Global Structure-from-Motion Meets Feedforward Reconstruction
Pith reviewed 2026-06-29 22:28 UTC · model grok-4.3
The pith
A hybrid SfM pipeline integrates feedforward 3D predictions into classical global optimization to handle both standard and difficult image collections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a new Structure-from-Motion pipeline by combining the respective strengths of classical and feedforward methods. The resulting system achieves state-of-the-art results across a wide range of scenarios while remaining scalable and open-source.
What carries the argument
The integration step that supplies feedforward reconstruction outputs as inputs to the classical global SfM optimizer.
If this is right
- Better recovery of scenes with low texture or symmetries that defeat pure classical pipelines.
- Retained accuracy and speed on standard datasets where feedforward methods alone degrade.
- A single open-source implementation that works across both challenging and routine reconstruction tasks.
Where Pith is reading between the lines
- The same integration pattern could be tested on other classical vision pipelines that currently lack feedforward priors.
- If the feedforward component can be made faster, the overall system might support real-time or incremental SfM.
- Failure modes of the hybrid would likely appear first in very large unordered collections where global optimization already strains memory.
Load-bearing premise
Feedforward outputs can be inserted into the classical optimizer without creating new scalability bottlenecks or robustness failures.
What would settle it
On a large mixed dataset the hybrid pipeline produces lower accuracy or slower runtimes than the stronger of the two separate methods alone.
Figures

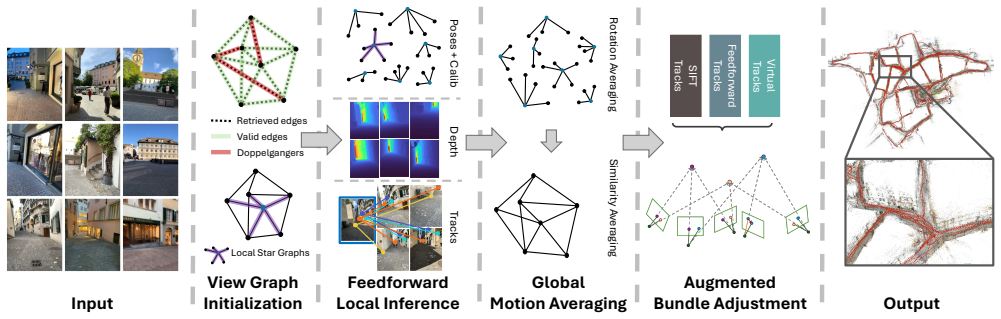

read the original abstract
Structure-from-Motion -- the process of simultaneously estimating camera poses and 3D scene structure from a collection of images -- remains a central challenge in computer vision, with many open problems yet to be solved. Recent advances in feedforward 3D reconstruction have made significant strides in overcoming persistent failure cases of classical SfM methods, particularly in scenarios characterized by low texture, limited overlap, and symmetries. However, while feedforward approaches excel in these challenging conditions, they often face limitations regarding scalability, accuracy, or robustness, and typically fall short of classical methods in standard reconstruction settings. In this work, we systematically analyze these limitations and propose a new Structure-from-Motion pipeline by combining the respective strengths of classical and feedforward methods. Extensive experiments across multiple datasets show the benefits of our approach, achieving state-of-the-art results across a wide range of scenarios. We share our system as an open-source implementation at https://github.com/colmap/gluemap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hybrid Structure-from-Motion pipeline that fuses feedforward 3D reconstruction outputs with classical global SfM optimization to address failure cases in low-texture, low-overlap, and symmetric scenes while preserving accuracy and scalability in standard regimes. It reports state-of-the-art results on multiple datasets and releases the system as open-source code.
Significance. If the fusion mechanism is shown to be robust, the work could meaningfully advance practical SfM by demonstrating a concrete way to combine the complementary strengths of classical bundle adjustment and modern feedforward models, with the open-source release aiding reproducibility.
major comments (2)
- [Method section] The central integration step (described in the method section) lacks explicit analysis or bounds on how feedforward-specific errors (scale ambiguity, hallucinated geometry in low-overlap regions) propagate into the global optimizer or bundle adjustment; this is load-bearing for the claim that the hybrid approach avoids new scalability or robustness failures.
