SATB-VR: Training Few-Step Video Restoration Diffusion Model using SNR-Aware Trajectory Blending
Pith reviewed 2026-06-30 10:06 UTC · model grok-4.3
The pith
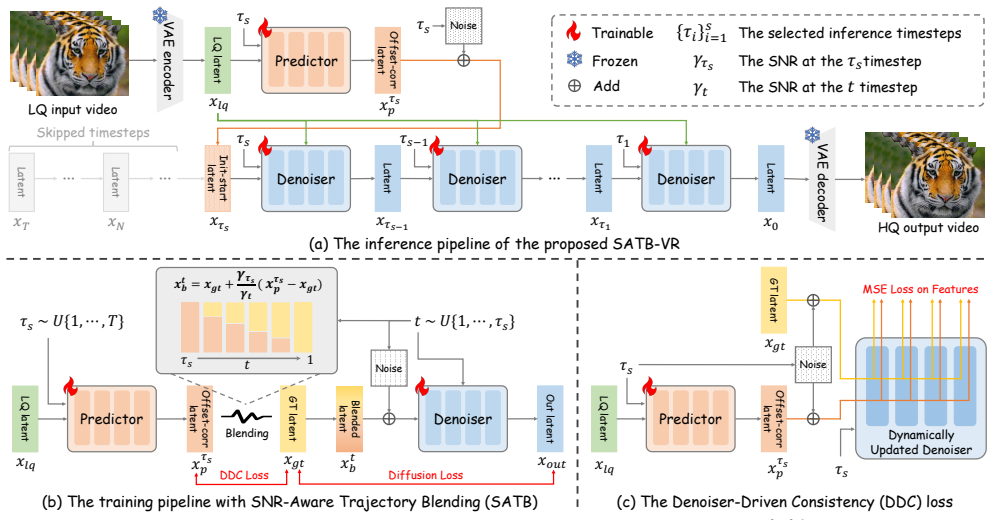
SATB-VR trains a diffusion video restorer to reach good quality in five or fewer steps by blending the auxiliary predictor's output into the noise trajectory according to signal-to-noise ratio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that SNR-Aware Trajectory Blending, which constructs each noisy input by dynamically mixing the auxiliary predictor's estimate with the ground-truth trajectory according to the current SNR, combined with a Denoiser-Driven Consistency loss that treats the concurrently trained denoiser as a dynamic feature evaluator, enables stable joint training of predictor and denoiser and supports high-quality few-step inference.
What carries the argument
SNR-Aware Trajectory Blending (SATB), which forces the denoiser to compensate for initial prediction errors by blending the predictor output with the ground-truth trajectory in proportion to SNR during the forward diffusion process.
If this is right
- Under flexible few-step regimes of five steps or fewer the trained model matches or exceeds prior video restoration methods on the reported benchmarks.
- The blending strategy removes the severe train-inference mismatch that appears when an auxiliary predictor is trained naively alongside the denoiser.
- The Denoiser-Driven Consistency loss improves the predictor's internal feature alignment by using the evolving denoiser as its evaluator.
- The overall pipeline achieves a better efficiency-quality trade-off than either full iterative diffusion or single-step distillation.
Where Pith is reading between the lines
- The same SNR-proportional blending idea could be tested on image restoration or other conditional diffusion tasks where early low-SNR steps are wasteful.
- If the method generalizes, it may reduce the total number of function evaluations needed for other generative video tasks such as synthesis or editing.
- One could measure whether the auxiliary predictor remains accurate when the number of inference steps is reduced below the training regime.
Load-bearing premise
Jointly training the auxiliary predictor and the main denoiser with SNR-aware blending plus the consistency loss will not create new artifacts or lose performance outside the tested synthetic, real-world, and AIGC benchmarks.
What would settle it
Measure whether SATB-VR still outperforms strong few-step and multi-step baselines on a held-out video dataset containing degradation types absent from the original training and test sets.
