DFM: Difference Feature Modeling with Text-Guided Gated Contrastive Loss for Remote Sensing Image Change Captioning
Pith reviewed 2026-06-29 01:19 UTC · model grok-4.3
The pith
Text-guided gated contrastive loss directs the vision encoder to extract critical change features for remote sensing image captioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
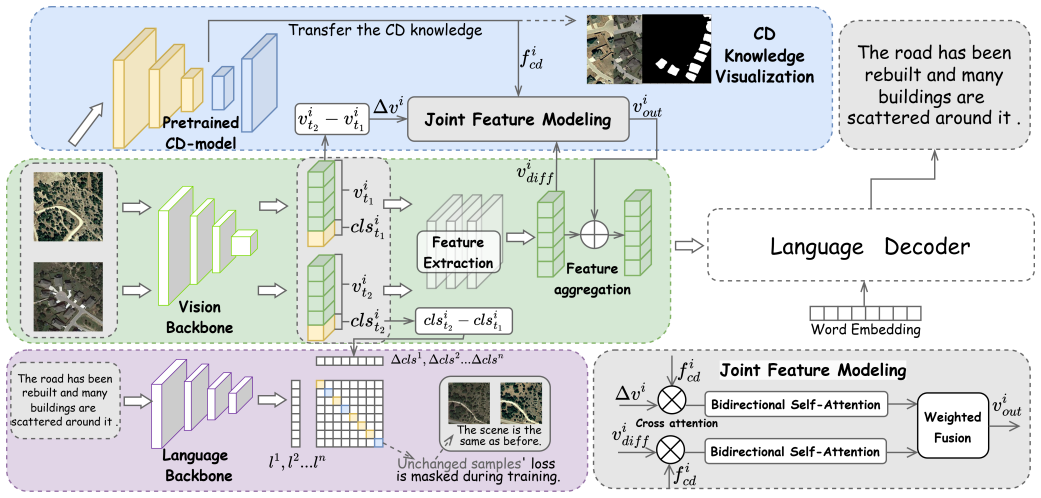
The DFM framework with TGCL and JFM improves RSICC performance by guiding the vision encoder to extract critical features from a text-modal perspective and capturing comprehensive spatiotemporal variations between multi-temporal images.
What carries the argument
Text-guided Gated Contrastive Loss (TGCL) that transfers guidance from text to vision encoder, plus Joint Feature Modeling (JFM) that fuses multi-scale difference representations.
If this is right
- The vision encoder learns to prioritize discriminative spatiotemporal changes over easily generated words.
- Multi-scale difference representations are fused to produce more complete descriptions of image pairs.
- Stable change detection knowledge from a pre-trained model transfers into the captioning task without retraining from scratch.
- The overall system generates captions that more accurately reflect actual changes between remote sensing images taken at different times.
Where Pith is reading between the lines
- The gated contrastive mechanism could be tested in other vision-language generation tasks where text must steer feature extraction without overpowering the main decoder.
- If the approach holds, it suggests a general pattern for injecting auxiliary modality signals into encoders for remote sensing tasks beyond captioning, such as change detection itself.
- Deployment on streaming satellite data would test whether the added losses remain stable when image pairs arrive with varying time gaps or sensor differences.
Load-bearing premise
The text-guided gated contrastive loss successfully transfers useful guidance from the text modality to the vision encoder without the pre-trained change detection model introducing domain mismatch or the contrastive objective dominating the autoregressive generation objective.
What would settle it
Running the proposed TGCL and JFM additions on standard RSICC benchmarks and finding no gain (or a drop) in standard caption metrics such as BLEU, METEOR, or CIDEr compared with the autoregressive baseline would falsify the central claim.
