Mobile UMI: Cross-View Diffusion Policy with Decoupled Kinematics for Mobile Manipulation
Pith reviewed 2026-05-21 04:50 UTC · model grok-4.3
The pith
Decoupling base locomotion from hand manipulation with a one-shot camera anchor and online state realignment lets standard diffusion policies succeed on mobile tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
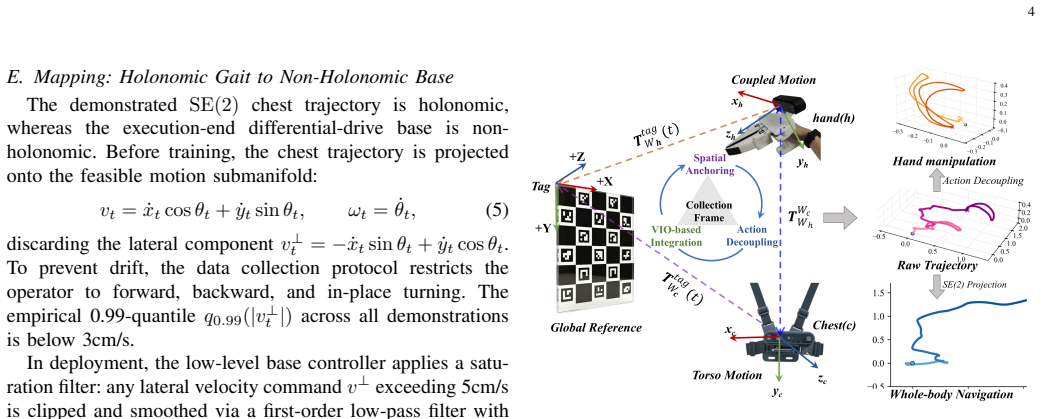
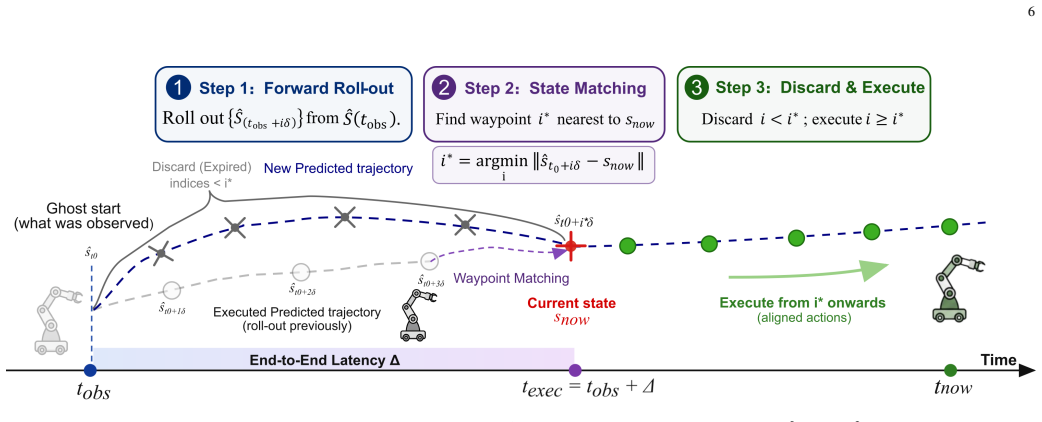
By recording demonstrations with chest and wrist cameras and using a one-shot ChArUco-based spatial anchor to re-express hand poses relative to the chest, the method extracts independent SE(3) manipulation trajectories and SE(2) base trajectories. An asynchronous receding-horizon executor then performs online state matching so that each generated action chunk is realigned with the current physical pose before execution, discarding expired waypoints. Controlled comparisons show that the chest-relative labels close much of the gap to baselines while the state matching closes the rest, yielding an 83.8 percent average success rate across four long-horizon household tasks without any changes to
What carries the argument
One-shot ChArUco-based spatial anchor that unifies chest and wrist frames to extract decoupled SE(3) hand trajectories relative to the chest and SE(2) base trajectories, together with the asynchronous receding-horizon executor that realigns action chunks via online state matching.
If this is right
- Chest-relative labels by themselves remove most locomotion contamination and close a large share of the performance gap to wrist-only baselines.
- Online state matching through receding-horizon execution removes the need for corrective backward motions at action splices caused by base advance during inference.
- The approach achieves high success on long-horizon tasks while leaving the underlying diffusion policy architecture unchanged.
- Demonstrations can be collected with portable interfaces that require no robot during data gathering.
Where Pith is reading between the lines
- The same factorization could reduce contamination in other human demonstration settings that mix walking and reaching.