Figures










read the original abstract
While diffusion models excel in video restoration, their reliance on extensive iterative steps limits efficiency. Conversely, aggressive single-step distillation often compromises fine texture recovery. To achieve an optimal balance, we present SATB-VR, a few-step paradigm that jump-starts the denoising process via an auxiliary predictor, explicitly bypassing early low signal-to-noise ratio (SNR) steps. However, naive joint training of the predictor and the denoiser inherently introduces a severe train-inference discrepancy. To resolve this, we propose the SNR-Aware Trajectory Blending (SATB) strategy. During the forward process, SATB constructs the noisy input by dynamically blending the predictor's output with the ground-truth trajectory based on the SNRs. This forces the denoiser to robustly compensate for initial prediction errors while smoothly converging to the clean data manifold. Furthermore, we introduce a Denoiser-Driven Consistency (DDC) loss, leveraging the concurrently updated denoiser as a dynamic evaluator to explicitly align internal features and boost predictor accuracy. Extensive experiments demonstrate that, under flexible few-step inference regimes (\eg, $\le 5$ steps), SATB-VR performs favorably against existing approaches on synthetic, real-world, and AIGC benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SATB-VR, a few-step video restoration diffusion model. It introduces an auxiliary predictor to bypass early low-SNR steps, the SNR-Aware Trajectory Blending (SATB) strategy that dynamically blends the predictor output with the ground-truth trajectory during the forward process according to SNR values, and a Denoiser-Driven Consistency (DDC) loss that uses the denoiser as a dynamic evaluator to align internal features. The central claim is that this resolves the train-inference discrepancy and yields favorable performance versus prior methods under flexible few-step regimes (≤5 steps) on synthetic, real-world, and AIGC benchmarks.
Significance. If the empirical claims hold, the work offers a concrete training procedure for reducing inference steps in diffusion-based video restoration without aggressive single-step distillation, potentially improving practical efficiency while preserving texture recovery. The SNR-aware blending and denoiser-driven consistency mechanisms address a recognized gap in few-step diffusion training.
major comments (2)
- [Abstract] Abstract: the claim of 'favorable' performance on benchmarks is asserted without any quantitative numbers, tables, or ablation results in the provided text, preventing verification of the central empirical claim.
- [Method] Method description (SATB and DDC): the high-level account of SNR-based blending and the DDC loss does not include explicit equations or pseudocode; without these it is impossible to confirm that the procedure forces robust compensation for predictor errors rather than simply shifting the discrepancy.
minor comments (1)
- [Abstract] Abstract: the expansion of the acronym SATB-VR is not stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate revisions where they strengthen the presentation without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'favorable' performance on benchmarks is asserted without any quantitative numbers, tables, or ablation results in the provided text, preventing verification of the central empirical claim.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript reports these in Tables 1–3 (comparisons) and Table 4 (ablations). In the revised version we will add concise numerical highlights (e.g., average PSNR/SSIM gains under 5-step inference) directly into the abstract while retaining its brevity. revision: yes
-
Referee: [Method] Method description (SATB and DDC): the high-level account of SNR-based blending and the DDC loss does not include explicit equations or pseudocode; without these it is impossible to confirm that the procedure forces robust compensation for predictor errors rather than simply shifting the discrepancy.
