OVIG: Optimistic Verification of AI Training Integrity via Gradient Signals
Pith reviewed 2026-06-26 14:12 UTC · model grok-4.3
The pith
OVIG verifies outsourced AI post-training by checking gradient differences against an empirical boundary from honest heterogeneous replays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
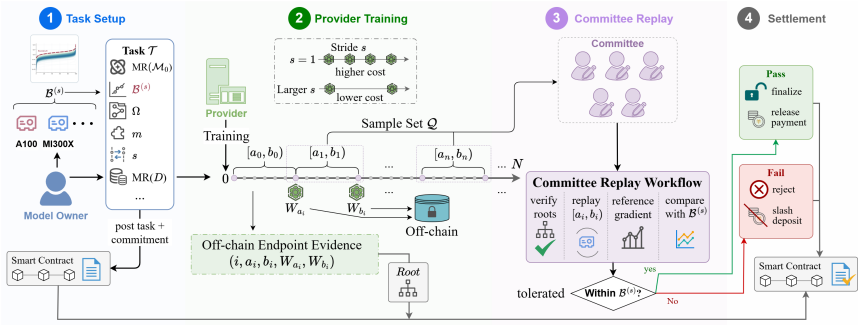
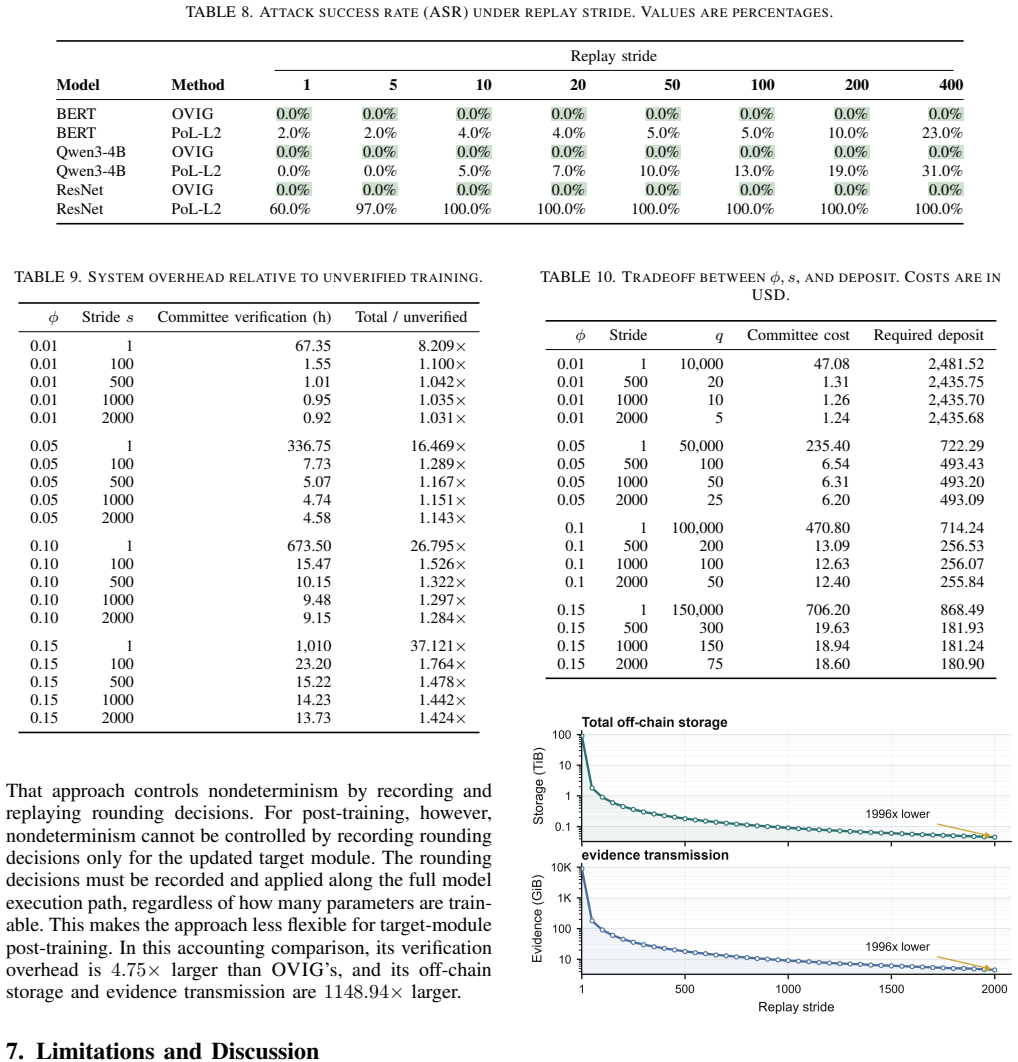
OVIG is an optimistic verification framework that audits outsourced post-training using an empirical boundary on gradient differences calibrated from honest heterogeneous replays. OVIG checks opened intervals against this boundary and combines optimistic sampling with a stride parameter s, which partitions training into stride-aligned intervals and retains only interval-endpoint evidence. Across shortcut training attacks and targeted manipulation attacks, OVIG maintains 0% ASR on language, vision, and diffusion workloads. On Qwen3, increasing the stride from s=1 to s=2000 reduces off-chain storage and evidence transmission by 1996x while preserving 0% ASR; at this setting, OVIG incurs only 1
What carries the argument
The empirical boundary on gradient differences calibrated from honest heterogeneous replays, used to audit stride-aligned training intervals via optimistic sampling.
