Mixed-Signal Charge-Domain Acceleration of Deep Neural networks through Interleaved Bit-Partitioned Arithmetic
Pith reviewed 2026-05-25 13:42 UTC · model grok-4.3
The pith
Bit-partitioning dot-products into interleaved low-bitwidth groups lets mixed-signal circuits accumulate in charge domain and share A/D converters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
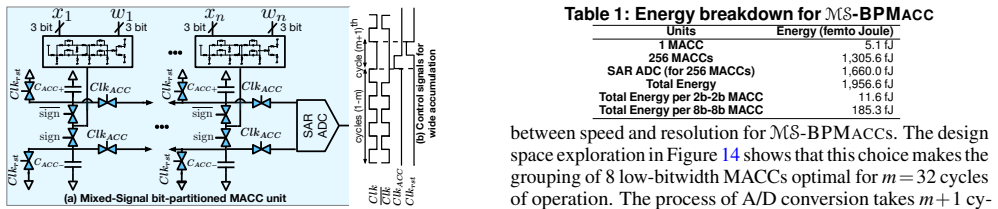
A vector dot-product can be bit-partitioned into groups of spatially parallel low-bitwidth operations interleaved across multiple elements of the vectors, so that groups of wide yet low-bitwidth multiply-accumulate units operate in the analog domain and share a single A/D converter, with switched-capacitor circuitry performing the group multiplications in the charge domain and accumulating the results of the group in its capacitors over multiple cycles.
What carries the argument
Interleaved bit-partitioned arithmetic realized through switched-capacitor charge-domain accumulation that shares one A/D converter across a group.
Load-bearing premise
Low-bitwidth bit-partitioned operations performed in the analog domain can handle encoding range limits and noise while the interleaved capacitive accumulation preserves the accuracy of the original DNN computation.
What would settle it
A direct accuracy comparison between a full DNN inference run on the proposed charge-domain interleaved bit-partitioned units versus an equivalent high-precision digital implementation, or power measurements showing whether A/D conversion energy per dot-product actually drops.
Figures










read the original abstract
Low-power potential of mixed-signal design makes it an alluring option to accelerate Deep Neural Networks (DNNs). However, mixed-signal circuitry suffers from limited range for information encoding, susceptibility to noise, and Analog to Digital (A/D) conversion overheads. This paper aims to address these challenges by offering and leveraging the insight that a vector dot-product (the basic operation in DNNs) can be bit-partitioned into groups of spatially parallel low-bitwidth operations, and interleaved across multiple elements of the vectors. As such, the building blocks of our accelerator become a group of wide, yet low-bitwidth multiply-accumulate units that operate in the analog domain and share a single A/D converter. The low-bitwidth operation tackles the encoding range limitation and facilitates noise mitigation. Moreover, we utilize the switched-capacitor design for our bit-level reformulation of DNN operations. The proposed switched-capacitor circuitry performs the group multiplications in the charge domain and accumulates the results of the group in its capacitors over multiple cycles. The capacitive accumulation combined with wide bit-partitioned operations alleviate the need for A/D conversion per operation. With such mathematical reformulation and its switched-capacitor implementation, we define a 3D-stacked microarchitecture, dubbed BIHIWE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a bit-partitioned reformulation of vector dot-products for DNN acceleration, enabling groups of low-bitwidth analog multiply-accumulate operations that share a single A/D converter. It describes a switched-capacitor implementation for charge-domain group multiplications with capacitive accumulation across cycles, and defines a 3D-stacked microarchitecture (BIHIWE) intended to reduce per-operation A/D overheads while addressing encoding range and noise issues via low-bitwidth operations.
Significance. If the claims on accuracy preservation and overhead reduction hold under realistic noise and process variation, the approach could enable more efficient mixed-signal DNN accelerators by minimizing A/D conversions through interleaved bit-partitioned charge-domain accumulation. The switched-capacitor reformulation is a concrete implementation idea that merits further exploration if supported by analysis.
major comments (2)
- [Abstract] Abstract: The central claims regarding noise mitigation, encoding range handling, and A/D overhead reduction via low-bitwidth bit-partitioned operations and interleaved capacitive accumulation are presented at a high level only, with no quantitative results, error analysis, simulations, circuit derivations, or accuracy evaluations provided to support them.
