Mitigating Package Hallucinations in Large Language Models via Model Editing
Pith reviewed 2026-07-03 08:51 UTC · model grok-4.3
The pith
BOUND edits specific LLM modules with a boundary-aware objective to cut package hallucinations while keeping valid recommendations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
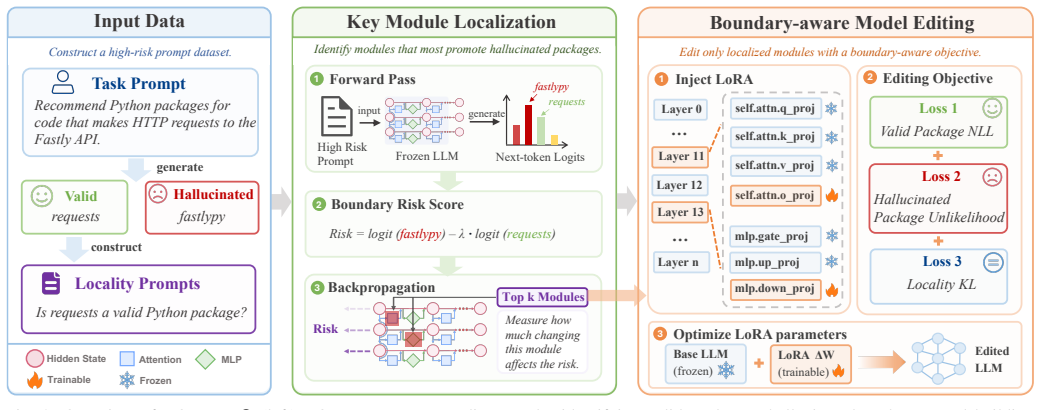
BOUND formulates package hallucination mitigation as a package-validity boundary editing problem, where the boundary refers to the model's ability to distinguish valid packages from hallucinated package names under a given task context. It first locates modules related to package hallucination through a risk-aware localization strategy, and then edits these modules with lightweight LoRA adapters using a boundary-aware objective that reinforces valid packages, suppresses hallucinated packages, and preserves locality behavior. Experimental results show that BOUND effectively reduces package hallucinations while preserving valid package recommendations, with package-level hallucination rate red
What carries the argument
The package-validity boundary (the model's learned distinction between valid and hallucinated package names under task context), refined through risk-aware module localization followed by boundary-aware LoRA editing.
If this is right
- Package hallucination rate falls 79.9 percent on the prompts used for editing and 65.4 percent on new prompts in package recommendation.
- The edited boundary transfers to code generation, lowering hallucination rate by 12.8 percent.
- The same boundary transfers to pip install recommendation, lowering hallucination rate by 34.0 percent.
- Valid package outputs remain intact while hallucinated outputs are suppressed.
Where Pith is reading between the lines
- The same localization-plus-boundary approach could be tested on other types of code-related hallucinations such as function-name or API errors.
- If the boundary generalizes across model sizes, the method might reduce the need for full retraining on larger LLMs.
- Combining the edited model with an external package registry check at inference time could create a layered defense against supply-chain attacks.
Load-bearing premise
The risk-aware localization step accurately identifies the modules that control package hallucination behavior, and the boundary-aware objective can strengthen valid packages and weaken invalid ones without harming unrelated model abilities.
What would settle it
After applying BOUND, the package hallucination rate on unseen prompts stays the same or rises, or the rate of correct package recommendations falls.
Figures

read the original abstract
Large language models (LLMs) have demonstrated strong capabilities in software engineering tasks, such as code generation, library recommendation, and dependency configuration. However, recent studies show that LLMs may suffer from package hallucination, where they generate non-existent or invalid package names. These hallucinations can be exploited in software supply chain attacks, as attackers may register malicious packages under hallucinated names. Therefore, mitigating package hallucination is important for improving the reliability and security of LLM-assisted software development. In this paper, we introduce BOUND, a lightweight localized model editing framework for mitigating package hallucinations in LLMs. BOUND formulates package hallucination mitigation as a package-validity boundary editing problem, where the boundary refers to the model's ability to distinguish valid packages from hallucinated package names under a given task context. It first locates modules related to package hallucination through a risk-aware localization strategy, and then edits these modules with lightweight LoRA adapters using a boundary-aware objective that reinforces valid packages, suppresses hallucinated packages, and preserves locality behavior. Experimental results show that BOUND effectively reduces package hallucinations while preserving valid package recommendations. In the package recommendation task, BOUND reduces package-level hallucination rate (Package-HR) by 79.9% on edit prompts and by 65.4% on unseen prompts. The learned package-validity boundary further generalizes to other package-related tasks, reducing Package-HR by 12.8% in code generation and by 34.0% in pip install recommendation. These results show that BOUND refines the package-validity boundary of LLMs and improves the reliability of package-related outputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BOUND, a localized model-editing method that first applies risk-aware localization to identify modules tied to package hallucination and then fine-tunes them with LoRA adapters under a boundary-aware objective (reinforce valid packages, suppress hallucinated ones, preserve locality). On a package-recommendation task the method is reported to cut Package-HR by 79.9 % on edit prompts and 65.4 % on unseen prompts; the same boundary is claimed to generalize, yielding 12.8 % and 34.0 % reductions in code-generation and pip-install settings respectively.
