based transformation,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), vol. 3, 2000, pp. 1843–1846
2000
-
[8]
Deep learning for acoustic modeling in para- metric speech generation: A systematic review of existing techniques and future trends,
Z.-H. Ling, S.-Y . Kang, H. Zen, A. Senior, M. Schuster, X.-J. Qian, H. M. Meng, and L. Deng, “Deep learning for acoustic modeling in para- metric speech generation: A systematic review of existing techniques and future trends,”IEEE Signal Process. Mag., vol. 32, no. 3, pp. 35–52, 2015
2015
-
[9]
Audio super resolution using neural networks,
V . Kuleshov, S. Z. Enam, and S. Ermon, “Audio super resolution using neural networks,” inProc. Int. Conf. Learn. Represent. (ICLR) Workshop, 2017
2017
-
[10]
Real-time speech frequency bandwidth extension,
Y . Li, M. Tagliasacchi, O. Rybakov, V . Ungureanu, and D. Roblek, “Real-time speech frequency bandwidth extension,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2021, pp. 691–695
2021
-
[11]
Bandwidth Extension on Raw Audio via Generative Adversarial Networks
S. Kim and V . Sathe, “Bandwidth extension on raw audio via generative adversarial networks,”arXiv preprint arXiv:1903.09027, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[12]
Bandwidth extension is all you need,
J. Su, Y . Wang, A. Finkelstein, and Z. Jin, “Bandwidth extension is all you need,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2021, pp. 696–700
2021
-
[13]
NU-Wave 2: A general neural audio upsampling model for various sampling rates,
S. Han and J. Lee, “NU-Wave 2: A general neural audio upsampling model for various sampling rates,” inProc. Interspeech, 2022, pp. 4401– 4405
2022
-
[14]
A deep neural network approach to speech bandwidth expansion,
K. Li and C.-H. Lee, “A deep neural network approach to speech bandwidth expansion,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2015, pp. 4395–4399
2015
-
[15]
A simple cepstral domain DNN approach to artificial speech bandwidth extension,
J. Abel, M. Strake, and T. Fingscheidt, “A simple cepstral domain DNN approach to artificial speech bandwidth extension,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2018, pp. 5469–5473
2018
-
[16]
Frequency extension of telephone narrowband speech signal using neural networks,
C. V . Botinhao, B. S. Carlos, L. P. Caloba, and M. R. Petraglia, “Frequency extension of telephone narrowband speech signal using neural networks,” inProc. Multiconf. Comput. Eng. Syst. Appl., vol. 2, 2006, pp. 1576–1579
2006
-
[17]
BAE-Net: A low complexity and high fidelity bandwidth- adaptive neural network for speech super-resolution,
G. Yu, X. Zheng, N. Li, R. Han, C. Zheng, C. Zhang, C. Zhou, Q. Huang, and B. Yu, “BAE-Net: A low complexity and high fidelity bandwidth- adaptive neural network for speech super-resolution,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2024, pp. 571–575
2024
-
[18]
Towards high-quality and efficient speech bandwidth extension with parallel amplitude and phase prediction,
Y .-X. Lu, Y . Ai, H.-P. Du, and Z. Ling, “Towards high-quality and efficient speech bandwidth extension with parallel amplitude and phase prediction,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 33, pp. 236–250, 2024. [Online]. Available: https: //api.semanticscholar.org/CorpusID:266977163
2024
-
[19]
mdctGAN: Taming transformer- based GAN for speech super-resolution with modified DCT spectra,
C. Shuai, C. Shi, L. Gan, and H. Liu, “mdctGAN: Taming transformer- based GAN for speech super-resolution with modified DCT spectra,” in Proc. Interspeech, 2023, pp. 5112–5116
2023
-
[20]
AERO: Audio super resolution in the spectral domain,
M. Mandel, O. Tal, and Y . Adi, “AERO: Audio super resolution in the spectral domain,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2023, pp. 1–5
2023
-
[21]
SFNet: A two-stage source- filter-based neural network for real-time speech bandwidth extension,
