Statistical Inference for Misspecified Contextual Bandits
Pith reviewed 2026-06-26 09:29 UTC · model grok-4.3
The pith
Scaled inverse-propensity convergence ensures consistent and asymptotically normal inference for misspecified contextual bandits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the scaled inverse-propensity convergence condition, the IPW-Z estimator for a broad class of marginal moment targets is consistent and asymptotically normal with a consistent sandwich variance estimator, even without a well-specified outcome model.
What carries the argument
The IPW-Z estimator, which applies inverse probability weighting to Z-estimating equations, stabilized by the scaled inverse-propensity convergence condition.
If this is right
- The IPW-Z estimator applies to projection parameters, structural parameters with noisy contexts, and off-policy values.
- Sufficient conditions establish scaled inverse-propensity convergence for multi-armed bandit algorithms and smooth contextual allocation policies.
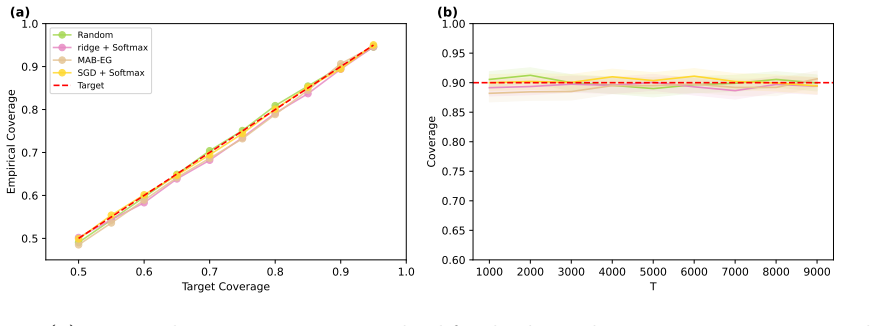
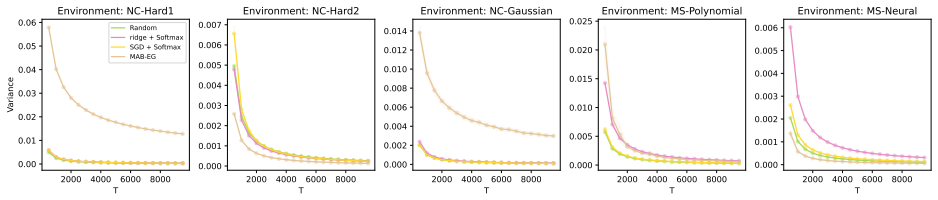
- Simulations and real-data application demonstrate reliable coverage and competitive performance.
- Misspecification can cause non-Gaussian behavior in standard algorithms without the stability condition.
Where Pith is reading between the lines
- Designers of adaptive experiments may need to verify or enforce the convergence condition to support later inference.
- The framework could apply to other adaptive designs if analogous stability conditions can be checked.
- Misspecification effects suggest prioritizing stability alongside reward in online policy selection.
Load-bearing premise
The scaled inverse-propensity convergence condition holds for the policy classes under consideration.
What would settle it
An example where scaled inverse-propensity convergence holds yet the IPW-Z estimator fails to be asymptotically normal or lacks consistent sandwich variance would falsify the central claim.
Figures
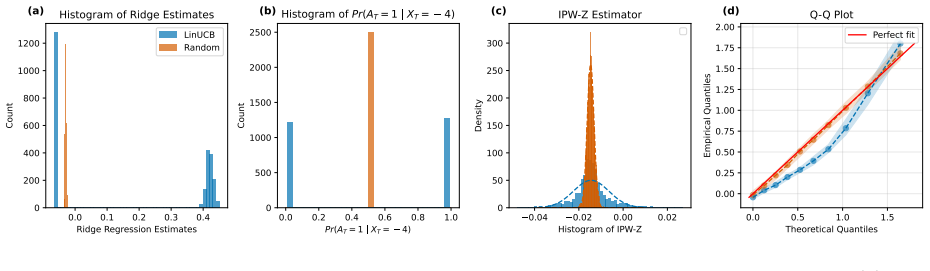
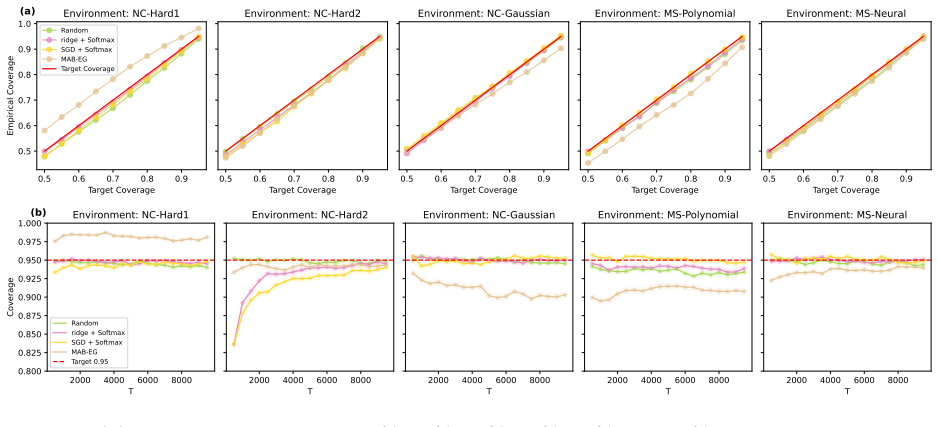
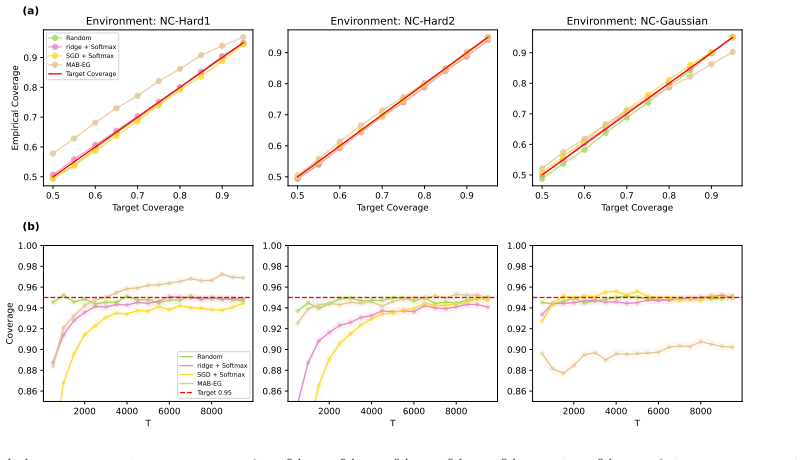
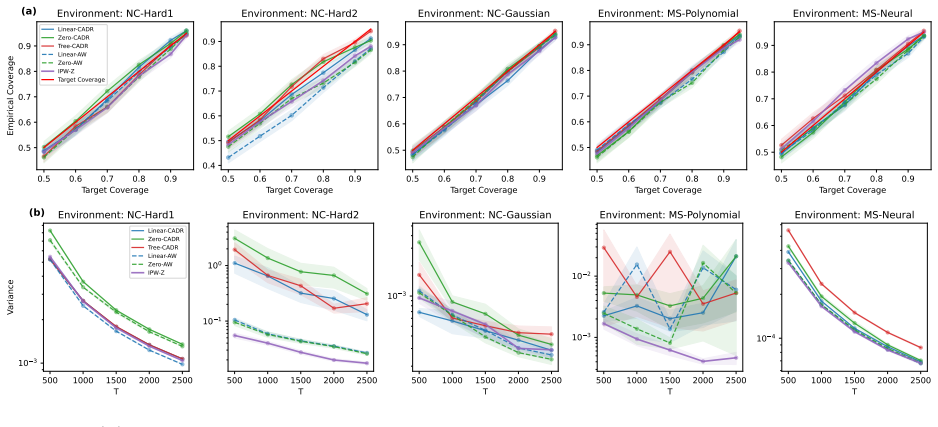
read the original abstract