- The state-matching step may generalize to any generative policy whose inference time exceeds the base motion timescale.
- Replacing the ChArUco board with learned visual anchors could test whether the method still works in changing lighting or without markers.
Load-bearing premise
The one-shot ChArUco-based spatial anchor reliably unifies chest and wrist visual-inertial frames with low error under natural human motion, allowing clean extraction of independent SE(3) and SE(2) trajectories.
What would settle it
A measurement that finds high unification error in the ChArUco anchor during typical walking would show the extracted trajectories remain contaminated and the reported gains cannot be credited to clean factorization.
Figures






read the original abstract
Mobile imitation learning on portable demonstration interfaces faces two coupled bottlenecks: locomotion-contaminated action labels and inference-induced execution latency on a continuously moving base. Recent wrist-mounted interfaces lower the cost of tabletop data collection, yet a single wrist view does not capture the global context required for base navigation. Adding a body-mounted camera entangles human walking with hand motion. Meanwhile, generative policies introduce hundreds of milliseconds of inference latency, during which the base advances past predicted waypoints, forcing backward corrections at action splices. This paper presents Mobile UMI, a hardware-free demonstration framework that addresses both gaps through three components. First, a dual-camera capture system records chest-centric global context and wrist-centric local interaction without any robot present. Second, a one-shot ChArUco-based spatial anchor unifies the chest and hand visual-inertial frames; the hand pose is then re-expressed relative to the chest to extract decoupled SE(3) manipulation and SE(2) base trajectories. Third, an asynchronous receding-horizon executor performs online state matching: each generated action chunk is realigned with the current physical pose so that expired waypoints are discarded before execution. The full system is evaluated on four long-horizon household tasks, achieving an average success rate of 83.8% over 100 trials per task. Controlled comparisons against ACT and Diffusion Policy show that the chest-relative label alone closes much of the gap; online state matching closes the remainder. These results indicate that, for mobile imitation learning under the tested conditions, explicit kinematic factorization combined with state-level latency alignment provides an effective solution without requiring architectural changes to the underlying policy class.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Mobile UMI, a hardware-free demonstration framework for mobile imitation learning. It uses a dual-camera (chest and wrist) capture system, a one-shot ChArUco-based spatial anchor to unify visual-inertial frames and extract decoupled SE(3) manipulation and SE(2) base trajectories, and an asynchronous receding-horizon executor for online state matching to mitigate inference latency. On four long-horizon household tasks, it reports 83.8% average success over 100 trials per task, with ablations showing gains from chest-relative labels and online matching over ACT and Diffusion Policy baselines.
Significance. If the decoupling holds, the work demonstrates that explicit kinematic factorization at the data level, paired with state-level latency alignment, can address key bottlenecks in mobile imitation learning without modifying the underlying policy architecture. This could enable more scalable collection of clean labels using portable interfaces and simplify deployment on continuously moving bases.
major comments (2)
- [Method section on ChArUco spatial anchor] Method section describing the spatial anchor: The central claim that the one-shot ChArUco anchor 'allows clean extraction' of independent SE(3) and SE(2) trajectories rests on the unverified assumption of low unification error under natural human motion. No quantitative metrics (e.g., pose estimation error, robustness to partial occlusion, IMU drift, or non-rigid motion) or failure cases are reported for this component, despite its load-bearing role in ensuring the extracted labels are locomotion-free and in supporting the ablation results.
- [Experimental evaluation] Experimental results: The reported 83.8% success rate and controlled comparisons are promising, but the absence of error bars, variance measures, and detailed failure analysis across the 100 trials per task limits assessment of whether the gains from decoupled labels and online matching are robust or sensitive to the anchor's accuracy.
minor comments (2)
- [Abstract] Abstract and introduction: The phrasing 'allows clean extraction' should be tempered or footnoted to reflect the lack of supporting error analysis for the anchor.
- [Notation and figures] Notation and figures: Ensure consistent use of SE(3)/SE(2) terminology and clarify how the re-expressed hand pose is computed in any accompanying diagrams.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the work.
read point-by-point responses
-
Referee: [Method section on ChArUco spatial anchor] Method section describing the spatial anchor: The central claim that the one-shot ChArUco anchor 'allows clean extraction' of independent SE(3) and SE(2) trajectories rests on the unverified assumption of low unification error under natural human motion. No quantitative metrics (e.g., pose estimation error, robustness to partial occlusion, IMU drift, or non-rigid motion) or failure cases are reported for this component, despite its load-bearing role in ensuring the extracted labels are locomotion-free and in supporting the ablation results.
