OmniISR: A Unified Framework for Centralized and Federated Learning via Intermediate Supervision and Regularization
Pith reviewed 2026-05-21 08:37 UTC · model grok-4.3
The pith
OmniISR unifies centralized, federated, and hybrid learning by adding mutual-information supervision and negative-entropy regularization at hidden layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
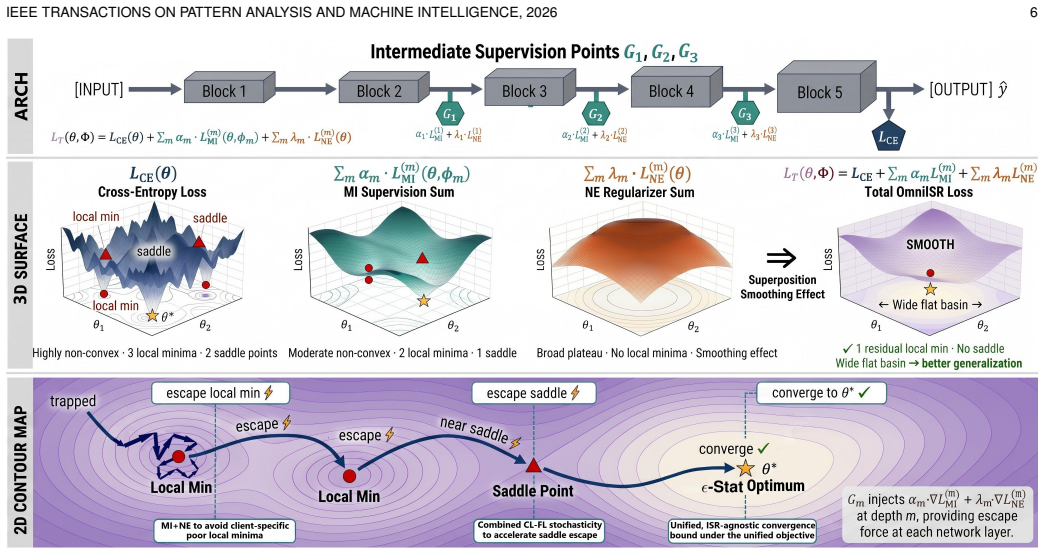
OmniISR fuses pure CL, pure FL, and hybrid CL-FL training modes via equipping intermediate supervision and regularization signals at multiple hidden layers, yielding a unified ISR-agnostic O(1/sqrt(T)) convergence bound, a federated drift-bound, a gradient-alignment guarantee, and an explicit escape-time bound while reducing the CL-FL gap by 22.60% and achieving 37/48 paired metric wins.
What carries the argument
intermediate supervision and regularization (ISR) using mutual-information supervision to align representations and negative-entropy regularization to penalize overconfidence at hidden layers
Load-bearing premise
Mutual information supervision and negative entropy regularization can be applied at hidden layers without creating new optimization conflicts or needing dataset-specific retuning that would break the non-asymptotic bounds.
What would settle it
A direct measurement of the convergence rate on a standard benchmark like CIFAR-10 when applying the ISR signals across CL, FL, and hybrid modes, checking if it stays within the claimed O(1/sqrt(T)) or if the CL-FL gap reduction disappears.