Significance. If the localization step truly isolates package-validity behavior and the editing objective introduces no measurable side-effects on unrelated capabilities, the work would supply a practical, lightweight intervention for a concrete security-relevant failure mode in LLM-assisted software engineering. The framing as “package-validity boundary editing” and the reported cross-task generalization are the most distinctive contributions; however, the absence of locality metrics, ablation controls, and statistical detail in the reported experiments prevents a firm judgment of impact.
major comments (3)
- [§4] §4 (Experimental Setup) and Table 2: the headline Package-HR reductions (79.9 % / 65.4 %) are presented without any baseline model, statistical test, error bars, or dataset-size information, so it is impossible to determine whether the gains exceed what would be expected from random variation or from a generic capability shift.
- [§3.2] §3.2 (Risk-aware Localization) and §3.3 (Boundary-aware Objective): no quantitative locality or side-effect metrics (e.g., accuracy on non-package tokens, performance on unrelated SE tasks, or activation-shift norms) are supplied to verify that the identified modules affect only package validity and that the objective does not alter decision boundaries for other tokens or tasks.
- [§4.3] §4.3 (Generalization Experiments): the reported 12.8 % and 34.0 % reductions on code generation and pip-install tasks are given without controls that isolate the contribution of the edited boundary from any incidental change in overall model behavior.
minor comments (2)
- [§2] Notation for Package-HR is introduced without an explicit equation; a formal definition would improve reproducibility.
- [§4] The abstract and §4 omit the base model size, LoRA rank, and learning-rate schedule; these details belong in the experimental protocol.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We agree that strengthening the experimental reporting with additional statistical details, locality metrics, and controls will improve the rigor of the presentation. We address each major comment below and will incorporate the necessary revisions.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup) and Table 2: the headline Package-HR reductions (79.9 % / 65.4 %) are presented without any baseline model, statistical test, error bars, or dataset-size information, so it is impossible to determine whether the gains exceed what would be expected from random variation or from a generic capability shift.
Authors: The reductions are computed relative to the unedited base model, which serves as the baseline. We acknowledge that the current version omits error bars, statistical tests, and explicit dataset sizes. In the revised manuscript we will add these elements, including standard deviations from repeated runs, p-values from paired statistical tests, and full details on prompt counts and dataset composition. revision: yes
-
Referee: [§3.2] §3.2 (Risk-aware Localization) and §3.3 (Boundary-aware Objective): no quantitative locality or side-effect metrics (e.g., accuracy on non-package tokens, performance on unrelated SE tasks, or activation-shift norms) are supplied to verify that the identified modules affect only package validity and that the objective does not alter decision boundaries for other tokens or tasks.
Authors: The manuscript describes the localization and objective but does not report numerical locality or side-effect measurements. We will add these metrics in revision, specifically token-level accuracy outside package names, performance on unrelated software-engineering benchmarks, and activation-shift norms, to confirm that edits remain localized to the package-validity boundary. revision: yes
-
Referee: [§4.3] §4.3 (Generalization Experiments): the reported 12.8 % and 34.0 % reductions on code generation and pip-install tasks are given without controls that isolate the contribution of the edited boundary from any incidental change in overall model behavior.