L. Dai, Y . Ke, A. Li, X. Li, and C. Zheng, “SFNet: A two-stage source- filter-based neural network for real-time speech bandwidth extension,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 34, pp. 169–183, 2025
2025
-
[22]
Resolution-robust large mask inpainting with Fourier convolutions,
R. Suvorov, E. Logacheva, A. Mashikhin, A. Remizova, A. Ashukha, A. Silvestrov, N. Kong, H. Goka, K. Park, and V . Lempitsky, “Resolution-robust large mask inpainting with Fourier convolutions,” in Proc. IEEE/CVF Winter Conf. Appl. Comput. Vis. (WACV), 2022, pp. 2149–2159
2022
-
[23]
SNR-progressive model with harmonic compensation for low-SNR speech enhancement,
Z. Hou, T. Lei, Q. Hu, Z. Cao, and J. Lu, “SNR-progressive model with harmonic compensation for low-SNR speech enhancement,”IEEE Signal Process. Lett., vol. 32, pp. 476–480, 2024
2024
-
[24]
SNR-based progressive learning of deep neural network for speech enhancement,
T. Gao, J. Du, L.-R. Dai, and C.-H. Lee, “SNR-based progressive learning of deep neural network for speech enhancement,” inProc. Interspeech, 2016, pp. 3713–3717
2016
-
[25]
UnivNet: A neural vocoder with multi-resolution spectrogram discriminators for high- fidelity waveform generation,
W. Jang, D. Lim, J. Yoon, B. Kim, and J. Kim, “UnivNet: A neural vocoder with multi-resolution spectrogram discriminators for high- fidelity waveform generation,” inProc. Interspeech, 2021, pp. 2207– 2211
2021
-
[26]
TF-GridNet: Integrating full- and sub-band modeling for speech sep- aration,
Z.-Q. Wang, S. Cornell, S. Choi, Y . Lee, B.-Y . Kim, and S. Watanabe, “TF-GridNet: Integrating full- and sub-band modeling for speech sep- aration,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 31, pp. 3221–3236, 2023
2023
-
[27]
TS-URGENet: A three-stage universal robust and generalizable speech enhancement network,
X. Rong, D. Wang, Q. Hu, Y . Wang, Y . Hu, and J. Lu, “TS-URGENet: A three-stage universal robust and generalizable speech enhancement network,” inProc. Interspeech, 2025, pp. 863–867
2025
-
[28]
Least squares generative adversarial networks,
X. Mao, Q. Li, H. Xie, R. Y . Lau, Z. Wang, and S. P. Smolley, “Least squares generative adversarial networks,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 2794–2802
2017
-
[29]
MelGAN: Generative adversarial networks for conditional waveform synthesis,
K. Kumar, R. Kumar, T. De Boissiere, L. Gestin, W. Z. Teoh, J. Sotelo, A. De Brebisson, Y . Bengio, and A. C. Courville, “MelGAN: Generative adversarial networks for conditional waveform synthesis,” inAdv. Neural Inf. Process. Syst. (NeurIPS), vol. 32, 2019
2019
-
[30]
CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (ver- sion 0.92),
J. Yamagishi, C. Veaux, and K. MacDonald, “CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (ver- sion 0.92),” [Online]. Available: https://datashare.ed.ac.uk/handle/10283/ 3443, 2019
2019
-
[31]
NISQA: A deep CNN- self-attention model for multidimensional speech quality prediction with crowdsourced datasets,
G. Mittag, B. Naderi, A. Chehadi, and S. M ¨oller, “NISQA: A deep CNN- self-attention model for multidimensional speech quality prediction with crowdsourced datasets,” inProc. Interspeech, 2021, pp. 2127–2131
2021
-
[32]
Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band tele- phone networks and speech codecs,
ITU-T, “Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band tele- phone networks and speech codecs,”Rec. ITU-T P .862, 2001
2001
-
[33]
EARS: An anechoic fullband speech dataset benchmarked for speech enhancement and dereverberation,
J. Richter, Y .-C. Wu, S. Krenn, S. Welker, B. Lay, S. Watanabe, A. Richard, and T. Gerkmann, “EARS: An anechoic fullband speech dataset benchmarked for speech enhancement and dereverberation,” in Proc. Interspeech, 2024, pp. 4873–4877
2024
-
[34]
Curriculum learning,
Y . Bengio, J. Louradour, R. Collobert, and J. Weston, “Curriculum learning,” inProc. Int. Conf. Mach. Learn. (ICML), 2009, pp. 41–48
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.