Contextual bandit algorithms have transformed modern experimentation by enabling real-time adaptation for personalized treatment. Yet these advantages create challenges for statistical inference due to adaptivity. We study inference with contextual-bandit data without assuming a well-specified outcome model. In this setting, we show a previously overlooked issue: standard algorithms such as LinUCB may fail to stabilize under misspecified working models, leading to non-Gaussian estimator behavior and invalid inference. This issue is practically important, as misspecified working models -- such as approximations of complex dynamical systems -- are often employed by online agents in real-world adaptive experiments to balance reward, computational tractability, and robustness. We develop an inverse-probability-weighted Z-estimation framework for a broad class of marginal moment targets, including projection parameters, structural parameters with noisy contexts, and off-policy values. We identify a stability condition tailored to this framework, scaled inverse-propensity convergence, under which the IPW-Z estimator is consistent and asymptotically normal with a consistent sandwich variance estimator. We further establish sufficient conditions for scaled inverse-propensity convergence for several policy classes, including multi-armed bandit algorithms and smooth contextual allocation policies. Simulations and a HeartSteps V1 real-data-calibrated application show reliable coverage and competitive performance across multiple targets. Overall, our results highlight the importance of stability-aware adaptive design for valid post-experiment inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an inverse-probability-weighted Z-estimation (IPW-Z) framework for inference on marginal moment targets (including projections, structural parameters, and off-policy values) in contextual bandits under outcome model misspecification. It introduces a stability condition called scaled inverse-propensity convergence, under which the IPW-Z estimator is consistent, asymptotically normal, and admits a consistent sandwich variance estimator. Sufficient conditions for this stability are derived for multi-armed bandit algorithms and smooth contextual allocation policies. Simulations and a HeartSteps V1 real-data application are used to illustrate reliable coverage.