Authors: We agree that quantitative validation of the ChArUco spatial anchor would provide stronger direct support for the claim of clean decoupled trajectory extraction. The current manuscript presents the anchor as a practical, hardware-free unification step using established computer-vision techniques, with its utility shown indirectly through high task success rates and the ablation comparing chest-relative versus wrist-only labels. To address the referee's concern directly, the revised manuscript will include a new quantitative evaluation subsection (or appendix) reporting pose estimation error, robustness to partial occlusion and natural human motion, IMU drift effects, and observed failure cases, obtained via additional controlled validation experiments. These metrics will clarify the anchor's contribution to locomotion-free labels. revision: yes
-
Referee: [Experimental evaluation] Experimental results: The reported 83.8% success rate and controlled comparisons are promising, but the absence of error bars, variance measures, and detailed failure analysis across the 100 trials per task limits assessment of whether the gains from decoupled labels and online matching are robust or sensitive to the anchor's accuracy.
Authors: We acknowledge that the experimental section would benefit from explicit variance reporting and failure-mode analysis to better demonstrate robustness. In the revised manuscript we will add standard deviations (or error bars) to all success-rate tables and figures, and we will expand the results discussion with a categorized breakdown of failure modes across the 100 trials per task (e.g., navigation errors, manipulation errors, timing/latency issues). This will allow readers to assess consistency of the reported gains from decoupled kinematics and online state matching, as well as any sensitivity to anchor accuracy. revision: yes
Circularity Check
No circularity: derivation chain is self-contained data processing and empirical evaluation
full rationale
The paper describes a dual-camera capture system, one-shot ChArUco spatial anchor for re-expressing hand pose relative to chest to extract decoupled SE(3) and SE(2) trajectories, and an asynchronous receding-horizon executor for state matching. These are presented as engineering components evaluated empirically on four household tasks with success rates and comparisons to ACT and Diffusion Policy baselines. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described method. The kinematic factorization is a preprocessing step on collected data rather than a derived result that reduces to its own inputs by construction. The central claim of effective solution without policy architecture changes rests on the reported controlled comparisons, which are independent of the method definition itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ChArUco marker provides accurate one-shot spatial alignment between chest and wrist cameras in dynamic human motion scenarios.
Reference graph
Works this paper leans on
-
[1]
Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots,
C. Chiet al., “Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots,” inRSS, 2024
work page 2024
-
[2]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chiet al., “Diffusion policy: Visuomotor policy learning via action diffusion,” inRSS, 2023
work page 2023
-
[3]
Learning predictive models from observation and interaction,
K. Schmeckpeperet al., “Learning predictive models from observation and interaction,” inECCV, 2020. 8 Fig. 7. Book placement: rollout and baseline failure modes under different module ablations. Fig. 8. Turn off the light: rollout and representative failure modes (miss touch, collision, wrong pose)
work page 2020
-
[4]
Learning dexterous grasping with object- centric visual affordances,
P. Mandikal and K. Grauman, “Learning dexterous grasping with object- centric visual affordances,” inICRA, 2021
work page 2021
-
[5]
Human-to-robot imitation in the wild,
S. Bahlet al., “Human-to-robot imitation in the wild,” arXiv preprint arXiv:2207.09450, 2022
-
[6]
RT-Trajectory: Robotic task generalization via hindsight trajectory sketches,
J. Guet al., “RT-Trajectory: Robotic task generalization via hindsight trajectory sketches,” inICLR, 2024
work page 2024
-
[7]
TidyBot++: An open-source holonomic mobile manipu- lator for robot learning,
J. Wuet al., “TidyBot++: An open-source holonomic mobile manipu- lator for robot learning,” inCoRL, 2024
work page 2024
-
[8]
P. Sundaresanet al., “HoMeR: Learning in-the-wild mobile manip- ulation via hybrid imitation and whole-body control,” arXiv preprint arXiv:2506.01185, 2025
-
[9]
MobRT: A digital twin-based framework for scalable learning in mobile manipulation,
Y . Meiet al., “MobRT: A digital twin-based framework for scalable learning in mobile manipulation,” arXiv preprint arXiv:2510.04592, 2025