- [Experiments section] Experimental results claim SOTA across wide scenarios, but without reported ablation on the fusion hyperparameters or failure-mode analysis in large-scale or low-overlap sequences, it is unclear whether the reported gains hold when feedforward outputs are noisy.
minor comments (1)
- The abstract would benefit from naming the specific datasets and metrics used to support the SOTA claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and note planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Method section] The central integration step (described in the method section) lacks explicit analysis or bounds on how feedforward-specific errors (scale ambiguity, hallucinated geometry in low-overlap regions) propagate into the global optimizer or bundle adjustment; this is load-bearing for the claim that the hybrid approach avoids new scalability or robustness failures.
Authors: We acknowledge that formal bounds on error propagation would provide additional theoretical support. The integration normalizes feedforward point clouds to the scale of classical tracks prior to fusion and applies robust kernels within bundle adjustment to downweight outliers from hallucinations. While the manuscript relies on empirical evidence rather than closed-form bounds, the results across low-overlap and symmetric scenes indicate no new failure modes are introduced. In revision we will add a dedicated paragraph in the method section clarifying these normalization and weighting steps. revision: partial
-
Referee: [Experiments section] Experimental results claim SOTA across wide scenarios, but without reported ablation on the fusion hyperparameters or failure-mode analysis in large-scale or low-overlap sequences, it is unclear whether the reported gains hold when feedforward outputs are noisy.
Authors: The current experiments already evaluate the pipeline on multiple datasets containing large-scale, low-overlap, and low-texture sequences, with consistent gains over baselines. We agree that explicit hyperparameter ablations and targeted failure-case breakdowns would strengthen the claims. We will add these analyses to the experiments section in the revised manuscript. revision: yes
Circularity Check
No circularity: experimental integration paper with no load-bearing derivations or self-referential fits
full rationale
The manuscript proposes an SfM pipeline that fuses feedforward outputs into a classical global optimizer and validates the combination via experiments on multiple datasets. No equations, parameter fits, predictions, or uniqueness theorems appear in the provided abstract or claims. The central result is an empirical performance comparison, not a derivation that reduces to its own inputs by construction. No self-citation chains or ansatzes are invoked to justify the method. This is the common case of a self-contained engineering contribution whose correctness can be assessed externally via the reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Netvlad: Cnn architecture for weakly supervised place recognition
Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pa- jdla, and Josef Sivic. Netvlad: Cnn architecture for weakly supervised place recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5297–5307, 2016. 2, 3
2016
-
[2]
Bearing-based net- work localizability: A unifying view.IEEE transactions on pattern analysis and machine intelligence, 41(9):2049–2069,
Federica Arrigoni and Andrea Fusiello. Bearing-based net- work localizability: A unifying view.IEEE transactions on pattern analysis and machine intelligence, 41(9):2049–2069,
2049
-
[3]
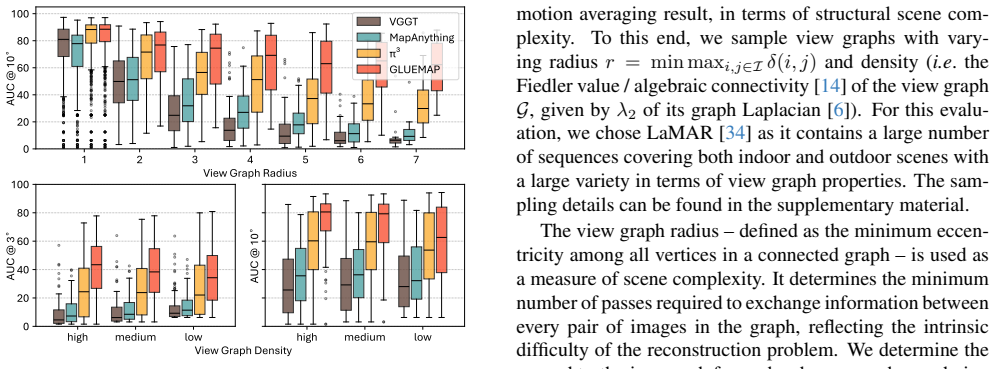
Megaloc: One retrieval to place them all
Gabriele Berton and Carlo Masone. Megaloc: One retrieval to place them all. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2861–2867, 2025. 3
