Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
Pith reviewed 2026-06-30 10:49 UTC · model grok-4.3
The pith
Flow-DPPO replaces ratio clipping with exact KL divergence constraints for more stable RL in flow matching models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
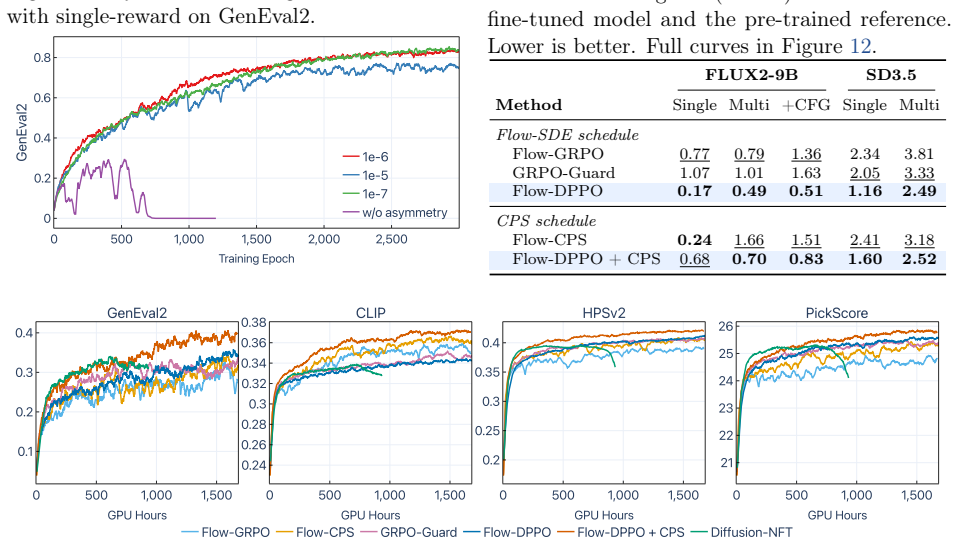
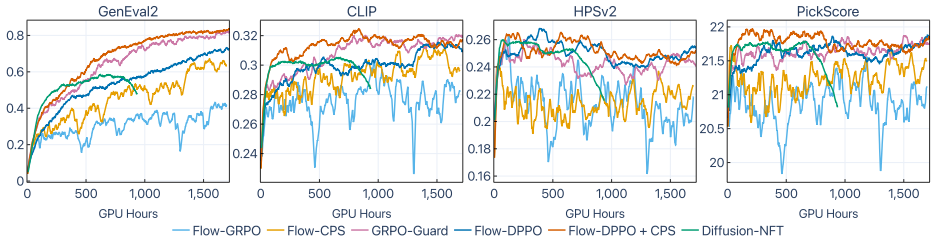
Flow-DPPO replaces the ratio clipping mechanism of PPO with a divergence proximal constraint. Because the per-step policy in flow models is Gaussian, the KL divergence between old and new policies can be computed exactly and cheaply. An asymmetric divergence mask then blocks gradient updates only when they move away from the trusted region while violating the divergence threshold. This approach is shown to deliver higher rewards with improved KL-proximal efficiency, to alleviate catastrophic forgetting, to promote balanced optimization across multiple objectives, and to support stable multi-epoch training where ratio clipping causes degradation.
What carries the argument
The asymmetric divergence mask applied to exact KL divergence between successive Gaussian per-step policies.
If this is right
- Higher rewards are achieved with better KL-proximal efficiency.
- Catastrophic forgetting is alleviated during online training.
- Multi-objective optimization becomes more balanced.
- Stable training is maintained across multiple epochs where ratio clipping degrades.
Where Pith is reading between the lines
- The same Gaussian-per-step observation could be reused in other continuous-time generative models that admit closed-form policy divergences.
- Stable multi-epoch training may allow reward models to be applied more thoroughly without repeated policy resets.
- The asymmetric mask could be adapted to other proximal methods that currently rely on ratio estimates.
Load-bearing premise
That the per-step policy in flow models is Gaussian, which permits exact and cheap KL divergence computation between old and new policies.
What would settle it
A controlled experiment in which the per-step policy is forced away from Gaussianity and Flow-DPPO no longer outperforms ratio clipping on reward or stability metrics.