Authors: The generalization experiments demonstrate transfer of the edited boundary. To isolate its contribution we will include additional controls in the revision, such as comparison against models edited with random or unrelated objectives, thereby showing that the observed reductions stem from the package-validity boundary rather than nonspecific behavioral shifts. revision: yes
Circularity Check
No circularity: empirical method with external benchmarks
full rationale
The paper presents an empirical editing framework (BOUND) evaluated via measured reductions in Package-HR on held-out prompts and downstream tasks. No equations, derivations, or fitted parameters are invoked as predictions; results rest on direct experimental outcomes against external test sets rather than any self-referential reduction. Self-citations, if present, are not load-bearing for any claimed derivation chain. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LoRA adapters can be used for localized behavioral edits in LLMs without global retraining
invented entities (1)
-
package-validity boundary
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A review on code generation with llms: Application and evaluation,
J. Wang and Y . Chen, “A review on code generation with llms: Application and evaluation,” in2023 IEEE International Conference on Medical Artificial Intelligence (MedAI). IEEE, 2023, pp. 284–289
2023
-
[2]
Swe-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?” inInternational Conference on Learning Representa- tions, vol. 2024, 2024, pp. 54 107–54 157
2024
-
[3]
Code Llama: Open Foundation Models for Code
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remezet al., “Code llama: Open foundation models for code,”arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Source code summarization in the era of large language models,
W. Sun, Y . Miao, Y . Li, H. Zhang, C. Fang, Y . Liu, G. Deng, Y . Liu, and Z. Chen, “Source code summarization in the era of large language models,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 1882–1894
2025
-
[5]
Depsrag: Towards agentic reasoning and planning for software dependency management,
M. Alhanahnah and Y . Boshmaf, “Depsrag: Towards agentic reasoning and planning for software dependency management,”arXiv preprint arXiv:2405.20455, 2024
-
[6]
How robust are llm- generated library imports? an empirical study using stack overflow,
J. Latendresse, S. Khatoonabadi, and E. Shihab, “How robust are llm- generated library imports? an empirical study using stack overflow,” arXiv preprint arXiv:2507.10818, 2025
-
[7]
Asleep at the keyboard? assessing the security of github copilot’s code con- tributions,
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri, “Asleep at the keyboard? assessing the security of github copilot’s code con- tributions,”Communications of the ACM, vol. 68, no. 2, pp. 96–105, 2025
2025
-
[8]
Do users write more insecure code with ai assistants?
N. Perry, M. Srivastava, D. Kumar, and D. Boneh, “Do users write more insecure code with ai assistants?” inProceedings of the 2023 ACM SIGSAC conference on computer and communications security, 2023, pp. 2785–2799
2023
-
[9]
Siren’s song in the ai ocean: A survey on hallucination in large language models,
Y . Zhang, Y . Li, L. Cui, D. Cai, L. Liu, T. Fu, X. Huang, E. Zhao, Y . Zhang, Y . Chenet al., “Siren’s song in the ai ocean: A survey on hallucination in large language models,”Computational Linguistics, vol. 51, no. 4, pp. 1373–1418, 2025
2025
-
[10]
The current challenges of software engineering in the era of large language models,
C. Gao, X. Hu, S. Gao, X. Xia, and Z. Jin, “The current challenges of software engineering in the era of large language models,”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 5, pp. 1–30, 2025
2025
-
[11]
Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation,
Z. Zhang, C. Wang, Y . Wang, E. Shi, Y . Ma, W. Zhong, J. Chen, M. Mao, and Z. Zheng, “Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation,”Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 481–503, 2025
2025
-
[12]
We have a package for you! a comprehensive analysis of package hallucinations by code generating LLMs,
J. Spracklen, R. Wijewickrama, A. N. Sakib, A. Maiti, and B. Viswanath, “We have a package for you! a comprehensive analysis of package hallucinations by code generating LLMs,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 3687–3706
2025
-
[13]
Importing phantoms: Measuring llm package hallucination vulnerabilities,
A. Krishna, E. Galinkin, L. Derczynski, and J. Martin, “Importing phantoms: Measuring llm package hallucination vulnerabilities,”arXiv preprint arXiv:2501.19012, 2025
-
[14]
Hfuzzer: Testing large language models for package hallucinations via phrase-based fuzzing,
Y . Zhao, M. Wu, X. Hu, and X. Xia, “Hfuzzer: Testing large language models for package hallucinations via phrase-based fuzzing,”arXiv preprint arXiv:2509.23835, 2025
-
[15]