- [Abstract (paragraph on insight and implementation)] The weakest assumption—that low-bitwidth analog operations combined with switched-capacitor accumulation can maintain sufficient accuracy without per-operation A/D conversions—is not accompanied by any supporting derivation, noise model, or empirical validation in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, agreeing where additional support is needed and outlining revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims regarding noise mitigation, encoding range handling, and A/D overhead reduction via low-bitwidth bit-partitioned operations and interleaved capacitive accumulation are presented at a high level only, with no quantitative results, error analysis, simulations, circuit derivations, or accuracy evaluations provided to support them.
Authors: We agree that the abstract presents the claims at a high level. The manuscript body provides the bit-partitioned reformulation of dot-products, the switched-capacitor implementation details, and the 3D-stacked microarchitecture definition. In revision we will expand the abstract to incorporate key quantitative estimates (such as A/D conversion reduction factors) drawn from the analysis already present in the paper. revision: yes
-
Referee: [Abstract (paragraph on insight and implementation)] The weakest assumption—that low-bitwidth analog operations combined with switched-capacitor accumulation can maintain sufficient accuracy without per-operation A/D conversions—is not accompanied by any supporting derivation, noise model, or empirical validation in the manuscript.
Authors: The referee correctly notes that the accuracy claim requires explicit support. The current manuscript argues qualitatively that low-bitwidth operations mitigate encoding-range and noise issues but does not include a noise model or derivation. We will add an analytical noise model and supporting derivation in the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents a novel architectural proposal that reformulates vector dot-products as interleaved bit-partitioned low-bitwidth analog operations implemented via switched-capacitor circuits, leading to the BIHIWE microarchitecture. No load-bearing step reduces by construction to fitted parameters, self-definitions, or self-citation chains; the central claims introduce independent design elements (group MAC units sharing A/D, capacitive accumulation over cycles) whose validity rests on the stated circuit properties rather than prior outputs of the same work. The provided abstract and description contain no equations or citations that exhibit the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a vector dot-product ... can be bit-partitioned into groups of spatially parallel low-bitwidth operations, and interleaved across multiple elements of the vectors ... switched-capacitor circuitry performs the group multiplications in the charge domain and accumulates the results ... over multiple cycles
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The low-bitwidth operation tackles the encoding range limitation and facilitates noise mitigation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Niehues, N.-Q. Pham, T.-L. Ha, M. Sperber, and A. Waibel. Low-Latency Neural Speech Translation. ArXiv e-prints, August 2018
work page 2018
- [2]
-
[3]
R. Li, Y . Shu, J. Su, H. Feng, and J. Wang. Using deep Residual Network to search for galaxy-Ly {\alpha} emitter lens candidates based on spectroscopic-selection. ArXiv e-prints, July 2018
work page 2018
- [4]
- [5]
-
[6]
Amant, Karthikeyan Sankaralingam, and Doug Burger
Hadi Esmaeilzadeh, Emily Blem, Renee St. Amant, Karthikeyan Sankaralingam, and Doug Burger. Dark silicon and the end of multicore scaling. InISCA, 2011
work page 2011
-
[7]
N. Hardavellas, M. Ferdman, B. Falsafi, and A. Ailamaki. Toward dark silicon in servers.IEEE Micro, 31(4):6–15, July–Aug. 2011
work page 2011
-
[8]
Conservation cores: Reducing the energy of mature computations
Ganesh Venkatesh, Jack Sampson, Nathan Goulding, Saturnino Garcia, Vladyslav Bryksin, Jose Lugo- Martinez, Steven Swanson, and Michael Bedford Taylor. Conservation cores: Reducing the energy of mature computations. In ASPLOS, 2010
