Physical Neural Networks Need Nonlinearity, Amplification, and Suppression for Learning
Pith reviewed 2026-06-26 02:00 UTC · model grok-4.3
The pith
Physical neural networks require signal amplification and suppression in addition to nonlinearity to perform nontrivial computations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Physical learning systems must support nonlinearity, amplification, and suppression to perform nontrivial computations; the authors demonstrate this requirement through simulations and supply physically plausible circuit designs that incorporate the three features.
What carries the argument
Circuit designs that combine nonlinearity with explicit amplification and suppression stages.
If this is right
- Linear physical networks remain restricted to trivial computations even when nonlinear elements are added without gain or suppression control.
- Effective physical learning requires hardware that can both boost and attenuate signals in addition to introducing nonlinearity.
- The supplied circuit designs provide a concrete route toward energy-efficient architectures that support general machine learning tasks.
- Absence of amplification or suppression in any physical substrate will prevent scaling to nontrivial learning performance.
Where Pith is reading between the lines
- The same three requirements may apply to optical, mechanical, or chemical physical computers beyond the electronic circuits examined here.
- Design rules derived from the circuits could be tested in other physical substrates to check whether amplification and suppression remain universally necessary.
- Failure to satisfy the three conditions in a given hardware platform would explain why many current physical neural networks plateau at low task complexity.
Load-bearing premise
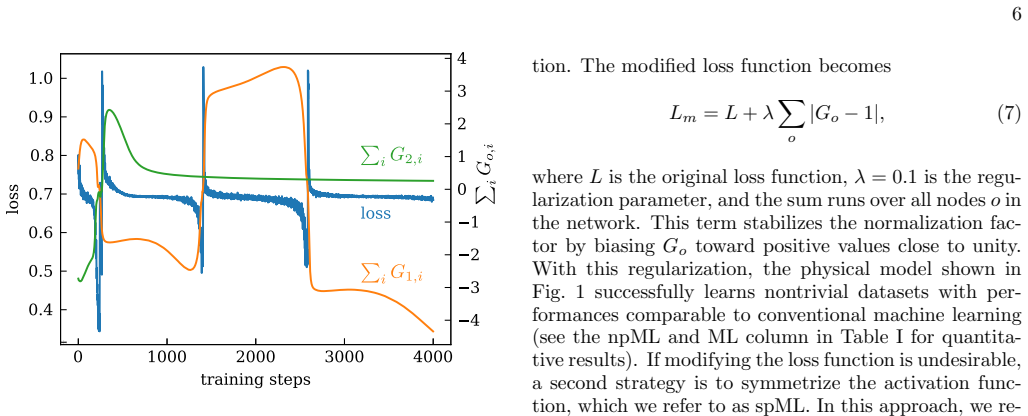
The simulations capture the behavior of real physical systems and the circuit designs can be built without unmodeled effects that eliminate the needed amplification or suppression.
What would settle it
A fabricated physical circuit matching the proposed designs that fails to achieve the predicted nonlinear computations because amplification or suppression is absent or destroyed by parasitic effects.