If this is right
- Outsourced post-training of large models can be audited without requiring identical hardware or full recomputation.
- Storage and evidence transmission costs drop by nearly three orders of magnitude when stride reaches 2000 while detection remains perfect.
- The same verification layer works across language, vision, and diffusion model families with comparable overhead.
- Total system cost stays within 15 percent of unverified training even after adding the verification steps.
Where Pith is reading between the lines
- Providers could publish the calibrated boundary as part of a service-level agreement, letting owners verify compliance without re-running the entire job.
- The stride mechanism may extend to other long-running iterative computations where only endpoint states need checking against a drift model.
- If the boundary calibration proves stable across more accelerator generations, the method could become a standard audit primitive for cloud AI services.
Load-bearing premise
The empirical boundary on gradient differences, calibrated from honest heterogeneous replays, is sufficient to distinguish benign numerical drift from integrity violations caused by malicious deviations in the declared training trajectory.
What would settle it
An experiment in which a malicious training run that deviates from the declared trajectory produces gradient differences that remain inside the calibrated honest boundary for the full duration of training.
Figures

read the original abstract
The rapid growth of AI has increased the demand for domain-specific post-training, while the cost and specialization of accelerator infrastructure push many model owners to outsource this process. Outsourced training lowers operational barriers, but creates a training-integrity gap: the owner receives a checkpoint, logs, and aggregate metrics without direct evidence that the declared training trajectory was faithfully executed. An untrusted provider may have incentives to deviate from that trajectory, either to save computation or to introduce targeted security risks. Auditing such deviations is difficult because floating-point execution on heterogeneous accelerators introduces benign numerical drift, making it hard to distinguish honest replay differences from integrity violations. Existing verification methods either observe training at too coarse a granularity or impose costs and deployment constraints that are impractical at scale. We present OVIG, an optimistic verification framework that audits outsourced post-training using an empirical boundary on gradient differences calibrated from honest heterogeneous replays. OVIG checks opened intervals against this boundary and combines optimistic sampling with a stride parameter $s$, which partitions training into stride-aligned intervals and retains only interval-endpoint evidence. Across shortcut training attacks and targeted manipulation attacks, OVIG maintains $0\%$ ASR on language, vision, and diffusion workloads. On Qwen3, increasing the stride from $s=1$ to $s=2000$ reduces off-chain storage and evidence transmission by $1996\times$ while preserving $0\%$ ASR; at this setting, OVIG incurs only $1.143\times$ total system overhead relative to training without verification. These results show that OVIG provides a practical integrity layer for outsourced AI post-training under heterogeneous execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OVIG, an optimistic verification framework for outsourced AI post-training integrity. It audits declared training trajectories by comparing gradient signals against an empirical boundary calibrated from honest heterogeneous replays, using stride-aligned interval sampling (parameter s) to retain only endpoint evidence and reduce off-chain costs. The central claims are that OVIG achieves 0% attack success rate (ASR) against shortcut training and targeted manipulation attacks on language, vision, and diffusion workloads, and that increasing s from 1 to 2000 on Qwen3 yields a 1996× reduction in storage/transmission with only 1.143× total overhead relative to unverified training.