2025
-
[4]
Doppelgangers: Learning to disambiguate images of similar structures
Ruojin Cai, Joseph Tung, Qianqian Wang, Hadar Averbuch- Elor, Bharath Hariharan, and Noah Snavely. Doppelgangers: Learning to disambiguate images of similar structures. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 34–44, 2023. 2, 3
2023
-
[5]
Efficient and robust large-scale rotation averaging
Avishek Chatterjee and Venu Madhav Govindu. Efficient and robust large-scale rotation averaging. InProceedings of the IEEE international conference on computer vision, pages 521–528, 2013. 2
2013
-
[6]
American Mathe- matical Soc., 1997
Fan RK Chung.Spectral graph theory. American Mathe- matical Soc., 1997. 6
1997
-
[7]
Global structure-from-motion by similarity averaging
Zhaopeng Cui and Ping Tan. Global structure-from-motion by similarity averaging. InProceedings of the IEEE interna- tional conference on computer vision, pages 864–872, 2015. 2, 5
2015
-
[8]
Junyuan Deng, Heng Li, Tao Xie, Weiqiang Ren, Qian Zhang, Ping Tan, and Xiaoyang Guo. Sail-recon: Large sfm by augmenting scene regression with localization.arXiv preprint arXiv:2508.17972, 2025. 3
-
[9]
Kai Deng, Zexin Ti, Jiawei Xu, Jian Yang, and Jin Xie. Vggt-long: Chunk it, loop it, align it–pushing vggt’s lim- its on kilometer-scale long rgb sequences.arXiv preprint arXiv:2507.16443, 2025. 2, 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 224–236, 2018. 2, 3
2018
-
[11]
Smerf: Streamable memory efficient radiance fields for real-time large-scene exploration
Daniel Duckworth, Peter Hedman, Christian Reiser, Pe- ter Zhizhin, Jean-Franc ¸ois Thibert, Mario Lu ˇci´c, Richard Szeliski, and Jonathan T Barron. Smerf: Streamable memory efficient radiance fields for real-time large-scene exploration. ACM Transactions on Graphics (TOG), 43(4):1–13, 2024. 6, 7, 8, 1, 2, 5
2024
-
[12]
Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion
Bardienus Pieter Duisterhof, Lojze Zust, Philippe Weinza- epfel, Vincent Leroy, Yohann Cabon, and Jerome Revaud. Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion. In2025 International Conference on 3D Vision (3DV), pages 1–10. IEEE, 2025. 3
2025
-
[13]
Rotation averaging and strong duality
Anders Eriksson, Carl Olsson, Fredrik Kahl, and Tat-Jun Chin. Rotation averaging and strong duality. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 127–135, 2018. 6
2018
-
[14]
Algebraic connectivity of graphs
Miroslav Fiedler. Algebraic connectivity of graphs. Czechoslovak mathematical journal, 23(2):298–305, 1973. 6
1973
-
[15]
Combining two-view constraints for motion estimation
Venu Madhav Govindu. Combining two-view constraints for motion estimation. InProceedings of the 2001 IEEE computer society conference on computer vision and pattern recognition. CVPR 2001, pages II–II. IEEE, 2001. 2
2001
-
[16]
Cambridge university press,
Richard Hartley and Andrew Zisserman.Multiple view ge- ometry in computer vision. Cambridge university press,
-
[17]
Optimal transport ag- gregation for visual place recognition
Sergio Izquierdo and Javier Civera. Optimal transport ag- gregation for visual place recognition. InProceedings of the ieee/cvf conference on computer vision and pattern recogni- tion, pages 17658–17668, 2024. 3, 4
2024
-
[18]
Image matching across wide baselines: From paper to practice
Yuhe Jin, Dmytro Mishkin, Anastasiia Mishchuk, Jiri Matas, Pascal Fua, Kwang Moo Yi, and Eduard Trulls. Image matching across wide baselines: From paper to practice. International Journal of Computer Vision, 129(2):517–547,
-
[19]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman M ¨uller, Johannes Sch ¨onberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed-forward metric 3d re- construction.arXiv preprint arXiv:2509.13414, 2025. 3, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023. 1