Significance. If the central results hold, the work provides a practical route to valid post-experiment inference in adaptive designs without requiring a correctly specified outcome model, which is common in real-world applications. The derivation of sufficient conditions for standard policy classes (multi-armed bandits and smooth contextual policies) and the emphasis on stability-aware design are concrete strengths that could influence both theory and experimental practice.
major comments (1)
- [Abstract / main theoretical section] The central claim rests on the scaled inverse-propensity convergence condition being sufficient for consistency, asymptotic normality, and sandwich variance consistency of the IPW-Z estimator. While the abstract states that sufficient conditions are established for the policy classes considered, the manuscript should explicitly verify (via the paper's own equations) that these conditions are not circular with the estimator definition itself and that they are checkable from observable quantities.
minor comments (2)
- [Introduction] Clarify the precise definition of the IPW-Z estimator and the marginal moment targets at the first use in the introduction, as these are central to the framework.
- [Simulations] The simulations section should report the exact policy classes, misspecification levels, and sample sizes used, to allow readers to assess how well the sufficient conditions are tested.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the constructive comment on clarifying the scaled inverse-propensity convergence condition. We address the point below and will incorporate the requested verification in the revision.
read point-by-point responses
-
Referee: [Abstract / main theoretical section] The central claim rests on the scaled inverse-propensity convergence condition being sufficient for consistency, asymptotic normality, and sandwich variance consistency of the IPW-Z estimator. While the abstract states that sufficient conditions are established for the policy classes considered, the manuscript should explicitly verify (via the paper's own equations) that these conditions are not circular with the estimator definition itself and that they are checkable from observable quantities.
Authors: We agree that an explicit verification strengthens the presentation. The scaled inverse-propensity convergence condition (Definition 3.1) is formulated exclusively in terms of the policy-generated propensity sequence {π_t(a|x)} and the target moment function m(θ; x, a, y), with no dependence on the outcome model or the IPW-Z estimating equation itself; hence it is non-circular by construction. In the revision we will add a short paragraph immediately after Definition 3.1 that quotes the relevant equations and states this independence explicitly. Regarding checkability, the sufficient conditions in Theorems 4.1 (multi-armed bandits) and 4.2 (smooth contextual policies) are expressed in terms of observable or design quantities: the minimum per-arm allocation probability (verifiable from the realized counts N_t(a)) and the policy Lipschitz constant (a known design parameter). We will insert a new Remark 4.3 that lists these quantities and notes how they can be inspected from the experimental log without reference to the outcome data. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces the scaled inverse-propensity convergence condition as an external stability requirement and separately derives sufficient conditions for it under multi-armed bandit and smooth contextual policies. These steps rely on standard asymptotic arguments for inverse-probability weighting and Z-estimation rather than any self-definition, fitted-parameter renaming, or load-bearing self-citation chain. The consistency, asymptotic normality, and sandwich variance results are direct consequences of the stated condition plus the derived sufficient conditions, with no reduction of outputs to inputs by construction visible in the provided material.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Outcome model may be misspecified
- domain assumption Scaled inverse-propensity convergence holds for the policies
Reference graph
Works this paper leans on
-
[1]
Inbal Nahum-Shani, Shawna N Smith, Bonnie J Spring, Linda M Collins, Katie Witkiewitz, Ambuj Tewari, and Susan A Murphy. Just-in-time adaptive interventions (jitais) in mobile health: key components and design principles for ongoing health behavior support.Annals of behavioral medicine, pages 1–17, 2016
2016
-
