idSCD: Identifying Training Datasets through Semantic Correlation Descriptors
Pith reviewed 2026-06-29 08:33 UTC · model grok-4.3
The pith
Models internalize dataset-specific spurious correlations that semantic correlation descriptors can extract to detect training dataset membership.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
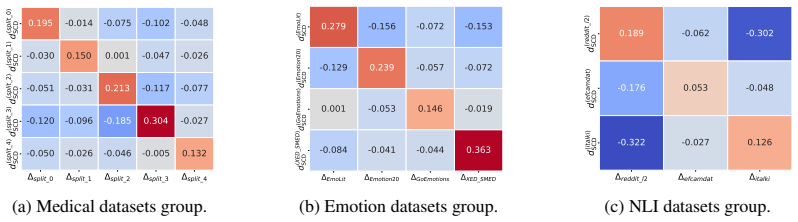
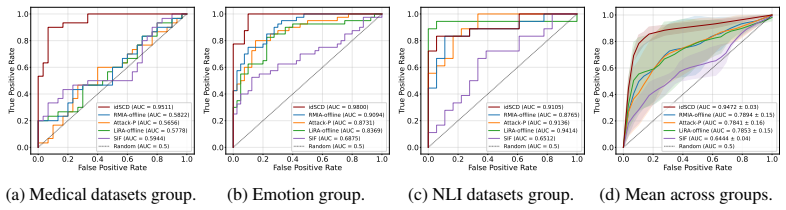
Datasets leave dataset-specific traces in a model's learned semantic correlation structure; incidental regularities that are predictive within a dataset but not causal for the underlying task are internalized during training. Semantic correlation descriptors capture this structure and make it comparable across dataset mixtures. A practical membership score tests whether a target dataset belongs to the training mixture by comparing only the model's SCD with the target dataset's standalone SCD. In leave-one-dataset-out diagnostics the descriptors recover dataset-specific changes and perfectly separate matching from non-matching pairs. The SCD-based classifier achieves the highest performance a
What carries the argument
Semantic correlation descriptors (SCDs): vectors that encode the semantic correlation structure learned by a model, enabling direct numerical comparison between a trained model and any candidate dataset without requiring leave-one-out retraining.
If this is right
- SCDs recover dataset-specific changes and perfectly separate matching from non-matching dataset pairs in leave-one-out diagnostics.
- An SCD-based membership classifier attains the highest average performance and lowest standard deviation across NLI, emotion, and medical text groups.
- The approach yields a relative ROC-AUC gain exceeding 60 percent when dataset groups expose distinct semantic particularities.
- The score operates with only the model's SCD and the target dataset's standalone SCD, without black-box queries or loss access.
- Performance holds across different degrees of semantic separation and keyword support between dataset splits.
Where Pith is reading between the lines
- If SCDs remain stable under fine-tuning, they could serve as persistent fingerprints for auditing deployed models' training data composition.
- The method may extend to detecting data poisoning by checking whether injected correlations appear in the model's SCD.
- Neighboring tasks such as detecting duplicate or near-duplicate training sources could be addressed by clustering SCD vectors across many candidate datasets.
- If the descriptors prove sensitive to collection artifacts, they might also help quantify unintended dataset leakage in public model releases.
Load-bearing premise
That incidental semantic correlations learned during training are sufficiently dataset-specific and stable to enable reliable membership inference even across datasets with partial semantic overlap.
What would settle it
Run the SCD membership score on two datasets that share identical semantic regularities yet differ in labels or collection source; if the score cannot distinguish the held-out dataset from the training one, the central claim is falsified.
Figures

read the original abstract
Can a dataset be recognized from the spurious correlations it induces during training? We argue that datasets leave dataset-specific traces in a model's learned semantic correlation structure: incidental regularities that are predictive within a dataset, but not causal for the underlying task, can be internalized during training. We use this insight to study dataset-level membership inference, moving beyond existing methods that rely on behavioral or distributional evidence such as confidence scores, losses, margins, generated samples, or query responses. We introduce a white-box semantic fingerprinting approach based on semantic correlation descriptors (SCDs), which capture the semantic correlation structure learned by a model and make it comparable across dataset mixtures. In a controlled leave-one-dataset-out diagnostic, SCDs recover dataset-specific changes and perfectly separate matching from non-matching dataset pairs. We then propose a practical SCD-based membership score that tests whether a target dataset is part of a model's training mixture using only the model's SCD and the target dataset's standalone SCD, without requiring leave-one-dataset-out models. Across three diverse experimental settings, with dataset groups for natural language inference, emotion classification, and medical text classification, we test both the advantages and limitations of SCD-based membership inference with different degrees of semantic separation and keyword support between dataset splits. On average, the classifier based on this score achieves the highest performance and the lowest std, outperforming black-box baselines RMIA, Attack-P, and LiRA, as well as the white-box SIF baseline. These results show that dataset membership can be traced through internal semantic correlations, with the largest relative gain exceeding 60% in ROC-AUC when dataset groups expose distinct semantic particularities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that datasets induce identifiable, dataset-specific incidental semantic correlations during training, which can be captured via semantic correlation descriptors (SCDs) for dataset-level membership inference. In a controlled leave-one-out diagnostic, SCDs recover these changes and achieve perfect separation between matching and non-matching dataset pairs. A practical SCD-based score, using only the model's SCD and the target dataset's standalone SCD, is then shown to outperform black-box baselines (RMIA, Attack-P, LiRA) and the white-box SIF baseline across NLI, emotion classification, and medical text tasks, with the largest relative ROC-AUC gain exceeding 60%.