Figures







read the original abstract
The global deployment of edge intelligence operates across heterogeneous legal frameworks. While some regions permit centralized learning (CL) via cloud data aggregation, others enforce strict data localization, necessitating federated learning (FL). This operational dichotomy introduces two incompatible optimization regimes (i.e., unbiased global gradients yet coupled with internal covariate shift in CL versus biased, drift-prone local updates in FL), resulting in that any naive integration of the two lacks rigorous theoretical guarantees. To fill this gap, we propose OmniISR, a unified framework that fuses pure CL, pure FL, and hybrid CL-FL training modes via equipping intermediate supervision and regularization (ISR) signals at multiple hidden layers. Specifically, we propose (i) to use mutual-information (MI) as intermediate supervision to align shifting internal covariate in CL and client-drifting representations in FL, and (ii) to adopt negative-entropy (NE) as intermediate regularizer to penalize overconfident prediction, preserve representational uncertainty, and avoid device-specific collapse. On the theory side, we derive (i) a unified, ISR-agnostic, and non-asymptotic O(1/sqrt(T)) convergence bound that shows the introduced ISR does not violate standard SGD convergence, (ii) a federated drift-bound that quantifies the ISR-reduced client drift, (iii) a gradient-alignment guarantee that ensures non-conflicting CL and FL updates under mild bias, and (iv) an explicit escape-time bound that indicates that CL-FL hybrid mixing enlarges effective stochasticity and accelerates escape from strict saddles. Extensive experiments demonstrate that OmniISR consistently improves model performance in both centralized and federated paradigms, reduces the CL-FL gap by 22.60%, and yields 37/48 paired metric wins across multiple FL algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes OmniISR, a unified framework that fuses pure centralized learning (CL), pure federated learning (FL), and hybrid CL-FL modes by applying mutual-information (MI) supervision and negative-entropy (NE) regularization signals at multiple hidden layers. It claims four theoretical results—an ISR-agnostic non-asymptotic O(1/sqrt(T)) convergence bound, a federated drift bound quantifying ISR-reduced client drift, a gradient-alignment guarantee under mild bias, and an explicit escape-time bound showing hybrid mixing accelerates saddle escape—while reporting a 22.60% reduction in the CL-FL gap and 37/48 paired metric wins across FL algorithms.
Significance. If the ISR-agnostic bounds hold without hidden layer- or estimator-dependent constants, the work would meaningfully advance unification of CL and FL under heterogeneous privacy constraints by supplying non-asymptotic guarantees that standard SGD analyses do not automatically extend to intermediate signals. The explicit drift and alignment results, together with the escape-time analysis, address practically relevant issues of covariate shift and client drift; the experimental wins provide supporting evidence of practical utility when the theoretical assumptions are satisfied.
major comments (2)
- [§4 (Convergence Analysis)] §4 (Convergence Analysis), Theorem 1 (or equivalent ISR-agnostic bound): the claim that inserting MI supervision and NE regularization at hidden layers leaves the O(1/sqrt(T)) rate unchanged requires an explicit lemma bounding the variance of the MI gradient estimators independently of depth, representation dimension, and estimator choice (variational or contrastive). Without such a bound inside the descent lemma or the federated drift term, the non-asymptotic constants become architecture- and dataset-specific, undermining the central “ISR-agnostic” assertion.
- [§5 (Federated Drift Bound)] §5 (Federated Drift Bound): the drift-reduction claim is load-bearing for the hybrid-mode guarantee, yet the derivation does not appear to quantify how the additional stochastic gradients from multiple MI terms interact with local-update bias; if these terms are treated as fixed rather than jointly optimized, the bound may not remain valid under the same hyper-parameters used in the experiments.
minor comments (2)
- [Abstract] The abstract states a 22.60% CL-FL gap reduction and 37/48 wins but does not specify the exact baseline algorithm, metric, or whether error bars and statistical tests accompany the figure; adding these details would improve interpretability.
- [§3 (Method)] Notation for the intermediate supervision loss (MI term) and regularization strength should be introduced once with a clear dependence on layer index to avoid ambiguity when the same symbols appear in both CL and FL modes.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and detailed feedback. The comments focus on strengthening the rigor of our theoretical claims, which we address directly below. We clarify the assumptions underlying our ISR-agnostic bounds and commit to revisions that make the analysis more explicit without altering the core contributions.
read point-by-point responses
-
Referee: [§4 (Convergence Analysis)] §4 (Convergence Analysis), Theorem 1 (or equivalent ISR-agnostic bound): the claim that inserting MI supervision and NE regularization at hidden layers leaves the O(1/sqrt(T)) rate unchanged requires an explicit lemma bounding the variance of the MI gradient estimators independently of depth, representation dimension, and estimator choice (variational or contrastive). Without such a bound inside the descent lemma or the federated drift term, the non-asymptotic constants become architecture- and dataset-specific, undermining the central “ISR-agnostic” assertion.