-
[10]
Mobile ALOHA: Learning bimanual mobile manipulation with low-cost whole-body teleoperation,
Z. Fuet al., “Mobile ALOHA: Learning bimanual mobile manipulation with low-cost whole-body teleoperation,” inICRA, 2024
work page 2024
-
[11]
TeleMoMa: A modular and versatile teleoperation system for mobile manipulation,
S. Dasset al., “TeleMoMa: A modular and versatile teleoperation system for mobile manipulation,” inRSS Workshop, 2024
work page 2024
-
[12]
SPIN: Simultaneous perception interaction and navi- gation,
H. Xionget al., “SPIN: Simultaneous perception interaction and navi- gation,” inCVPR, 2024
work page 2024
-
[13]
Mobi-Pi: Mobilizing your robot learning policy,
J. Yanget al., “Mobi-Pi: Mobilizing your robot learning policy,” in CoRL, 2025
work page 2025
-
[14]
LookOut: Real-world humanoid egocentric navigation,
L. Y . Zhuet al., “LookOut: Real-world humanoid egocentric navigation,” inICCV, 2025
work page 2025
-
[15]
DexCap: Scalable and portable mocap data collection system for dexterous manipulation,
C. Wanget al., “DexCap: Scalable and portable mocap data collection system for dexterous manipulation,” inACM SIGGRAPH, 2024
work page 2024
-
[16]
DexUMI: Using human hand as the universal manipula- tion interface for dexterous manipulation,
M. Xuet al., “DexUMI: Using human hand as the universal manipula- tion interface for dexterous manipulation,” inCoRL, 2025
work page 2025
-
[17]
AnyTeleop: A general vision-based dexterous robot arm- hand teleoperation system,
Y . Qinet al., “AnyTeleop: A general vision-based dexterous robot arm- hand teleoperation system,” inRSS, 2023
work page 2023
-
[18]
Holo-Dex: Teaching dexterity with immersive mixed reality,
S. P. Arunachalamet al., “Holo-Dex: Teaching dexterity with immersive mixed reality,” inICRA, 2023
work page 2023
-
[19]
A. Iyeret al., “Open Teach: A versatile teleoperation system for robotic manipulation,” arXiv preprint arXiv:2403.07870, 2024
-
[20]
GELLO: A general, low-cost, and intuitive teleoperation framework for robot manipulators,
P. Wuet al., “GELLO: A general, low-cost, and intuitive teleoperation framework for robot manipulators,” inIROS, 2024
work page 2024
-
[21]
Bunny-visionpro: Real-time bimanual dexterous teleoperation for imitation learning,
R. Dinget al., “Bunny-VisionPro: Real-time bimanual dexterous teleop- eration for imitation learning,” arXiv preprint arXiv:2407.03162, 2024
-
[22]
Open-TeleVision: Teleoperation with immersive active visual feedback,
X. Chenget al., “Open-TeleVision: Teleoperation with immersive active visual feedback,” inCoRL, 2025
work page 2025
-
[23]
EgoMimic: Scaling imitation learning via egocentric video,
S. Kareeret al., “EgoMimic: Scaling imitation learning via egocentric video,” inICRA, 2025
work page 2025
-
[24]
Vision in action: Learning active perception from human demonstrations,
H. Xionget al., “Vision in action: Learning active perception from human demonstrations,” inCoRL, 2025
work page 2025
-
[25]
AnyDexGrasp: General dexterous grasping for different hands with human-level learning efficiency,
H. S. Fanget al., “AnyDexGrasp: General dexterous grasping for different hands with human-level learning efficiency,” arXiv preprint arXiv:2502.16420, 2025
-
[26]
ManipTrans: Efficient dexterous bimanual manipulation transfer via residual learning,
K. Liet al., “ManipTrans: Efficient dexterous bimanual manipulation transfer via residual learning,” arXiv preprint arXiv:2503.21860, 2025
-
[27]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inRSS, 2023
work page 2023
-
[28]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Y . Zeet al., “3D diffusion policy: Generalizable visuomotor policy learn- ing via simple 3D representations,” arXiv preprint arXiv:2403.03954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
S. Liuet al., “RDT-1B: A diffusion foundation model for bimanual manipulation,” arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
RoboPanoptes: The all-seeing robot with whole-body dexterity,
X. Xuet al., “RoboPanoptes: The all-seeing robot with whole-body dexterity,” inRSS, 2025
work page 2025
-
[31]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Y . Huet al., “Video prediction policy: A generalist robot policy with predictive visual representations,” arXiv preprint arXiv:2412.14803, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
X. Zhuet al., “Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper,” arXiv preprint arXiv:2507.15062, 2025
-
[33]
A. Sridharet al., “MemER: Scaling up memory for robot control via experience retrieval,” arXiv preprint arXiv:2510.20328, 2025
-
[34]
OpenVINS: A research platform for visual-inertial estimation,
P. Genevaet al., “OpenVINS: A research platform for visual-inertial estimation,” inICRA, 2020, pp. 7726–7732
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.