[2]
A systematic review of just-in-time adaptive interventions (jitais) to promote physical activity
Wendy Hardeman, Julie Houghton, Kathleen Lane, Andy Jones, and Felix Naughton. A systematic review of just-in-time adaptive interventions (jitais) to promote physical activity. International Journal of Behavioral Nutrition and Physical Activity, 16(1):31, 2019
2019
-
[3]
A contextual-bandit approach to personalized news article recommendation
Lihong Li, Wei Chu, John Langford, and Robert E Schapire. A contextual-bandit approach to personalized news article recommendation. InProceedings of the 19th international conference on World wide web, pages 661–670, 2010
2010
-
[4]
Automatic ad format selec- tion via contextual bandits
Liang Tang, Romer Rosales, Ajit Singh, and Deepak Agarwal. Automatic ad format selec- tion via contextual bandits. InProceedings of the 22nd ACM international conference on Information & Knowledge Management, pages 1587–1594, 2013
2013
-
[5]
Scaling up behavioral science interventions in online education.Proceedings of the National Academy of Sciences, 117(26): 14900–14905, 2020
Ren´ e F Kizilcec, Justin Reich, Michael Yeomans, Christoph Dann, Emma Brunskill, Glenn Lopez, Selen Turkay, Joseph Jay Williams, and Dustin Tingley. Scaling up behavioral science interventions in online education.Proceedings of the National Academy of Sciences, 117(26): 14900–14905, 2020
2020
-
[6]
Mining big data in education: Affordances and challenges.Review of research in education, 44(1):130–160, 2020
Christian Fischer, Zachary A Pardos, Ryan Shaun Baker, Joseph Jay Williams, Padhraic Smyth, Renzhe Yu, Stefan Slater, Rachel Baker, and Mark Warschauer. Mining big data in education: Affordances and challenges.Review of research in education, 44(1):130–160, 2020
2020
-
[7]
Adaptive experimental design: Prospects and applications in political science.American Journal of Political Science, 65(4): 826–844, 2021
Molly Offer-Westort, Alexander Coppock, and Donald P Green. Adaptive experimental design: Prospects and applications in political science.American Journal of Political Science, 65(4): 826–844, 2021
2021
-
[8]
A mobile health intervention for emerging adults with regular cannabis use: A micro-randomized pilot trial design protocol.Contemporary Clinical Trials, 145:107667, 2024
Lara N Coughlin, Maya Campbell, Tiffany Wheeler, Chavez Rodriguez, Autumn Rae Florim- bio, Susobhan Ghosh, Yongyi Guo, Pei-Yao Hung, Mark W Newman, Huijie Pan, et al. A mobile health intervention for emerging adults with regular cannabis use: A micro-randomized pilot trial design protocol.Contemporary Clinical Trials, 145:107667, 2024
2024
-
[9]
The impact of using reinforcement learning to personalize communication 75 on medication adherence: findings from the reinforce trial.npj Digital Medicine, 7(1):39, 2024
Julie C Lauffenburger, Elad Yom-Tov, Punam A Keller, Marie E McDonnell, Katherine L Crum, Gauri Bhatkhande, Ellen S Sears, Kaitlin Hanken, Lily G Bessette, Constance P Fontanet, et al. The impact of using reinforcement learning to personalize communication 75 on medication adherence: findings from the reinforce trial.npj Digital Medicine, 7(1):39, 2024
2024
-
[10]
Optimizing an adaptive digital oral health intervention for promoting oral self-care behaviors: Micro-randomized trial protocol.Contemporary clinical trials, 139:107464, 2024
Inbal Nahum-Shani, Zara M Greer, Anna L Trella, Kelly W Zhang, Stephanie M Carpenter, Dennis Ruenger, David Elashoff, Susan A Murphy, and Vivek Shetty. Optimizing an adaptive digital oral health intervention for promoting oral self-care behaviors: Micro-randomized trial protocol.Contemporary clinical trials, 139:107464, 2024
2024
-
[11]
Learning to optimize via posterior sampling.Mathe- matics of Operations Research, 39(4):1221–1243, 2014
Daniel Russo and Benjamin Van Roy. Learning to optimize via posterior sampling.Mathe- matics of Operations Research, 39(4):1221–1243, 2014
2014
-
[12]
Estimation consid- erations in contextual bandits.arXiv preprint arXiv:1711.07077, 2017
Maria Dimakopoulou, Zhengyuan Zhou, Susan Athey, and Guido Imbens. Estimation consid- erations in contextual bandits.arXiv preprint arXiv:1711.07077, 2017
Pith/arXiv arXiv 2017
-
[13]
A deployed online reinforcement learning algorithm in an oral health clinical trial
Anna L Trella, Kelly W Zhang, Hinal Jajal, Inbal Nahum-Shani, Vivek Shetty, Finale Doshi- Velez, and Susan A Murphy. A deployed online reinforcement learning algorithm in an oral health clinical trial. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 39, pages 28792–28800, 2025