Figures


read the original abstract
The primary goal of Remote Sensing Image Change Captioning (RSICC) is to automatically generate descriptions of changes between remote sensing images captured at different time points. Existing models still rely on a single autoregressive generation paradigm, which tends to prioritize learning easily generated vocabulary over capturing discriminative differences between images. To address this, we reframe the training paradigm and propose a novel Difference Feature Modeling (DFM) framework. Specifically, we introduce a Text-guided Gated Contrastive Loss (TGCL) to guide the vision encoder to extract critical features from a text-modal perspective. Additionally, we incorporate a pre-trained Change Detection model to transfer stable change detection knowledge. In order to further enhance the representation, we design a Joint Feature Modeling (JFM) module to achieve the fusion of multi-scale difference representations, thereby capturing comprehensive spatiotemporal variations between multi-temporal images. Extensive experiments on multiple datasets demonstrate the effectiveness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Difference Feature Modeling (DFM) framework for Remote Sensing Image Change Captioning (RSICC). It reframes training away from a single autoregressive paradigm by introducing a Text-guided Gated Contrastive Loss (TGCL) to guide the vision encoder from a text-modal perspective, incorporating a pre-trained change detection model to transfer stable knowledge, and designing a Joint Feature Modeling (JFM) module to fuse multi-scale difference representations for capturing spatiotemporal variations. The authors state that extensive experiments on multiple datasets demonstrate the effectiveness of the approach.
Significance. If the performance gains hold under detailed validation, the work would be moderately significant for RSICC by targeting the tendency of autoregressive models to favor easily generated vocabulary over discriminative change features. The combination of gated contrastive guidance and pre-trained CD knowledge transfer offers a concrete mechanism for multi-modal feature enhancement, though its impact depends on resolving the unaddressed transfer and optimization issues.
major comments (2)
- [Abstract] Abstract: the central claim that TGCL transfers useful text-modal guidance to the vision encoder while the pre-trained change detection model supplies stable knowledge without domain mismatch is unsupported; no analysis addresses how features from a pre-trained CD model align with target RSICC datasets that vary by sensor, resolution, and acquisition conditions.
- [Abstract] Abstract (description of joint optimization): the manuscript provides no weighting analysis, loss-component monitoring, or ablation showing that the contrastive TGCL term does not dominate the autoregressive generation objective; without this, it remains possible that any reported gains derive from the standard captioning path alone.
minor comments (1)
- [Abstract] Abstract: dataset names, quantitative metrics, and baseline comparisons are omitted, which would strengthen the claim of effectiveness even at the summary level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that TGCL transfers useful text-modal guidance to the vision encoder while the pre-trained change detection model supplies stable knowledge without domain mismatch is unsupported; no analysis addresses how features from a pre-trained CD model align with target RSICC datasets that vary by sensor, resolution, and acquisition conditions.
Authors: We agree that the abstract's claims regarding the transfer of text-modal guidance via TGCL and stable knowledge from the pre-trained change detection model would benefit from explicit support. Although the experimental results on multiple datasets with varying conditions indirectly demonstrate the effectiveness, we will revise the manuscript to include an analysis of feature alignment, such as cosine similarity measures or visualization of feature distributions across different sensors and resolutions, to substantiate the lack of domain mismatch. revision: yes
-
Referee: [Abstract] Abstract (description of joint optimization): the manuscript provides no weighting analysis, loss-component monitoring, or ablation showing that the contrastive TGCL term does not dominate the autoregressive generation objective; without this, it remains possible that any reported gains derive from the standard captioning path alone.