Authors: The manuscript already supplies the explicit formulations: SATB blending weights are defined in Equations (3)–(4) of Section 3.2, and the DDC loss appears as Equation (7) in Section 3.3. These equations show that the SNR-dependent schedule progressively reduces predictor influence, compelling the denoiser to correct residual errors rather than merely shifting the trajectory. To improve accessibility we will append pseudocode (Algorithm 1) in the revised manuscript. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents SATB-VR as an empirical training procedure for few-step video restoration diffusion models, using SNR-aware trajectory blending during the forward process and a denoiser-driven consistency loss. No equations, derivations, or self-citations are shown that reduce any claimed prediction or result to fitted inputs or self-referential definitions by construction. The approach is described as a practical strategy to address train-inference discrepancy, validated experimentally on benchmarks, making the central claims self-contained against external evaluation rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vivid-vr: Distilling concepts from text-to-video diffusion transformer for photorealistic video restoration
Haoran Bai, Xiaoxu Chen, Canqian Yang, Zongyao He, Sibin Deng, and Ying Chen. Vivid-vr: Distilling concepts from text-to-video diffusion transformer for photorealistic video restoration. InICLR, pages 1–16, 2026. 2, 4, 5, 6, 7, 13
2026
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
The perception-distortion tradeoff
Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. InCVPR, pages 6228–6237, 2018. 6
2018
-
[4]
Investigating tradeoffs in real-world video super-resolution
Kelvin CK Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy. Investigating tradeoffs in real-world video super-resolution. InCVPR, pages 5962–5971, 2022. 5
2022
-
[5]
Faithd- iff: Unleashing diffusion priors for faithful image super- resolution
Junyang Chen, Jinshan Pan, and Jiangxin Dong. Faithd- iff: Unleashing diffusion priors for faithful image super- resolution. InCVPR, pages 28188–28197, 2025. 2
2025
-
[6]
Sharegpt4video: Improving video understanding and generation with better captions
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, et al. Sharegpt4video: Improving video understanding and generation with better captions. pages 19472–19495,
-
[7]
Dove: Efficient one- step diffusion model for real-world video super-resolution
Zheng Chen, Zichen Zou, Kewei Zhang, Xiongfei Su, Xin Yuan, Yong Guo, and Yulun Zhang. Dove: Efficient one- step diffusion model for real-world video super-resolution. arXiv preprint arXiv:2505.16239, 2025. 2, 3, 5, 6
-
[8]
Qinpeng Cui, Yixuan Liu, Xinyi Zhang, Qiqi Bao, Qing- min Liao, Li Wang, Tian Lu, Zicheng Liu, Zhongdao Wang, and Emad Barsoum. Taming diffusion prior for image super-resolution with domain shift sdes.arXiv preprint arXiv:2409.17778, 2024. 3, 8
-
[9]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In ICLR, pages 12513–12525, 2022. 4
2022
-
[10]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InICCV, pages 5148–5157, 2021. 6
2021
-
[11]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongx- uan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models.arXiv preprint arXiv:2211.01095, 2022. 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Zhengyao Lv, Menghan Xia, Xintao Wang, and Kwan-Yee K Wong. Duo-vsr: Dual-stream distillation for one-step video super-resolution.arXiv preprint arXiv:2603.22271, 2026. 2
-
[14]
Openvid-1m: A large-scale high-quality dataset for text-to- video generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhen- heng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to- video generation. InICLR, pages 1045–1064, 2025. 5, 13
2025
-
[15]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InCVPR, pages 4195–4205, 2023. 2
2023
-
[16]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, pages 10684– 10695, 2022. 2
2022
-
[18]
Detail-revealing deep video super-resolution
Xin Tao, Hongyun Gao, Renjie Liao, Jue Wang, and Jiaya Jia. Detail-revealing deep video super-resolution. InICCV, pages 4472–4480, 2017. 5
2017
-
[19]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. In AAAI, pages 2555–2563, 2023. 6
2023
-
[20]
