GUIDE-VAE: Advancing Data Generation with User Information and Pattern Dictionaries
Pith reviewed 2026-05-23 17:16 UTC · model grok-4.3
The pith
GUIDE-VAE conditions a VAE on user embeddings and composes covariances from a shared pattern dictionary to generate realistic user-specific data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
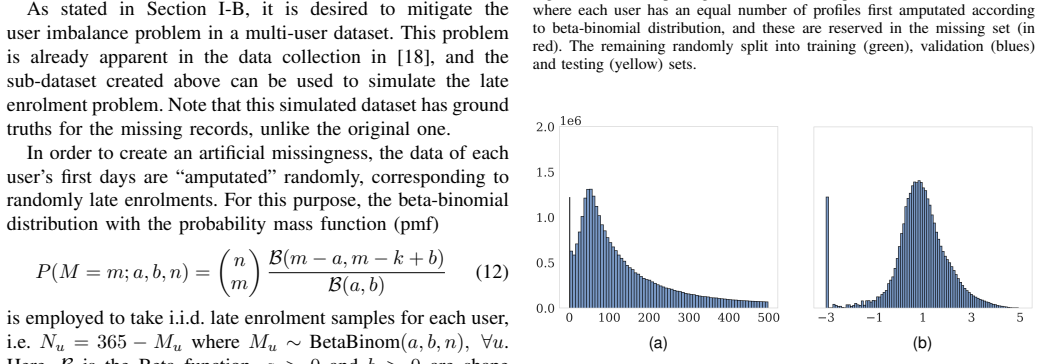
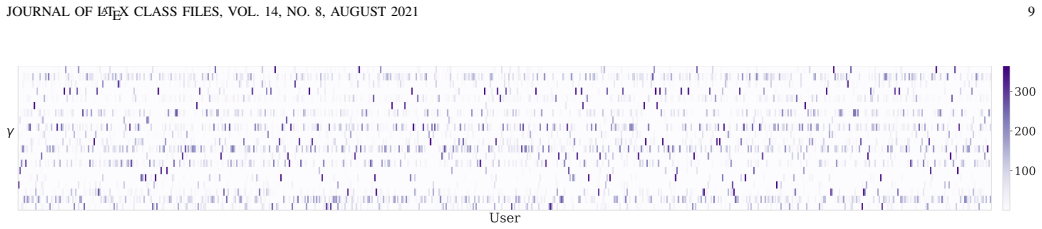
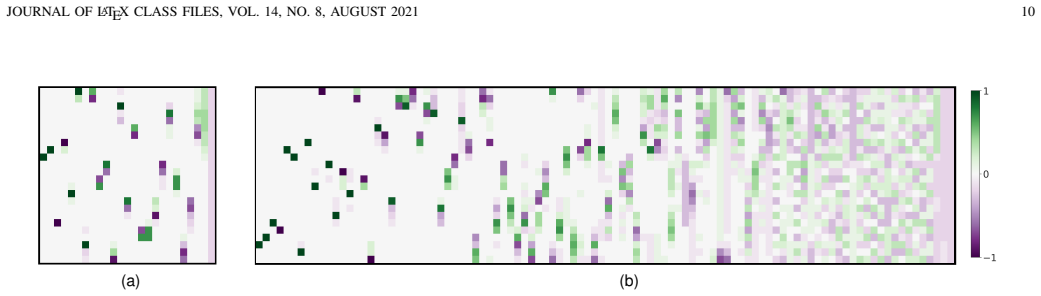
GUIDE-VAE is a conditional generative model that feeds learned user embeddings into the decoder and assembles feature covariances from a shared pattern dictionary via PDCC. On a multi-user smart-meter dataset with large imbalance, the model yields higher-quality synthetic records and more accurate missing-record imputations than baselines that lack user conditioning or pattern sharing, while qualitative checks confirm reduced noise and over-smoothing.
What carries the argument
User embeddings plus pattern dictionary-based covariance composition (PDCC) inside a conditional VAE
If this is right
- Data points can be generated for any chosen user by supplying that user's embedding.
- Performance on generation and imputation remains stable under large differences in the number of records per user.
- PDCC reduces the noise and over-smoothing typical of VAE outputs by explicitly modeling feature dependencies through shared patterns.
