OrderDP: A Theoretically Guaranteed Lossless Dynamic Data Pruning Framework
Pith reviewed 2026-06-27 18:24 UTC · model grok-4.3
The pith
OrderDP achieves unbiased data pruning by first randomly selecting a subset then choosing the top-q samples on a surrogate loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
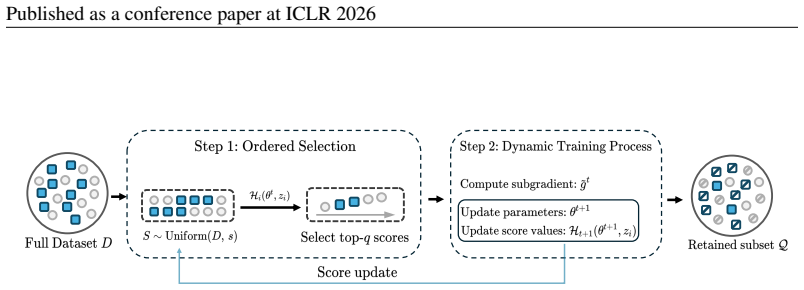
OrderDP first randomly selects a subset and then chooses the top-q samples, where unbiasedness is established with respect to a surrogate loss. This ensures that OrderDP conducts unbiased training in terms of the surrogate objective. Convergence and generalization analyses are further established to elucidate how OrderDP affects optimal performance and enables well-controlled acceleration while ensuring guaranteed final performance.
What carries the argument
Two-stage selection (random subset followed by top-q ranking) with unbiasedness proved relative to a surrogate loss.
If this is right
- Gradient estimates remain unbiased relative to the surrogate objective throughout training.
- Convergence to the surrogate optimum follows from the provided analyses.
- Generalization bounds quantify the effect of pruning on final performance.
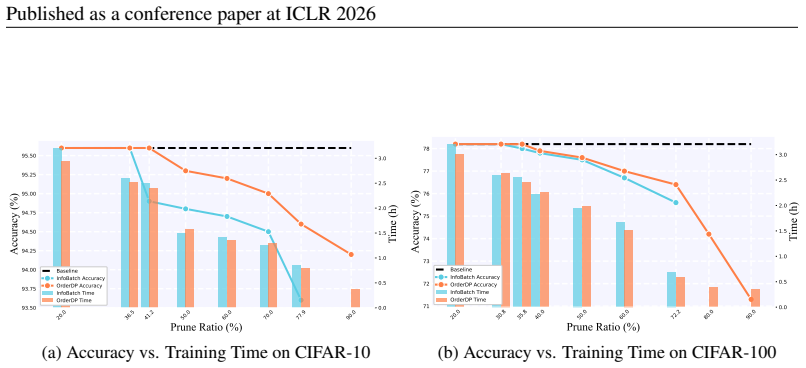
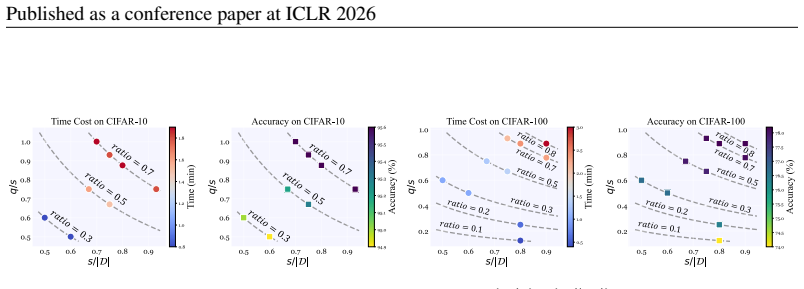
- Training cost reductions exceeding 40 percent are achieved with competitive accuracy on CIFAR-10, CIFAR-100, and ImageNet-1K.
- Exact control over acceleration is possible while preserving stable convergence.
Where Pith is reading between the lines
- The random-then-top-q structure could be reused with different ranking criteria while retaining the unbiasedness argument.
- The convergence and generalization results may guide choices of pruning fraction in new application domains.
- If a better surrogate can be identified for a given task, the same framework would directly improve the transfer of unbiasedness to the true objective.
Load-bearing premise
The surrogate loss used to prove unbiasedness is a sufficiently close proxy to the true training loss so that unbiasedness on the surrogate transfers to the original objective and final performance.
What would settle it
An experiment in which OrderDP-trained models show substantially lower final accuracy than full-dataset training on a task where the surrogate loss diverges from the primary loss.