Significance. If the results hold, the work offers a new white-box fingerprinting method for tracing dataset membership through internalized semantic structures rather than behavioral or distributional signals. The reported outperformance with lowest standard deviation and the explicit testing across varying degrees of semantic separation are strengths; the approach could complement existing membership inference techniques when datasets exhibit distinct semantic particularities.
major comments (2)
- [Abstract] Abstract: the claim that SCDs 'perfectly separate matching from non-matching dataset pairs' in the leave-one-out diagnostic is load-bearing for the central claim, yet the manuscript provides no quantitative details on the separation metric, threshold, or potential confounds from shared semantic patterns across dataset groups.
- [Abstract] Abstract and experimental settings: the practical SCD score's reported average outperformance (highest performance, lowest std) is tested 'with different degrees of semantic separation and keyword support,' but lacks reported per-setting ROC-AUC values, error bars, or an explicit ablation isolating whether incidental correlations (e.g., common NLI patterns) produce false positives when a dataset is absent, directly bearing on whether the gains over RMIA/LiRA/SIF generalize.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments point-by-point below. We agree that providing additional quantitative details will improve clarity and have planned revisions to the abstract and experimental sections accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that SCDs 'perfectly separate matching from non-matching dataset pairs' in the leave-one-out diagnostic is load-bearing for the central claim, yet the manuscript provides no quantitative details on the separation metric, threshold, or potential confounds from shared semantic patterns across dataset groups.
Authors: We agree that the abstract would benefit from including quantitative details supporting the 'perfect separation' claim. In the revised manuscript, we will update the abstract to specify the separation metric (cosine similarity between SCDs) and note that perfect separation corresponds to an ROC-AUC of 1.0 in the leave-one-out diagnostic. We will also incorporate a brief discussion of potential confounds from shared semantic patterns, explaining how the experimental design with varying semantic separation addresses this. revision: yes
-
Referee: [Abstract] Abstract and experimental settings: the practical SCD score's reported average outperformance (highest performance, lowest std) is tested 'with different degrees of semantic separation and keyword support,' but lacks reported per-setting ROC-AUC values, error bars, or an explicit ablation isolating whether incidental correlations (e.g., common NLI patterns) produce false positives when a dataset is absent, directly bearing on whether the gains over RMIA/LiRA/SIF generalize.