- The same architecture supports both unconditional synthetic generation and conditional imputation of missing entries.
- The method applies to any multi-user collection where entities share latent patterns but differ in data richness.
Where Pith is reading between the lines
- The separation of user-specific and shared components offers a route to personalization in other generative tasks that currently ignore identity.
- A learned pattern dictionary may surface recurring structures that domain experts could inspect or reuse across different user cohorts.
- The framework suggests a general template for conditional generation whenever data arrives from multiple sources with unequal sampling rates.
Load-bearing premise
User embeddings together with a shared pattern dictionary can extract user-specific structure even when data volume varies sharply across users, rather than the model simply memorizing the few users who contribute most records.
What would settle it
A controlled experiment on a synthetic multi-user dataset with extreme imbalance (most users having only a handful of records) in which GUIDE-VAE's generation or imputation metrics fall to the level of a standard VAE without user embeddings or PDCC.
Figures







read the original abstract
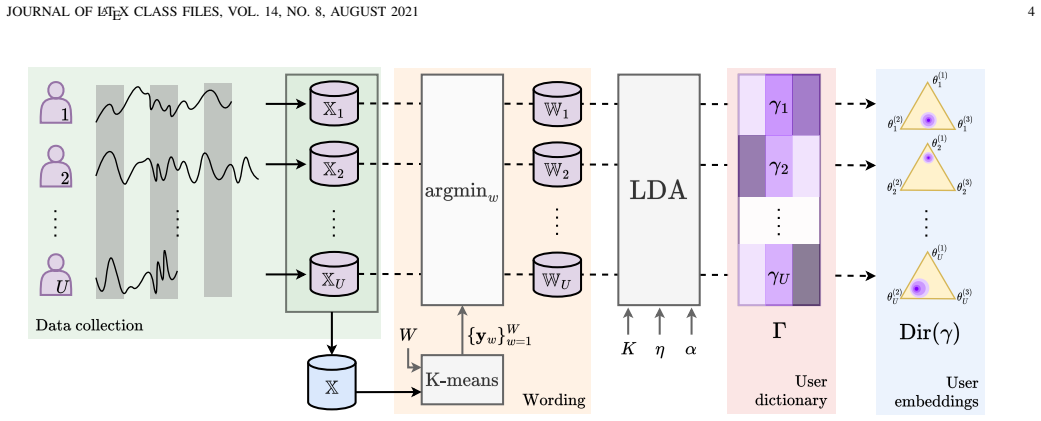
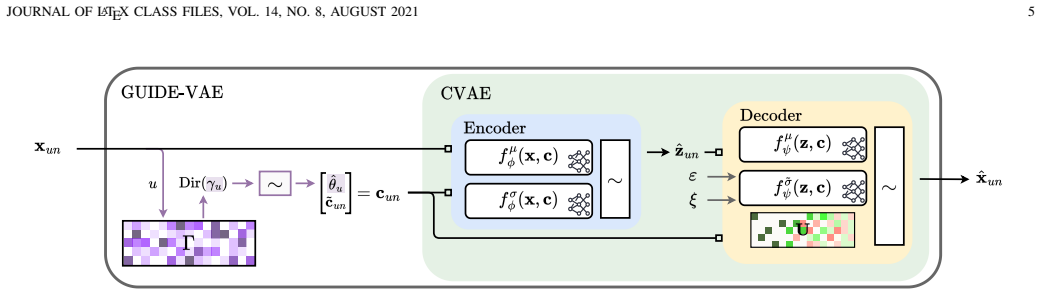
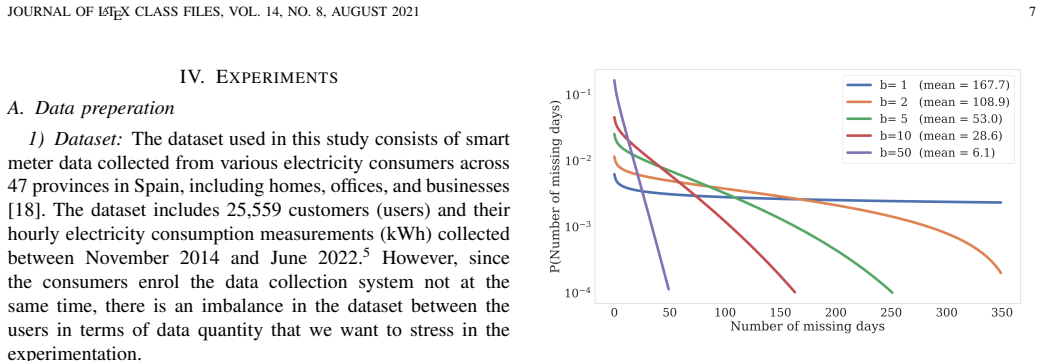
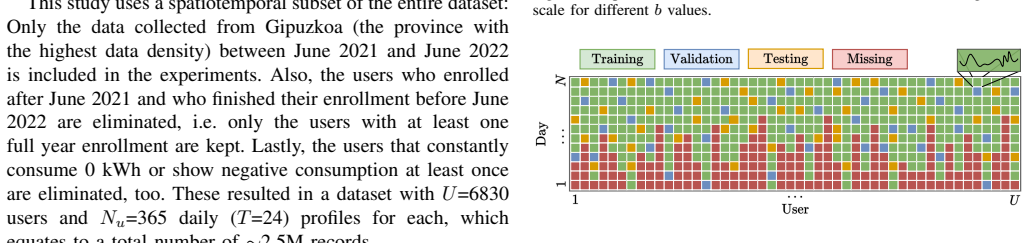
Generative modelling of multi-user datasets has become prominent in science and engineering. Generating a data point for a given user requires employing user information, and conventional generative models, including variational autoencoders (VAEs), often ignore this. This paper introduces GUIDE-VAE, a novel conditional generative model that leverages user embeddings to generate user-guided data. By leveraging shared patterns across users, GUIDE-VAE improves performance in multi-user settings, even under significant data imbalance. In addition to integrating user information, GUIDE-VAE incorporates a pattern dictionary-based covariance composition (PDCC) to improve the realism of generated samples by capturing complex feature dependencies. While user embeddings drive performance gains, PDCC addresses common issues such as noise and over-smoothing typically seen in VAEs. The proposed GUIDE-VAE was evaluated on a multi-user smart meter dataset characterised by substantial data imbalance across users. Quantitative results show that