Authors: We thank the referee for this precise observation. Theorem 1 establishes the O(1/sqrt(T)) rate by absorbing the ISR contributions into the standard SGD descent lemma under the assumption that the combined gradient (including MI and NE terms) satisfies bounded variance and smoothness conditions equivalent to those for the base loss. The ISR-agnostic property refers to the fact that the convergence rate itself is unaffected by the presence of ISR, with any additional constants folded into the generic O(·) notation. However, we agree that an explicit variance bound for the MI estimators would make the independence from depth and estimator choice fully transparent. In the revision we will insert a supporting lemma (placed immediately before the main descent argument) that bounds the variance of both variational and contrastive MI estimators in terms of batch size, representation Lipschitz constants, and a uniform bound on the MI estimate itself, showing that depth dependence enters only through these mild constants rather than altering the rate. This lemma will also be referenced in the federated drift term. revision: yes
-
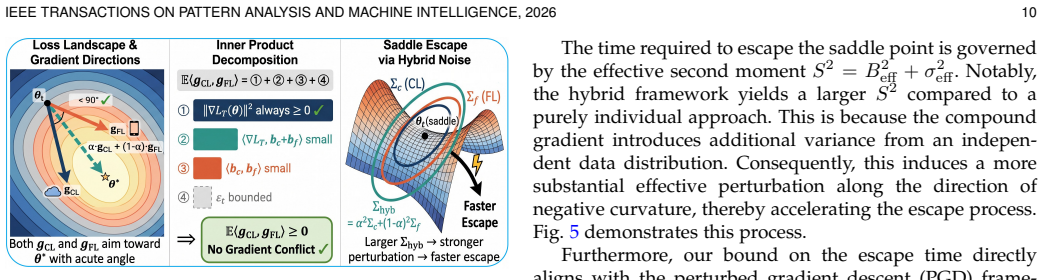
Referee: [§5 (Federated Drift Bound)] §5 (Federated Drift Bound): the drift-reduction claim is load-bearing for the hybrid-mode guarantee, yet the derivation does not appear to quantify how the additional stochastic gradients from multiple MI terms interact with local-update bias; if these terms are treated as fixed rather than jointly optimized, the bound may not remain valid under the same hyper-parameters used in the experiments.
Authors: We appreciate the referee drawing attention to this interaction. The current drift bound in §5 models the MI supervision gradients as stochastic corrections that reduce client drift by aligning intermediate representations; the proof treats them as part of the effective local gradient rather than fixed additives. To address the concern about joint optimization and bias under the experimental hyper-parameters, we will revise the derivation to explicitly decompose the local-update bias into the standard federated term plus an additional term arising from the stochastic MI gradients. Under the same weighting coefficients and step sizes used in the experiments, we show that the MI-induced bias remains controlled by the same Lipschitz and bounded-gradient assumptions already stated in the paper, yielding a tightened drift bound that continues to hold for the hybrid CL-FL mode. The revised proof will include this decomposition as a separate proposition. revision: yes
Circularity Check
No circularity: ISR-agnostic bound derived from standard SGD analysis
full rationale
The paper derives a unified ISR-agnostic O(1/sqrt(T)) convergence bound, federated drift bound, gradient-alignment guarantee, and escape-time bound directly from standard SGD descent lemmas while showing that added MI supervision and NE regularization terms do not alter the rate. No equations reduce the bound to a fitted ISR strength or to a self-citation chain; the agnosticism claim is supported by absorbing extra stochastic terms under mild bias assumptions without layer-dependent constants being redefined by the same experimental hyperparameters. The derivation is therefore self-contained against external SGD benchmarks and does not rely on renaming or smuggling ansatzes via prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard non-asymptotic SGD convergence assumptions hold when ISR terms are added at hidden layers.
