MAVIS: Multi-Agent Video Retrieval via Structured Video Understanding
Pith reviewed 2026-06-27 17:25 UTC · model grok-4.3
The pith
MAVIS retrieves videos by parsing them into structured semantic libraries and using multi-agent logic debate instead of full embedding scans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
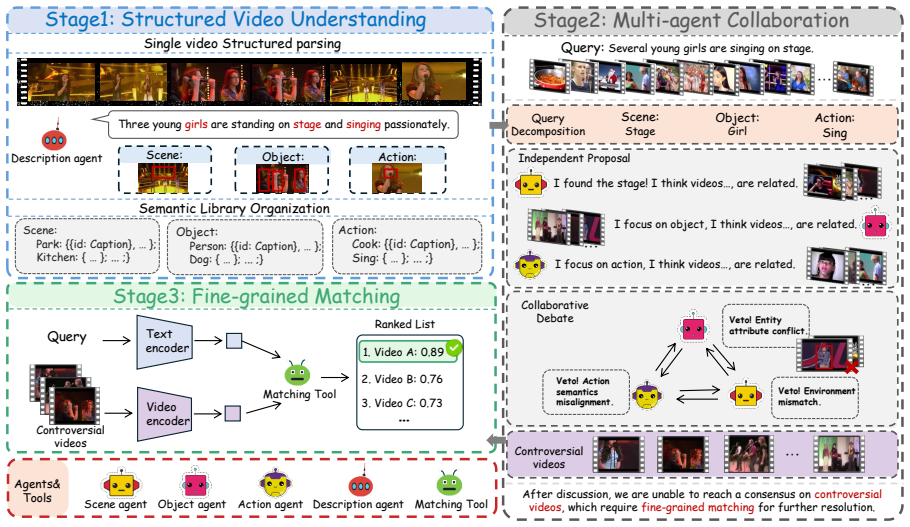
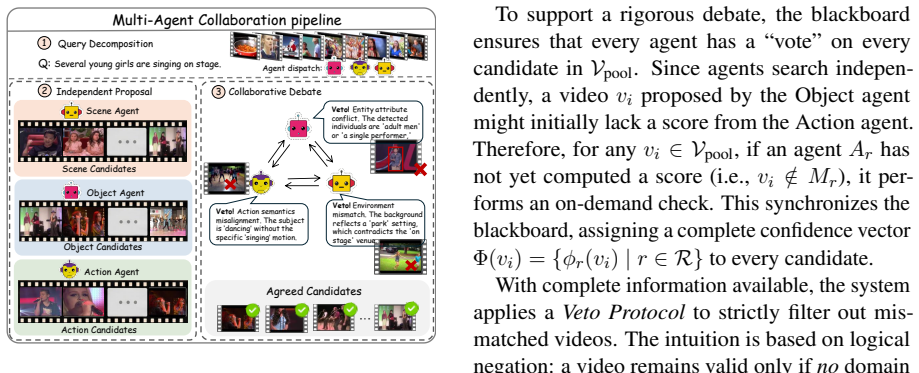
MAVIS rethinks video retrieval as cooperative reasoning rather than brute-force search. It parses raw videos into a Structured Semantic Library for explicit attribute-level indexing. A planner decomposes user intents into atomic sub-tasks and dispatches specialized agents. These agents then apply Logic-aware Debate with a strict veto protocol to prune logical mismatches, leaving only controversial candidates for fine-grained verification. This workflow bypasses full-library traversal and delivers competitive performance on MSR-VTT, MSVD, and ActivityNet without task-specific fine-tuning.
What carries the argument
The Logic-aware Debate mechanism, in which agents use a strict veto protocol to collaboratively eliminate logical mismatches and isolate a compact set of controversial candidates.
If this is right
- Full-corpus embedding scans become unnecessary for video retrieval once videos are indexed in the Structured Semantic Library.
- The veto-based debate produces an interpretable trace of why certain candidates are eliminated.
- Competitive results hold across MSR-VTT, MSVD, and ActivityNet without any task-specific fine-tuning of the underlying models.
- Complex user intents can be handled by decomposing them into atomic sub-tasks dispatched to independent agents.