Significance. If the empirical gradient-difference boundary can be shown to separate all benign numerical drift (across hardware, drivers, batch ordering, and mixed precision) from every malicious deviation while remaining non-circular, OVIG would provide a deployable, low-overhead integrity layer for outsourced post-training, addressing a practical gap between coarse aggregate metrics and full replay verification.
major comments (2)
- [Abstract] Abstract: the central verification boundary is defined empirically from the same class of honest heterogeneous replays the method later certifies. No quantitative coverage (number of distinct hardware pairs, total replay steps, or statistical procedure for setting the bound) is supplied, so it is impossible to determine whether the interval is guaranteed to contain every possible honest execution while excluding all attacks.
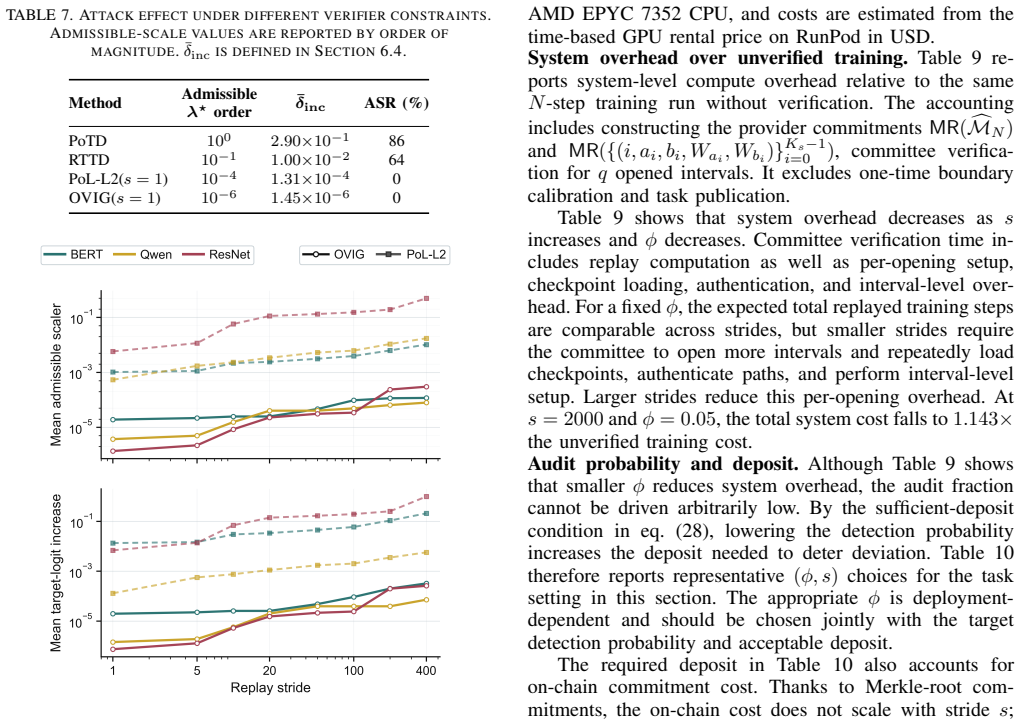
- [Abstract] Abstract: the 0% ASR claim on shortcut and manipulation attacks at s=2000 rests on the boundary remaining tight enough to catch deviations even when only every 2000th step is checked. Without an analysis of how stride interacts with the calibration set (e.g., whether attacks can be crafted to stay inside the bound at large s), the preservation of 0% ASR is not yet demonstrated to be robust.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on the calibration of the verification boundary and the robustness of the stride parameter. We provide point-by-point responses below and will make revisions to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central verification boundary is defined empirically from the same class of honest heterogeneous replays the method later certifies. No quantitative coverage (number of distinct hardware pairs, total replay steps, or statistical procedure for setting the bound) is supplied, so it is impossible to determine whether the interval is guaranteed to contain every possible honest execution while excluding all attacks.