GUIDE-VAE performs effectively on both synthetic data generation and missing-record imputation tasks, while qualitative evaluations indicate that it produces more plausible and less noisy data. These results establish GUIDE-VAE as a promising tool for controlled, realistic data generation in multi-user datasets, with potential applications across domains that require user-informed modelling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GUIDE-VAE, a conditional VAE that incorporates user embeddings for user-guided generation and a pattern dictionary-based covariance composition (PDCC) to capture complex feature dependencies and reduce noise/over-smoothing. It claims improved performance on synthetic data generation and missing-record imputation tasks for a multi-user smart meter dataset with substantial imbalance across users, with qualitative results showing more plausible outputs.
Significance. If substantiated, the approach could advance conditional generative modeling for imbalanced multi-user datasets by explicitly handling user-specific structure. However, the absence of reported metrics, baselines, or ablations in the presented claims limits its immediate impact.
major comments (3)
- [Abstract] Abstract: The central claim that 'quantitative results show that GUIDE-VAE performs effectively' and improves performance 'even under significant data imbalance' is unsupported by any reported metrics, baselines, statistical tests, error bars, or dataset statistics, making the performance assertions impossible to evaluate.
- [Abstract] Abstract/Evaluation: The assumption that user embeddings combined with the shared pattern dictionary reliably capture user-specific structure under imbalance lacks any ablation isolating low-data users, stratified reconstruction error by user data volume, or analysis of embedding behavior when rich-user data is held out or down-weighted; without this, gains could be artifacts of memorization rather than the claimed mechanism.
- [Methods] Methods: No equations, derivations, or explicit formulation are shown for the PDCC covariance composition or the precise integration of user embeddings into the VAE encoder/decoder, preventing assessment of whether these components are load-bearing or tautological.
minor comments (2)
- The manuscript would benefit from explicit mathematical definitions of the user embedding conditioning and PDCC operation, including how the pattern dictionary is learned and composed.