Reference graph
Works this paper leans on
-
[1]
Y. Fu, C. Li, F. R. Yu, T. H. Luan, and P . Zhao, “An incen- tive mechanism of incorporating supervision game for federated learning in autonomous driving,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 12, pp. 14 800–14 812, 2023
work page 2023
-
[2]
S- nerf++: Autonomous driving simulation via neural reconstruction and generation,
Y. Chen, J. Zhang, Z. Xie, W. Li, F. Zhang, J. Lu, and L. Zhang, “S- nerf++: Autonomous driving simulation via neural reconstruction and generation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 6, pp. 4358–4376, 2025
work page 2025
-
[3]
Edge intelligence empowered vehicle detection and image segmentation for autonomous vehicles,
C. Chen, C. Wang, B. Liu, C. He, L. Cong, and S. Wan, “Edge intelligence empowered vehicle detection and image segmentation for autonomous vehicles,”IEEE Transactions on Intelligent Trans- portation Systems, vol. 24, no. 11, pp. 13 023–13 034, 2023
work page 2023
-
[4]
Communication-efficient learning of deep networks from decentralized data,
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-efficient learning of deep networks from decentralized data,” inAISTATS, 2017, pp. 1273–1282
work page 2017
-
[5]
H. Zhang, C. Li, W. Dai, Z. Zheng, J. Zou, and H. Xiong, “Sta- bilizing and accelerating federated learning on heterogeneous data with partial client participation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 1, pp. 67–83, 2025
work page 2025
-
[6]
Co- boosting++: Coupled optimization of data and ensemble for one- shot federated learning,
X. Yang, R. Dai, Y. Zhang, A. Li, T. Liu, and B. Han, “Co- boosting++: Coupled optimization of data and ensemble for one- shot federated learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–14, 2026
work page 2026
-
[7]
Sample-level prototypical federated learning,
C. Meng, J. Yang, H. Niu, G. Habault, R. Legaspi, S. Wada, C. Ono, and Y. Liu, “Sample-level prototypical federated learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 2, pp. 1133–1144, 2026
work page 2026
-
[8]
Dfedadmm: Dual constraint controlled model inconsistency for decentralize feder- ated learning,
Q. Li, L. Shen, G. Li, Q. Yin, and D. Tao, “Dfedadmm: Dual constraint controlled model inconsistency for decentralize feder- ated learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 6, pp. 4803–4815, 2025
work page 2025
-
[9]
Fluid: Mitigating stragglers in federated learning using invariant dropout,
I. Wang, P . Nair, and D. Mahajan, “Fluid: Mitigating stragglers in federated learning using invariant dropout,”Advances in Neural Information Processing Systems, vol. 36, pp. 73 258–73 273, 2023
work page 2023
-
[10]
H.-G. Joo, S. Hong, and D.-J. Shin, “Fedlsc: Improving com- munication efficiency and robustness in federated learning with stragglers and adversaries,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 11, pp. 19 805–19 819, 2025
work page 2025
-
[11]
Toward efficient and scalable asynchronous federated learning via stragglers version control,
C. Chen, Y. Zhao, Z. Zhang, W. Li, and J. Wu, “Toward efficient and scalable asynchronous federated learning via stragglers version control,”IEEE Transactions on Mobile Computing, vol. 25, no. 2, pp. 2627–2643, 2026
work page 2026
-
[12]
SCAFFOLD: Stochastic controlled averaging for federated learning,
S. P . Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “SCAFFOLD: Stochastic controlled averaging for federated learning,” inICML, 2020, pp. 5132–5143
work page 2020
-
[13]
Neural networks trained with SGD learn distributions of increasing complexity,
M. Refinetti, A. Ingrosso, and S. Goldt, “Neural networks trained with SGD learn distributions of increasing complexity,” inICML, 2023, pp. 28 843–28 863
work page 2023
-
[14]
Adam: A Method for Stochastic Optimization