Authors: The full manuscript provides these details in the experimental methodology section, where the calibration uses multiple hardware pairs and a statistical procedure based on the maximum observed gradient differences in honest replays. To address the referee's concern about the abstract, we will revise it to include a concise summary of the quantitative coverage, ensuring readers can assess the bound's validity without referring to the body. revision: yes
-
Referee: [Abstract] Abstract: the 0% ASR claim on shortcut and manipulation attacks at s=2000 rests on the boundary remaining tight enough to catch deviations even when only every 2000th step is checked. Without an analysis of how stride interacts with the calibration set (e.g., whether attacks can be crafted to stay inside the bound at large s), the preservation of 0% ASR is not yet demonstrated to be robust.
Authors: The paper demonstrates through extensive experiments on language, vision, and diffusion models that 0% ASR is maintained at s=2000. The attacks tested could not evade detection at the sampled endpoints. We agree that an explicit analysis of stride-calibration interaction would strengthen the presentation. In the revision, we will include a discussion subsection examining potential evasion strategies under large stride and explaining why they are not feasible given the boundary tightness observed in honest replays. revision: partial
Circularity Check
No circularity: empirical boundary is calibrated on honest data and tested on separate attacks
full rationale
The paper presents OVIG as an empirical verification method that calibrates a gradient-difference boundary exclusively from honest heterogeneous replays and then evaluates it against distinct shortcut and manipulation attacks. No derivation, equation, or claim reduces a prediction to its own calibration inputs by construction. The 0% ASR result is reported as an empirical outcome on held-out attack workloads rather than a statistically forced output from the same replays used for the bound. The approach is self-contained against external benchmarks and does not rely on self-citation chains or self-definitional steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- stride s
- empirical gradient boundary
axioms (1)
- domain assumption Gradient differences observed in honest heterogeneous replays form a reliable, attack-distinguishable boundary.
Reference graph
Works this paper leans on
-
[1]
Artifi- cial intelligence index report 2025,
N. Maslej, L. Fattorini, R. Perrault, Y . Gil, V . Parli, N. Kariuki, E. Capstick, A. Reuel, E. Brynjolfsson, J. Etchemendyet al., “Artifi- cial intelligence index report 2025,”arXiv preprint arXiv:2504.07139, 2025
arXiv 2025
-
[2]
The state of ai in 2025: Agents, innovation, and transformation,
A. Singla, A. Sukharevsky, B. Hall, L. Yee, M. Chui, and T. Balakrishnan, “The state of ai in 2025: Agents, innovation, and transformation,” McKinsey & Company, Tech. Rep., Nov. 2025, quantumBlack, AI by McKinsey. [Online]. Available: https://www. mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
2025
-
[3]
Coreweave announces agreement with OpenAI to deliver AI infrastructure,
CoreWeave, “Coreweave announces agreement with OpenAI to deliver AI infrastructure,” PR Newswire, March 2025, accessed: 2026-06-06. [Online]. Available: https://www.prnewswire.com/new s-releases/coreweave-announces-agreement-with-openai-to-deliver-a i-infrastructure-302397595.html
2025
-
[4]
Mayo Clinic and Microsoft collaborate to develop a frontier AI model for healthcare,
Mayo Clinic and Microsoft, “Mayo Clinic and Microsoft collaborate to develop a frontier AI model for healthcare,” PR Newswire, June 2026, accessed: 2026-06-06. [Online]. Available: https://www.prne wswire.com/news-releases/mayo-clinic-and-microsoft-collaborate-t o-develop-a-frontier-ai-model-for-healthcare-302788613.html
2026
-
[5]
