ForeSci: Evaluating LLM Agents for Forward-Looking AI Research Judgment
Pith reviewed 2026-06-28 18:44 UTC · model grok-4.3
The pith
ForeSci creates a benchmark with 500 temporally controlled tasks to test whether LLM agents can make forward-looking AI research judgments from historical evidence alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
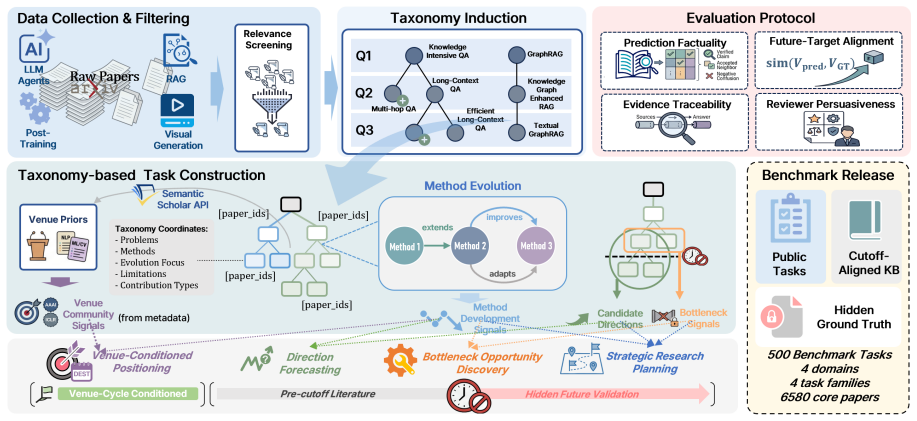
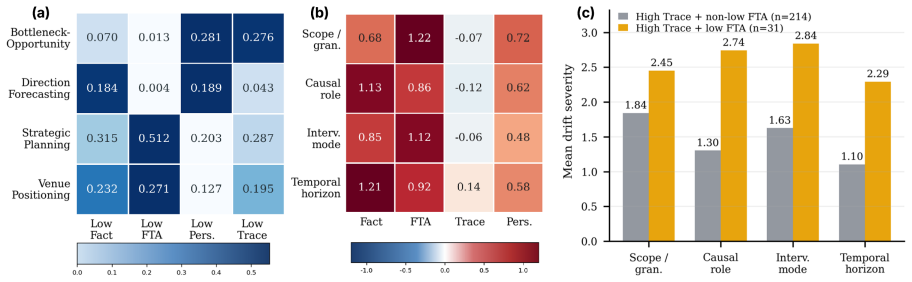
ForeSci consists of 500 tasks across four fast-moving AI domains and four decision families. Each task is paired with a cutoff-aligned offline knowledge base from which post-cutoff papers are removed during generation and retained only for validation. Tasks are built exclusively from pre-cutoff taxonomy branches and evidence signals, and answer-generation backbones are chosen to precede the task cutoffs, preventing random future-event prediction. When native LLMs, Hybrid RAG, and three research-agent adaptations are tested on four backbones, explicit evidence organization raises traceability and factual support, yet performance gains vary sharply by decision family and a recurring evidence-d
What carries the argument
The ForeSci benchmark, which pairs each forward-looking research task with a cutoff-aligned offline knowledge base and pre-cutoff task derivations to isolate judgment from future information.
If this is right
- Explicit evidence organization improves traceability and factual support when agents perform research judgments.
- Performance improvements from evidence organization depend on the specific decision family being tested.
- Agents can cite relevant evidence while still selecting the wrong research target, indicating a systematic decoupling.
- Native LLMs, retrieval-augmented hybrids, and agent adaptations become directly comparable on the same set of forward-looking tasks.
Where Pith is reading between the lines
- The benchmark format could be adapted to test foresight in other fast-moving fields such as materials discovery or clinical trial design.
- Training loops that reward both evidence citation and correct target selection might reduce the observed decoupling.
- Domain-level performance differences could identify which areas of AI research are inherently harder to anticipate from past signals.
- Periodic re-running of the benchmark with new cutoffs would track whether agent capabilities improve over calendar time.
Load-bearing premise
That tasks derived only from information available before a chosen date can isolate the skill of judging future research directions without turning the test into either data leakage or random future prediction.