Figures

read the original abstract
Data pruning (DP), as an oft-stated strategy to alleviate heavy training burdens, reduces the volume of training samples according to a well-defined pruning method while striving for near-lossless performance. However, existing approaches, which commonly select highly informative samples, can lead to biased gradient estimation compared to full-dataset training. Furthermore, the analysis of this bias and its impact on final performance remains ambiguous. To address these challenges, we propose OrderDP, a plug-and-play framework that aims to obtain stable, unbiased, and near-lossless training acceleration with theoretical guarantees. Specifically, OrderDP first randomly selects a subset and then chooses the top-$q$ samples, where unbiasedness is established with respect to a surrogate loss. This ensures that OrderDP conducts unbiased training in terms of the surrogate objective. We further establish convergence and generalization analyses, elucidating how OrderDP affects optimal performance and enables well-controlled acceleration while ensuring guaranteed final performance. Empirically, we evaluate OrderDP against comprehensive baselines on CIFAR-10, CIFAR-100, and ImageNet-1K, demonstrating competitive accuracy, stable convergence, and exact control -- all with a simpler design and faster runtime, while reducing training cost by over 40%. Delivering both strong performance and computational efficiency, our method serves as a robust and easily adaptable tool for data-efficient learning. The code is publicly available at https://github.com/shengze-xu/OrderDP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OrderDP, a plug-and-play dynamic data pruning framework. It first draws a random subset and then retains the top-q samples according to scores from a surrogate loss; unbiasedness of the resulting gradient estimator is proved with respect to this surrogate objective. Convergence and generalization bounds are derived to characterize the effect on optimal performance, and experiments on CIFAR-10/100 and ImageNet-1K report competitive accuracy, stable training, and >40% cost reduction relative to full-dataset baselines.
Significance. If the surrogate-to-true-loss transfer is rigorously controlled, the work supplies a theoretically grounded route to lossless acceleration that existing heuristic pruning methods lack. Public code and large-scale empirical results are explicit strengths.
major comments (2)
- [Abstract, §3] Abstract and §3 (method): unbiasedness is established only w.r.t. the surrogate loss; the manuscript does not supply a quantitative bound on |L_surrogate( heta) - L_true( heta)| that is absorbed into the convergence rate. Without such a bound the claim of 'theoretically guaranteed lossless' training on the original objective is unsupported.
- [§4] §4 (convergence analysis): the generalization bound is stated to 'elucidate how OrderDP affects optimal performance,' yet the derivation appears to inherit the surrogate unbiasedness directly; if the surrogate is not identical to the training loss, the rate does not necessarily control the true excess risk.
minor comments (2)
- [§3] Notation for the surrogate scoring function should be introduced once and used consistently; current presentation mixes 'surrogate loss' and 'scoring function' without an explicit definition equation.
- [Experiments] Empirical tables would benefit from reporting standard deviations over multiple random seeds to substantiate the 'stable convergence' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the theoretical scope of our guarantees. We address each major comment below and will revise the manuscript accordingly for clarity.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): unbiasedness is established only w.r.t. the surrogate loss; the manuscript does not supply a quantitative bound on |L_surrogate(θ) - L_true(θ)| that is absorbed into the convergence rate. Without such a bound the claim of 'theoretically guaranteed lossless' training on the original objective is unsupported.
Authors: We agree that the unbiasedness, convergence, and generalization results are established strictly with respect to the surrogate loss, as stated in Section 3. The title and abstract use 'lossless' to indicate that OrderDP introduces no bias relative to this surrogate objective (thereby preserving its optimization path), with empirical results showing near-lossless transfer to the true loss. However, the manuscript does not derive an explicit bound on |L_surrogate(θ) - L_true(θ)| or absorb it into the rates. We will revise the abstract, introduction, and Section 4 to explicitly qualify all theoretical claims as surrogate-relative, add a discussion of surrogate choice to control the gap, and note that stronger transfer bounds would require additional assumptions on the surrogate. This revision will be made. revision: yes
-
Referee: [§4] §4 (convergence analysis): the generalization bound is stated to 'elucidate how OrderDP affects optimal performance,' yet the derivation appears to inherit the surrogate unbiasedness directly; if the surrogate is not identical to the training loss, the rate does not necessarily control the true excess risk.