Authors: We acknowledge the importance of verifying that the TGCL term contributes meaningfully without dominating the autoregressive loss. In the revised version, we will include loss component monitoring during training, an analysis of different weighting schemes for the TGCL term, and additional ablations isolating the effect of TGCL to confirm that the performance improvements stem from the proposed guidance rather than the base captioning objective alone. revision: yes
Circularity Check
No circularity: framework described at high level with empirical validation only
full rationale
The provided manuscript text contains no equations, derivations, or mathematical claims that could reduce to self-definition or fitted inputs. The DFM framework, TGCL, and JFM are introduced as architectural choices whose effectiveness is asserted via experiments on multiple datasets rather than any internal prediction that collapses to the inputs by construction. No self-citations appear in the abstract or description that serve as load-bearing justification for uniqueness or ansatz. The central claim therefore remains self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rscama: Remote sensing image change captioning with state space model,
Chenyang Liu et al., “Rscama: Remote sensing image change captioning with state space model,”IEEE Geoscience and Remote Sensing Letters, 2024
2024
-
[2]
A decoupling paradigm with prompt learning for remote sensing image change captioning,
Chenyang Liu et al., “A decoupling paradigm with prompt learning for remote sensing image change captioning,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–18, 2023
2023
-
[3]
Pixel-level change detection pseudo-label learning for remote sensing change captioning,
Chenyang Liu et al., “Pixel-level change detection pseudo-label learning for remote sensing change captioning,” inIGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2024, pp. 8405–8408
2024
-
[4]
High-fidelity lake extraction via two-stage prompt enhancement: Establishing a novel baseline and benchmark,
Ben Chen et al., “High-fidelity lake extraction via two-stage prompt enhancement: Establishing a novel baseline and benchmark,” in2024 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2024, pp. 1–6
2024
-
[5]
Change detection based on deep siamese convolu- tional network for optical aerial images,
Yang Zhan et al., “Change detection based on deep siamese convolu- tional network for optical aerial images,”IEEE Geoscience and Remote Sensing Letters, vol. 14, no. 10, pp. 1845–1849, 2017
2017
-
[6]
A deep convolutional coupling network for change detection based on heterogeneous optical and radar images,
Jia Liu et al., “A deep convolutional coupling network for change detection based on heterogeneous optical and radar images,”IEEE transactions on neural networks and learning systems, vol. 29, no. 3, pp. 545–559, 2016
2016
-
[7]
Toward generalized change detection on planetary surfaces with convolutional autoencoders and transfer learn- ing,
Hannah Rae Kerner et al., “Toward generalized change detection on planetary surfaces with convolutional autoencoders and transfer learn- ing,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 12, no. 10, pp. 3900–3918, 2019
2019
-
[8]
Multispectral change detection with bilinear convolu- tional neural networks,
Yun Lin et al., “Multispectral change detection with bilinear convolu- tional neural networks,”IEEE Geoscience and Remote Sensing Letters, vol. 17, no. 10, pp. 1757–1761, 2019
2019
-
[9]
Change detection in synthetic aperture radar images based on deep neural networks,
Maoguo Gong et al., “Change detection in synthetic aperture radar images based on deep neural networks,”IEEE transactions on neural networks and learning systems, vol. 27, no. 1, pp. 125–138, 2015
2015
-
[10]
Captioning changes in bi-temporal remote sensing images,
Seloua Chouaf et al., “Captioning changes in bi-temporal remote sensing images,” in2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS. IEEE, 2021, pp. 2891–2894
2021
-
[11]
Change captioning: A new paradigm for multitem- poral remote sensing image analysis,
Genc Hoxha et al., “Change captioning: A new paradigm for multitem- poral remote sensing image analysis,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2022
2022
-
[12]
Proximal remote sensing: an essential tool for bridging the gap between high-resolution ecosystem monitoring and global ecology,
Zoe Amie Pierrat et al., “Proximal remote sensing: an essential tool for bridging the gap between high-resolution ecosystem monitoring and global ecology,”New Phytologist, 2025
2025
-
[13]
Remote sensing in forestry: current challenges, considerations and directions,
Fabian Ewald Fassnacht et al., “Remote sensing in forestry: current challenges, considerations and directions,”F orestry: An International Journal of F orest Research, vol. 97, no. 1, pp. 11–37, 2024
2024
-
[14]
Remote sensing for agriculture in the era of industry 5.0–a survey,
Nancy Victor et al., “Remote sensing for agriculture in the era of industry 5.0–a survey,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024
2024
-
[15]
Progressive scale-aware network for remote sens- ing image change captioning,