2025
-
[14]
Susan Athey, Undral Byambadalai, Vitor Hadad, Sanath Kumar Krishnamurthy, Weiwen Le- ung, and Joseph Jay Williams. Contextual bandits in a survey experiment on charitable giving: Within-experiment outcomes versus policy learning.arXiv preprint arXiv:2211.12004, 2022
arXiv 2022
-
[15]
From ads to interventions: Contextual bandits in mobile health
Ambuj Tewari and Susan A Murphy. From ads to interventions: Contextual bandits in mobile health. InMobile health: sensors, analytic methods, and applications, pages 495–517. Springer, 2017
2017
-
[16]
Misspecified linear bandits
Avishek Ghosh, Sayak Ray Chowdhury, and Aditya Gopalan. Misspecified linear bandits. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 31, 2017
2017
-
[17]
Adapting to mis- specification in contextual bandits.Advances in Neural Information Processing Systems, 33: 11478–11489, 2020
Dylan J Foster, Claudio Gentile, Mehryar Mohri, and Julian Zimmert. Adapting to mis- specification in contextual bandits.Advances in Neural Information Processing Systems, 33: 11478–11489, 2020
2020
-
[18]
Learning with good feature representa- tions in bandits and in rl with a generative model
Tor Lattimore, Csaba Szepesvari, and Gellert Weisz. Learning with good feature representa- tions in bandits and in rl with a generative model. InInternational conference on machine learning, pages 5662–5670. PMLR, 2020
2020
-
[19]
Tractable contextual bandits beyond realizability
Sanath Kumar Krishnamurthy, Vitor Hadad, and Susan Athey. Tractable contextual bandits beyond realizability. InInternational Conference on Artificial Intelligence and Statistics, pages 1423–1431. PMLR, 2021
2021
-
[20]
Adapting to misspecification in contextual bandits with offline regression oracles
Sanath Kumar Krishnamurthy, Vitor Hadad, and Susan Athey. Adapting to misspecification in contextual bandits with offline regression oracles. InInternational Conference on Machine Learning, pages 5805–5814. PMLR, 2021
2021
-
[21]
Accurate inference for adaptive linear models
Yash Deshpande, Lester Mackey, Vasilis Syrgkanis, and Matt Taddy. Accurate inference for adaptive linear models. InInternational Conference on Machine Learning, pages 1194–1203. PMLR, 2018. 76
2018
-
[22]
Assessing time- varying causal effect moderation in mobile health.Journal of the American Statistical Asso- ciation, 113(523):1112–1121, 2018
Audrey Boruvka, Daniel Almirall, Katie Witkiewitz, and Susan A Murphy. Assessing time- varying causal effect moderation in mobile health.Journal of the American Statistical Asso- ciation, 113(523):1112–1121, 2018
2018
-
[23]
Estimat- ing time-varying causal excursion effects in mobile health with binary outcomes.Biometrika, 108(3):507–527, 2021
Tianchen Qian, Hyesun Yoo, Predrag Klasnja, Daniel Almirall, and Susan A Murphy. Estimat- ing time-varying causal excursion effects in mobile health with binary outcomes.Biometrika, 108(3):507–527, 2021
2021
-
[24]
Semi-parametric inference based on adaptively collected data.arXiv preprint arXiv:2303.02534, 2023
Licong Lin, Koulik Khamaru, and Martin J Wainwright. Semi-parametric inference based on adaptively collected data.arXiv preprint arXiv:2303.02534, 2023
arXiv 2023
-
[25]
Post-episodic reinforcement learning inference.arXiv e-prints, pages arXiv–2302, 2023
Vasilis Syrgkanis and Ruohan Zhan. Post-episodic reinforcement learning inference.arXiv e-prints, pages arXiv–2302, 2023
2023
-
[26]
On conditional least squares estimation for stochastic processes.The Annals of statistics, pages 629–642, 1978
Lawrence A Klimko and Paul I Nelson. On conditional least squares estimation for stochastic processes.The Annals of statistics, pages 629–642, 1978
1978
-
[27]
Asymptotic properties of nonlinear least squares estimates in stochastic re- gression models.The Annals of Statistics, pages 1917–1930, 1994
Tze Leung Lai. Asymptotic properties of nonlinear least squares estimates in stochastic re- gression models.The Annals of Statistics, pages 1917–1930, 1994
1917
-
[28]
Statistical inference with m-estimators on adaptively collected data.Advances in neural information processing systems, 34:7460–7471, 2021
Kelly Zhang, Lucas Janson, and Susan Murphy. Statistical inference with m-estimators on adaptively collected data.Advances in neural information processing systems, 34:7460–7471, 2021
2021
-
[29]
Statistical inference for online decision making: In a contextual bandit setting.Journal of the American Statistical Association, 116(533):240–255, 2021