Figures



read the original abstract
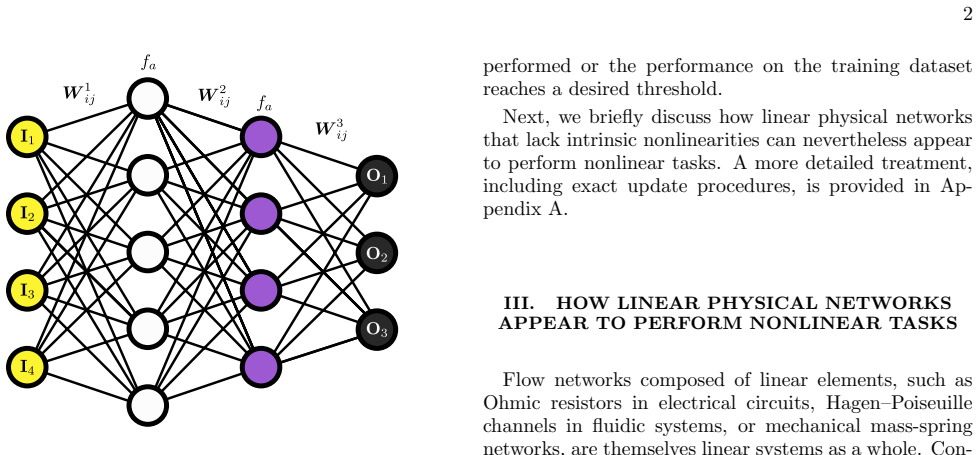
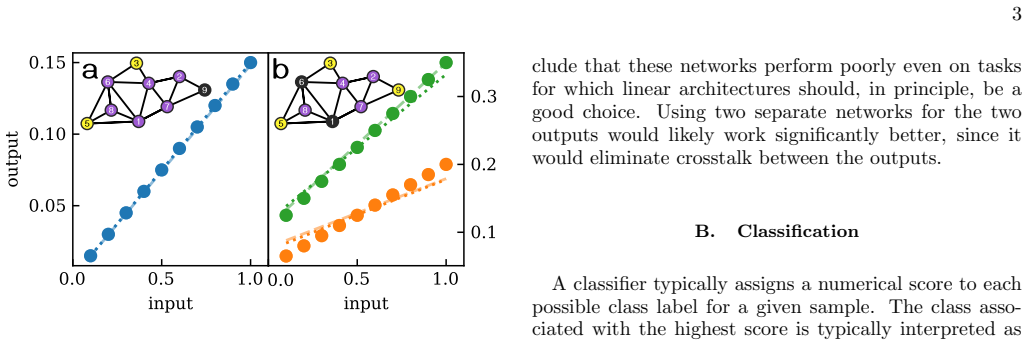
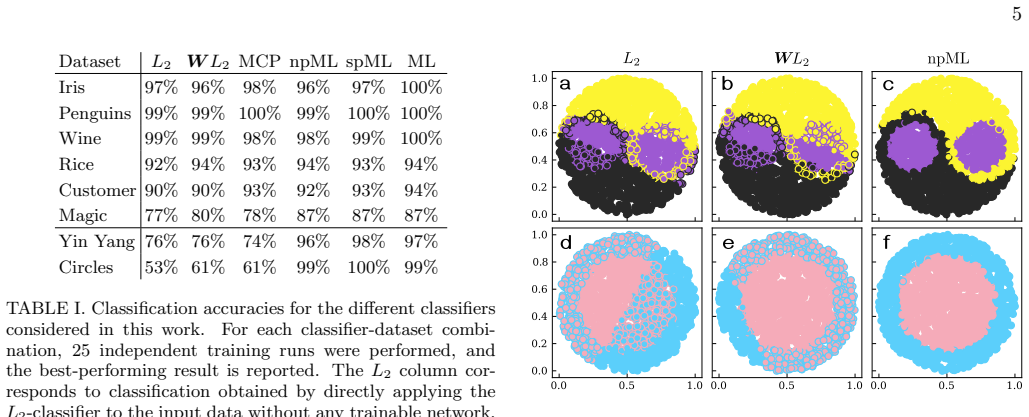
The exponential growth in energy consumption of artificial intelligence systems has spurred interest in physical computing paradigms that exploit the relaxation of physical systems toward steady states. However, many existing physical networks are fundamentally linear and incapable of performing nonlinear operations crucial for meaningful machine learning tasks. Here we use simulations to show that nonlinearity alone is insufficient; physical learning systems must also support signal amplification and suppression to perform nontrivial computations. We present physically plausible circuit designs that incorporate these essential features, enabling effective nonlinear information processing. Our findings clarify the limitations of linear physical networks and provide guidance for developing energy-efficient physical learning architectures capable of general machine learning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript uses simulations to argue that physical neural networks require not only nonlinearity but also signal amplification and suppression to perform nontrivial machine learning computations. It presents physically plausible circuit designs that incorporate these features to enable effective nonlinear information processing and clarifies limitations of linear physical networks.