2023
-
[21]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InEuropean Confer- ence on Computer Vision, pages 71–91. Springer, 2024. 3
2024
-
[22]
Pixel-perfect structure-from- motion with featuremetric refinement
Philipp Lindenberger, Paul-Edouard Sarlin, Viktor Lars- son, and Marc Pollefeys. Pixel-perfect structure-from- motion with featuremetric refinement. InProceedings of the IEEE/CVF international conference on computer vision, pages 5987–5997, 2021. 3
2021
-
[23]
Lightglue: Local feature matching at light speed
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Polle- feys. Lightglue: Local feature matching at light speed. In Proceedings of the IEEE/CVF international conference on computer vision, pages 17627–17638, 2023. 2, 3
2023
-
[24]
Robust Incremental Structure-from-Motion with Hy- brid Features
Shaohui Liu, Yidan Gao, Tianyi Zhang, Remi Pautrat, Jo- hannes Lutz Sch ¨onberger, Viktor Larsson, and Marc Polle- feys. Robust Incremental Structure-from-Motion with Hy- brid Features. InECCV, 2024. 1, 3
2024
-
[25]
Distinctive image features from scale- invariant keypoints.International journal of computer vi- sion, 60(2):91–110, 2004
David G Lowe. Distinctive image features from scale- invariant keypoints.International journal of computer vi- sion, 60(2):91–110, 2004. 1, 2, 4
2004
-
[26]
VGGT-SLAM: Dense RGB SLAM Optimized on the SL(4) Manifold
Dominic Maggio, Hyungtae Lim, and Luca Carlone. Vggt- slam: Dense rgb slam optimized on the sl (4) manifold.arXiv preprint arXiv:2505.12549, 2025. 3 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Robust rotation and translation estimation in multiview reconstruction
Daniel Martinec and Tomas Pajdla. Robust rotation and translation estimation in multiview reconstruction. In2007 IEEE conference on computer vision and pattern recogni- tion, pages 1–8. IEEE, 2007. 2
2007
-
[28]
Openmvg: Open multiple view geometry
Pierre Moulon, Pascal Monasse, Romuald Perrot, and Re- naud Marlet. Openmvg: Open multiple view geometry. In International Workshop on Reproducible Research in Pattern Recognition, pages 60–74. Springer, 2016. 1
2016
-
[29]
Robust camera location esti- mation by convex programming
Onur Ozyesil and Amit Singer. Robust camera location esti- mation by convex programming. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2674–2683, 2015. 2
2015
-
[30]
Global structure-from-motion revisited
Linfei Pan, D ´aniel Bar´ath, Marc Pollefeys, and Johannes L Sch¨onberger. Global structure-from-motion revisited. In European Conference on Computer Vision, pages 58–77. Springer, 2024. 1, 2, 6, 7
2024
-
[31]
Mp-sfm: Monocular surface priors for robust structure-from-motion
Zador Pataki, Paul-Edouard Sarlin, Johannes L Sch ¨onberger, and Marc Pollefeys. Mp-sfm: Monocular surface priors for robust structure-from-motion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21891–21901, 2025. 1, 3, 5, 7, 8, 2
2025
-
[32]
Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF international conference on computer vision, pages 10901–10911, 2021. 6, 7, 3, 8, 9
2021
-
[33]
Superglue: Learning feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947, 2020. 3
2020
-
[34]
Lamar: Benchmarking localization and mapping for augmented reality
Paul-Edouard Sarlin, Mihai Dusmanu, Johannes L Sch¨onberger, Pablo Speciale, Lukas Gruber, Viktor Larsson, Ondrej Miksik, and Marc Pollefeys. Lamar: Benchmarking localization and mapping for augmented reality. InEuropean Conference on Computer Vision, pages 686–704. Springer, 2022. 6, 8, 2
2022
-
[35]
Fast image- based localization using direct 2d-to-3d matching
Torsten Sattler, Bastian Leibe, and Leif Kobbelt. Fast image- based localization using direct 2d-to-3d matching. In2011 International Conference on Computer Vision, pages 667–