work page 2010
-
[9]
Optimizing fpga-based accelerator design for deep convolutional neural networks
Chen Zhang, Peng Li, Guangyu Sun, Yijin Guan, Bingjun Xiao, and Jason Cong. Optimizing fpga-based accelerator design for deep convolutional neural networks. In FPGA, 2015
work page 2015
-
[10]
Neural acceleration for general-purpose approximate programs
Hadi Esmaeilzadeh, Adrian Sampson, Luis Ceze, and Doug Burger. Neural acceleration for general-purpose approximate programs. to apear in Commun. ACM , 2013
work page 2013
-
[11]
Dadiannao: A machine-learning supercomputer
Yunji Chen, Tao Luo, Shaoli Liu, Shijin Zhang, Liqiang He, Jia Wang, Ling Li, Tianshi Chen, Zhiwei Xu, Ninghui Sun, et al. Dadiannao: A machine-learning supercomputer. In MICRO, 2014
work page 2014
-
[12]
Tetris: Scalable and efficient neural network acceleration with 3d memory
Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, and Christos Kozyrakis. Tetris: Scalable and efficient neural network acceleration with 3d memory. InASPLOS, 2017
work page 2017
-
[13]
Alberto Delmas, Sayeh Sharify, Patrick Judd, and An- dreas Moshovos. Tartan: Accelerating fully-connected and convolutional layers in deep learning networks by exploiting numerical precision variability.arXiv, 2017
work page 2017
-
[14]
TABLA: A unified template-based framework for accelerating statistical machine learning
Divya Mahajan, Jongse Park, Emmanuel Amaro, Hardik Sharma, Amir Yazdanbakhsh, Joon Kim, and Hadi Esmaeilzadeh. TABLA: A unified template-based framework for accelerating statistical machine learning. In HPCA, 2016
work page 2016
-
[15]
Cambricon-x: An accelerator for sparse neural networks
Shijin Zhang, Zidong Du, Lei Zhang, Huiying Lan, Shaoli Liu, Ling Li, Qi Guo, Tianshi Chen, and Yunji Chen. Cambricon-x: An accelerator for sparse neural networks. In MICRO, 2016
work page 2016
-
[16]
Cnvlutin: ineffectual-neuron-free deep neural network computing
Jorge Albericio, Patrick Judd, Tayler Hetherington, Tor Aamodt, Natalie Enright Jerger, and Andreas Moshovos. Cnvlutin: ineffectual-neuron-free deep neural network computing. In ISCA, 2016
work page 2016
-
[17]
Stripes: Bit- serial deep neural network computing
Patrick Judd, Jorge Albericio, Tayler Hetherington, Tor M Aamodt, and Andreas Moshovos. Stripes: Bit- serial deep neural network computing. InMICRO, 2016
work page 2016
-
[18]
From high-level deep neural models to fpgas
Hardik Sharma, Jongse Park, Divya Mahajan, Em- manuel Amaro, Joon Kim, Chenkai Shao, Asit Misra, and Hadi Esmaeilzadeh. From high-level deep neural models to fpgas. In MICRO, 2016
work page 2016
-
[19]
Accelerating persistent neural networks at datacenter scale
Eric Chung, Jeremy Fowers, Kalin Ovtcharov, Michael Papamichael, Adrian Caulfield, Todd Massengil, Ming Liu, Daniel Lo, Shlomi Alkalay, Michael Haselman, Christian Boehn, Oren Firestein, Alessandro Forin, Kang Su Gatlin, Mahdi Ghandi, Stephen Heil, Kyle Holohan, Tamas Juhasz, Ratna Kumar Kovvuri, Sitaram Lanka, Friedel van Megen, Dima Mukhortov, Prerak Pat...
work page 2017
-
[20]
SCNN: An Accelerator for Compressed-sparse Convolutional Neural Networks
Angshuman Parashar, Minsoo Rhu, Anurag Mukkara, Antonio Puglielli, Rangharajan Venkatesan, Brucek Khailany, Joel Emer, Stephen W Keckler, and William J Dally. SCNN: An Accelerator for Compressed-sparse Convolutional Neural Networks. InISCA, 2017
work page 2017
-
[21]
Yodann: An ultra-low power convolutional neural network accelerator based on binary weights
Renzo Andri, Lukas Cavigelli, Davide Rossi, and Luca Benini. Yodann: An ultra-low power convolutional neural network accelerator based on binary weights. arXiv, 2016
work page 2016
-
[22]
Eie: efficient inference engine on compressed deep neural 12 network
Song Han, Xingyu Liu, Huizi Mao, Jing Pu, Ardavan Pedram, Mark A Horowitz, and William J Dally. Eie: efficient inference engine on compressed deep neural 12 network. In ISCA, 2016
work page 2016
-
[23]
Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks
Yu-Hsin Chen, Joel Emer, and Vivienne Sze. Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks. InISCA, 2016
work page 2016
-
[24]
Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks
Yu-Hsin Chen, Tushar Krishna, Joel S Emer, and Vivi- enne Sze. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. JSSC, 2017
work page 2017
-
[25]
Neurocube: A programmable digital neuromorphic architecture with high-density 3d memory
Duckhwan Kim, Jaeha Kung, Sek Chai, Sudhakar Yalamanchili, and Saibal Mukhopadhyay. Neurocube: A programmable digital neuromorphic architecture with high-density 3d memory. In Computer Architecture (ISCA), 2016 ACM/IEEE 43rd Annual International Symposium on, pages 380–392. IEEE, 2016
work page 2016
-
[26]
In- datacenter performance analysis of a tensor processing unit
Norman P Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, et al. In- datacenter performance analysis of a tensor processing unit. In ISCA, 2017
work page 2017
-
[27]
Diannao: a small-footprint high-throughput accelerator for ubiquitous machine-learning
Tianshi Chen, Zidong Du, Ninghui Sun, Jia Wang, Chengyong Wu, Yunji Chen, and Olivier Temam. Diannao: a small-footprint high-throughput accelerator for ubiquitous machine-learning. In ASPLOS, 2014
work page 2014
-
[28]
Bit fusion: Bit-level dynamically compos- able architecture for accelerating deep neural networks
Hardik Sharma, Jongse Park, Naveen Suda, Liangzhen Lai, Benson Chau, Vikas Chandra, and Hadi Es- maeilzadeh. Bit fusion: Bit-level dynamically compos- able architecture for accelerating deep neural networks
-
[29]
Vahide Aklaghi, Amir Yazdanbakhsh, Kambiz Samadi, Hadi Esmaeilzadeh, and Rajesh K. Gupta. Snapea: Predictive early activation for reducing computation in deep convolutional neural networks. InISCA, 2018
work page 2018
-
[30]
UCNN: Exploiting Computational Reuse in Deep Neural Networks via Weight Repetition
Kartik Hegde, Jiyong Yu, Rohit Agrawal, Mengjia Yan, Michael Pellauer, and Christopher W Fletcher. Ucnn: Exploiting computational reuse in deep neural networks via weight repetition. arXiv preprint arXiv:1804.06508, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Jinmook Lee, Changhyeon Kim, Sanghoon Kang, Dongjoo Shin, Sangyeob Kim, and Hoi-Jun Yoo. Unpu: A 50.6 tops/w unified deep neural network accelerator with 1b-to-16b fully-variable weight bit-precision. In ISSCC, 2018
work page 2018
-
[32]
Isaac: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars
Ali Shafiee, Anirban Nag, Naveen Muralimanohar, Rajeev Balasubramonian, John Paul Strachan, Miao Hu, R Stanley Williams, and Vivek Srikumar. Isaac: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars. InISCA, 2016
work page 2016
-
[33]
Prakalp Srivastava, Mingu Kang, Sujan K Gonu- gondla, Sungmin Lim, Jungwook Choi, Vikram Adve, Nam Sung Kim, and Naresh Shanbhag. Promise: An end-to-end design of a programmable mixed-signal accelerator for machine-learning algorithms. In 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2018
work page 2018
-
[34]
Switched-capacitor neu- ral networks
YP Tsividis and D Anastassiou. Switched-capacitor neu- ral networks. Electronics Letters, 23(18):958–959, 1987
work page 1987
-
[35]
Redeye: analog convnet image sensor architecture for continuous mobile vision
Robert LiKamWa, Yunhui Hou, Julian Gao, Mia Polansky, and Lin Zhong. Redeye: analog convnet image sensor architecture for continuous mobile vision. In ACM SIGARCH Computer Architecture News , volume 44, pages 255–266. IEEE Press, 2016
work page 2016
-
[36]
Passive charge redistribution digital-to-analogue multiplier
Daniel Bankman and Boris Murmann. Passive charge redistribution digital-to-analogue multiplier. Electronics Letters, 51(5):386–388, 2015
work page 2015
-
[37]
E. H. Lee and S. S. Wong. Analysis and design of a passive switched-capacitor matrix multiplier for approximate computing. IEEE Journal of Solid-State Circuits, 52(1):261–271, Jan 2017. ISSN 0018-9200. doi: 10.1109/JSSC.2016.2599536
-
[38]
Daniel Bankman, Lita Yang, Bert Moons, Marian Verhelst, and Boris Murmann. An always-on 3.8µj/86% cifar-10 mixed-signal binary cnn processor with all memory on chip in 28nm cmos. InSolid-State Circuits Conference-(ISSCC), 2018 IEEE International, pages 222–224. IEEE, 2018
work page 2018
-
[39]