Cerebras and G42’s Inception unveil Jais: A 13B parameter arabic LLM trained on Condor Galaxy,
J. Hampton, “Cerebras and G42’s Inception unveil Jais: A 13B parameter arabic LLM trained on Condor Galaxy,” EnterpriseAI, August 2023, accessed: 2026-06-06. [Online]. Available: https: //www.enterpriseai.news/2023/08/30/cerebras-and-g42s-inception-u nveil-jais-a-13b-parameter-arabic-llm-trained-on-condor-galaxy/
2023
-
[6]
Optimistic verifiable training by controlling hardware nondeterminism,
M. Srivastava, S. Arora, and D. Boneh, “Optimistic verifiable training by controlling hardware nondeterminism,” inAdvances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[7]
Verifying the quality of outsourced training on clouds,
P. Li, Y . Wang, Z. Liu, K. Xu, Q. Wang, C. Shen, and Q. Li, “Verifying the quality of outsourced training on clouds,” inEuropean Symposium on Research in Computer Security. Springer, 2022, pp. 126–144
2022
-
[8]
vtune: Veri- fiable fine-tuning for llms through backdooring,
E. Zhang, A. Pal, A. Potti, and M. Goldblum, “vtune: Veri- fiable fine-tuning for llms through backdooring,”arXiv preprint arXiv:2411.06611, 2024
arXiv 2024
-
[9]
Watermarking makes language models radioactive,
T. Sander, P. Fernandez, A. Durmus, M. Douze, and T. Furon, “Watermarking makes language models radioactive,”Advances in Neural Information Processing Systems, vol. 37, pp. 21 079–21 113, 2024
2024
-
[10]
Securepol: Integration of watermarking with proof-of-learning to enhance security against spoofing attacks,
O. Ural and K. Yoshigoe, “Securepol: Integration of watermarking with proof-of-learning to enhance security against spoofing attacks,” IEEE Access, vol. 13, pp. 213 067–213 091, 2025
2025
-
[11]
Entangled watermarks as a defense against model extraction,
H. Jia, C. A. Choquette-Choo, V . Chandrasekaran, and N. Papernot, “Entangled watermarks as a defense against model extraction,” in 30th USENIX security symposium (USENIX Security 21), 2021, pp. 1937–1954
2021
-
[12]
Llm dataset inference: Did you train on my dataset?
P. Maini, H. Jia, N. Papernot, and A. Dziedzic, “Llm dataset inference: Did you train on my dataset?”Advances in Neural Information Processing Systems, vol. 37, pp. 124 069–124 092, 2024
2024
-
[13]
Tools for verifying neural models’ training data,
D. Choi, Y . Shavit, and D. K. Duvenaud, “Tools for verifying neural models’ training data,”Advances in Neural Information Processing Systems, vol. 36, pp. 1154–1188, 2023
2023
-
[14]
Back- door detection through replicated execution of outsourced training,
H. Jia, S. Wyllie, A. B. Sediq, A. Ibrahim, and N. Papernot, “Back- door detection through replicated execution of outsourced training,” in 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 2025, pp. 169–188
2025
-
[15]
Proof-of-learning: Definitions and practice,
H. Jia, M. Yaghini, C. A. Choquette-Choo, N. Dullerud, A. Thudi, V . Chandrasekaran, and N. Papernot, “Proof-of-learning: Definitions and practice,” in2021 IEEE Symposium on Security and Privacy (SP). IEEE, 2021, pp. 1039–1056
2021
-
[16]
Zero- knowledge proofs of training for deep neural networks,
K. Abbaszadeh, J. Katz, C. Pappas, and D. Papadopoulos, “Zero- knowledge proofs of training for deep neural networks,” inPro- ceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 4316–4330
2024
-
[17]
Laminator: Verifiable ml property cards using hardware-assisted attestations,
V . Duddu, L. J. Gunn, and N. Asokan, “Laminator: Verifiable ml property cards using hardware-assisted attestations,” inProceedings of the Fifteenth ACM Conference on Data and Application Security and Privacy, 2024, pp. 317–328
2024
-
[18]
Ciphersteal: Stealing input data from tee-shielded neural networks with ciphertext side channels,
Y . Yuan, Z. Liu, S. Deng, Y . Chen, S. Wang, Y . Zhang, and Z. Su, “Ciphersteal: Stealing input data from tee-shielded neural networks with ciphertext side channels,” in2025 IEEE Symposium on Security and Privacy (SP). IEEE, 2025, pp. 4136–4154