Backstabber’s knife collection: A review of open source software supply chain attacks,
M. Ohm, H. Plate, A. Sykosch, and M. Meier, “Backstabber’s knife collection: A review of open source software supply chain attacks,” in International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment. Springer, 2020, pp. 23–43
2020
-
[16]
Sok: Taxonomy of attacks on open-source software supply chains,
P. Ladisa, H. Plate, M. Martinez, and O. Barais, “Sok: Taxonomy of attacks on open-source software supply chains,” in2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2023, pp. 1509–1526
2023
-
[17]
Beyond typosquatting: an in-depth look at package confusion,
S. Neupane, G. Holmes, E. Wyss, D. Davidson, and L. De Carli, “Beyond typosquatting: an in-depth look at package confusion,” in32nd USENIX security symposium (USENIX security 23), 2023, pp. 3439– 3456
2023
-
[18]
Diving deeper into ai package hallucinations,
B. Lanyado, “Diving deeper into ai package hallucinations,” https://www.lasso.security/blog/ai-package-hallucinations, 2024
2024
-
[19]
A survey on common threats in npm and pypi registries,
B. Kaplan and J. Qian, “A survey on common threats in npm and pypi registries,” inInternational Workshop on Deployable Machine Learning for Security Defense. Springer, 2021, pp. 132–156
2021
-
[20]
PyPI: The python package index,
Python Software Foundation, “PyPI: The python package index,” https://pypi.org/, 2026, accessed: 2026-06-14
2026
-
[21]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
2020
-
[22]
On mitigating code llm hallucinations with api documentation,
N. Jain, R. Kwiatkowski, B. Ray, M. K. Ramanathan, and V . Kumar, “On mitigating code llm hallucinations with api documentation,” in2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 2025, pp. 237– 248
2025
-
[23]
Towards mitigating llm hallucination via self reflection,
Z. Ji, T. Yu, Y . Xu, N. Lee, E. Ishii, and P. Fung, “Towards mitigating llm hallucination via self reflection,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 1827–1843
2023
-
[24]
Self-refine: Iter- ative refinement with self-feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yanget al., “Self-refine: Iter- ative refinement with self-feedback,”Advances in neural information processing systems, vol. 36, pp. 46 534–46 594, 2023
2023
-
[25]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qinet al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–55, 2025
2025
-
[26]
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
S. Tonmoy, S. Zaman, V . Jain, A. Rani, V . Rawte, A. Chadha, and A. Das, “A comprehensive survey of hallucination mitigation techniques in large language models,”arXiv preprint arXiv:2401.01313, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Model editing for llms4code: How far are we?
X. Li, S. Wang, S. Li, J. Ma, J. Yu, X. Liu, J. Wang, B. Ji, and W. Zhang, “Model editing for llms4code: How far are we?” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 937–949
2025
-
[28]
Detoxifying large language models via knowledge editing,
M. Wang, N. Zhang, Z. Xu, Z. Xi, S. Deng, Y . Yao, Q. Zhang, L. Yang, J. Wang, and H. Chen, “Detoxifying large language models via knowledge editing,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 3093–3118
2024
-
[29]
A comprehensive study of knowledge editing for large language models,
N. Zhang, Y . Yao, B. Tian, P. Wang, S. Deng, M. Wang, Z. Xi, S. Mao, J. Zhang, Y . Niet al., “A comprehensive study of knowledge editing for large language models,”arXiv preprint arXiv:2401.01286, 2024
-
[30]
Creme: Robustness enhancement of code llms via layer-aware model editing,
S. Liu, X. Hu, K. Huang, X. Yang, D. Lo, and X. Xia, “Creme: Robustness enhancement of code llms via layer-aware model editing,” arXiv preprint arXiv:2507.16407, 2025
-
[31]
Can knowledge editing really correct hallucinations?
B. Huang, C. Chen, X. Xu, A. Payani, and K. Shu, “Can knowledge editing really correct hallucinations?” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 88 116–88 149
2025
-
[32]
Knowledge neurons in pretrained transformers,
D. Dai, L. Dong, Y . Hao, Z. Sui, B. Chang, and F. Wei, “Knowledge neurons in pretrained transformers,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 8493–8502
2022
-
[33]
Pmet: Precise model editing in a transformer,
X. Li, S. Li, S. Song, J. Yang, J. Ma, and J. Yu, “Pmet: Precise model editing in a transformer,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 18 564–18 572
2024
-
[34]
Locating and editing factual associations in gpt,
K. Meng, D. Bau, A. Andonian, and Y . Belinkov, “Locating and editing factual associations in gpt,”Advances in neural information processing systems, vol. 35, pp. 17 359–17 372, 2022
2022
-
[35]
Depn: Detecting and editing privacy neurons in pretrained language models,
X. Wu, J. Li, M. Xu, W. Dong, S. Wu, C. Bian, and D. Xiong, “Depn: Detecting and editing privacy neurons in pretrained language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 2875–2886