Haoyu Chen, Wenbin Lu, and Rui Song. Statistical inference for online decision making: In a contextual bandit setting.Journal of the American Statistical Association, 116(533):240–255, 2021
2021
-
[30]
Off-policy evaluation via adaptive weighting with data from contextual bandits
Ruohan Zhan, Vitor Hadad, David A Hirshberg, and Susan Athey. Off-policy evaluation via adaptive weighting with data from contextual bandits. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 2125–2135, 2021
2021
-
[31]
Post-contextual-bandit inference.Advances in neural information processing sys- tems, 34:28548–28559, 2021
Aur´ elien Bibaut, Maria Dimakopoulou, Nathan Kallus, Antoine Chambaz, and Mark van Der Laan. Post-contextual-bandit inference.Advances in neural information processing sys- tems, 34:28548–28559, 2021
2021
-
[32]
Kelly W Zhang, Lucas Janson, and Susan A Murphy. Statistical inference after adaptive sampling for longitudinal data.arXiv preprint arXiv:2202.07098, 2022
arXiv 2022
-
[33]
Replicable bandits for digital health interventions.arXiv preprint arXiv:2407.15377, 2024
Kelly W Zhang, Nowell Closser, Anna L Trella, and Susan A Murphy. Replicable bandits for digital health interventions.arXiv preprint arXiv:2407.15377, 2024
arXiv 2024
-
[34]
Inference with the upper confidence bound algorithm
Koulik Khamaru and Cun-Hui Zhang. Inference with the upper confidence bound algorithm. arXiv preprint arXiv:2408.04595, 2024
arXiv 2024
-
[35]
Budhaditya Halder, Shubhayan Pan, and Koulik Khamaru. Stable thompson sampling: Valid inference via variance inflation.arXiv preprint arXiv:2505.23260, 2025. 77
arXiv 2025
-
[36]
Why adaptively collected data have negative bias and how to correct for it
Xinkun Nie, Xiaoying Tian, Jonathan Taylor, and James Zou. Why adaptively collected data have negative bias and how to correct for it. InInternational Conference on Artificial Intelligence and Statistics, pages 1261–1269. PMLR, 2018
2018
-
[37]
Inference for batched bandits.Advances in neural information processing systems, 33:9818–9829, 2020
Kelly Zhang, Lucas Janson, and Susan Murphy. Inference for batched bandits.Advances in neural information processing systems, 33:9818–9829, 2020
2020
-
[38]
Strong consistency of least squares estimates in dynamic models.The annals of Statistics, 7(3):484–489, 1979
TW Anderson and John B Taylor. Strong consistency of least squares estimates in dynamic models.The annals of Statistics, 7(3):484–489, 1979
1979
-
[39]
Strong consistency of least squares estimators in linear regression models.The Annals of Statistics, 8(4):778–788, 1980
Norbert Christopeit and Kurt Helmes. Strong consistency of least squares estimators in linear regression models.The Annals of Statistics, 8(4):778–788, 1980
1980
-
[40]
Least squares estimates in stochastic regression models with applications to identification and control of dynamic systems.The Annals of Statistics, pages 154–166, 1982
Tze Leung Lai and Ching Zong Wei. Least squares estimates in stochastic regression models with applications to identification and control of dynamic systems.The Annals of Statistics, pages 154–166, 1982
1982
-
[41]
Strong consistency of maximum quasi-likelihood esti- mators in generalized linear models with fixed and adaptive designs.The Annals of Statistics, 27(4):1155–1163, 1999
Kani Chen, Inchi Hu, and Zhiliang Ying. Strong consistency of maximum quasi-likelihood esti- mators in generalized linear models with fixed and adaptive designs.The Annals of Statistics, 27(4):1155–1163, 1999
1999
-
[42]
Near-optimal inference in adaptive linear regression.arXiv preprint arXiv:2107.02266, 2021
Koulik Khamaru, Yash Deshpande, Tor Lattimore, Lester Mackey, and Martin J Wainwright. Near-optimal inference in adaptive linear regression.arXiv preprint arXiv:2107.02266, 2021
arXiv 2021
-
[43]
Statistical inference for online decision making via stochastic gradient descent.Journal of the American Statistical Association, 116(534):708–719, 2021
Haoyu Chen, Wenbin Lu, and Rui Song. Statistical inference for online decision making via stochastic gradient descent.Journal of the American Statistical Association, 116(534):708–719, 2021
2021
-
[44]
Qiyang Han, Koulik Khamaru, and Cun-Hui Zhang. Ucb algorithms for multi-armed bandits: Precise regret and adaptive inference.arXiv preprint arXiv:2412.06126, 2024. URLhttps: //arxiv.org/abs/2412.06126
arXiv 2024
-
[45]
Confidence intervals for policy evaluation in adaptive experiments.Proceedings of the national academy of sciences, 118(15):e2014602118, 2021