2025
-
[19]
TDXRay: Microarchitectural side-channel analysis of Intel TDX for real-world workloads,
T. Hornetz, H. Yavarzadeh, A. Cheu, A. Gascon, L. Gerlach, D. Moghimi, P. Schoppmann, M. Schwarz, and R. Zhang, “TDXRay: Microarchitectural side-channel analysis of Intel TDX for real-world workloads,” in2026 IEEE Symposium on Security and Privacy (S&P). IEEE, 2026
2026
-
[20]
A digital signature based on a conventional encryption function,
R. C. Merkle, “A digital signature based on a conventional encryption function,” inConference on the theory and application of crypto- graphic techniques. Springer, 1987, pp. 369–378
1987
-
[21]
Towards under- standing and enhancing security of{Proof-of-Training}for{DNN} model ownership verification,
Y . Chang, H. Jiang, C. Lin, X. Huang, and J. Weng, “Towards under- standing and enhancing security of{Proof-of-Training}for{DNN} model ownership verification,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 7233–7250
2025
-
[22]
A scalable verification solution for blockchains,
J. Teutsch and C. Reitwießner, “A scalable verification solution for blockchains,” inAspects of Computation and Automata Theory with Applications. World Scientific, 2024, pp. 377–424
2024
-
[23]
opml: Optimistic machine learning on blockchain,
K. Conway, C. So, X. Yu, and K. Wong, “opml: Optimistic machine learning on blockchain,”arXiv preprint arXiv:2401.17555, 2024
arXiv 2024
-
[24]
Proof-of-learning is currently more broken than you think,
C. Fang, H. Jia, A. Thudi, M. Yaghini, C. A. Choquette-Choo, N. Dullerud, V . Chandrasekaran, and N. Papernot, “Proof-of-learning is currently more broken than you think,” in2023 IEEE 8th European Symposium on Security and Privacy (EuroS&P). IEEE, 2023, pp. 797–816
2023
-
[25]
Randomness in neural network training: Characterizing the impact of tooling,
D. Zhuang, X. Zhang, S. Song, and S. Hooker, “Randomness in neural network training: Characterizing the impact of tooling,”Proceedings of Machine Learning and Systems, vol. 4, pp. 316–336, 2022
2022
-
[26]
Towards training reproducible deep learning models,
B. Chen, M. Wen, Y . Shi, D. Lin, G. K. Rajbahadur, and Z. M. Jiang, “Towards training reproducible deep learning models,” inProceedings of the 44th international conference on software engineering, 2022, pp. 2202–2214
2022
-
[27]
Checkpointing and deterministic training for deep learning,
X. Xu, H. Liu, G. Tao, Z. Xuan, and X. Zhang, “Checkpointing and deterministic training for deep learning,” inProceedings of the 1st International Conference on AI Engineering: Software Engineering for AI, 2022, pp. 65–76
2022
-
[28]
Zkdl: Efficient zero-knowledge proofs of deep learning training,
H. Sun, T. Bai, J. Li, and H. Zhang, “Zkdl: Efficient zero-knowledge proofs of deep learning training,”IEEE Transactions on Information F orensics and Security, vol. 20, pp. 914–927, 2024
2024
-
[29]
Experimenting with zero-knowledge proofs of training,
S. Garg, A. Goel, S. Jha, S. Mahloujifar, M. Mahmoody, G.- V . Policharla, and M. Wang, “Experimenting with zero-knowledge proofs of training,” inProceedings of the 2023 ACM SIGSAC con- ference on computer and communications security, 2023, pp. 1880– 1894
2023
-
[30]
Founding zero-knowledge proof of training on optimum vicinity,
G. Tan, A. Gasc ´on, S. Meiklejohn, M. Raykova, X. Wang, and N. Luo, “Founding zero-knowledge proof of training on optimum vicinity,” in Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, 2025, pp. 1173–1187
2025
-
[31]
{SoK}: Un- derstanding{zk-SNARKs}: The gap between research and practice,
J. Liang, D. Hu, P. Wu, Y . Yang, Q. Shen, and Z. Wu, “{SoK}: Un- derstanding{zk-SNARKs}: The gap between research and practice,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 2085–2104
2025
-
[32]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, V olume 1 (Long and Short ...