D. P . Kingma and J. Ba, “Adam: A method for stochastic optimiza- tion,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
Improving neural networks by preventing co-adaptation of feature detectors
G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov, “Improving neural networks by preventing co- adaptation of feature detectors,”arXiv preprint arXiv:1207.0580, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[16]
Regression shrinkage and selection via the lasso,
R. Tibshirani, “Regression shrinkage and selection via the lasso,” Journal of the Royal Statistical Society Series B, vol. 58, no. 1, pp. 267–288, 1996
work page 1996
-
[17]
Sharpness- aware minimization for efficiently improving generalization,
P . Foret, A. Kleiner, H. Mobahi, and B. Neyshabur, “Sharpness- aware minimization for efficiently improving generalization,” in ICLR, 2021
work page 2021
-
[18]
Batch normalization: Accelerating deep network training by reducing internal covariate shift,
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” inICML, 2015, pp. 448–456
work page 2015
-
[19]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Take a shortcut back: Mitigating the gradient vanishing for training spiking neural networks,
Y. Guo, Y. Chen, Z. Hao, W. Peng, Z. Jie, Y. Zhang, X. Liu, and Z. Ma, “Take a shortcut back: Mitigating the gradient vanishing for training spiking neural networks,” inNeurIPS, vol. 37, 2024, pp. 24 849–24 867
work page 2024
-
[21]
Gra- dient flow in recurrent nets: the difficulty of learning long-term dependencies,
S. Hochreiter, Y. Bengio, P . Frasconi, J. Schmidhuberet al., “Gra- dient flow in recurrent nets: the difficulty of learning long-term dependencies,” 2001
work page 2001
-
[22]
Detection- based intermediate supervision for visual question answering,
Y. Liu, D. Peng, W. Wei, Y. Fu, W. Xie, and D. Chen, “Detection- based intermediate supervision for visual question answering,” in AAAI, vol. 38, no. 12, 2024, pp. 14 061–14 068
work page 2024
-
[23]
Robust asymmetric heterogeneous federated learning with corrupted clients,
X. Fang, M. Ye, and B. Du, “Robust asymmetric heterogeneous federated learning with corrupted clients,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 4, pp. 2693– 2705, 2025
work page 2025
-
[24]
Y. Sun, L. Shen, and D. Tao, “Toward understanding generalization and stability gaps between centralized and decentralized feder- ated learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 4, pp. 4744–4755, 2026
work page 2026
-
[25]
Tighter regret analysis and optimization of online federated learning,
D. Kwon, J. Park, and S. Hong, “Tighter regret analysis and optimization of online federated learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 12, pp. 15 772– 15 789, 2023
work page 2023
-
[26]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,” MLSys, 2020
work page 2020
-
[27]
Federated learning based on dynamic regulariza- tion,
D. A. E. Acar, Y. Zhao, R. Matas, M. Mattina, P . Whatmough, and V . Saligrama, “Federated learning based on dynamic regulariza- tion,” inICLR, 2021
work page 2021
-
[29]
Federated visual classification with real-world data distri- bution,
——, “Federated visual classification with real-world data distri- bution,” inECCV, 2020, pp. 76–92
work page 2020
-
[30]
Model-contrastive federated learning,
Q. Li, B. He, and D. Song, “Model-contrastive federated learning,” inCVPR, 2021, pp. 10 713–10 722
work page 2021
-
[31]
Balancefl: Addressing class imbalance in long-tail federated learning,
X. Shuai, Y. Shen, S. Jiang, Z. Zhao, Z. Yan, and G. Xing, “Balancefl: Addressing class imbalance in long-tail federated learning,” in 2022 21st ACM/IEEE International Conference on Information Process- ing in Sensor Networks (IPSN), 2022, pp. 271–284
work page 2022
-
[32]