Figures











read the original abstract
Recent work has demonstrated that online reinforcement learning (RL) can substantially improve the quality and alignment of flow matching models for image and video generation. Methods such as Flow-GRPO and CPS cast the denoising process as a Markov Decision Process and apply PPO-style ratio clipping to enforce a trust region. However, we argue that ratio clipping is structurally ill-suited for flow models: the probability ratio between new and old policies is a noisy, single-sample estimate of the true policy divergence, leading to over-constraining in some regions of the trajectory and under-constraining in others. We propose Flow-DPPO (Flow Divergence Proximal Policy Optimization), which replaces ratio clipping with a divergence proximal constraint. A key observation is that the per-step policy in flow models is Gaussian, enabling exact and cheap computation of the KL divergence between old and new policies. Flow-DPPO employs an asymmetric divergence mask that blocks gradient updates only when they simultaneously move away from the trusted region and violate the divergence threshold. Experiments show that Flow-DPPO achieves higher rewards with better KL-proximal efficiency, alleviates catastrophic forgetting, promotes balanced multi-objective optimization, and enables stable multi-epoch training where ratio clipping degrades. Code and models are available at https://github.com/Tencent-Hunyuan/UniRL/tree/main/FlowDPPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Flow-DPPO as an alternative to PPO-style ratio clipping for online RL fine-tuning of flow matching models. It replaces the probability ratio with a divergence proximal constraint that applies an asymmetric mask to the KL term, justified by the claim that per-step policies in flow models are Gaussian and thus permit exact, cheap KL computation between old and new policies. The method is asserted to yield higher rewards, improved KL-proximal efficiency, reduced catastrophic forgetting, balanced multi-objective optimization, and stable multi-epoch training.
Significance. If the Gaussian per-step policy assumption is verified and the experimental improvements are reproducible, the approach could supply a structurally better trust-region mechanism for RL on flow-based generative models than direct adaptations of PPO clipping, which the authors argue is mismatched to the denoising trajectory structure.
major comments (2)
- [Abstract] Abstract: the central justification that 'the per-step policy in flow models is Gaussian, enabling exact and cheap computation of the KL divergence' is presented as an observation without derivation, proof, or empirical check against the MDP formulation of the denoising process. This assumption is load-bearing; if the velocity field plus stochasticity at each step does not yield independent per-step Gaussians, the closed-form KL no longer holds and the divergence proximal constraint reduces to an approximation whose cost and correctness are uncharacterized.
- [Abstract] Abstract: the experimental claims ('achieves higher rewards with better KL-proximal efficiency, alleviates catastrophic forgetting...') are stated without any quantitative values, baseline comparisons, dataset specifications, or ablation controls, preventing assessment of whether the reported advantages are statistically meaningful or robust.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below. Where the manuscript requires clarification or expansion, we indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central justification that 'the per-step policy in flow models is Gaussian, enabling exact and cheap computation of the KL divergence' is presented as an observation without derivation, proof, or empirical check against the MDP formulation of the denoising process. This assumption is load-bearing; if the velocity field plus stochasticity at each step does not yield independent per-step Gaussians, the closed-form KL no longer holds and the divergence proximal constraint reduces to an approximation whose cost and correctness are uncharacterized.
Authors: The per-step Gaussian structure follows directly from the flow-matching formulation: the deterministic velocity field is perturbed by additive isotropic Gaussian noise at each denoising step, yielding independent Gaussian transitions under the MDP in Section 2. This is not an unverified claim; the closed-form KL is derived in Section 3.2 and used for the asymmetric mask. We will add a concise derivation paragraph (with the explicit transition density) to the methods section and a one-sentence reference in the abstract. Empirical confirmation appears in the KL-computation timing and accuracy ablations of Section 4.3. If the referee believes an additional appendix proof is needed, we can supply it. revision: yes
-
Referee: [Abstract] Abstract: the experimental claims ('achieves higher rewards with better KL-proximal efficiency, alleviates catastrophic forgetting...') are stated without any quantitative values, baseline comparisons, dataset specifications, or ablation controls, preventing assessment of whether the reported advantages are statistically meaningful or robust.