Vitor Hadad, David A Hirshberg, Ruohan Zhan, Stefan Wager, and Susan Athey. Confidence intervals for policy evaluation in adaptive experiments.Proceedings of the national academy of sciences, 118(15):e2014602118, 2021
2021
-
[46]
Anytime-valid off-policy inference for contextual bandits.ACM/IMS Journal of Data Sci- ence, 1(3):1–42, 2024
Ian Waudby-Smith, Lili Wu, Aaditya Ramdas, Nikos Karampatziakis, and Paul Mineiro. Anytime-valid off-policy inference for contextual bandits.ACM/IMS Journal of Data Sci- ence, 1(3):1–42, 2024
2024
-
[47]
Off-policy estimation of long-term average outcomes with applications to mobile health.Journal of the American Statistical Association, 116(533):382–391, 2021
Peng Liao, Predrag Klasnja, and Susan Murphy. Off-policy estimation of long-term average outcomes with applications to mobile health.Journal of the American Statistical Association, 116(533):382–391, 2021
2021
-
[48]
Batch policy learning in average reward markov decision processes.Annals of statistics, 50(6):3364, 2022
Peng Liao, Zhengling Qi, Runzhe Wan, Predrag Klasnja, and Susan A Murphy. Batch policy learning in average reward markov decision processes.Annals of statistics, 50(6):3364, 2022
2022
-
[49]
Springer, 2003
Mark J Laan and James M Robins.Unified methods for censored longitudinal data and causal- ity. Springer, 2003. 78
2003
-
[50]
Springer, 2013
Bibhas Chakraborty and Erica EM Moodie.Statistical methods for dynamic treatment regimes, volume 2. Springer, 2013
2013
-
[51]
James Leiner, Robin Dunn, and Aaditya Ramdas. Adaptive off-policy inference for M- estimators under model misspecification.arXiv preprint arXiv:2509.14218, 2025. URL https://arxiv.org/abs/2509.14218
arXiv 2025
-
[52]
The ode method for convergence of stochastic approximation and reinforcement learning.SIAM Journal on Control and Optimization, 38(2):447–469, 2000
Vivek S Borkar and Sean P Meyn. The ode method for convergence of stochastic approximation and reinforcement learning.SIAM Journal on Control and Optimization, 38(2):447–469, 2000
2000
-
[53]
Donghwan Lee and Niao He. A unified switching system perspective and ode analysis of q-learning algorithms.arXiv preprint arXiv:1912.02270, 2019
arXiv 1912
-
[54]
A new convergent variant of q-learning with linear function approximation.Advances in Neural Information Processing Systems, 33: 19412–19421, 2020
Diogo Carvalho, Francisco S Melo, and Pedro Santos. A new convergent variant of q-learning with linear function approximation.Advances in Neural Information Processing Systems, 33: 19412–19421, 2020
2020
-
[55]
The ode method for stochastic approximation and reinforcement learning with markovian noise.Journal of Machine Learning Research, 26(24):1–76, 2025
Shuze Daniel Liu, Shuhang Chen, and Shangtong Zhang. The ode method for stochastic approximation and reinforcement learning with markovian noise.Journal of Machine Learning Research, 26(24):1–76, 2025
2025
-
[56]
Reinforcement learning under model mismatch
Aurko Roy, Huan Xu, and Sebastian Pokutta. Reinforcement learning under model mismatch. Advances in neural information processing systems, 30, 2017
2017
-
[57]
Cambridge university press, 2015
Guido W Imbens and Donald B Rubin.Causal inference in statistics, social, and biomedical sciences. Cambridge university press, 2015
2015
-
[58]
Using least squares to approximate unknown regression functions.Interna- tional economic review, pages 149–170, 1980
Halbert White. Using least squares to approximate unknown regression functions.Interna- tional economic review, pages 149–170, 1980
1980
-
[59]
Andreas Buja, Lawrence Brown, Richard Berk, Edward George, Emil Pitkin, Mikhail Traskin, Kai Zhang, and Linda Zhao. Models as approximations I: Consequences illustrated with linear regression.Statistical Science, 34(4):523–544, 2019. doi: 10.1214/18-STS693. URL https://doi.org/10.1214/18-STS693
-
[60]
Generic machine learning inference on heterogeneous treatment effects in randomized experiments, with an application to immunization in india
Victor Chernozhukov, Mert Demirer, Esther Duflo, and Ivan Fernandez-Val. Generic machine learning inference on heterogeneous treatment effects in randomized experiments, with an application to immunization in india. Technical report, National Bureau of Economic Research, 2018
2018
-
[61]
Online learning in bandits with predicted context
Yongyi Guo, Ziping Xu, and Susan Murphy. Online learning in bandits with predicted context. InInternational Conference on Artificial Intelligence and Statistics, pages 2215–2223. PMLR, 2024