Where Pith is reading between the lines
- The same parsing-plus-debate pattern could be tested on image or text retrieval where query sparsity also creates asymmetry.
- If the semantic library step proves stable, retrieval systems might reduce reliance on ever-larger embedding models.
- The veto protocol itself could be reused in other multi-agent setups to improve reliability of final selections.
Load-bearing premise
Automatically parsing raw videos into a Structured Semantic Library preserves the semantic attributes needed for accurate retrieval without introducing substantial errors or omissions.
What would settle it
Retrieval accuracy on MSR-VTT or ActivityNet drops below that of standard dual-encoder baselines when the same videos are used but the semantic library parsing step is replaced by a version that introduces documented attribute omissions.
Figures



read the original abstract
The dominant paradigm in video retrieval relies on embedding-based full-corpus scanning, which suffers from inherent computational inefficiency and the semantic asymmetry between information-dense videos and sparse textual queries. To bridge this gap, we introduce \textbf{MAVIS}, a novel multi-agent framework that rethinks retrieval as cooperative reasoning rather than brute-force search. MAVIS first bridges the granularity mismatch by parsing raw videos into a \textbf{Structured Semantic Library}, enabling explicit attribute-level indexing. During retrieval, a planner decomposes complex user intents into atomic sub-tasks, dispatching specialized agents to independently nominate candidates. Crucially, MAVIS employs a \textbf{Logic-aware Debate} mechanism with a strict veto protocol, where agents collaboratively prune logical mismatches to identify a compact set of ``controversial'' candidates for fine-grained verification. This agentic workflow effectively bypasses the inefficiency of full-library traversal. Extensive experiments on MSR-VTT, MSVD, and ActivityNet demonstrate that MAVIS achieves competitive performance without task-specific fine-tuning, offering a scalable and interpretable alternative to traditional dual-encoder approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MAVIS, a multi-agent framework for video retrieval that parses raw videos into a Structured Semantic Library for attribute-level indexing. A planner decomposes user queries into sub-tasks dispatched to specialized agents, which nominate candidates; a Logic-aware Debate mechanism with strict veto protocol then prunes logical mismatches before fine-grained verification. The central claim is that this workflow achieves competitive performance on MSR-VTT, MSVD, and ActivityNet without task-specific fine-tuning, providing a scalable and interpretable alternative to dual-encoder embedding approaches.
Significance. If substantiated, the result would offer a meaningful shift from full-corpus embedding scans to cooperative agentic reasoning, with potential gains in efficiency and interpretability for large-scale video retrieval. The no-fine-tuning aspect and explicit use of structured attributes plus debate are notable if the performance claims hold under standard protocols.
major comments (2)
- [Abstract] Abstract: the claim that 'extensive experiments ... demonstrate that MAVIS achieves competitive performance' supplies no quantitative results, baselines, metrics, error bars, or experimental protocol, preventing verification of the central performance claim.
- [Abstract and §2] Abstract and §2 (framework description): the construction of the Structured Semantic Library is described only at the conceptual level with no parser details, error analysis, or ablation on attribute fidelity (e.g., temporal relations or fine-grained actions). This is load-bearing for the claim that the library enables accurate downstream retrieval, as systematic omissions would corrupt input to the planner, agents, and debate mechanism.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'extensive experiments ... demonstrate that MAVIS achieves competitive performance' supplies no quantitative results, baselines, metrics, error bars, or experimental protocol, preventing verification of the central performance claim.
Authors: We agree that the abstract should include quantitative support for the performance claim to allow immediate verification. In the revised manuscript we will add the key metrics (e.g., R@1, R@5, R@10 on MSR-VTT, MSVD, and ActivityNet), the main baselines, and a brief statement of the evaluation protocol while respecting abstract length constraints. revision: yes
-
Referee: [Abstract and §2] Abstract and §2 (framework description): the construction of the Structured Semantic Library is described only at the conceptual level with no parser details, error analysis, or ablation on attribute fidelity (e.g., temporal relations or fine-grained actions). This is load-bearing for the claim that the library enables accurate downstream retrieval, as systematic omissions would corrupt input to the planner, agents, and debate mechanism.