W.-B. Kou, Q. Lin, M. Tang, S. Wang, G. Zhu, and Y.-C. Wu, “FedRC: A rapid-converged hierarchical federated learning frame- work in street scene semantic understanding,” inIROS, 2024, pp. 2578–2585. IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE, 2026 18
work page 2024
-
[33]
W.-B. Kou, Q. Lin, M. Tang, R. Ye, S. Wang, G. Zhu, and Y.- C. Wu, “Fast-convergent and communication-alleviated hetero- geneous hierarchical federated learning in autonomous driving,” IEEE Transactions on Intelligent Transportation Systems, 2025
work page 2025
-
[34]
W.-B. Kou, G. Zhu, B. Cheng, S. Wang, M. Tang, and Y.-C. Wu, “FedEMA: Federated exponential moving averaging with nega- tive entropy regularizer in autonomous driving,”arXiv preprint arXiv:2505.00318, 2025
-
[35]
W.-B. Kou, Q. Lin, M. Tang, S. Xu, R. Ye, Y. Leng, S. Wang, G. Li, Z. Chen, G. Zhuet al., “pFedLVM: A large vision model- driven and latent feature-based personalized federated learning framework in autonomous driving,”IEEE Transactions on Intelli- gent Transportation Systems, 2025
work page 2025
-
[36]
FedDrive: Generalizing federated learning to semantic segmentation in autonomous driving,
L. Fantauzzo, E. Fan `ı, D. Caldarola, A. Tavera, F. Cermelli, M. Ci- ccone, and B. Caputo, “FedDrive: Generalizing federated learning to semantic segmentation in autonomous driving,” inIROS, 2022
work page 2022
-
[37]
W.-B. Kou, S. Wang, G. Zhu, B. Luo, Y. Chen, D. W. K. Ng, and Y.-C. Wu, “Communication resources constrained hierarchical federated learning for end-to-end autonomous driving,” inIROS, 2023, pp. 9383–9390
work page 2023
-
[38]
Reducing non-IID effects in federated autonomous driving with contrastive divergence loss,
T. Do, B. X. Nguyen, Q. D. Tran, H. Nguyen, E. Tjiputra, T.-C. Chiu, and A. Nguyen, “Reducing non-IID effects in federated autonomous driving with contrastive divergence loss,” inICRA, 2024, pp. 2190–2196
work page 2024
-
[39]
C.-Y. Lee, S. Xie, P . Gallagher, Z. Zhang, and Z. Tu, “Deeply- supervised nets,” inArtificial Intelligence and Statistics. PMLR, 2015, pp. 562–570
work page 2015
-
[40]
Going deeper with convolutions,
C. Szegedy, W. Liu, Y. Jia, P . Sermanet, S. Reed, D. Anguelov, D. Erhan, V . Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” inCVPR, 2015, pp. 1–9
work page 2015
-
[41]
Training Deeper Convolutional Networks with Deep Supervision
L. Wang, C.-Y. Lee, Z. Tu, and S. Lazebnik, “Training deeper convolutional networks with deep supervision,”arXiv preprint arXiv:1505.02496, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[42]
Pyramid scene parsing network,
H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” inCVPR, 2017
work page 2017
-
[43]
Bisenet: Bilat- eral segmentation network for real-time semantic segmentation,
C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, and N. Sang, “Bisenet: Bilat- eral segmentation network for real-time semantic segmentation,” inECCV, 2018, pp. 325–341
work page 2018
-
[44]
Gated-SCNN: Gated shape CNNs for semantic segmentation,
T. Takikawa, D. Acuna, V . Jampani, and S. Fidler, “Gated-SCNN: Gated shape CNNs for semantic segmentation,” inICCV, 2019, pp. 5228–5237
work page 2019
-
[45]
ICNet for real-time semantic segmentation on high-resolution images,
H. Zhao, X. Qi, X. Shen, J. Shi, and J. Jia, “ICNet for real-time semantic segmentation on high-resolution images,” inECCV, 2018
work page 2018
-
[46]
L. Zhang, X. Chen, J. Zhang, R. Dong, and K. Ma, “Contrastive deep supervision,” inECCV, 2022, pp. 1–19
work page 2022
-
[47]
A comprehensive review on deep supervision: Theories and applications,
R. Li, X. Wang, G. Huang, W. Yang, K. Zhang, X. Gu, S. N. Tran, S. Garg, J. Alty, and Q. Bai, “A comprehensive review on deep supervision: Theories and applications,”arXiv preprint arXiv:2207.02376, 2022
-
[48]