-
[33]
Backpropagation and stochastic gradient descent method,
S.-i. Amari, “Backpropagation and stochastic gradient descent method,”Neurocomputing, vol. 5, no. 4-5, pp. 185–196, 1993
1993
-
[34]
A stochastic approximation method,
H. Robbins and S. Monro, “A stochastic approximation method,”The annals of mathematical statistics, pp. 400–407, 1951
1951
-
[35]
Ieee standard for floating-point arithmetic,
“Ieee standard for floating-point arithmetic,”IEEE Std 754-2019 (Revision of IEEE 754-2008), pp. 1–84, 2019
2019
-
[36]
Full-speed deterministic bit-accurate parallel floating-point summation on multi- and many-core architectures,
S. Collange, D. Defour, S. Graillat, and R. Iakymchuk, “Full-speed deterministic bit-accurate parallel floating-point summation on multi- and many-core architectures,”INRIA, DALI–LIRMM, LIP6, ICS, Tech. Rep. HAL: hal-00949355, 2014
2014
-
[37]
Arbitrum: Scalable, private smart contracts,
H. Kalodner, S. Goldfeder, X. Chen, S. M. Weinberg, and E. W. Felten, “Arbitrum: Scalable, private smart contracts,” in27th USENIX Security Symposium (USENIX Security 18), 2018, pp. 1353–1370
2018
-
[38]
Casper the friendly finality gadget,
V . Buterin and V . Griffith, “Casper the friendly finality gadget,”arXiv preprint arXiv:1710.09437, 2017
Pith/arXiv arXiv 2017
-
[39]
Specular: Towards secure, trust-minimized optimistic blockchain execution,
Z. Ye, U. Misra, J. Cheng, W. Zhou, and D. Song, “Specular: Towards secure, trust-minimized optimistic blockchain execution,” in2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024, pp. 3943–3960
2024
-
[40]
It takes two: A peer- prediction solution for blockchain verifier’s dilemma,
Z. Zhao, X. Chen, and Y . Zhou, “It takes two: A peer- prediction solution for blockchain verifier’s dilemma,”arXiv preprint arXiv:2406.01794, 2024
arXiv 2024
-
[41]
Concentration inequalities for sam- pling without replacement,
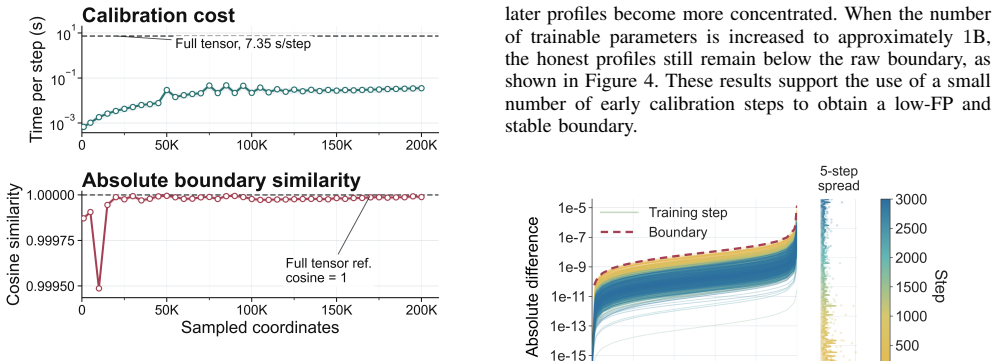
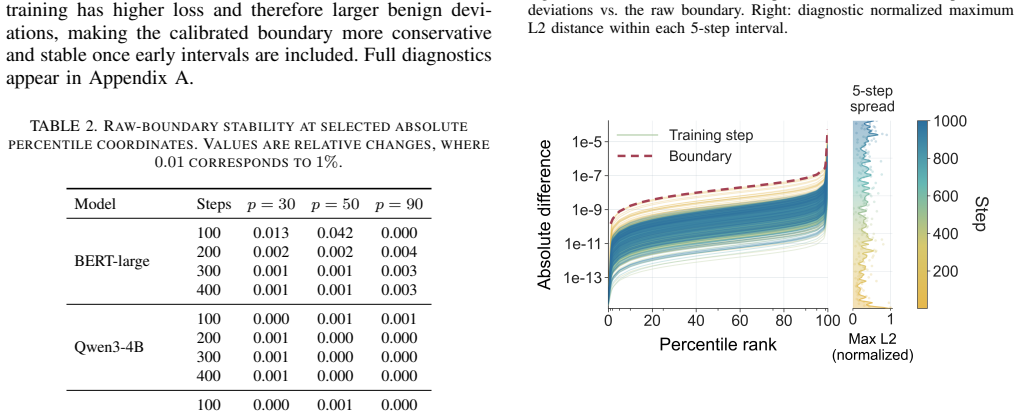
R. Bardenet and O.-A. Maillard, “Concentration inequalities for sam- pling without replacement,” 2015. Appendix A. Full Boundary Stability Diagnostics Table 11 reports the full set of boundary stability diag- nostics used in section 6.2. The notation follows section 5.4: a raw boundary profile is a percentile function eBρ s(p), where ρ∈ {abs,rel}andp∈Λ. I...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.