Authors: We acknowledge that the abstract summarizes average performance and that per-setting details are important for assessing generalization. We will revise to include per-setting ROC-AUC values with error bars in the abstract or a new table reference. Regarding the explicit ablation for false positives due to incidental correlations in absent datasets, the current leave-one-out diagnostic provides evidence against false positives by showing clear separation. However, to directly isolate the effect of common patterns (e.g., NLI), we will add a dedicated ablation experiment in the revision. revision: yes
Circularity Check
No circularity: empirical method validated against external baselines
full rationale
The paper introduces SCDs as a new descriptor for semantic correlations and validates membership inference empirically via leave-one-out diagnostics and direct comparisons to independent baselines (RMIA, LiRA, Attack-P, SIF). No equations or claims reduce by construction to fitted parameters, self-definitions, or self-citation chains; the separation performance and outperformance are measured outcomes on held-out dataset groups, not tautological renamings or imported uniqueness theorems. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization, 2020. URL https://arxiv.org/abs/1907.02893
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
Scalable membership inference attacks via quantile regression, 2023
Martin Bertran, Shuai Tang, Michael Kearns, Jamie Morgenstern, Aaron Roth, and Zhiwei Steven Wu. Scalable membership inference attacks via quantile regression, 2023. URL https://arxiv.org/abs/2307.03694
-
[3]
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia: A suite for analyzing large language models across training and scaling, 2023. URL https://arxiv.org/abs/2304.01373
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Yake! keyword extraction from single documents using multiple local features
Ricardo Campos, V \' tor Mangaravite, Arian Pasquali, Al \' pio Jorge, C \'e lia Nunes, and Adam Jatowt. Yake! keyword extraction from single documents using multiple local features. Information Sciences, 509: 0 257--289, 2020
2020
-
[5]
Membership inference attacks from first principles, 2022
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership inference attacks from first principles, 2022. URL https://arxiv.org/abs/2112.03570
-
[6]
Chang, Dheeraj Rajagopal, Tolga Bolukbasi, Lucas Dixon, and Ian Tenney
Tyler A. Chang, Dheeraj Rajagopal, Tolga Bolukbasi, Lucas Dixon, and Ian Tenney. Scalable influence and fact tracing for large language model pretraining, 2024. URL https://arxiv.org/abs/2410.17413
-
[7]
Choquette-Choo, Florian Tramer, Nicholas Carlini, and Nicolas Papernot
Christopher A. Choquette-Choo, Florian Tramer, Nicholas Carlini, and Nicolas Papernot. Label-only membership inference attacks, 2021. URL https://arxiv.org/abs/2007.14321
-
[8]
Membership inference attack using self influence functions, 2022
Gilad Cohen and Raja Giryes. Membership inference attack using self influence functions, 2022. URL https://arxiv.org/abs/2205.13680
-
[9]
GoEmotions: A Dataset of Fine-Grained Emotions
Dorottya Demszky, Dana Movshovitz-Attias, Jeongwoo Ko, Alan Cowen, Gaurav Nemade, and Sujith Ravi. GoEmotions: A Dataset of Fine-Grained Emotions . In 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020
2020
-
[10]
PubMed 200k RCT: a Dataset for Sequential Sentence Classification in Medical Abstracts
Franck Dernoncourt and Ji Young Lee. Pubmed 200k rct: a dataset for sequential sentence classification in medical abstracts. In International Joint Conference on Natural Language Processing, 2017. URL https://arxiv.org/abs/1710.06071
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Shortcut learning of large language models in natural language understanding, 2023
Mengnan Du, Fengxiang He, Na Zou, Dacheng Tao, and Xia Hu. Shortcut learning of large language models in natural language understanding, 2023. URL https://arxiv.org/abs/2208.11857
-
[12]
Not all splits are equal: Rethinking attribute generalization across unrelated categories
Liviu Nicolae Firca, Antonio Barbalau, Dan Oneata, and Elena Burceanu. Not all splits are equal: Rethinking attribute generalization across unrelated categories. NeurIPSW, 2025
2025
-
[13]
SMED : Social media emotion dataset
Amrita Ganguly. SMED : Social media emotion dataset. Kaggle, 2023. URL https://www.kaggle.com/datasets/gangulyamrita/social-media-emotion-dataset. Five-class emotion dataset curated from social media
2023
-
[14]
The ef-cambridge open language database (efcamdat)
Jeroen Geertzen, Theodora Alexopoulou, and Anna Korhonen. The ef-cambridge open language database (efcamdat). Annual Review of Applied Linguistics, 33: 0 208--231, 2013
2013
-
[15]
Zemel, Wieland Brendel, Matthias Bethge, and Felix A
Robert Geirhos, J \" o rn - Henrik Jacobsen, Claudio Michaelis, Richard S. Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. Shortcut learning in deep neural networks. CoRR, abs/2004.07780, 2020. URL https://arxiv.org/abs/2004.07780
-
[16]
Annotation Artifacts in Natural Language Inference Data
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R. Bowman, and Noah A. Smith. Annotation artifacts in natural language inference data, 2018. URL https://arxiv.org/abs/1803.02324
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
o ping Electronic Conference Proceedings , pages 115--129. Link \
Thomas G Hudson and Sardar Jaf. On the development of a large scale corpus for native language identification. In Proceedings of the 17th International Workshop on Treebanks and Linguistic Theories (TLT 2018), December 13--14, 2018, Oslo University, Norway, volume 155 of Link \"o ping Electronic Conference Proceedings , pages 115--129. Link \"o ping Unive...