-
[36]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 4104–4113, 2016. 1, 2
2016
-
[37]
A vote-and-verify strat- egy for fast spatial verification in image retrieval
Johannes Lutz Sch ¨onberger, True Price, Torsten Sattler, Jan- Michael Frahm, and Marc Pollefeys. A vote-and-verify strat- egy for fast spatial verification in image retrieval. InAsian Conference on Computer Vision (ACCV), 2016. 2
2016
-
[38]
Pixelwise View Selection for Un- structured Multi-View Stereo
Johannes Lutz Sch ¨onberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. Pixelwise View Selection for Un- structured Multi-View Stereo. InECCV, 2016. 1
2016
-
[39]
A multi-view stereo benchmark with high- resolution images and multi-camera videos
Thomas Schops, Johannes L Schonberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and An- dreas Geiger. A multi-view stereo benchmark with high- resolution images and multi-camera videos. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 3260–3269, 2017. 6, 7, 1, 3, 4
2017
-
[40]
FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
You Shen, Zhipeng Zhang, Yansong Qu, and Liujuan Cao. Fastvggt: Training-free acceleration of visual geometry transformer.arXiv preprint arXiv:2509.02560, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Photo tourism: exploring photo collections in 3d
Noah Snavely, Steven M Seitz, and Richard Szeliski. Photo tourism: exploring photo collections in 3d. InACM siggraph 2006 papers, pages 835–846. 2006. 1, 2
2006
-
[42]
Optimizing the viewing graph for structure-from-motion
Chris Sweeney, Torsten Sattler, Tobias Hollerer, Matthew Turk, and Marc Pollefeys. Optimizing the viewing graph for structure-from-motion. InProceedings of the IEEE interna- tional conference on computer vision, pages 801–809, 2015. 2
2015
-
[43]
Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds
Zhenggang Tang, Yuchen Fan, Dilin Wang, Hongyu Xu, Rakesh Ranjan, Alexander Schwing, and Zhicheng Yan. Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 5283–5293,
-
[44]
The interpretation of structure from mo- tion.Proceedings of the Royal Society of London
Shimon Ullman. The interpretation of structure from mo- tion.Proceedings of the Royal Society of London. Series B. Biological Sciences, 203(1153):405–426, 1979. 1
1979
-
[45]
Posediffusion: Solving pose estimation via diffusion-aided bundle adjustment
Jianyuan Wang, Christian Rupprecht, and David Novotny. Posediffusion: Solving pose estimation via diffusion-aided bundle adjustment. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 9773–9783,
-
[46]
Vggsfm: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. Vggsfm: Visual geometry grounded deep structure from motion. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 21686–21697, 2024. 3, 4, 1, 2
2024
-
[47]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 1, 3, 6, 7
2025
-
[48]
Continuous 3d per- ception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d per- ception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025. 3, 7
2025
-
[49]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20697– 20709, 2024. 3
2024
-
[50]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. pi3: Scalable permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Towards linear-time incremental struc- ture from motion
Changchang Wu. Towards linear-time incremental struc- ture from motion. In2013 International Conference on 3D Vision-3DV 2013, pages 127–134. IEEE, 2013. 1
2013
-
[52]
Doppelgangers++: Improved visual disam- biguation with geometric 3d features
Yuanbo Xiangli, Ruojin Cai, Hanyu Chen, Jeffrey Byrne, and Noah Snavely. Doppelgangers++: Improved visual disam- biguation with geometric 3d features. InProceedings of the 10 Computer Vision and Pattern Recognition Conference, pages 27166–27175, 2025. 3, 4, 7, 2