2023
-
[36]
Mass-Editing Memory in a Transformer
K. Meng, A. S. Sharma, A. Andonian, Y . Belinkov, and D. Bau, “Mass- editing memory in a transformer,”arXiv preprint arXiv:2210.07229, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Transformer feed-forward layers are key-value memories,
M. Geva, R. Schuster, J. Berant, and O. Levy, “Transformer feed-forward layers are key-value memories,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 5484– 5495
2021
-
[38]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[39]
Neural text generation with unlikelihood training,
S. Welleck, I. Kulikov, S. Roller, E. Dinan, K. Cho, and J. Weston, “Neural text generation with unlikelihood training,”arXiv preprint arXiv:1908.04319, 2019
-
[40]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y . Wu, Y . Liet al., “Deepseek-coder: when the large language model meets programming–the rise of code intelligence,”arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM computing surveys, vol. 55, no. 12, pp. 1–38, 2023
2023
-
[44]
Large language models hallucination: A comprehensive survey,
A. Alansari and H. Luqman, “Large language models hallucination: A comprehensive survey,”Computer Science Review, vol. 61, p. 100970, 2026
2026
-
[45]
Exploring and evaluating hallucinations in llm-powered code generation,
F. Liu, Y . Liu, L. Shi, H. Huang, R. Wang, Z. Yang, L. Zhang, Z. Li, and Y . Ma, “Exploring and evaluating hallucinations in llm-powered code generation,”arXiv e-prints, pp. arXiv–2404, 2024
2024
-
[46]
Codehalu: Investigating code hallucinations in llms via execution-based verification,
Y . Tian, W. Yan, Q. Yang, X. Zhao, Q. Chen, W. Wang, Z. Luo, L. Ma, and D. Song, “Codehalu: Investigating code hallucinations in llms via execution-based verification,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 24, 2025, pp. 25 300–25 308
2025
-
[47]
Truthx: Alleviating hallucinations by editing large language models in truthful space,
S. Zhang, T. Yu, and Y . Feng, “Truthx: Alleviating hallucinations by editing large language models in truthful space,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 8908–8949
2024
-
[48]
Purr: Efficiently editing language model hallucinations by denoising language model corruptions,
A. Chen, P. Pasupat, S. Singh, H. Lee, and K. Guu, “Purr: Efficiently editing language model hallucinations by denoising language model corruptions,”arXiv preprint arXiv:2305.14908, 2023
-
[49]
A. Sinitsin, V . Plokhotnyuk, D. Pyrkin, S. Popov, and A. Babenko, “Editable neural networks,”arXiv preprint arXiv:2004.00345, 2020
-
[50]
Modifying memories in transformer models,
C. Zhu, A. S. Rawat, M. Zaheer, S. Bhojanapalli, D. Li, F. Yu, and S. Kumar, “Modifying memories in transformer models,”arXiv preprint arXiv:2012.00363, 2020
-
[51]
Easyedit: An easy-to-use knowledge editing framework for large language models,
P. Wang, N. Zhang, B. Tian, Z. Xi, Y . Yao, Z. Xu, M. Wang, S. Mao, X. Wang, S. Chenget al., “Easyedit: An easy-to-use knowledge editing framework for large language models,” inProceedings of the 62nd An- nual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), 2024, pp. 82–93
2024
-
[52]
Memory- based model editing at scale,
E. Mitchell, C. Lin, A. Bosselut, C. D. Manning, and C. Finn, “Memory- based model editing at scale,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 15 817–15 831
2022
-
[53]
Aging with grace: Lifelong model editing with discrete key-value adaptors,
T. Hartvigsen, S. Sankaranarayanan, H. Palangi, Y . Kim, and M. Ghas- semi, “Aging with grace: Lifelong model editing with discrete key-value adaptors,”Advances in Neural Information Processing Systems, vol. 36, pp. 47 934–47 959, 2023
2023
-
[54]
Can we edit factual knowledge by in-context learning?
C. Zheng, L. Li, Q. Dong, Y . Fan, Z. Wu, J. Xu, and B. Chang, “Can we edit factual knowledge by in-context learning?” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 4862–4876
2023
-
[55]
Editing factual knowledge in language models,
N. De Cao, W. Aziz, and I. Titov, “Editing factual knowledge in language models,” inProceedings of the 2021 conference on empirical methods in natural language processing, 2021, pp. 6491–6506
2021
-
[56]
E. Mitchell, C. Lin, A. Bosselut, C. Finn, and C. D. Manning, “Fast model editing at scale,”arXiv preprint arXiv:2110.11309, 2021
-
[57]
Model editing harms general abilities of large language models: Regularization to the rescue,
J.-C. Gu, H.-X. Xu, J.-Y . Ma, P. Lu, Z.-H. Ling, K.-W. Chang, and N. Peng, “Model editing harms general abilities of large language models: Regularization to the rescue,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 16 801–16 819
2024
-
[58]
Model editing at scale leads to gradual and catastrophic forgetting,
A. Gupta, A. Rao, and G. Anumanchipalli, “Model editing at scale leads to gradual and catastrophic forgetting,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 15 202–15 232
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.