Fred N Buhler, Peter Brown, Jiabo Li, Thomas Chen, Zhengya Zhang, and Michael P Flynn. A 3.43 tops/w 48.9 pj/pixel 50.1 nj/classification 512 analog neuron sparse coding neural network with on-chip learning and classification in 40nm cmos. In VLSI Circuits, 2017 Symposium on, pages C30–C31. IEEE, 2017
work page 2017
-
[40]
Renée St. Amant, Amir Yazdanbakhsh, Jongse Park, Bradley Thwaites, Hadi Esmaeilzadeh, Arjang Hassibi, Luis Ceze, and Doug Burger. General-purpose code acceleration with limited-precision analog computation. In ISCA, 2014
work page 2014
-
[41]
Jintao Zhang, Zhuo Wang, and Naveen Verma. 18.4 a matrix-multiplying adc implementing a machine- learning classifier directly with data conversion. In Solid-State Circuits Conference-(ISSCC), 2015 IEEE International, pages 1–3. IEEE, 2015
work page 2015
-
[42]
Analysis and Design of a Passive Switched-Capacitor Matrix Multiplier for Approximate Computing
Edward H Lee and S Simon Wong. Analysis and Design of a Passive Switched-Capacitor Matrix Multiplier for Approximate Computing. IEEE Journal of Solid-State Circuits, 52(1):261–271, 2017
work page 2017
-
[43]
Analysis and design of analog integrated circuits
Paul R Gray, Paul Hurst, Robert G Meyer, and Stephen Lewis. Analysis and design of analog integrated circuits. Wiley, 2001
work page 2001
-
[44]
Ping Chi, Shuangchen Li, Cong Xu, Tao Zhang, Jishen Zhao, Yongpan Liu, Yu Wang, and Yuan Xie. Prime: A novel processing-in-memory architecture for neural network computation in reram-based main memory. In ISCA, 2016
work page 2016
-
[45]
Loom: Exploiting weight and activation precisions to accelerate convolutional neural networks
Sayeh Sharify, Alberto Delmas Lascorz, Patrick Judd, and Andreas Moshovos. Loom: Exploiting weight and activation precisions to accelerate convolutional neural networks. arXiv, 2017
work page 2017
-
[46]
Tetris: Scalable and efficient neural network acceleration with 3d memory
Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, and Christos Kozyrakis. Tetris: Scalable and efficient neural network acceleration with 3d memory. https: //github.com/stanford-mast/nn_dataflow, 2017
work page 2017
-
[47]
Yuanfang Li and Ardavan Pedram. Caterpillar: Coarse grain reconfigurable architecture for accelerating the training of deep neural networks. InApplication-specific Systems, Architectures and Processors (ASAP), 2017 IEEE 28th International Conference on , pages 1–10. IEEE, 2017
work page 2017
-
[48]
A high speed and low power 8 bit x 8 bit multiplier design using novel two transistor (2t) xor gates
Himani Upadhyay and Shubhajit Roy Chowdhury. A high speed and low power 8 bit x 8 bit multiplier design using novel two transistor (2t) xor gates. Journal of Low Power Electronics , 01 2015. doi: 13 10.1166/jolpe.2015.1362
-
[49]
Hybrid memory cube specification 1.0.Last Revision Jan, 2013
Hybrid Memory Cube Consortium et al. Hybrid memory cube specification 1.0.Last Revision Jan, 2013
work page 2013
-
[50]
Hybrid memory cube new dram architecture increases density and performance
Joe Jeddeloh and Brent Keeth. Hybrid memory cube new dram architecture increases density and performance. In VLSI Technology (VLSIT), 2012 Symposium on, pages 87–88. IEEE, 2012
work page 2012
-
[51]
Wolfe, Kambiz Samadi, Hadi Esmaeilzadeh, and Nam Sung Kim
Amir Yazdanbakhsh, Hajar Falahati, Philip J. Wolfe, Kambiz Samadi, Hadi Esmaeilzadeh, and Nam Sung Kim. GANAX: A Unified SIMD-MIMD Acceleration for Generative Adversarial Network. InISCA, 2018
work page 2018
-
[52]
Mohammed Ismail and Terri Fiez.Analog VLSI: signal and information processing, volume 166. McGraw-Hill New York, 1994
work page 1994
-
[53]
Vaibhav Tripathi and Boris Murmann. Mismatch characterization of small metal fringe capacitors.IEEE Transactions on Circuits and Systems I: Regular Papers, 61(8):2236–2242, 2014
work page 2014
-
[54]
Thermal feasibility of die-stacked processing in memory
Yasuko Eckert, Nuwan Jayasena, and Gabriel H Loh. Thermal feasibility of die-stacked processing in memory. 2014
work page 2014
-
[55]
Facebook AI Research. Caffe2. https://caffe2.ai/
-
[56]
One weird trick for parallelizing convolutional neural networks
Alex Krizhevsky. One weird trick for parallelizing convolutional neural networks. arXiv, 2014
work page 2014
-
[57]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009. URL http://image-net.org/