2024
-
[62]
CRC press, 1995
Raymond J Carroll, David Ruppert, and Leonard A Stefanski.Measurement error in nonlinear models, volume 105. CRC press, 1995
1995
-
[63]
John Wiley & Sons, 2009
Wayne A Fuller.Measurement error models. John Wiley & Sons, 2009. 79
2009
-
[64]
Reinforcement learning on dyads to enhance med- ication adherence
Ziping Xu, Hinal Jajal, Sung Won Choi, Inbal Nahum-Shani, Guy Shani, Alexandra M Psiho- gios, Pei-Yao Hung, and Susan A Murphy. Reinforcement learning on dyads to enhance med- ication adherence. InInternational Conference on Artificial Intelligence in Medicine, pages 490–499. Springer, 2025
2025
-
[65]
Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms
Lihong Li, Wei Chu, John Langford, and Xuanhui Wang. Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms. InProceedings of the fourth ACM international conference on Web search and data mining, pages 297–306, 2011
2011
-
[66]
Cambridge university press, 2000
Aad W Van der Vaart.Asymptotic statistics, volume 3. Cambridge university press, 2000
2000
-
[67]
Reinforcement learning: an introduction mit press
Richard S Sutton and Andrew G Barto. Reinforcement learning: an introduction mit press. Cambridge, MA, 22447:10, 1998
1998
-
[68]
Finite-time analysis of the multiarmed bandit problem, 2002
P Auer. Finite-time analysis of the multiarmed bandit problem, 2002
2002
-
[69]
Contextual bandits with linear payoff functions
Wei Chu, Lihong Li, Lev Reyzin, and Robert Schapire. Contextual bandits with linear payoff functions. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 208–214. JMLR Workshop and Conference Proceedings, 2011
2011
-
[70]
Analysis of thompson sampling for the multi-armed bandit problem
Shipra Agrawal and Navin Goyal. Analysis of thompson sampling for the multi-armed bandit problem. InConference on learning theory, pages 39–1. JMLR Workshop and Conference Proceedings, 2012
2012
-
[71]
A tutorial on thompson sampling.Foundations and Trends®in Machine Learning, 11(1):1–96, 2018
Daniel J Russo, Benjamin Van Roy, Abbas Kazerouni, Ian Osband, Zheng Wen, et al. A tutorial on thompson sampling.Foundations and Trends®in Machine Learning, 11(1):1–96, 2018
2018
-
[72]
Peng Liao, Kristjan Greenewald, Predrag Klasnja, and Susan Murphy. Personalized heartsteps: A reinforcement learning algorithm for optimizing physical activity.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 4(1):1–22, 2020
2020
-
[73]
Improved algorithms for linear stochastic bandits.Advances in neural information processing systems, 24, 2011
Yasin Abbasi-Yadkori, D´ avid P´ al, and Csaba Szepesv´ ari. Improved algorithms for linear stochastic bandits.Advances in neural information processing systems, 24, 2011
2011
-
[74]
Thompson sampling for contextual bandits with linear payoffs
Shipra Agrawal and Navin Goyal. Thompson sampling for contextual bandits with linear payoffs. InInternational conference on machine learning, pages 127–135. PMLR, 2013
2013
-
[75]
Boltzmann exploration done right.Advances in neural information processing systems, 30, 2017
Nicol` o Cesa-Bianchi, Claudio Gentile, G´ abor Lugosi, and Gergely Neu. Boltzmann exploration done right.Advances in neural information processing systems, 30, 2017
2017
-
[76]
Power constrained bandits
Jiayu Yao, Emma Brunskill, Weiwei Pan, Susan Murphy, and Finale Doshi-Velez. Power constrained bandits. InMachine Learning for Healthcare Conference, pages 209–259. PMLR, 2021
2021
-
[77]
Targeting for long-term outcomes.Management Science, 70(6):3841–3855, 2024
Jeremy Yang, Dean Eckles, Paramveer Dhillon, and Sinan Aral. Targeting for long-term outcomes.Management Science, 70(6):3841–3855, 2024
2024
-
[78]
Reinforcement learning: A survey.Journal of artificial intelligence research, 4:237–285, 1996
Leslie Pack Kaelbling, Michael L Littman, and Andrew W Moore. Reinforcement learning: A survey.Journal of artificial intelligence research, 4:237–285, 1996. 80
1996
-
[79]
Policy gradient methods for reinforcement learning with function approximation.Advances in neural infor- mation processing systems, 12, 1999
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation.Advances in neural infor- mation processing systems, 12, 1999
1999
-
[80]
Multi-armed bandit algorithms and empirical evalua- tion
Joannes Vermorel and Mehryar Mohri. Multi-armed bandit algorithms and empirical evalua- tion. InEuropean conference on machine learning, pages 437–448. Springer, 2005
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.