Significance. If the simulation results hold under scrutiny, the work would offer concrete design guidance for energy-efficient physical learning architectures, highlighting that nonlinearity alone is insufficient for general tasks. No machine-checked proofs or parameter-free derivations are reported.
major comments (2)
- [Abstract] Abstract: the central claim that amplification and suppression are required rests entirely on unspecified simulations; no details on methods, parameter choices, error analysis, or validation against physical data are provided, so support for the claim cannot be assessed.
- The reported circuit designs are asserted to be physically plausible, but without quantitative results or implementation details it is impossible to evaluate whether unmodeled effects would destroy the required amplification or suppression.
minor comments (1)
- [Abstract] The abstract could explicitly state the scope of the simulations and any assumptions about physical realizability.
Simulated Author's Rebuttal
We thank the referee for their comments. We address each major point below, clarifying the content of the full manuscript while acknowledging its simulation-based scope.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that amplification and suppression are required rests entirely on unspecified simulations; no details on methods, parameter choices, error analysis, or validation against physical data are provided, so support for the claim cannot be assessed.
Authors: The abstract is intentionally concise. The full manuscript contains a Methods section specifying the simulation approach (numerical solution of circuit differential equations), exact parameter values for nonlinearity (diode models), amplification (op-amp gains), and suppression (resistive attenuation), as well as error analysis via ensemble statistics over randomized initial conditions. As this is a simulation study, no physical hardware validation is included; we acknowledge this limitation explicitly in the text. revision: partial
-
Referee: The reported circuit designs are asserted to be physically plausible, but without quantitative results or implementation details it is impossible to evaluate whether unmodeled effects would destroy the required amplification or suppression.
Authors: The manuscript supplies explicit circuit diagrams with component values, derives the effective input-output relations, and reports quantitative learning performance (accuracy and loss curves) for the designs. The components are standard and commercially available. We agree that a dedicated noise or parasitic analysis is absent and could be added, but the presented results demonstrate functionality under the modeled dynamics. revision: no
- Lack of any experimental validation on physical hardware implementations.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe simulation results establishing that nonlinearity alone is insufficient for physical learning systems and that amplification/suppression are also required, along with plausible circuit designs. No equations, derivations, self-citations, fitted parameters renamed as predictions, or ansatzes are presented that reduce the central claim to its own inputs by construction. The work is self-contained against external benchmarks via simulations, with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Feed all training samples belonging to classj through the network
-
[2]
Record the corresponding network outputs and compute their average, yielding the average output yj for classj
-
[3]
Repeat this procedure for all classes
-
[4]
Then compute the Euclidean distances|| ˆyi − yj||for each classj
To classify a new samplex i, feed it through the network to obtain the output ˆyi. Then compute the Euclidean distances|| ˆyi − yj||for each classj
-
[5]
reservoir
Assign the sample the predicted labell p corre- sponding to the classjyielding the minimal Eu- clidean distance. Formally, this procedure can be written as lp = arg min j ˆyi − yj = arg min j ∥W(x i − xj)∥,(4) 4 where xj denotes the average of all samples belonging to classj, and yj =W xj. This expression already sug- gests that the inclusion of the linea...