Authors: The generalization bound in Section 4 is derived under the surrogate objective precisely to characterize the effect of pruning on excess risk relative to that objective, leveraging the established unbiasedness. We acknowledge that this does not automatically control true excess risk without controlling the surrogate-true gap. In the revision we will add an explicit remark in Section 4 clarifying the scope of the bound, reiterate that it elucidates surrogate-level effects, and reference the empirical validation on the true task (CIFAR/ImageNet results) as evidence of practical transfer. This addresses the concern directly. revision: yes
Circularity Check
No circularity; derivation builds on independent surrogate unbiasedness and separate analyses
full rationale
The provided abstract and description establish unbiasedness of the random-subset + top-q selection with respect to an explicitly introduced surrogate loss, followed by separate convergence and generalization results. No quoted step reduces a claimed prediction or guarantee to a fitted parameter or self-citation by construction; the surrogate is presented as a distinct proxy rather than defined via the final performance metric. The central claims therefore remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural Computation , volume=
Four types of learning curves , author=. Neural Computation , volume=. 1992 , publisher=
1992
-
[5]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Reproducible scaling laws for contrastive language-image learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[6]
Advances in Neural Information Processing Systems , volume=
Uncovering neural scaling laws in molecular representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
ICML , pages=
Crafting papers on machine learning , author=. ICML , pages=
-
[8]
1980 , publisher=
The need for biases in learning generalizations , author=. 1980 , publisher=
1980
-
[9]
1990 , publisher=
The computational complexity of machine learning , author=. 1990 , publisher=
1990
-
[10]
2013 , publisher=
Machine learning: An artificial intelligence approach , author=. 2013 , publisher=
2013
-
[11]
2006 , publisher=
Pattern classification , author=. 2006 , publisher=
2006
-
[12]
Suppressed for Anonymity , author=
-
[13]
Cognitive skills and their acquisition , pages=
Mechanisms of skill acquisition and the law of practice , author=. Cognitive skills and their acquisition , pages=. 2013 , publisher=
2013
-
[14]
IBM Journal of research and development , volume=
Some studies in machine learning using the game of checkers , author=. IBM Journal of research and development , volume=. 1959 , publisher=
1959
-
[15]
The Twelfth International Conference on Learning Representations , year=
InfoBatch: Lossless Training Speed Up by Unbiased Dynamic Data Pruning , author=. The Twelfth International Conference on Learning Representations , year=
-
[16]
ECCV , pages=
Contextual diversity for active learning , author=. ECCV , pages=. 2020 , organization=
2020
-
[17]
ICMLg , pages=
Herding dynamical weights to learn , author=. ICMLg , pages=
-
[18]
ICLR , year=
Active Learning for Convolutional Neural Networks: A Core-Set Approach , author=. ICLR , year=
-
[19]
ICLR , year=
Selection via Proxy: Efficient Data Selection for Deep Learning , author=. ICLR , year=
-
[21]
Advances in neural information processing systems , volume=
Deep learning on a data diet: Finding important examples early in training , author=. Advances in neural information processing systems , volume=
-
[22]
The Eleventh International Conference on Learning Representations , year=
Dataset Pruning: Reducing Training Data by Examining Generalization Influence , author=. The Eleventh International Conference on Learning Representations , year=
-
[23]
Accelerating Deep Learning with Dynamic Data Pruning , publisher =
Raju, Ravi S and Daruwalla, Kyle and Lipasti, Mikko , keywords =. Accelerating Deep Learning with Dynamic Data Pruning , publisher =
-
[25]
ICML , year=
Coresets for data-efficient training of machine learning models , author=. ICML , year=
-
[26]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
GLISTER: Generalization based Data Subset Selection for Efficient and Robust Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[27]
Proceedings of the 34th International Conference on Machine Learning-Volume 70 , pages=
Understanding black-box predictions via influence functions , author=. Proceedings of the 34th International Conference on Machine Learning-Volume 70 , pages=. 2017 , organization=
2017
-
[28]
International Conference on Artificial Intelligence and Statistics , pages=
Stochastic optimization for spectral risk measures , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
2023
-
[29]
Neurocomputing , volume=
Backpropagation and stochastic gradient descent method , author=. Neurocomputing , volume=. 1993 , publisher=
1993
-
[30]
International Conference on Artificial Intelligence and Statistics , pages=