2025
-
[53]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935,
-
[54]
Disambiguating visual relations using loop constraints
Christopher Zach, Manfred Klopschitz, and Marc Polle- feys. Disambiguating visual relations using loop constraints. In2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 1426–1433. IEEE,
-
[55]
Cameras as rays: Pose estimation via ray diffusion.arXiv preprint arXiv:2402.14817, 2024
Jason Y Zhang, Amy Lin, Moneish Kumar, Tzu-Hsuan Yang, Deva Ramanan, and Shubham Tulsiani. Cameras as rays: Pose estimation via ray diffusion.arXiv preprint arXiv:2402.14817, 2024. 3
-
[56]
Aliked: A lighter keypoint and descriptor extraction network via deformable transformation.IEEE Transactions on Instrumentation and Measurement, 72:1–16, 2023
Xiaoming Zhao, Xingming Wu, Weihai Chen, Peter CY Chen, Qingsong Xu, and Zhengguo Li. Aliked: A lighter keypoint and descriptor extraction network via deformable transformation.IEEE Transactions on Instrumentation and Measurement, 72:1–16, 2023. 2, 3
2023
-
[57]
Baseline desensitizing in translation averaging
Bingbing Zhuang, Loong-Fah Cheong, and Gim Hee Lee. Baseline desensitizing in translation averaging. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4539–4547, 2018. 2
2018
-
[58]
Streaming 4D Visual Geometry Transformer
Dong Zhuo, Wenzhao Zheng, Jiahe Guo, Yuqi Wu, Jie Zhou, and Jiwen Lu. Streaming 4d visual geometry transformer. arXiv preprint arXiv:2507.11539, 2025. 3 11 Global Structure-from-Motion Meets Feedforward Reconstruction Supplementary Material
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Ablations To understand the contribution of each component, we con- duct ablation studies along three axes: the track types used in augmented bundle adjustment, the choice of feedforward backbone, and the covisibility filtering strategy. 6.1. Augmented Bundle Adjustment Augmented bundle adjustment (A-BA) is ablated in Ta- ble 6, where all variants start f...
-
[60]
Different Radius for Local Estimation The proposed method fixes the radius to 1 for local esti- mation, which maximizes the overlap between neighboring views within each star graph
Alternative System Designs 7.1. Different Radius for Local Estimation The proposed method fixes the radius to 1 for local esti- mation, which maximizes the overlap between neighboring views within each star graph. Increasing the radius is not straightforward: it would require a graph expansion step, and feedforward tracking only works when frames pairs ha...
-
[61]
All experiments are conducted on an Neoverse-V2 CPU with 856 GB RAM and an NVIDIA GH200 GPU with 96 GB memory
Runtime Component-level runtime statistics are summarized in Ta- ble 9 and Table 10. All experiments are conducted on an Neoverse-V2 CPU with 856 GB RAM and an NVIDIA GH200 GPU with 96 GB memory. Abatchrefers to an im- age pair or a star. Because the number of retrieved pairs and the maximum number of neighbors per image are fixed, the runtime of Doppelga...
-
[62]
For each sequence, we select a random center frame every 200 images
Sampling Method for Analysis We consider all sequences in the LaMAR [34] dataset. For each sequence, we select a random center frame every 200 images. Around each center frame, we extract subse- quences at multiple temporal densities: • Consecutive sampling (high density): subsequences of length 4, 8, 16, 32, 64, and 128 frames. • Sampling every 2 frames ...
-
[63]
Track Mixing Strategy The three source of tracks, namely SIFT, feedforward tracks, and virtual tracks, are combined through a priority- based mixing strategy before being passed to the final bun- dle adjustment. The goal is to ensure that every image pair receives sufficient constraints while prioritizing SIFT tracks which have the highest accuracy and av...