2018
-
[18]
Datamodels: Predicting predictions from training data, 2022
Andrew Ilyas, Sung Min Park, Logan Engstrom, Guillaume Leclerc, and Aleksander Madry. Datamodels: Predicting predictions from training data, 2022. URL https://arxiv.org/abs/2202.00622
-
[19]
On feature learning in the presence of spurious correlations, 2022
Pavel Izmailov, Polina Kirichenko, Nate Gruver, and Andrew Gordon Wilson. On feature learning in the presence of spurious correlations, 2022. URL https://arxiv.org/abs/2210.11369
-
[20]
Understanding black-box predictions via influence functions, 2020
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions, 2020. URL https://arxiv.org/abs/1703.04730
-
[21]
Stolen memories: Leveraging model memorization for calibrated white-box membership inference, 2020
Klas Leino and Matt Fredrikson. Stolen memories: Leveraging model memorization for calibrated white-box membership inference, 2020. URL https://arxiv.org/abs/1906.11798
-
[22]
Membership leakage in label-only exposures, 2021
Zheng Li and Yang Zhang. Membership leakage in label-only exposures, 2021. URL https://arxiv.org/abs/2007.15528
-
[23]
Shortcut learning in medical image segmentation
Manxi Lin, Nina Weng, Kamil Mikolaj, Zahra Bashir, Morten BS Svendsen, Martin G Tolsgaard, Anders N Christensen, and Aasa Feragen. Shortcut learning in medical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 623--633. Springer, 2024
2024
-
[24]
Membership inference attacks by exploiting loss trajectory, 2022
Yiyong Liu, Zhengyu Zhao, Michael Backes, and Yang Zhang. Membership inference attacks by exploiting loss trajectory, 2022. URL https://arxiv.org/abs/2208.14933
-
[25]
Llm dataset inference: Did you train on my dataset?, 2024
Pratyush Maini, Hengrui Jia, Nicolas Papernot, and Adam Dziedzic. Llm dataset inference: Did you train on my dataset?, 2024. URL https://arxiv.org/abs/2406.06443
-
[26]
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference
R. Thomas McCoy, Ellie Pavlick, and Tal Linzen. Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference, 2019. URL https://arxiv.org/abs/1902.01007
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[27]
Machine Learning with Membership Privacy using Adversarial Regularization
Milad Nasr, Reza Shokri, and Amir Houmansadr. Machine learning with membership privacy using adversarial regularization, 2018. URL https://arxiv.org/abs/1807.05852
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Hugo Frezat, Julien Le Sommer, Ronan Fablet, Guillaume Balarac, and Redouane Lguen- sat
Milad Nasr, Reza Shokri, and Amir Houmansadr. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In 2019 IEEE Symposium on Security and Privacy (SP), page 739–753. IEEE, May 2019. doi:10.1109/sp.2019.00065. URL http://dx.doi.org/10.1109/SP.2019.00065
-
[29]
Probing neural network comprehension of natural language arguments, 2019
Timothy Niven and Hung-Yu Kao. Probing neural network comprehension of natural language arguments, 2019. URL https://arxiv.org/abs/1907.07355
-
[30]
O hman, Marc P \`a mies, Kaisla Kajava, and J \
Emily \"O hman, Marc P \`a mies, Kaisla Kajava, and J \"o rg Tiedemann. XED : A multilingual dataset for sentiment analysis and emotion detection. In The 28th International Conference on Computational Linguistics (COLING 2020), 2020
2020
-
[31]
Bridging explainability and embeddings: Bee aware of spuriousness
Cristian Daniel Paduraru, Antonio Barbalau, Radu Filipescu, Andrei Liviu Nicolicioiu, and Elena Burceanu. Bridging explainability and embeddings: Bee aware of spuriousness. In ICLR , 2026
2026
-
[32]
Nicolas Papernot, Patrick McDaniel, Arunesh Sinha, and Michael P. Wellman. Sok: Security and privacy in machine learning. In 2018 IEEE European Symposium on Security and Privacy (EuroS&P), pages 399--414, 2018. doi:10.1109/EuroSP.2018.00035
-
[33]
Trak: Attributing model behavior at scale.arXiv preprint arXiv:2303.14186, 2023
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Aleksander Madry. Trak: Attributing model behavior at scale, 2023. URL https://arxiv.org/abs/2303.14186
-
[34]
Oslo: One-shot label-only membership inference attacks, 2024
Yuefeng Peng, Jaechul Roh, Subhransu Maji, and Amir Houmansadr. Oslo: One-shot label-only membership inference attacks, 2024. URL https://arxiv.org/abs/2405.16978
-
[35]
20-emotion text classification dataset, 2025
Shreyas Pulle. 20-emotion text classification dataset, 2025. URL https://huggingface.co/datasets/shreyaspulle98/emotion-dataset-20-emotions
2025
-
[36]
Native language cognate effects on second language lexical choice
Ella Rabinovich, Yulia Bogdanova, Dimitra Laparidou, Svitlana Volkova, and Yulia Tsvetkov. Native language cognate effects on second language lexical choice. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2745--2755, Brussels, Belgium, October 2018. Association for Computational Linguistics. doi:10.18653/v...