What would settle it
A result in which the same agents that score well on ForeSci tasks make research-direction predictions after the cutoff that match actual subsequent outcomes no better than random selection.
Figures


read the original abstract
AI research often requires decisions before future evidence exists: which bottleneck to attack, which direction to pursue, or where a project should be positioned. We introduce ForeSci, a temporally controlled benchmark for evaluating whether LLM agents can make such forward-looking research judgements from historical evidence. ForeSci contains 500 tasks across four fast-moving AI domains and four decision families. Each task is paired with a cutoff-aligned offline knowledge base; post-cutoff papers are hidden during generation and used only for validation. To avoid random future-event prediction, tasks are derived from pre-cutoff taxonomy branches and evidence signals, and answer-generation backbones are selected to precede the task cutoffs. We evaluate native LLMs, Hybrid RAG, and three research-agent adaptations across four backbones. Results show that explicit evidence organization improves traceability and factual support, but gains depend strongly on the decision family. Diagnostics reveal a recurring evidence-decision decoupling: agents may cite relevant evidence while forecasting the wrong research object. ForeSci turns forward-looking AI research judgement into a controlled benchmark for evaluating research agents as decision-making systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ForeSci, a temporally controlled benchmark for evaluating LLM agents on forward-looking AI research judgments. It contains 500 tasks across four fast-moving AI domains and four decision families. Each task uses a cutoff-aligned offline knowledge base where post-cutoff papers are hidden during generation and used only for validation. Tasks are derived from pre-cutoff taxonomy branches and evidence signals with answer-generation backbones preceding cutoffs to avoid future-event prediction. Evaluations of native LLMs, Hybrid RAG, and three research-agent adaptations show that explicit evidence organization improves traceability and factual support depending on the decision family, and reveal evidence-decision decoupling.
Significance. If the temporal controls successfully prevent data leakage and isolate forward-looking judgment, ForeSci would offer a novel, controlled benchmark for assessing research agents as decision-making systems. This addresses an important gap in evaluating AI systems on decisions that must precede future evidence, and the diagnostics on evidence-decision decoupling could guide future agent improvements. The use of hidden post-cutoff papers for validation is a strength if the no-leakage premise holds.
major comments (2)
- [Abstract (task construction)] Abstract (task construction): The central claim that the benchmark isolates forward-looking judgment relies on the assumption that evaluated LLMs have no parametric knowledge of post-cutoff papers. However, the manuscript provides no verification that the models' training data cutoffs precede the task cutoffs, despite modern LLMs often having training data extending past 2023. This is load-bearing for the validity of the controlled evaluation.
- [Abstract (results)] Abstract (results): The abstract summarizes results on improvements from evidence organization and dependence on decision family but does not include any quantitative metrics, statistical analysis, or specific performance numbers. Without these, it is difficult to evaluate the strength of the claims about gains depending on decision family.
minor comments (2)
- [Abstract] Abstract: The four decision families are mentioned but not defined or exemplified, which reduces clarity for readers.
- [Abstract] Abstract: The phrase 'three research-agent adaptations across four backbones' is ambiguous without further specification of what the adaptations and backbones are.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on ForeSci. The feedback highlights important aspects of the temporal controls and abstract presentation. We respond point by point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract (task construction)] The central claim that the benchmark isolates forward-looking judgment relies on the assumption that evaluated LLMs have no parametric knowledge of post-cutoff papers. However, the manuscript provides no verification that the models' training data cutoffs precede the task cutoffs, despite modern LLMs often having training data extending past 2023. This is load-bearing for the validity of the controlled evaluation.
Authors: We agree that explicit verification of model training cutoffs is necessary to support the no-leakage claim. In the revised manuscript we will add a dedicated subsection listing the publicly documented training cutoffs for each evaluated model (sourced from model cards and technical reports) and compare them directly against the task cutoffs used in ForeSci. Where alignment is imperfect we will note the limitation and, where feasible, report supplementary results restricted to models with earlier cutoffs. This revision directly addresses the load-bearing assumption without changing the benchmark construction. revision: yes
-
Referee: [Abstract (results)] The abstract summarizes results on improvements from evidence organization and dependence on decision family but does not include any quantitative metrics, statistical analysis, or specific performance numbers. Without these, it is difficult to evaluate the strength of the claims about gains depending on decision family.