Authors: We acknowledge that the current description of the Structured Semantic Library remains high-level. We will expand §2 with concrete parser implementation details (model, prompting strategy, output schema), an error analysis of attribute extraction on a held-out set, and an ablation study measuring the impact of temporal-relation and action-attribute fidelity on end-to-end retrieval metrics. revision: yes
Circularity Check
No circularity: conceptual framework with no equations or self-referential derivations
full rationale
The paper describes a multi-agent video retrieval framework at the architectural level, with no equations, fitted parameters, or mathematical derivations present in the abstract or described structure. The Structured Semantic Library is introduced as an input processing step rather than defined in terms of downstream outputs. No self-citations are invoked as load-bearing uniqueness theorems, and performance claims rest on external experiments rather than internal reductions. This is a standard non-circular systems paper.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Structured Semantic Library
no independent evidence
-
Logic-aware Debate mechanism with strict veto protocol
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Msr-vtt: A large video description dataset for bridging video and language , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[2]
Proceedings of the IEEE international conference on computer vision , pages=
Youtube2text: Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot recognition , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[3]
Proceedings of the 44th International ACM SIGIR Conference on research and development in information retrieval , pages=
Hierarchical cross-modal graph consistency learning for video-text retrieval , author=. Proceedings of the 44th International ACM SIGIR Conference on research and development in information retrieval , pages=
-
[4]
Proceedings of the 30th ACM International Conference on Multimedia , pages=
Cross-lingual cross-modal retrieval with noise-robust learning , author=. Proceedings of the 30th ACM International Conference on Multimedia , pages=
-
[5]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Unified coarse-to-fine alignment for video-text retrieval , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[6]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
VoP: Text-Video Co-Operative Prompt Tuning for Cross-Modal Retrieval , author=. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
2023
-
[7]
Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Video corpus moment retrieval with contrastive learning , author=. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[8]
Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XXI 16 , pages=
Tvr: A large-scale dataset for video-subtitle moment retrieval , author=. Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XXI 16 , pages=. 2020 , organization=
2020
-
[9]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[10]
Neurocomputing , volume=
Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning , author=. Neurocomputing , volume=. 2022 , publisher=
2022
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wang, Jiamian and Sun, Guohao and Wang, Pichao and Liu, Dongfang and Dianat, Sohail and Rabbani, Majid and Rao, Raghuveer and Tao, Zhiqiang , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[12]
International conference on machine learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[13]
Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , pages=
Text-video retrieval with disentangled conceptualization and set-to-set alignment , author=. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , pages=
-
[14]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation , author=
-
[15]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Holistic features are almost sufficient for text-to-video retrieval , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[16]
arXiv preprint arXiv:2407.12508 , year=
Merlin: Multimodal embedding refinement via llm-based iterative navigation for text-video retrieval-rerank pipeline , author=. arXiv preprint arXiv:2407.12508 , year=
-
[17]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Text is mass: Modeling as stochastic embedding for text-video retrieval , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Dgl: Dynamic global-local prompt tuning for text-video retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Cap4video: What can auxiliary captions do for text-video retrieval? , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Videomae v2: Scaling video masked autoencoders with dual masking , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[21]
Proceedings of the 30th ACM International Conference on Multimedia , pages=
Partially relevant video retrieval , author=. Proceedings of the 30th ACM International Conference on Multimedia , pages=
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vita-clip: Video and text adaptive clip via multimodal prompting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Timechat: A time-sensitive multimodal large language model for long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Video-llama: An instruction-tuned audio-visual language model for video understanding , author=. arXiv preprint arXiv:2306.02858 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[27]
European Conference on Computer Vision , pages=
Llama-vid: An image is worth 2 tokens in large language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[28]
Advances in Neural Information Processing Systems , volume=