Ordered sgd: A new stochastic optimization framework for empirical risk minimization , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[31]
Advances in Neural Information Processing Systems , volume=
Beyond neural scaling laws: beating power law scaling via data pruning , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Advances in neural information processing systems , volume=
Coresets via bilevel optimization for continual learning and streaming , author=. Advances in neural information processing systems , volume=
-
[34]
arXiv preprint arXiv:1708.00489 , year=
Active learning for convolutional neural networks: A core-set approach , author=. arXiv preprint arXiv:1708.00489 , year=
-
[35]
Advances in neural information processing systems , volume=
Coresets for scalable Bayesian logistic regression , author=. Advances in neural information processing systems , volume=
-
[36]
Journal of Machine Learning Research , volume=
Automated scalable Bayesian inference via Hilbert coresets , author=. Journal of Machine Learning Research , volume=
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Coreset sampling from open-set for fine-grained self-supervised learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
Advances in Neural Information Processing Systems , volume=
Beyond efficiency: Molecular data pruning for enhanced generalization , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Journal of banking & finance , volume=
On the coherence of expected shortfall , author=. Journal of banking & finance , volume=. 2002 , publisher=
2002
-
[40]
CIFAR-10 (Canadian Institute for Advanced Research) , journal=
Alex Krizhevsky and Vinod Nair and Geoffrey Hinton , year=. CIFAR-10 (Canadian Institute for Advanced Research) , journal=
-
[41]
CIFAR-100 (Canadian Institute for Advanced Research) , journal=
Alex Krizhevsky and Vinod Nair and Geoffrey Hinton , year=. CIFAR-100 (Canadian Institute for Advanced Research) , journal=
-
[42]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[43]
Proceedings of Neuro-N
Stochastic gradient learning in neural networks , author=. Proceedings of Neuro-N. 1991 , publisher=
1991
-
[44]
Adam: A Method for Stochastic Optimization
Kingma, Diederik P. and Ba, Jimmy , keywords =. Adam: A Method for Stochastic Optimization , publisher =. 2014 , copyright =. doi:10.48550/ARXIV.1412.6980 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6980 2014
-
[45]
2019 , eprint=
Decoupled Weight Decay Regularization , author=. 2019 , eprint=
2019
-
[46]
Large Batch Training of Convolutional Networks
You, Yang and Gitman, Igor and Ginsburg, Boris , keywords =. Large Batch Training of Convolutional Networks , publisher =. 2017 , copyright =. doi:10.48550/ARXIV.1708.03888 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1708.03888 2017
-
[47]
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
You, Yang and Li, Jing and Reddi, Sashank and Hseu, Jonathan and Kumar, Sanjiv and Bhojanapalli, Srinadh and Song, Xiaodan and Demmel, James and Keutzer, Kurt and Hsieh, Cho-Jui , keywords =. Large Batch Optimization for Deep Learning: Training BERT in 76 minutes , publisher =. 2019 , copyright =. doi:10.48550/ARXIV.1904.00962 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1904.00962 2019
-
[48]
International conference on machine learning , pages=
Penalizing gradient norm for efficiently improving generalization in deep learning , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[49]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Gradient norm aware minimization seeks first-order flatness and improves generalization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[50]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[51]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[53]
International Conference on Artificial Intelligence and Statistics , pages=
Choosing the sample with lowest loss makes sgd robust , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[55]
Algorithmic Learning Theory , pages=
Submodular combinatorial information measures with applications in machine learning , author=. Algorithmic Learning Theory , pages=. 2021 , organization=
2021
-
[56]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Large-scale dataset pruning with dynamic uncertainty , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[61]
Advances in Neural Information Processing Systems , volume=
Doremi: Optimizing data mixtures speeds up language model pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
Advances in Neural Information Processing Systems , volume=
Active bias: Training more accurate neural networks by emphasizing high variance samples , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
Advances in neural information processing systems , volume=
Data pruning via moving-one-sample-out , author=. Advances in neural information processing systems , volume=
-
[64]
International Conference on Machine Learning , pages=
Grad-match: Gradient matching based data subset selection for efficient deep model training , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[67]
2021 , eprint=