- [Evaluation] Evaluation is limited to a single domain (smart meters); broader testing or discussion of generalizability would strengthen the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below and commit to revisions that directly resolve the identified gaps in the abstract, evaluation, and methods sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'quantitative results show that GUIDE-VAE performs effectively' and improves performance 'even under significant data imbalance' is unsupported by any reported metrics, baselines, statistical tests, error bars, or dataset statistics, making the performance assertions impossible to evaluate.
Authors: We agree that the abstract's performance claims require supporting quantitative details to be evaluable. In the revised manuscript we will expand the abstract to report key metrics (reconstruction and generation errors), the specific baselines used, statistical tests with error bars from repeated runs, and dataset statistics quantifying the user imbalance. This will allow direct assessment of the claimed improvements. revision: yes
-
Referee: [Abstract] Abstract/Evaluation: The assumption that user embeddings combined with the shared pattern dictionary reliably capture user-specific structure under imbalance lacks any ablation isolating low-data users, stratified reconstruction error by user data volume, or analysis of embedding behavior when rich-user data is held out or down-weighted; without this, gains could be artifacts of memorization rather than the claimed mechanism.
Authors: We acknowledge the value of these targeted ablations for substantiating the mechanism. The revised version will include new experiments that isolate performance on low-data users, provide stratified reconstruction errors by user data volume, and analyze embedding behavior under hold-out or down-weighting of rich-user data. These additions will help distinguish the proposed user-embedding and pattern-dictionary contributions from potential memorization effects. revision: yes
-
Referee: [Methods] Methods: No equations, derivations, or explicit formulation are shown for the PDCC covariance composition or the precise integration of user embeddings into the VAE encoder/decoder, preventing assessment of whether these components are load-bearing or tautological.
Authors: We agree that explicit mathematical formulations are essential. The revised methods section will present the full equations for the pattern-dictionary-based covariance composition (PDCC), including how dictionary atoms are selected and combined, as well as the precise conditioning of the VAE encoder and decoder on user embeddings. Derivations and implementation details will be added to clarify the role of each component. revision: yes
Circularity Check
No circularity: architecture and claims are independent of inputs
full rationale
The paper defines GUIDE-VAE as a conditional VAE augmented with user embeddings and a pattern dictionary-based covariance composition (PDCC). These are presented as architectural additions whose value is assessed via empirical evaluation on a smart-meter dataset (synthetic generation and imputation tasks). No equations, derivations, or self-citations are invoked that reduce the claimed performance gains to a fitted quantity defined by the same data or to a prior result by the same authors. The abstract and model description treat user embeddings and PDCC as mechanisms whose effectiveness is tested rather than assumed by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard VAE modeling assumptions (Gaussian latent variables, evidence lower bound optimization)
invented entities (1)
-
Pattern dictionary-based covariance composition (PDCC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Synthetic data for privacy-preserving clinical risk prediction,
Z. Qian, T. Callender, B. Cebere, S. M. Janes, N. Navani, and M. van der Schaar, “Synthetic data for privacy-preserving clinical risk prediction,” medRxiv, pp. 2023–05, 2023
work page 2023
-
[2]
Pocket2mol: Effi- cient molecular sampling based on 3d protein pockets,
X. Peng, S. Luo, J. Guan, Q. Xie, J. Peng, and J. Ma, “Pocket2mol: Effi- cient molecular sampling based on 3d protein pockets,” in International Conference on Machine Learning . PMLR, 2022, pp. 17 644–17 655
work page 2022
-
[3]
Anonymization through data synthesis using generative adversarial networks (ads-gan),
J. Yoon, L. N. Drumright, and M. Van Der Schaar, “Anonymization through data synthesis using generative adversarial networks (ads-gan),” IEEE journal of biomedical and health informatics , vol. 24, no. 8, pp. 2378–2388, 2020