Self-chained image-language model for video localization and question answering , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[30]
Forty-first International Conference on Machine Learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first International Conference on Machine Learning , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Camel: Communicative agents for" mind" exploration of large language model society , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
VarCMP: Adapting Cross-Modal Pre-Training Models for Video Anomaly Retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Learning Dynamic Similarity by Bidirectional Hierarchical Sliding Semantic Probe for Efficient Text Video Retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[34]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Vca: Video curious agent for long video understanding , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[35]
React: Synergizing reasoning and acting in language models , author=
-
[36]
Advances in Neural Information Processing Systems , volume=
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Proceedings of the IEEE international conference on computer vision , pages=
Dense-captioning events in videos , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[38]
European Conference on Computer Vision , year=
InternVideo2: Scaling Foundation Models forMultimodal Video Understanding , author=. European Conference on Computer Vision , year=
-
[39]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Muse: Mamba is efficient multi-scale learner for text-video retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[40]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[41]
Proceedings of the 30th ACM international conference on multimedia , pages=
X-clip: End-to-end multi-grained contrastive learning for video-text retrieval , author=. Proceedings of the 30th ACM international conference on multimedia , pages=
-
[42]
Advances in Neural Information Processing Systems , volume=
Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment , author=. arXiv preprint arXiv:2310.01852 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
2024 , howpublished =
Introducing. 2024 , howpublished =
2024
-
[45]
VideoPrism: A Foundational Visual Encoder for Video Understanding , author=
-
[46]
IEEE Transactions on Circuits and Systems for Video Technology , year=
Linguistic hallucination for text-based video retrieval , author=. IEEE Transactions on Circuits and Systems for Video Technology , year=
-
[47]
arXiv preprint arXiv:2401.07339 , year=
Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges , author=. arXiv preprint arXiv:2401.07339 , year=
-
[48]
arXiv preprint arXiv:2503.10200 , year=
Lvagent: Long video understanding by multi-round dynamical collaboration of mllm agents , author=. arXiv preprint arXiv:2503.10200 , year=
-
[49]
arXiv preprint arXiv:2411.13093 , year=
Video-rag: Visually-aligned retrieval-augmented long video comprehension , author=. arXiv preprint arXiv:2411.13093 , year=
-
[50]
European Conference on Computer Vision , pages=
Videoagent: A memory-augmented multimodal agent for video understanding , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[51]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
H-GAR: A Hierarchical Interaction Framework via Goal-Driven Observation-Action Refinement for Robotic Manipulation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[52]
arXiv preprint arXiv:2603.08361 , year=
VLA: Prior-Guided Vision-Language-Action Models via World Knowledge Variation , author=. arXiv preprint arXiv:2603.08361 , year=
-
[53]
Proceedings of the 33nd ACM International Conference on Multimedia , year=
EmoSym: A Symbiotic Framework for Unified Emotional Understanding and Generation via Latent Reasoning , author=. Proceedings of the 33nd ACM International Conference on Multimedia , year=
-
[54]
UniEmo: Unifying Emotional Understanding and Generation with Learnable Expert Queries
UniEmo: Unifying Emotional Understanding and Generation with Learnable Expert Queries , author=. arXiv preprint arXiv:2507.23372 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
2025 , eprint=
TC-GS: Tri-plane based compression for 3D Gaussian Splatting , author=. 2025 , eprint=
2025
-
[56]
European Conference on Computer Vision , pages=
Cat: Enhancing multimodal large language model to answer questions in dynamic audio-visual scenarios , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[57]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Cat+: Investigating and enhancing audio-visual understanding in large language models , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[58]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
When Eyes and Ears Disagree: Can MLLMs Discern Audio-Visual Confusion? , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[59]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
SUGAR: Learning Skeleton Representation with Visual-Motion Knowledge for Action Recognition , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[60]
2024 , url =
Hai Nan and Qilang Ye and Zitong Yu and Kang An , title =. 2024 , url =
2024
-
[61]
IEEE Signal Processing Letters , year=
Pose-Promote: Progressive Visual Perception for Activities of Daily Living , author=. IEEE Signal Processing Letters , year=
-
[62]
2026 , eprint=
Retrieving to Recover: Towards Incomplete Audio-Visual Question Answering via Semantic-consistent Purification , author=. 2026 , eprint=
2026
-
[63]
Neural Networks , pages=
Mgtr-miss: More ground truth retrieving based multimodal interaction and semantic supervision for video description , author=. Neural Networks , pages=. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.