-
[64]
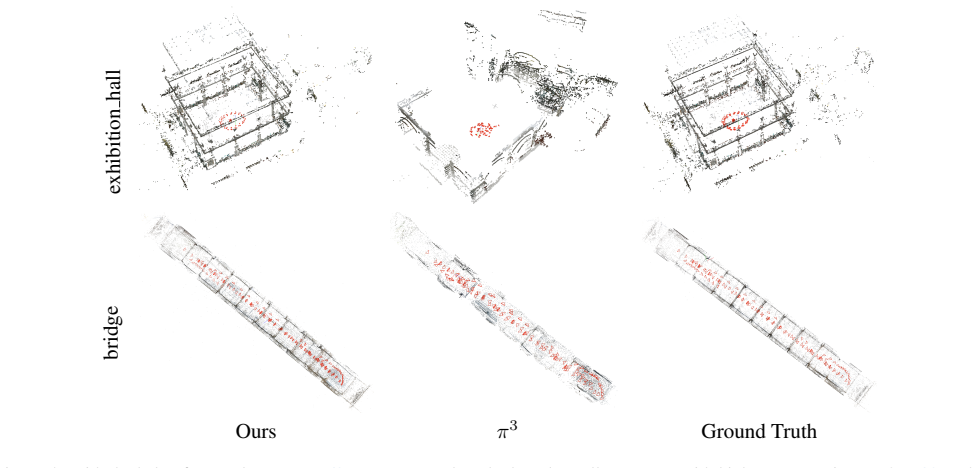
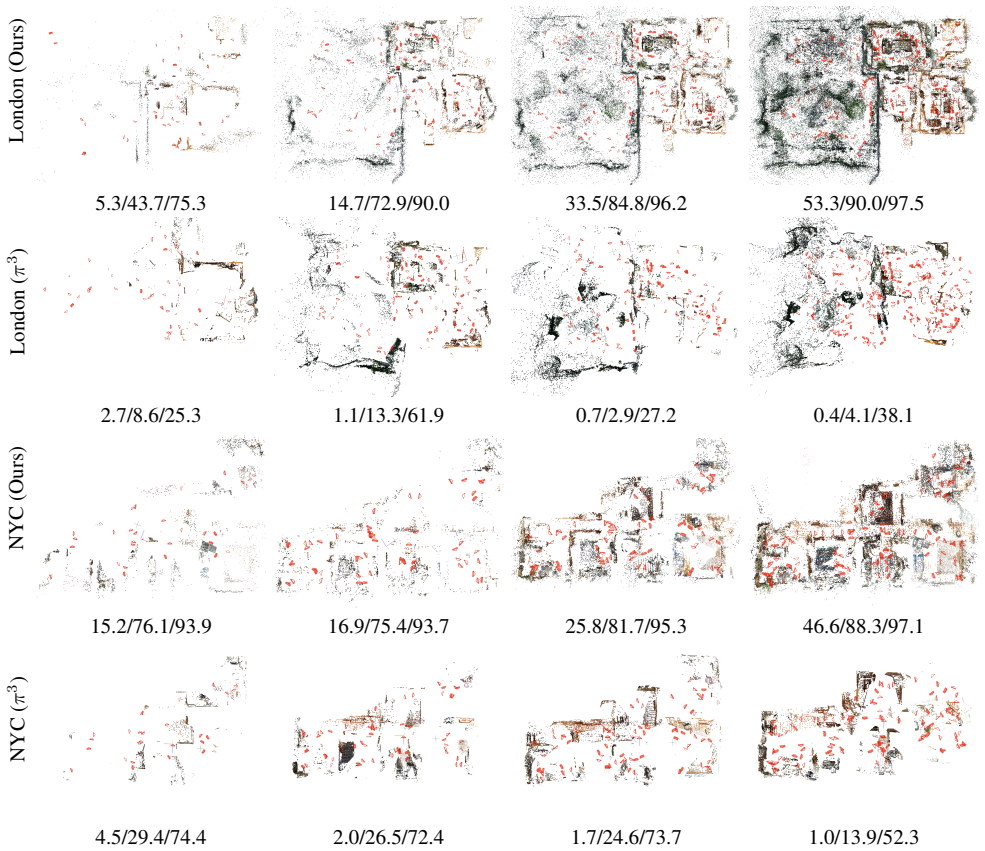
More Visualizations To demonstrate the concrete challenges faced by Structure- from-Motion, we provide further visual examples. In symmetric scenes, feedforward methods often have difficulty distinguishing visually similar structures, result- ing in collapsed reconstructions where distinct parts of the scene are incorrectly merged. One such example with f...