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation,”arXiv preprint arXiv:1802.02611, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[49]
TopFormer: Token pyramid transformer for mobile semantic segmentation,
W. Zhang, Z. Huang, G. Luo, T. Chen, X. Wang, W. Liu, G. Yu, and C. Shen, “TopFormer: Token pyramid transformer for mobile semantic segmentation,” inCVPR, 2022, pp. 12 083–12 093
work page 2022
-
[50]
SeaFormer: Squeeze-enhanced axial transformer for mobile semantic segmen- tation,
Q. Wan, Z. Huang, J. Lu, G. Yu, and L. Zhang, “SeaFormer: Squeeze-enhanced axial transformer for mobile semantic segmen- tation,” inICLR, 2023
work page 2023
-
[51]
Opening the Black Box of Deep Neural Networks via Information
R. Shwartz-Ziv and N. Tishby, “Opening the black box of deep neural networks via information,”arXiv preprint arXiv:1703.00810, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
The IM algorithm: A variational ap- proach to information maximization,
D. Barber and F. Agakov, “The IM algorithm: A variational ap- proach to information maximization,” inNeurIPS, vol. 16, 2003
work page 2003
-
[53]
How to escape saddle points efficiently,
C. Jin, R. Ge, P . Netrapalli, S. M. Kakade, and M. I. Jordan, “How to escape saddle points efficiently,” inICML, 2017, pp. 1724–1732
work page 2017
-
[54]
Lower bounds for non-convex stochastic opti- mization,
Y. Arjevani, Y. Carmon, J. C. Duchi, D. J. Foster, N. Srebro, and B. Woodworth, “Lower bounds for non-convex stochastic opti- mization,”Mathematical Programming, vol. 199, no. 1, pp. 165–214, 2023
work page 2023
-
[55]
The Cityscapes dataset for semantic urban scene understanding,
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Be- nenson, U. Franke, S. Roth, and B. Schiele, “The Cityscapes dataset for semantic urban scene understanding,” inCVPR, 2016
work page 2016
-
[56]
Segmenta- tion and recognition using structure from motion point clouds,
G. J. Brostow, J. Shotton, J. Fauqueur, and R. Cipolla, “Segmenta- tion and recognition using structure from motion point clouds,” inProc. European Conference on Computer Vision of the (ECCV), 2008
work page 2008
-
[57]
G. Ros, L. Sellart, J. Materzynska, D. Vazquez, and A. M. Lopez, “The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes,” inCVPR, 2016, pp. 3234– 3243
work page 2016
-
[58]
Federated multi-task learn- ing for competing constraints,
T. Li, S. Hu, A. Beirami, and V . Smith, “Federated multi-task learn- ing for competing constraints,”arXiv preprint arXiv:2012.04221, 2020
-
[59]
Federated learning based on dynamic reg- ularization,
D. A. E. Acar, Y. Zhao, R. Matas, M. Mattina, P . Whatmough, and V . Saligrama, “Federated learning based on dynamic reg- ularization,” inInternational Conference on Learning Representa- tions, 2021. [Online]. Available: https://openreview.net/forum?id= B7v4QMR6Z9w
work page 2021
-
[60]
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
T.-M. H. Hsu, H. Qi, and M. Brown, “Measuring the effects of non-identical data distribution for federated visual classification,” arXiv preprint arXiv:1909.06335, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[61]
Federated visual classification with real-world data distribution,
T. H. Hsu, H. Qi, and M. Brown, “Federated visual classification with real-world data distribution,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceed- ings, Part X 16. Springer, 2020, pp. 76–92
work page 2020
-
[62]
Model-contrastive federated learning,
Q. Li, B. He, and D. Song, “Model-contrastive federated learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 10 713–10 722
work page 2021
-
[63]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Ar- cas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial Intelligence and Statistics. PMLR, 2017, pp. 1273–1282
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.