2020
-
[6]
Krizhevsky, I
A. Krizhevsky, I. Sutskever, and G. E. Hinton, Imagenet classification with deep convolutional neural networks, Communications of the ACM60, 84 (2017)
2017
-
[7]
S. V. Lab, Large scale visual recognition challenge 2012 (ilsvrc2012),https://image-net.org/challenges/ LSVRC/2012/results.html(2010)
2012
-
[8]
C. E. Tripp, J. Perr-Sauer, J. Gafur, A. Nag, A. Purkayastha, S. Zisman, and E. A. Bensen, Measur- ing the energy consumption and efficiency of deep neural networks: An empirical analysis and design recommen- dations (2024), arXiv:2403.08151 [cs.LG]
arXiv 2024
-
[9]
Markovi´ c, A
D. Markovi´ c, A. Mizrahi, D. Querlioz, and J. Grollier, Physics for neuromorphic computing, Nature Reviews Physics2, 499 (2020)
2020
-
[10]
Zhang, P
S. Zhang, P. Huang, H. You, X. Wu, W. Chen, L. Zhang, and Q. Cui, Readout scheme in analog computing-in- memory: Review of design principles and recent progress, Microelectronic Engineering305, 112466 (2026)
2026
-
[11]
Yamazaki, V.-K
K. Yamazaki, V.-K. Vo-Ho, D. Bulsara, and N. Le, Spik- ing neural networks and their applications: A review, Brain Sciences12, 863 (2022)
2022
-
[12]
Chun and T
H. Chun and T. D. Chung, Iontronics, Annual Review of Analytical Chemistry8, 441 (2015)
2015
-
[13]
Y. Du, R. van Mastrigt, J. Veenstra, and C. Coulais, Metamaterials that learn to change shape, Nature Physics 10.1038/s41567-026-03226-2 (2026)
-
[14]
Shohat and M
D. Shohat and M. van Hecke, Geometric control and memory in networks of hysteretic elements, Physical Re- view Letters134, 188201 (2025)
2025
-
[15]
E. R. W. van Doremaele, X. Ji, J. Rivnay, and Y. van de Burgt, A retrainable neuromorphic biosensor for on-chip learning and classification, Nature Electronics6, 765 (2023)
2023
-
[16]
Multimodal oscillator networks learn to solve a classification problem , volume =
D. de Bos and M. Serra-Garcia, Multimodal oscillator networks learn to solve a classification problem, npj Metamaterials2, 10.1038/s44455-025-00015-4 (2026)