Chenyang Liu et al., “Progressive scale-aware network for remote sens- ing image change captioning,” inIGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2023, pp. 6668– 6671
2023
-
[16]
Rsmamba: Remote sensing image classification with state space model,
Keyan Chen et al., “Rsmamba: Remote sensing image classification with state space model,”IEEE Geoscience and Remote Sensing Letters, 2024
2024
-
[17]
Change detection methods for remote sensing in the last decade: A comprehensive review,
Guangliang Cheng et al., “Change detection methods for remote sensing in the last decade: A comprehensive review,”Remote Sensing, vol. 16, no. 13, pp. 2355, 2024
2024
-
[18]
Advances and challenges in deep learning-based change detection for remote sensing images: A review through various learning paradigms,
Lukang Wang et al., “Advances and challenges in deep learning-based change detection for remote sensing images: A review through various learning paradigms,”Remote Sensing, vol. 16, no. 5, pp. 804, 2024
2024
-
[19]
Changeclip: Remote sensing change detection with multimodal vision-language representation learning,
Sijun Dong et al., “Changeclip: Remote sensing change detection with multimodal vision-language representation learning,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 208, pp. 53–69, 2024
2024
-
[20]
A novel approach to unsupervised change detection based on a semisupervised svm and a similarity measure,
Francesca Bovolo et al., “A novel approach to unsupervised change detection based on a semisupervised svm and a similarity measure,” IEEE transactions on geoscience and remote sensing, vol. 46, no. 7, pp. 2070–2082, 2008
2070
-
[21]
Fusion of sar and multispectral images using random forest regression for change detection,
Dae Kyo Seo et al., “Fusion of sar and multispectral images using random forest regression for change detection,”ISPRS International Journal of Geo-Information, vol. 7, no. 10, pp. 401, 2018
2018
-
[22]
Learning relationship for very high resolution image change detection,
Chunlei Huo et al., “Learning relationship for very high resolution image change detection,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 9, no. 8, pp. 3384–3394, 2016
2016
-
[23]
Sar image change detection based on hybrid condi- tional random field,
Hejing Li et al., “Sar image change detection based on hybrid condi- tional random field,”IEEE Geoscience and Remote Sensing Letters, vol. 12, no. 4, pp. 910–914, 2014
2014
-
[24]
Attention is all you need,
Ashish Vaswani et al., “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[25]
Attention-based spatial and spectral network with pca-guided self-supervised feature extraction for change detection in hyperspectral images,
Zhao Wang et al., “Attention-based spatial and spectral network with pca-guided self-supervised feature extraction for change detection in hyperspectral images,”Remote Sensing, vol. 13, no. 23, pp. 4927, 2021
2021
-
[26]
Transunetcd: A hybrid transformer network for change detection in optical remote-sensing images,
Qingyang Li et al., “Transunetcd: A hybrid transformer network for change detection in optical remote-sensing images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–19, 2022
2022
-
[27]
Cdformer: A hyperspectral image change detection method based on transformer encoders,
Jigang Ding et al., “Cdformer: A hyperspectral image change detection method based on transformer encoders,”IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022
2022
-
[28]
Diffusion models beat gans on image synthesis,
Prafulla Dhariwal et al., “Diffusion models beat gans on image synthesis,”Advances in neural information processing systems, vol. 34, pp. 8780–8794, 2021
2021
-
[29]
Changemamba: Remote sensing change detection with spatio-temporal state space model,
Hongruixuan Chen et al., “Changemamba: Remote sensing change detection with spatio-temporal state space model,”IEEE Transactions on Geoscience and Remote Sensing, 2024
2024
-
[30]
Vmamba: Visual state space model,
Yue Liu et al., “Vmamba: Visual state space model,”Advances in neural information processing systems, vol. 37, pp. 103031–103063, 2025
2025
-
[32]
Robust change captioning,
Dong Huk Park et al., “Robust change captioning,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[33]
Describing and localizing multiple changes with trans- formers,
Yue Qiu et al., “Describing and localizing multiple changes with trans- formers,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 1971–1980
2021
-
[34]
Remote sensing image change captioning with dual-branch transformers: A new method and a large scale dataset,
Chenyang Liu et al., “Remote sensing image change captioning with dual-branch transformers: A new method and a large scale dataset,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1– 20, 2022
2022
-
[35]
All-mpnet at semeval-2024 task 1: Application of mpnet for evaluating semantic textual relatedness,
Marco Siino, “All-mpnet at semeval-2024 task 1: Application of mpnet for evaluating semantic textual relatedness,” inProceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), 2024, pp. 379–384
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.