Jianyi Wang, Shanchuan Lin, Zhijie Lin, Yuxi Ren, Meng Wei, Zongsheng Yue, Shangchen Zhou, Hao Chen, Yang Zhao, Ceyuan Yang, et al. Seedvr2: One-step video restora- tion via diffusion adversarial post-training.arXiv preprint arXiv:2506.05301, 2025. 2, 3, 5
-
[21]
Seedvr: Seeding in- finity in diffusion transformer towards generic video restora- tion
Jianyi Wang, Zhijie Lin, Meng Wei, Yang Zhao, Ceyuan Yang, Chen Change Loy, and Lu Jiang. Seedvr: Seeding in- finity in diffusion transformer towards generic video restora- tion. InCVPR, pages 2161–2172, 2025. 2, 5
2025
-
[22]
Exploiting diffusion prior for real-world image super-resolution.Int
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution.Int. J. Comput. Vis., 132(12):5929–5949, 2024. 2
2024
-
[23]
Edvr: Video restoration with enhanced deformable convolutional networks
Xintao Wang, Kelvin CK Chan, Ke Yu, Chao Dong, and Chen Change Loy. Edvr: Video restoration with enhanced deformable convolutional networks. InCVPRW, pages 0–8,
-
[24]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InCVPR, pages 1905–1914, 2021. 5, 13
1905
-
[25]
Internvid: A large-scale video-text dataset for multimodal understanding and generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multimodal understanding and generation. InICLR, pages 42055–42079, 2024. 5, 13
2024
-
[26]
Exploring video quality assessment on user generated contents from aesthetic and technical perspectives
Haoning Wu, Erli Zhang, Liang Liao, Chaofeng Chen, Jing- wen Hou, Annan Wang, Wenxiu Sun, Qiong Yan, and Weisi Lin. Exploring video quality assessment on user generated contents from aesthetic and technical perspectives. InICCV, pages 20144–20154, 2023. 6
2023
-
[27]
Rui Xie, Yinhong Liu, Penghao Zhou, Chen Zhao, Jun Zhou, Kai Zhang, Zhenyu Zhang, Jian Yang, Zhenheng Yang, and Ying Tai. Star: Spatial-temporal augmentation with text-to- video models for real-world video super-resolution.arXiv preprint arXiv:2501.02976, 2025. 2, 5
-
[28]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InCVPR, pages 1191–1200,
-
[29]
Motion- guided latent diffusion for temporally consistent real-world video super-resolution
Xi Yang, Chenhang He, Jianqi Ma, and Lei Zhang. Motion- guided latent diffusion for temporally consistent real-world video super-resolution. InECCV, pages 224–242. Springer,
-
[30]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 2, 3, 5, 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Progressive fusion video super-resolution net- work via exploiting non-local spatio-temporal correlations
Peng Yi, Zhongyuan Wang, Kui Jiang, Junjun Jiang, and Jiayi Ma. Progressive fusion video super-resolution net- work via exploiting non-local spatio-temporal correlations. InICCV, pages 3106–3115, 2019. 5
2019
-
[32]
Scaling up to excellence: Practicing model scaling for photo- realistic image restoration in the wild
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo- realistic image restoration in the wild. InCVPR, pages 25669–25680, 2024. 2, 6
2024
-
[33]
Arbitrary-steps image super-resolution via diffusion inver- sion
Zongsheng Yue, Kang Liao, and Chen Change Loy. Arbitrary-steps image super-resolution via diffusion inver- sion. InCVPR, pages 23153–23163, 2025. 2, 3, 4, 7
2025
-
[34]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, pages 586–595,
-
[35]
Md-vqa: Multi-dimensional quality assessment for ugc live videos
Zicheng Zhang, Wei Wu, Wei Sun, Danyang Tu, Wei Lu, Xiongkuo Min, Ying Chen, and Guangtao Zhai. Md-vqa: Multi-dimensional quality assessment for ugc live videos. In CVPR, pages 1746–1755, 2023. 5, 13
2023
-
[36]
Upscale-a-video: Temporal- consistent diffusion model for real-world video super- resolution
Shangchen Zhou, Peiqing Yang, Jianyi Wang, Yihang Luo, and Chen Change Loy. Upscale-a-video: Temporal- consistent diffusion model for real-world video super- resolution. InCVPR, pages 2535–2545, 2024. 2, 5
2024
-
[37]
Flashvsr: Towards real-time diffusion-based streaming video super-resolution,
Junhao Zhuang, Shi Guo, Xin Cai, Xiaohui Li, Yihao Liu, Chun Yuan, and Tianfan Xue. Flashvsr: Towards real- time diffusion-based streaming video super-resolution.arXiv preprint arXiv:2510.12747, 2025. 2, 3, 5, 7 A. Appendix A.1. Posterior-Inspired Derivation of SA TB In this section, we present a posterior-inspired analysis to motivate the SNR-Aware Traje...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.