-
[17]
Taglietti, A
F. Taglietti, A. Pulici, M. Roxburgh, G. Seguini, I. Vi- damour, S. Menzel, E. Franco, M. Laus, E. Vasilaki, M. Perego, T. J. Hayward, M. Fanciulli, and J. C. Gartside, Learning nonlinear heterogeneity in physical kolmogorov-arnold networks (2026)
2026
-
[18]
Zolfagharinejad, J
M. Zolfagharinejad, J. B¨ uchel, L. Cassola, S. Kinge, G. S. Syed, A. Sebastian, and W. G. van der Wiel, Analogue speech recognition based on physical computing, Nature 645, 886 (2025)
2025
-
[19]
Dillavou, M
S. Dillavou, M. Stern, A. J. Liu, and D. J. Durian, Demonstration of decentralized physics-driven learning, Phys. Rev. Appl.18, 014040 (2022)
2022
-
[20]
V. R. Anisetti, B. Scellier, and J. M. Schwarz, Learning by non-interfering feedback chemical signaling in physical networks, Physical Review Research5, 023024 (2023)
2023
-
[21]
Y. Cai, Achieve the minimum width of neural networks for universal approximation (2022), arXiv:2209.11395 [cs.LG]
arXiv 2022
-
[22]
Stern, D
M. Stern, D. Hexner, J. W. Rocks, and A. J. Liu, Super- vised learning in physical networks: From machine learn- ing to learning machines, Physical Review X11, 021045 (2021)
2021
-
[23]
Chorowski and J
J. Chorowski and J. M. Zurada, Learning understandable neural networks with nonnegative weight constraints, IEEE Transactions on Neural Networks and Learning Systems26, 62 (2015)
2015
-
[24]
R. A. Fisher, Iris, UCI Machine Learning Repository (1936), DOI: https://doi.org/10.24432/C56C76
-
[25]
A. M. Horst, A. P. Hill, and K. B. Gorman, palmer- penguins: Palmer archipelago (antarctica) penguin data 8 (2020), r package version 0.1.0
2020
-
[26]
S. Aeberhard and M. Forina, Wine, UCI Machine Learning Repository (1992), DOI: https://doi.org/10.24432/C5PC7J
-
[27]
M. K. lkay Cinar, Rice (Cammeo and Osman- cik), UCI Machine Learning Repository (2019), DOI: https://doi.org/10.24432/C5MW4Z
-
[28]