work page 2020
-
[4]
Auto-Encoding Variational Bayes
D. P. Kingma, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[5]
Learning structured output represen- tation using deep conditional generative models,
K. Sohn, H. Lee, and X. Yan, “Learning structured output represen- tation using deep conditional generative models,” Advances in neural information processing systems , vol. 28, 2015
work page 2015
-
[6]
Explicitly minimizing the blur error of variational autoencoders,
G. Bredell, K. Flouris, K. Chaitanya, E. Erdil, and E. Konukoglu, “Explicitly minimizing the blur error of variational autoencoders,” arXiv preprint arXiv:2304.05939, 2023
-
[7]
Defining ‘good’: Evaluation framework for synthetic smart meter data,
S. Chai, G. Chadney, C. Avery, P. Grunewald, P. Van Hentenryck, and P. L. Donti, “Defining ‘good’: Evaluation framework for synthetic smart meter data,” arXiv preprint arXiv:2407.11785 , 2024
-
[8]
C. Sun, J. van Soest, and M. Dumontier, “Generating synthetic personal health data using conditional generative adversarial networks combining with differential privacy,” Journal of Biomedical Informatics , vol. 143, p. 104404, 2023
work page 2023
-
[9]
Deep learning based recommen- der system: A survey and new perspectives,
S. Zhang, L. Yao, A. Sun, and Y . Tay, “Deep learning based recommen- der system: A survey and new perspectives,” ACM computing surveys (CSUR), vol. 52, no. 1, pp. 1–38, 2019
work page 2019
-
[10]
Constructing dynamic residential energy lifestyles using latent dirichlet allocation,
X. Chen, C. Zanocco, J. Flora, and R. Rajagopal, “Constructing dynamic residential energy lifestyles using latent dirichlet allocation,” Applied Energy, vol. 318, p. 119109, 2022
work page 2022
-
[11]
Padpaf: Partial disentan- glement with partially-federated gans,
A. J. Almansoori, S. Horv ´ath, and M. Tak ´aˇc, “Padpaf: Partial disentan- glement with partially-federated gans,” 2022
work page 2022
-
[12]
D. M. Blei, A. Y . Ng, and M. I. Jordan, “Latent dirichlet allocation,” Journal of machine Learning research , vol. 3, no. Jan, pp. 993–1022, 2003
work page 2003
-
[13]
Decaf: Generating fair synthetic data using causally-aware generative networks,
B. Van Breugel, T. Kyono, J. Berrevoets, and M. Van der Schaar, “Decaf: Generating fair synthetic data using causally-aware generative networks,” Advances in Neural Information Processing Systems, vol. 34, pp. 22 221–22 233, 2021
work page 2021
-
[14]
Tabular data synthesis with gans for adaptive ai models,
S. Hans, A. Sanghi, and D. Saha, “Tabular data synthesis with gans for adaptive ai models,” in Proceedings of the 7th Joint International Conference on Data Science & Management of Data , 2024, pp. 242– 246
work page 2024
-
[15]
Structured uncertainty prediction networks,
G. Dorta, S. Vicente, L. Agapito, N. D. F. Campbell, and I. Simpson, “Structured uncertainty prediction networks,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , June 2018
work page 2018
-
[16]
Structured uncertainty in the observation space of variational autoen- coders,
J. Langley, M. Monteiro, C. Jones, N. Pawlowski, and B. Glocker, “Structured uncertainty in the observation space of variational autoen- coders,” Transactions on Machine Learning Research , 2022
work page 2022
-
[17]
Kernel mean embedding of distributions: A review and beyond,
K. Muandet, K. Fukumizu, B. Sriperumbudur, B. Sch ¨olkopf et al. , “Kernel mean embedding of distributions: A review and beyond,” Foundations and Trends® in Machine Learning , vol. 10, no. 1-2, pp. 1–141, 2017
work page 2017
-
[18]
An electricity smart meter dataset of spanish households: insights into consumption patterns,
C. Quesada, L. Astigarraga, C. Merveille, and C. E. Borges, “An electricity smart meter dataset of spanish households: insights into consumption patterns,” Scientific Data, vol. 11, no. 1, p. 59, 2024
work page 2024
-
[19]
Generating contextual load profiles using a conditional variational autoencoder,
C. Wang, S. H. Tindemans, and P. Palensky, “Generating contextual load profiles using a conditional variational autoencoder,” in 2022 IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT-Europe), 2022, pp. 1–6
work page 2022
-
[20]
Adam: A Method for Stochastic Optimization
D. P. Kingma, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014. APPENDIX A PROOFS Theorem 1. Any positive definite matrix can be constructed using PDCC at least in V (V − T ) + 1 different ways. Proof. Let M ∈ RT ×T be a positive definite matrix with eigenvalues λt > 0, ∀t. Then, the Cholesky decomposition of (M−ξI) resul...
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.