-
[37]
Detecting fine-grained emotions in literature
Luis Rei and Dunja Mladenić. Detecting fine-grained emotions in literature. Applied Sciences, 13 0 (13), 2023. ISSN 2076-3417. doi:10.3390/app13137502. URL https://www.mdpi.com/2076-3417/13/13/7502
-
[38]
A survey of privacy attacks in machine learning
Maria Rigaki and Sebastian Garcia. A survey of privacy attacks in machine learning. ACM Computing Surveys, 56 0 (4): 0 1–34, November 2023. ISSN 1557-7341. doi:10.1145/3624010. URL http://dx.doi.org/10.1145/3624010
-
[39]
White-box vs black-box: Bayes optimal strategies for membership inference, 2019
Alexandre Sablayrolles, Matthijs Douze, Yann Ollivier, Cordelia Schmid, and Hervé Jégou. White-box vs black-box: Bayes optimal strategies for membership inference, 2019. URL https://arxiv.org/abs/1908.11229
-
[40]
Ahmed Salem, Yang Zhang, Mathias Humbert, Pascal Berrang, Mario Fritz, and Michael Backes. Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models, 2018. URL https://arxiv.org/abs/1806.01246
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Web-scale k-means clustering
David Sculley. Web-scale k-means clustering. In Proceedings of the 19th International Conference on World Wide Web, pages 1177--1178. ACM, 2010
2010
-
[42]
Membership Inference Attacks against Machine Learning Models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models, 2017. URL https://arxiv.org/abs/1610.05820
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Systematic evaluation of privacy risks of machine learning models, 2020
Liwei Song and Prateek Mittal. Systematic evaluation of privacy risks of machine learning models, 2020. URL https://arxiv.org/abs/2003.10595
-
[44]
A statistical interpretation of term specificity and its application in retrieval
Karen Sp \"a rck Jones. A statistical interpretation of term specificity and its application in retrieval. Journal of Documentation, 28 0 (1): 0 11--21, 1972
1972
-
[45]
Enhancing training data attribution with representational optimization, 2025
Weiwei Sun, Haokun Liu, Nikhil Kandpal, Colin Raffel, and Yiming Yang. Enhancing training data attribution with representational optimization, 2025. URL https://arxiv.org/abs/2505.18513
-
[46]
Wang, Prateek Mittal, Dawn Song, and Ruoxi Jia
Jiachen T. Wang, Prateek Mittal, Dawn Song, and Ruoxi Jia. Data shapley in one training run, 2025. URL https://arxiv.org/abs/2406.11011
-
[47]
Causal attention for unbiased visual recognition, 2021
Tan Wang, Chang Zhou, Qianru Sun, and Hanwang Zhang. Causal attention for unbiased visual recognition, 2021. URL https://arxiv.org/abs/2108.08782
-
[48]
Understanding rare spurious correlations in neural networks, 2022
Yao-Yuan Yang, Chi-Ning Chou, and Kamalika Chaudhuri. Understanding rare spurious correlations in neural networks, 2022. URL https://arxiv.org/abs/2202.05189
-
[49]
Enhanced membership inference attacks against machine learning models, 2022
Jiayuan Ye, Aadyaa Maddi, Sasi Kumar Murakonda, Vincent Bindschaedler, and Reza Shokri. Enhanced membership inference attacks against machine learning models, 2022. URL https://arxiv.org/abs/2111.09679
-
[50]
The clever hans mirage: A comprehensive survey on spurious correlations in machine learning
Wenqian Ye, Luyang Jiang, Eric Xie, Guangtao Zheng, Yunsheng Ma, Xu Cao, Dongliang Guo, Daiqing Qi, Zeyu He, Yijun Tian, et al. The clever hans mirage: A comprehensive survey on spurious correlations in machine learning. arXiv preprint arXiv:2402.12715, 2024
-
[51]
Privacy Risk in Machine Learning: Analyzing the Connection to Overfitting
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyzing the connection to overfitting, 2018. URL https://arxiv.org/abs/1709.01604
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[52]
Low-cost high-power membership inference attacks, 2024
Sajjad Zarifzadeh, Philippe Liu, and Reza Shokri. Low-cost high-power membership inference attacks, 2024. URL https://arxiv.org/abs/2312.03262
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.