Authors: Abstracts conventionally omit numerical detail; the concrete results (reward deltas, KL-proximal curves, forgetting metrics on ImageNet and video datasets, multi-epoch stability ablations, and statistical significance) are reported with tables and figures in Sections 4 and 5. To address the concern we will insert two representative quantitative statements (e.g., average reward lift and KL efficiency gain versus Flow-GRPO) into the revised abstract while preserving its length limit. revision: yes
Circularity Check
No circularity; derivation rests on stated Gaussian observation as external premise
full rationale
The paper presents the Gaussian per-step policy as a 'key observation' enabling exact KL, without deriving it from prior equations, fitted parameters, or self-citations in the provided text. The replacement of ratio clipping with divergence proximal constraint follows directly from this assumption rather than reducing to it by construction. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations are present. The central claims remain independent of the paper's own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The per-step policy in flow models is Gaussian
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Geneval 2: Addressing benchmark drift in text-to-image evaluation.arXiv preprint arXiv:2512.16853,
Amita Kamath, Kai-Wei Chang, Ranjay Krishna, Luke Zettlemoyer, Yushi Hu, and Marjan Ghazvininejad. Geneval 2: Addressing benchmark drift in text-to-image evaluation.arXiv preprint arXiv:2512.16853,
-
[3]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Yiming Cheng, Miles Yang, Zhao Zhong, and Liefeng Bo. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward-decoupled normalizationpolicyoptimizationformulti-rewardrloptimization.arXiv preprint arXiv:2601.05242,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Rethinking the Trust Region in LLM Reinforcement Learning
Penghui Qi, Xiangxin Zhou, Zichen Liu, Tianyu Pang, Chao Du, Min Lin, and Wee Sun Lee. Rethinking the trust region in llm reinforcement learning.arXiv preprint arXiv:2602.04879,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proximal Policy Optimization Algorithms
13 John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Feng Wang and Zihao Yu. Coefficients-preserving sampling for reinforcement learning with flow matching.arXiv preprint arXiv:2509.05952,
-
[10]
Jing Wang, Jiajun Liang, Jie Liu, Henglin Liu, Gongye Liu, Jun Zheng, Wanyuan Pang, Ao Ma, Zhenyu Xie, Xintao Wang, et al. Grpo-guard: Mitigating implicit over-optimization in flow matching via regulated clipping.arXiv preprint arXiv:2510.22319,
-
[11]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Shuchen Xue, Chongjian Ge, Shilong Zhang, Yichen Li, and Zhi-Ming Ma. Advantage weighted matching: Aligning rl with pretraining in diffusion models.arXiv preprint arXiv:2509.25050, 2025a. Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual gener...
-
[13]
for trajectory generation, uses group-relative advantage estimation, and applies the divergence-based mask during policy optimization. Algorithm 1Flow-DPPO Training 1:Input:Flow modelv θ, reference modelvref, reward functionR, promptsC 2:Hyperparameters:group sizeG, divergence thresholdδ, KL coefficientβ, stochasticityη 3:foreach training iterationdo 4:Sa...
2002
-
[14]
(2026) for the LLM regime
to the finite-horizon, undiscounted setting of flow model denoising, following the approach of Qi et al. (2026) for the LLM regime. We use the MDP notation introduced in Section 2.1:K− 1decision steps indexed byk∈ { 1, . . . , K− 1}, states sk = (c, tk,x tk), actions ak = xtk+1, and terminal reward R(x0,c). 16 B.1 Proof of Performance Difference Identity ...
2026
-
[15]
Appendix C
thus provides a rigorous theoretical guarantee for Flow-DPPO: by enforcing a per-step divergence threshold, the penalty term remains controlled, ensuring monotonic policy improvement. Appendix C. KL Divergence Between Gaussian Policies In this section, we derive the KL divergence between old and new policies in flow models and establish its connection to ...
2025
-
[16]
G.3 Ablation Studies G.3.1 Classifier-Free Guidance Previous works found that CFG heavily affects the training convergence and performance (Zheng et al., 2026). Here, we study the effect of CFG on the training of Flow-DPPO on FLUX2-9B, as shown 27 0 200 400 600 800 0 0.2 0.4 0.6 0.8 1β = 1e-3 β = 1e-2 β = 0 (no KL reg.) Training Epoch KL Divergence [×10⁻³...
2026
-
[17]
Per-columnboldand underline mark the top-1 and top-2 methods; blue rows highlight our two contributions. FLUX2-9B SD3.5 FLUX.1-dev MethodSingle Multi +CFG Single Multi Single Flow-GRPO 84.5 46.8 54.6 56.6 39.9 87.8 Flow-CPS 82.7 47.1 89.0 74.8 44.6 91.2 GRPO-Guard 82.8 49.0 78.885.847.8 87.6 Diffusion-NFT – 47.3 – 64.5 42.5 – Flow-DPPO 85.1 57.7 87.4 78.9...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.