M. Cardoso, Wholesale customers, UCI Ma- chine Learning Repository (2013), DOI: https://doi.org/10.24432/C5030X
-
[29]
R. Bock, MAGIC Gamma Telescope, UCI Machine Learning Repository (2004), DOI: https://doi.org/10.24432/C52C8B
-
[30]
L. Kriener, J. G¨ oltz, and M. A. Petrovici, The yin-yang dataset (2021), arXiv:2102.08211 [cs.AI]
arXiv 2021
-
[31]
M. H. Amin, M. Elbtity, M. Mohammadi, and R. Zand, Mram-based analog sigmoid function for in-memory com- puting,Proceedings of the Great Lakes Symposium on VLSI 2022, Proceedings of the Great Lakes Symposium on VLSI 2022 (GLSVLSI ’22), Association for Comput- ing Machinery, New York, NY, USA, 319-323 GLSVLSI ’22, 319 (2022), arXiv:2204.09918 [cs.ET]
arXiv 2022
-
[32]
S. Xu, X. Li, C. Xie, H. Chen, C. Chen, and Z. Song, A high-precision implementation of the sigmoid activation function for computing-in-memory architecture, Micro- machines12, 1183 (2021)
2021
-
[33]
N. C. X. Stuhlm¨ uller and M. Dijkstra, Code for: Physi- cal neural networks need nonlinearity, amplification and suppression for learning (2026)
2026
-
[34]
N. C. X. Stuhlm¨ uller and D. Marjolein, Data for: Phys- ical neural networks need nonlinearity, amplification and suppression for learning, 10.5281/zenodo.20845832 (2026)
-
[35]
Melamed, G
O. Melamed, G. Yehudai, and G. Vardi, Provable un- learning with gradient ascent on two-layer relu neural networks (2025)
2025
-
[36]
D. J. Watts and S. H. Strogatz, Collective dynamics of ‘small-world’ networks, Nature393, 440 (1998). 9 Appendix A: Contrastive learning rule For training the network using a contrastive local up- date rule, two identical copies of the same network are re- quired [14]. In thefreephase, input voltages are applied to the input nodes and the resulting output...
1998
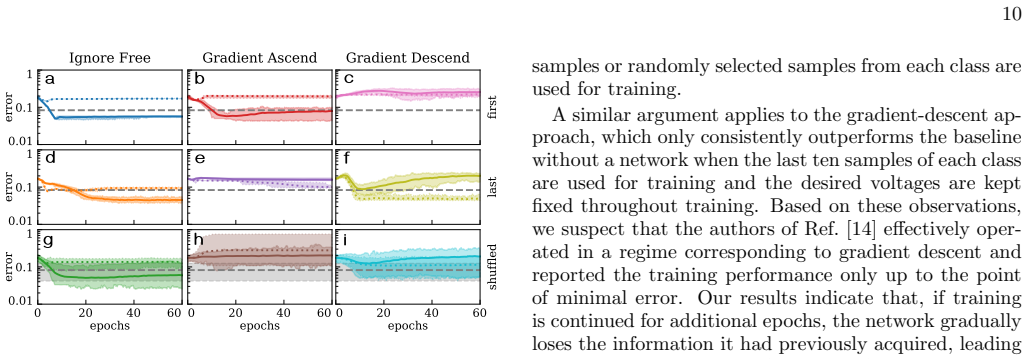
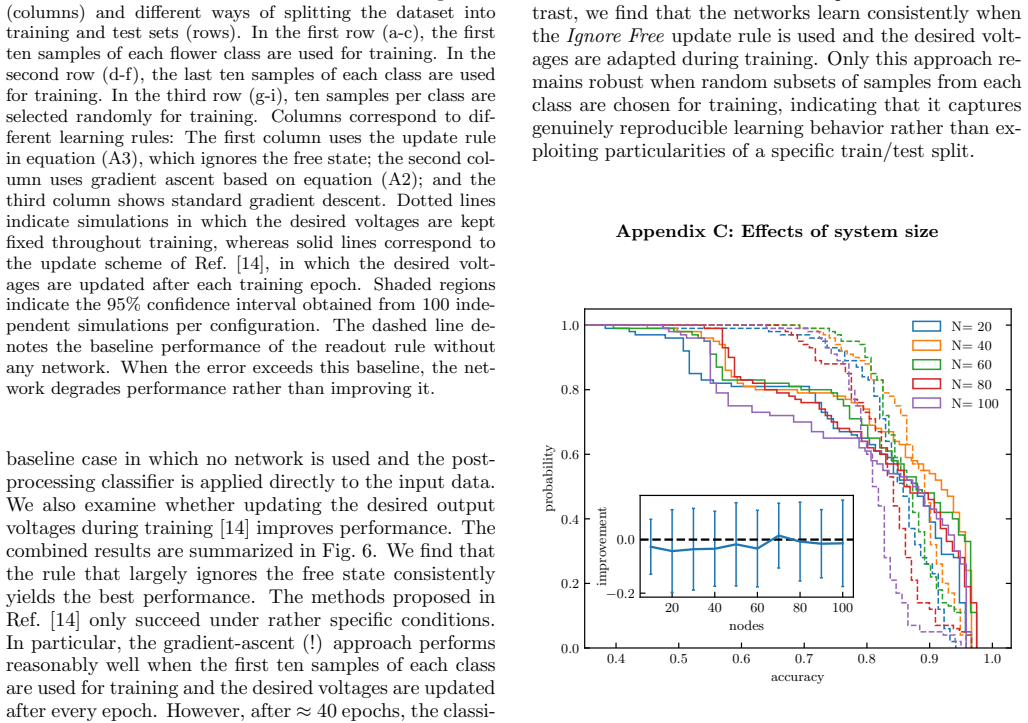
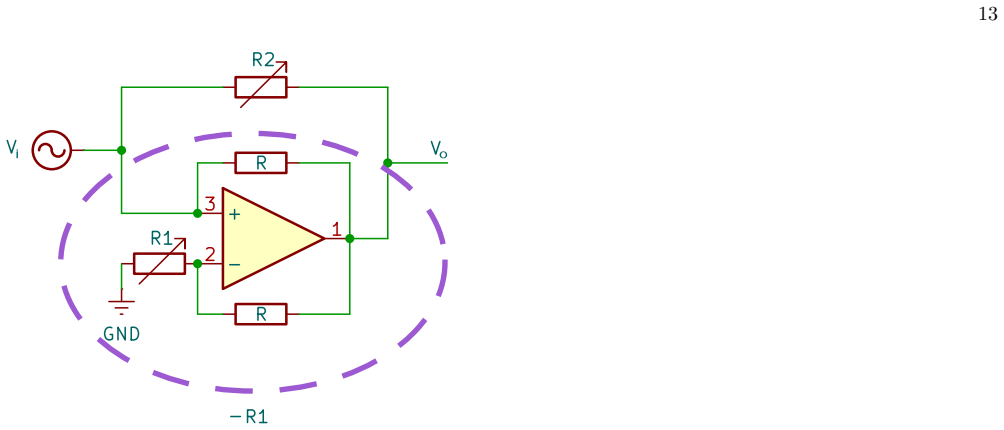
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.