ResNet strikes back: An improved training procedure in timm , author=. 2021 , eprint=
2021
-
[68]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[69]
2021 , eprint=
Masked Autoencoders Are Scalable Vision Learners , author=. 2021 , eprint=
2021
-
[70]
2017 , eprint=
Random Erasing Data Augmentation , author=. 2017 , eprint=
2017
-
[71]
2018 , eprint=
mixup: Beyond Empirical Risk Minimization , author=. 2018 , eprint=
2018
-
[72]
2019 , eprint=
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features , author=. 2019 , eprint=
2019
-
[73]
The Twelfth International Conference on Learning Representations , year=
Repeated Random Sampling for Minimizing the Time-to-Accuracy of Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[75]
On the coherence of expected shortfall
Carlo Acerbi and Dirk Tasche. On the coherence of expected shortfall. Journal of banking & finance, 26 0 (7): 0 1487--1503, 2002
2002
-
[76]
Contextual diversity for active learning
Sharat Agarwal, Himanshu Arora, Saket Anand, and Chetan Arora. Contextual diversity for active learning. In ECCV, pp.\ 137--153. Springer, 2020
2020
-
[77]
Backpropagation and stochastic gradient descent method
Shun-ichi Amari. Backpropagation and stochastic gradient descent method. Neurocomputing, 5 0 (4-5): 0 185--196, 1993
1993
-
[78]
Four types of learning curves
Shun-ichi Amari, Naotake Fujita, and Shigeru Shinomoto. Four types of learning curves. Neural Computation, 4 0 (4): 0 605--618, 1992
1992
-
[79]
Data pruning and neural scaling laws: fundamental limitations of score-based algorithms
Fadhel Ayed and Soufiane Hayou. Data pruning and neural scaling laws: fundamental limitations of score-based algorithms. arXiv preprint arXiv:2302.06960, 2023
arXiv 2023
-
[80]
Coresets via bilevel optimization for continual learning and streaming
Zal \'a n Borsos, Mojmir Mutny, and Andreas Krause. Coresets via bilevel optimization for continual learning and streaming. Advances in neural information processing systems, 33: 0 14879--14890, 2020
2020
-
[81]
Stochastic gradient learning in neural networks
L \'e on Bottou et al. Stochastic gradient learning in neural networks. Proceedings of Neuro-N mes , 91 0 (8): 0 12, 1991
1991
-
[82]
Automated scalable bayesian inference via hilbert coresets
Trevor Campbell and Tamara Broderick. Automated scalable bayesian inference via hilbert coresets. Journal of Machine Learning Research, 20 0 (15): 0 1--38, 2019
2019
-
[83]
Instruction mining: Instruction data selection for tuning large language models
Yihan Cao, Yanbin Kang, Chi Wang, and Lichao Sun. Instruction mining: Instruction data selection for tuning large language models. arXiv preprint arXiv:2307.06290, 2023
arXiv 2023
-
[84]
Active bias: Training more accurate neural networks by emphasizing high variance samples
Haw-Shiuan Chang, Erik Learned-Miller, and Andrew McCallum. Active bias: Training more accurate neural networks by emphasizing high variance samples. Advances in Neural Information Processing Systems, 30, 2017
2017
-
[85]
Uncovering neural scaling laws in molecular representation learning
Dingshuo Chen, Yanqiao Zhu, Jieyu Zhang, Yuanqi Du, Zhixun Li, Qiang Liu, Shu Wu, and Liang Wang. Uncovering neural scaling laws in molecular representation learning. Advances in Neural Information Processing Systems, 36: 0 1452--1475, 2023
2023
-
[86]
Beyond efficiency: Molecular data pruning for enhanced generalization
Dingshuo Chen, Zhixun Li, Yuyan Ni, Guibin Zhang, Ding Wang, Qiang Liu, Shu Wu, Jeffrey Yu, and Liang Wang. Beyond efficiency: Molecular data pruning for enhanced generalization. Advances in Neural Information Processing Systems, 37: 0 18036--18061, 2024
2024
-
[87]
Reproducible scaling laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 2818--2829, 2023
2023
-
[88]
Selection via proxy: Efficient data selection for deep learning
Cody Coleman, Christopher Yeh, Stephen Mussmann, Baharan Mirzasoleiman, Peter Bailis, Percy Liang, Jure Leskovec, and Matei Zaharia. Selection via proxy: Efficient data selection for deep learning. In ICLR, 2019
2019
-
[89]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp.\ 248--255. Ieee, 2009
2009
-
[90]
Adversarial active learning for deep networks: a margin based approach
Melanie Ducoffe and Frederic Precioso. Adversarial active learning for deep networks: a margin based approach. arXiv preprint arXiv:1802.09841, 2018
Pith/arXiv arXiv 2018
-
[91]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 770--778, 2016
2016
-
[92]
Masked autoencoders are scalable vision learners, 2021
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners, 2021
2021
-
[93]
Large-scale dataset pruning with dynamic uncertainty
Muyang He, Shuo Yang, Tiejun Huang, and Bo Zhao. Large-scale dataset pruning with dynamic uncertainty. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 7713--7722, 2024
2024
-
[94]
Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. Scaling laws for transfer. arXiv preprint arXiv:2102.01293, 2021
Pith/arXiv arXiv 2021
-
[95]
Deep learning scaling is predictable, empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.