Authors: We accept that the absence of concrete numbers weakens the abstract. The revised abstract will include the main quantitative findings, such as the accuracy deltas observed when adding explicit evidence organization across the four decision families, together with a brief statement on statistical significance. These additions will be kept concise while conveying the magnitude and decision-family dependence of the reported effects. revision: yes
Circularity Check
No circularity: benchmark construction is externally grounded in temporal cutoffs and hidden validation papers
full rationale
The paper introduces ForeSci as a new benchmark whose tasks are constructed from pre-cutoff taxonomy branches and evidence signals, with post-cutoff papers explicitly hidden during task generation and reserved solely for validation. No derivation step reduces to a fitted parameter renamed as prediction, no self-citation chain is invoked to justify uniqueness or ansatz choices, and no equation or definition is shown to be equivalent to its own inputs by construction. The central claim—that the benchmark isolates forward-looking judgment—rests on the stated construction procedure rather than on any internal self-reference or load-bearing prior work by the same authors. This is a standard case of an externally validated benchmark proposal with no detectable circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year =
ReAct: Synergizing Reasoning and Acting in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[2]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Retrieval-Augmented Generation for Knowledge-Intensive NLP , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[4]
AI Can Learn Scientific Taste , author =. arXiv preprint arXiv:2603.14473 , year =
-
[5]
arXiv preprint arXiv:2312.07559 , year =
PaperQA: Retrieval-Augmented Generative Agent for Scientific Research , author =. arXiv preprint arXiv:2312.07559 , year =
-
[6]
arXiv preprint arXiv:2410.13185 , year =
Chain of Ideas: Revolutionizing Research Via Novel Idea Development with LLM Agents , author =. arXiv preprint arXiv:2410.13185 , year =
-
[7]
arXiv preprint arXiv:2405.09939 , year =
SciQAG: A Framework for Auto-Generated Science Question Answering Dataset with Fine-grained Evaluation , author =. arXiv preprint arXiv:2405.09939 , year =
-
[8]
arXiv preprint arXiv:2602.20459 , year =
PreScience: A Benchmark for Forecasting Scientific Contributions , author =. arXiv preprint arXiv:2602.20459 , year =
-
[9]
Learning to Predict Future-Aligned Research Proposals with Language Models
Learning to Predict Future-Aligned Research Proposals with Language Models , author =. arXiv preprint arXiv:2603.27146 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Taxoadapt: Aligning llm-based multidimensional taxonomy construction to evolving research corpora , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
Intern-Atlas: A Methodological Evolution Graph as Research Infrastructure for
Wu, Yujun and Zhang, Dongxu and Li, Xinchen and Xu, Jinhang and Duan, Yiling and Liu, Yumou and Pan, Jiabao and Zhu, Qiyuan and Zhou, Xuanhe and Wei, Jingxuan and Li, Siyuan and Chen, Jintao and He, Conghui and Tan, Cheng , journal =. Intern-Atlas: A Methodological Evolution Graph as Research Infrastructure for. 2026 , url =
2026
-
[12]
Gridach, Mourad and Nanavati, Jay and Zine El Abidine, Khaldoun and Mendes, Lenon and Mack, Christina , journal =. Agentic. 2025 , url =
2025
-
[13]
Yamada, Yutaro and Lange, Robert Tjarko and Lu, Cong and Hu, Shengran and Lu, Chris and Foerster, Jakob and Clune, Jeff and Ha, David , journal =. The. 2025 , url =
2025
-
[14]
Advances in Neural Information Processing Systems , volume=
Ai-researcher: Autonomous scientific innovation , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Advances in Neural Information Processing Systems , volume=
Mlr-bench: Evaluating ai agents on open-ended machine learning research , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
2026 , url =
Lupidi, Alisia and Gauri, Bhavul and Foster, Thomas Simon and Al Omari, Bassel and Magka, Despoina and Pepe, Alberto and Audran-Reiss, Alexis and Aghamelu, Muna and Baldwin, Nicolas and Cipolina-Kun, Lucia and Gagnon-Audet, Jean-Christophe and Leow, Chee Hau and Lefdal, Sandra and Mossalam, Hossam and Moudgil, Abhinav and Nazir, Saba and Tewolde, Emanuel ...