work page 2009
-
[58]
Very deep con- volutional networks for large-scale image recognition
Karen Simonyan and Andrew Zisserman. Very deep con- volutional networks for large-scale image recognition. arXiv, 2014
work page 2014
-
[59]
Quantized neural networks: Training neural networks with low precision weights and activations
Itay Hubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Quantized neural networks: Training neural networks with low precision weights and activations. arXiv, 2016
work page 2016
-
[60]
Learning multi- ple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multi- ple layers of features from tiny images. Computer Sci- ence Department, University of Toronto, Tech. Rep, 2009
work page 2009
-
[61]
Going deeper with convolutions
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2015
work page 2015
-
[62]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016
work page 2016
-
[63]
YOLOv3: An Incremental Improvement
Joseph Redmon and Ali Farhadi. Yolov3: An incre- mental improvement. arXiv preprint arXiv:1804.02767, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[64]
Building a large annotated corpus of english: The penn treebank
Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beatrice Santorini. Building a large annotated corpus of english: The penn treebank. Computational linguistics, 1993
work page 1993
-
[65]
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 1997
work page 1997
-
[66]
Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients
Shuchang Zhou, Zekun Ni, Xinyu Zhou, He Wen, Yuxin Wu, and Yuheng Zou. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv, 2016
work page 2016
-
[67]
Mishra, Eriko Nurvitadhi, Jeffrey J
Asit K. Mishra, Eriko Nurvitadhi, Jeffrey J. Cook, and Debbie Marr. WRPN: wide reduced-precision networks. arXiv, 2017
work page 2017
-
[68]
Fengfu Li, Bo Zhang, and Bin Liu. Ternary weight networks. arXiv, 2016
work page 2016
-
[69]
LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks
Dongqing Zhang, Jiaolong Yang, Dongqiangzi Ye, and Gang Hua. Lq-nets: Learned quantization for highly accurate and compact deep neural networks. arXiv preprint arXiv:1807.10029, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[70]
https://developer.nvidia.com/ tensorrt
Nvidia tensor rt 5.1. https://developer.nvidia.com/ tensorrt
-
[71]
Pipelayer: A pipelined reram-based accelerator for deep learning
Linghao Song, Xuehai Qian, Hai Li, and Yiran Chen. Pipelayer: A pipelined reram-based accelerator for deep learning. In High Performance Computer Architecture (HPCA), 2017 IEEE International Symposium on, pages 541–552. IEEE, 2017
work page 2017
- [72]
-
[73]
B. Murmann. ADC Performance Survey 1997-2016 . murmann/adcsurvey.html, [Online]. Available. URL http://web.stanford.edu/
work page 1997
-
[74]
A 0.0013 mm2 10b 10ms/s sar adc with a 0.0048 mm2 42db-rejection passive fir filter
Pieter Harpe. A 0.0013 mm2 10b 10ms/s sar adc with a 0.0048 mm2 42db-rejection passive fir filter. In2018 IEEE Custom Integrated Circuits Conference, CICC
-
[75]
Institute of Electrical and Electronics Engineers Inc., 2018
work page 2018
-
[76]
S. Li, K. Chen, J. H. Ahn, J. B. Brockman, and N. P. Jouppi. CACTI-P: Architecture-level Modeling for SRAM-based Structures with Advanced Leakage Reduction Techniques. In ICCAD, 2011
work page 2011
-
[77]
Automatic differentiation in pytorch
Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. InNIPS-W, 2017
work page 2017
-
[78]
Neural network distiller, June 2018
Neta Zmora, Guy Jacob, and Gal Novik. Neural network distiller, June 2018. URL https://doi.org/10.5281/zenodo.1297430
-
[79]
Reram-based processing-in-memory architecture for recurrent neural network acceleration
Yun Long, Taesik Na, and Saibal Mukhopadhyay. Reram-based processing-in-memory architecture for recurrent neural network acceleration. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, (99):1–14, 2018
work page 2018
-
[80]
Jan Crols and Michel Steyaert. Switched-opamp: An approach to realize full cmos switched-capacitor circuits at very low power supply voltages. IEEE Journal of Solid-State Circuits, 29(8):936–942, 1994
work page 1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.