-
[65]
For ETH3D [39], per-scene results can be found in Table 11
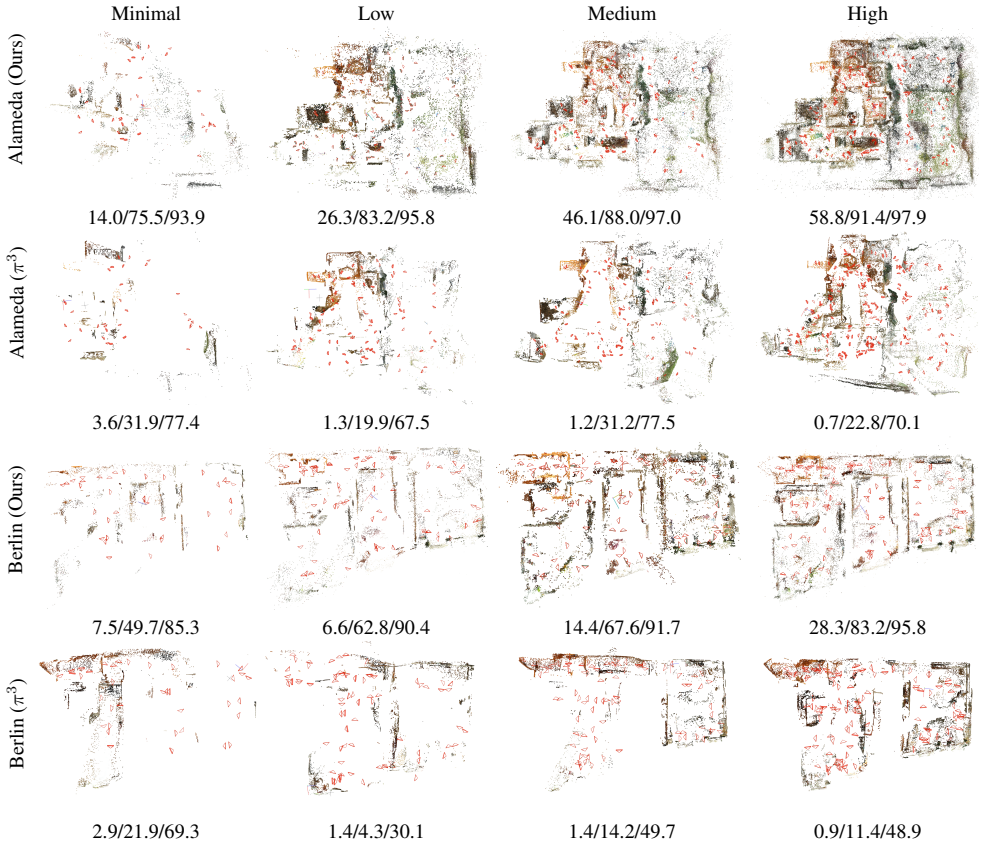
Detailed results In this section, we provide per-scene and per-category breakdowns for ETH3D [39], CO3DV2 [32], and IMC2021 [18]. For ETH3D [39], per-scene results can be found in Table 11. ETH3D features high-resolution images with millimeter-accurate ground truth across diverse indoor and outdoor environments. The proposed method achieves the highest ac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.