2026
-
[17]
arXiv preprint arXiv:2510.10909 , year =
PaperArena: An Evaluation Benchmark for Tool-Augmented Agentic Reasoning on Scientific Literature , author =. arXiv preprint arXiv:2510.10909 , year =
-
[18]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Exante: A benchmark for ex-ante inference in large language models , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[19]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Set the clock: Temporal alignment of pretrained language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[20]
2024 , url =
Ye, Chenchen and Hu, Ziniu and Deng, Yihe and Huang, Zijie and Ma, Mingyu Derek and Zhu, Yanqiao and Wang, Wei , journal =. 2024 , url =
2024
-
[21]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[22]
International Conference on Learning Representations , volume=
Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers , author=. International Conference on Learning Representations , volume=
-
[23]
Is this idea novel? an automated benchmark for judgment of research ideas
Is this Idea Novel? An Automated Benchmark for Judgment of Research Ideas , author=. arXiv preprint arXiv:2603.10303 , year=
-
[24]
2026 , url =
Jiang, Bo , journal =. 2026 , url =
2026
-
[25]
Arbitrariness of Peer Review: A Bayesian Analysis of the
Francois, Olivier , journal =. Arbitrariness of Peer Review: A Bayesian Analysis of the. 2015 , url =
2015
-
[26]
2025 , howpublished =
2025
-
[27]
2024 , howpublished =
2024
-
[28]
2025 , howpublished =
Gemini Models , author =. 2025 , howpublished =
2025
-
[29]
Nature , volume=
Towards end-to-end automation of AI research , author=. Nature , volume=. 2026 , publisher=
2026
-
[30]
Nature , pages=
A multi-agent system for automating scientific discovery , author=. Nature , pages=. 2026 , publisher=
2026
-
[31]
SciImpact: A Multi-Dimensional, Multi-Field Benchmark for Scientific Impact Prediction
SciImpact: A Multi-Dimensional, Multi-Field Benchmark for Scientific Impact Prediction , author=. arXiv preprint arXiv:2604.17141 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
arXiv preprint arXiv:2508.11987 , year=
Futurex: An advanced live benchmark for llm agents in future prediction , author=. arXiv preprint arXiv:2508.11987 , year=
-
[33]
ForecastBench: A Dynamic Benchmark of
Karger, Ezra and Bastani, Houtan and Chen, Yueh-Han and Jacobs, Zachary and Halawi, Danny and Zhang, Fred and Tetlock, Philip , booktitle=. ForecastBench: A Dynamic Benchmark of
-
[34]
Introducing
Moy Yuan and Zifeng Ding and Andreas Vlachos , booktitle=. Introducing. 2026 , url=
2026
-
[35]
Tao, Zhengwei and Wu, Pu and Jin, Zhi and Bai, Xiaoying and Zhao, Haiyan and Dou, Chengfeng and Chen, Xiancai and Li, Jia and Li, Linyu and Tao, Chongyang and Zhang, Wentao , journal=
-
[36]
Advances in Neural Information Processing Systems , year=
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , author=. Advances in Neural Information Processing Systems , year=
-
[37]
Nature , volume=
A Benchmark of Expert-Level Academic Questions to Assess. Nature , volume=
-
[38]
Bragg, Jonathan and D'Arcy, Mike and Balepur, Nishant and Bareket, Dan and Dalvi Mishra, Bhavana and Feldman, Sergey and Haddad, Dany and Hwang, Jena D. and Jansen, Peter and Kishore, Varsha and Majumder, Bodhisattwa Prasad and Naik, Aakanksha and Rahamimov, Sigal and Richardson, Kyle and Singh, Amanpreet and Surana, Harshit and Tiktinsky, Aryeh and Vasu,...
-
[39]
ResearchBench: Benchmarking
Liu, Yujie and Yang, Zonglin and Xie, Tong and Ni, Jinjie and Gao, Ben and Li, Yuqiang and Tang, Shixiang and Ouyang, Wanli and Cambria, Erik and Zhou, Dongzhan , journal=. ResearchBench: Benchmarking
-
[40]
Empirical Methods in Natural Language Processing , year=
Matter-of-Fact: A Benchmark for Verifying the Feasibility of Literature-Supported Claims in Materials Science , author=. Empirical Methods in Natural Language Processing , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.